Chatgpt Etwas wie: „Bitte scout all die Technik für mich und fassen Sie Tendencies und Muster zusammen, basierend auf dem, was Sie für interessiert haben.“ Sie wissen, dass Sie etwas Generisches bekommen würden, wo es einige Web sites und Nachrichtenquellen durchsucht und Ihnen diese übergibt.
Dies liegt daran, dass Chatgpt für allgemeine Anwendungsfälle erstellt wurde. Es wendet normale Suchmethoden an, um Informationen abzurufen und sich häufig auf einige Webseiten zu beschränken.
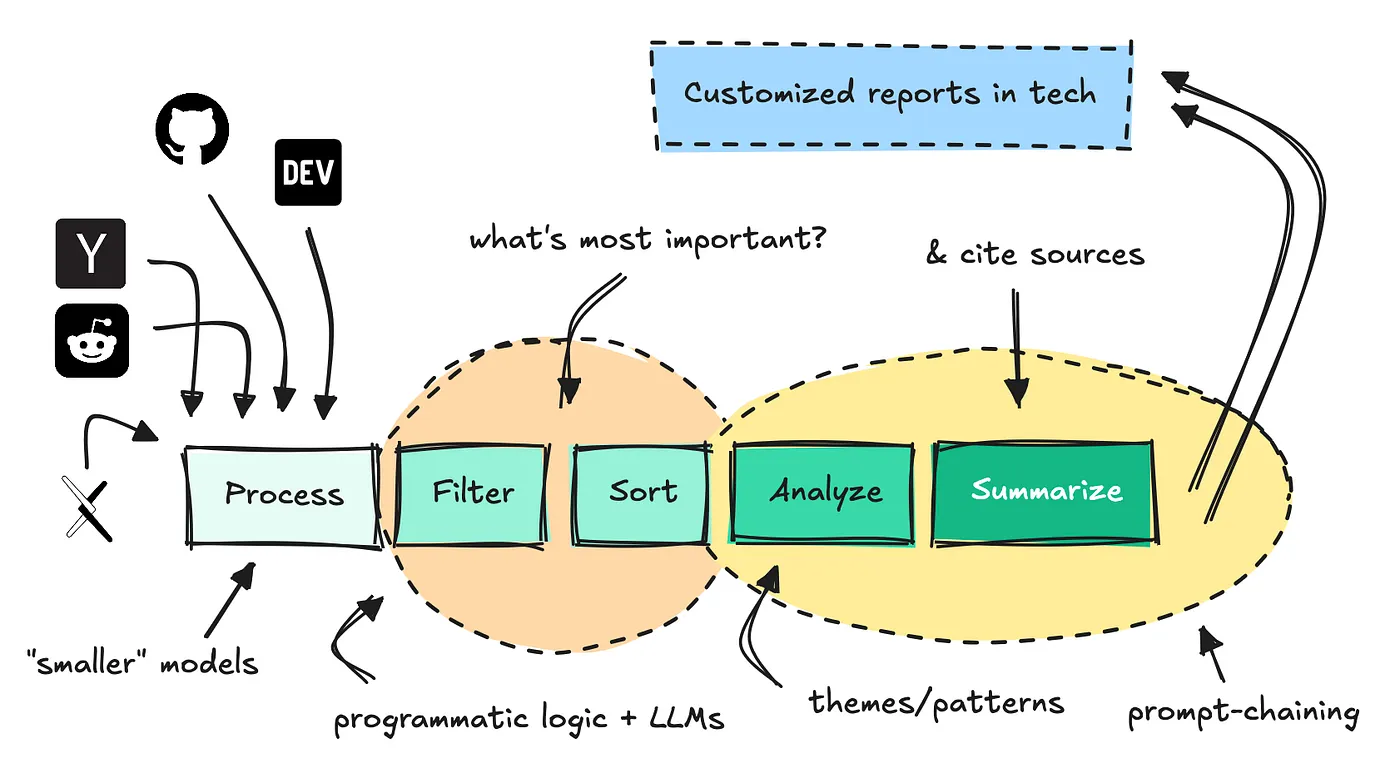
In diesem Artikel werden Sie angezeigt, wie Sie einen Nischenagenten erstellen, der alle Technologien skotieren, Millionen von Texten zusammenfassen, Daten basierend auf einer Persona filtern und Muster und Themen finden können, auf die Sie reagieren können.
Der Sinn dieses Workflows besteht darin, das Sitzen und Scrollen durch Foren und soziale Medien selbst zu vermeiden. Der Agent sollte es für Sie tun und alles greifen, was nützlich ist.

Wir werden dies mithilfe einer eindeutigen Datenquelle, einem kontrollierten Workflow und einigen schnellen Verkettungstechniken ausschalten können.

Durch das Zwischenspeichern von Daten können wir die Kosten auf ein paar Cent professional Bericht reduzieren.
Wenn Sie den Bot ausprobieren möchten, ohne ihn selbst zu booten, können Sie sich diesem anschließen Zwietracht Kanal. Sie werden das Repository finden Hier Wenn Sie es selbst bauen möchten.
Dieser Artikel konzentriert sich auf die allgemeine Architektur und die Erstellung, nicht die kleineren Codierungsdetails Github.
Notizen zum Gebäude
Wenn Sie neu im Bau mit Agenten sind, können Sie das Gefühl haben, dass dieser nicht bahnbrechend genug ist.
Wenn Sie jedoch etwas erstellen möchten, das funktioniert, müssen Sie Ihre KI -Anwendungen ziemlich viel Software program -Engineering anwenden. Auch wenn LLMs jetzt alleine handeln können, brauchen sie immer noch Anleitung und Leitplanken.
Bei solchen Workflows, bei denen ein klarer Weg, den das System einschlagen sollte, sollten Sie strukturiertere „Workflow-ähnliche“ Systeme erstellen. Wenn Sie einen Menschen in der Schleife haben, können Sie mit etwas Dynamischeres arbeiten.
Der Grund, warum dieser Workflow so intestine funktioniert, ist, dass ich eine sehr gute Datenquelle dahinter habe. Ohne diesen Datengraben wäre der Workflow nicht besser als Chatgpt.
Daten vorbereiten und zwischenstrichen
Bevor wir einen Agenten erstellen können, müssen wir eine Datenquelle vorbereiten, in die er anziehen kann.
Ich denke, dass viele Menschen falsch machen, wenn sie mit LLM -Systemen zusammenarbeiten, ist die Überzeugung, dass KI Daten für sich allein verarbeiten und aggregieren kann.
Irgendwann können wir ihnen möglicherweise genügend Werkzeuge geben, um sie selbst zu bauen, aber wir sind noch nicht in Bezug auf die Zuverlässigkeit da.
Wenn wir additionally solche Systeme erstellen, benötigen wir Datenpipelines, um genauso sauber zu sein wie für jedes andere System.
Das System, das ich hier erstellt habe, verwendet eine Datenquelle, die ich bereits zur Verfügung stellte. Ich verstehe, wie ich den LLM beibringe, um sie zu nutzen.
Es nimmt Tausende von Texten aus Tech -Foren und Web sites professional Tag auf und verwendet kleine NLP -Modelle, um die Hauptschlüsselwörter zu zerstören, sie zu kategorisieren und die Stimmung zu analysieren.
Auf diese Weise können wir sehen, welche Schlüsselwörter in verschiedenen Kategorien über einen bestimmten Zeitraum tendieren.
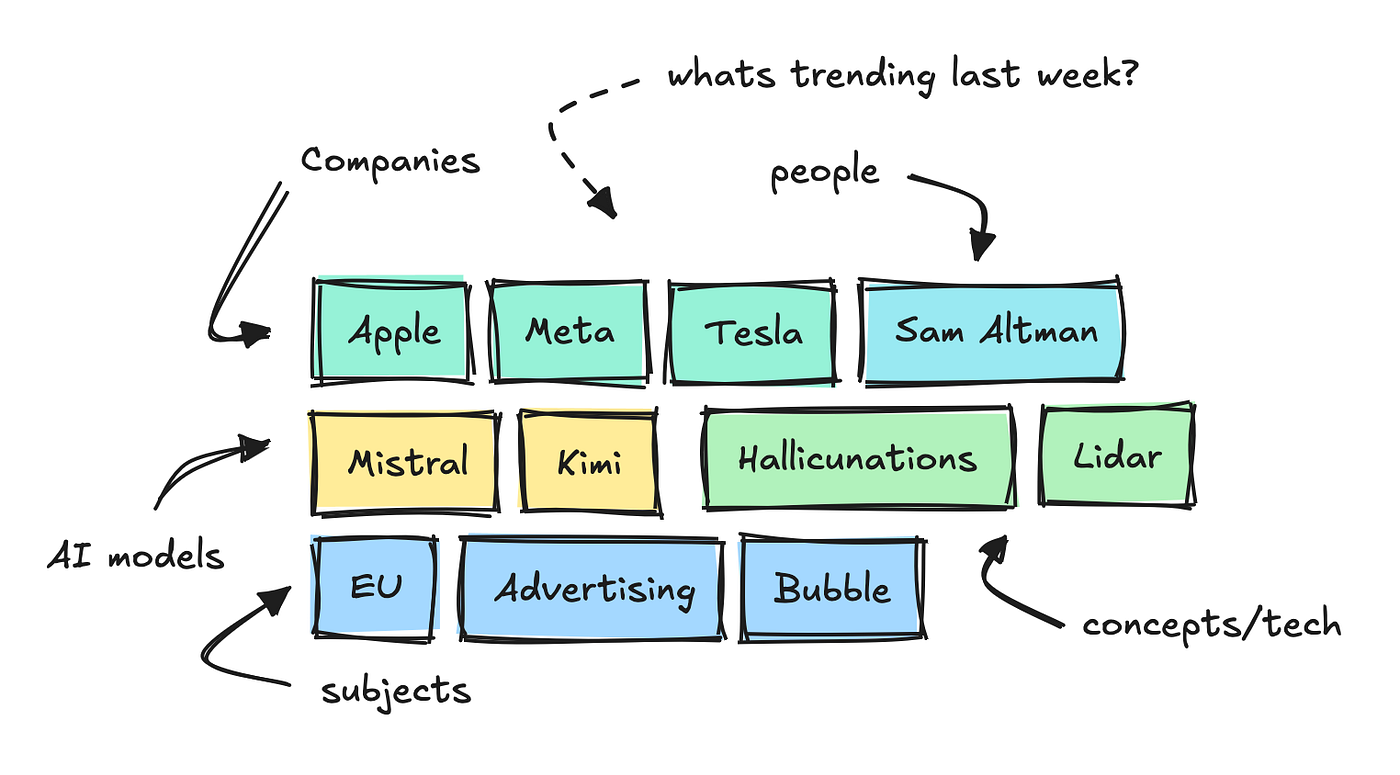
Um diesen Agenten zu erstellen, habe ich einen weiteren Endpunkt hinzugefügt, der für jedes dieser Schlüsselwörter „Fakten“ sammelt.
Dieser Endpunkt erhält ein Schlüsselwort und einen Zeitraum, und das System sortiert Kommentare und Beiträge durch Engagement. Anschließend verarbeitet es die Texte in Stücken mit kleineren Modellen, die entscheiden können, welche „Fakten“ aufbewahrt werden sollen.
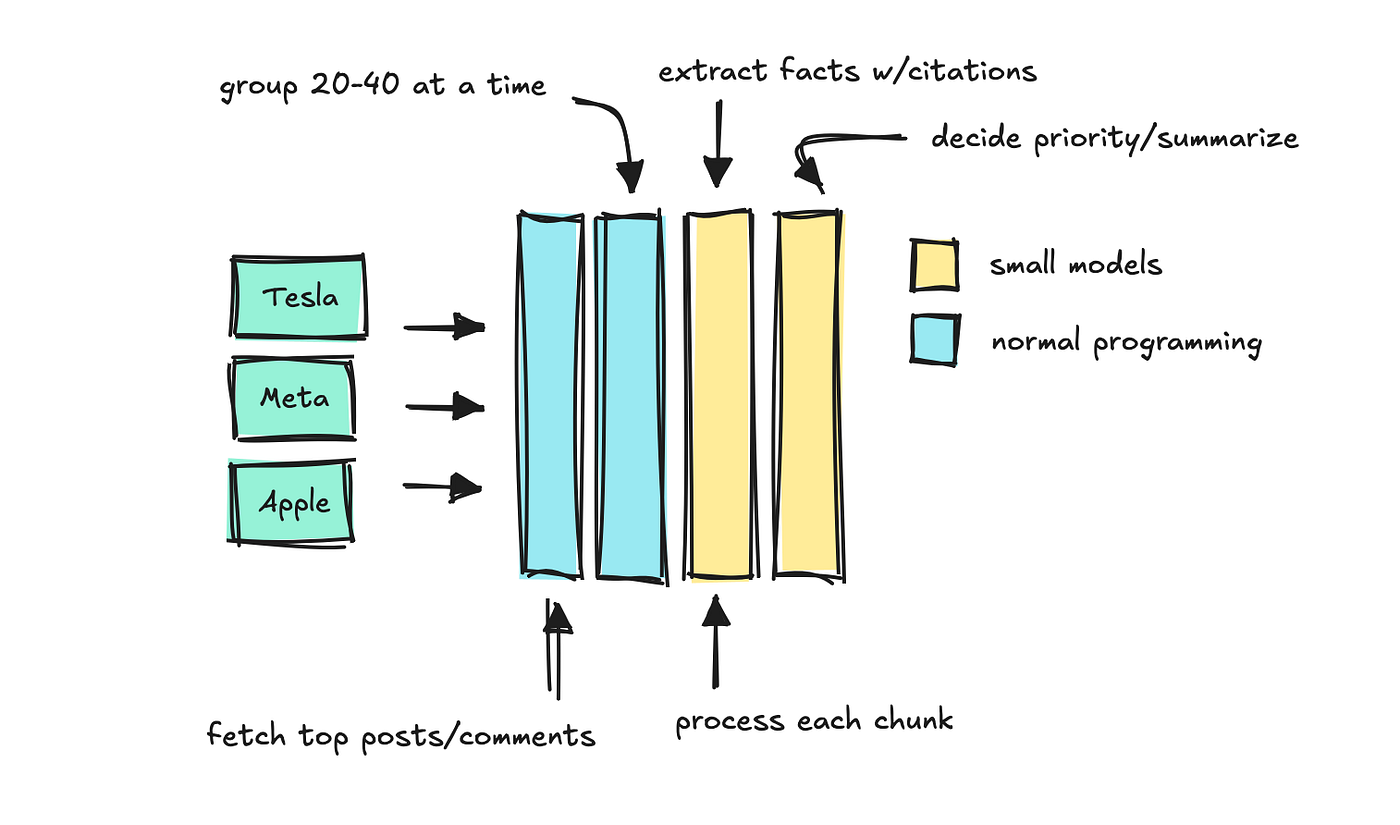
Wir wenden eine letzte LLM an, um zusammenzufassen, welche Fakten am wichtigsten sind, und halten die Quellzitate intakt.
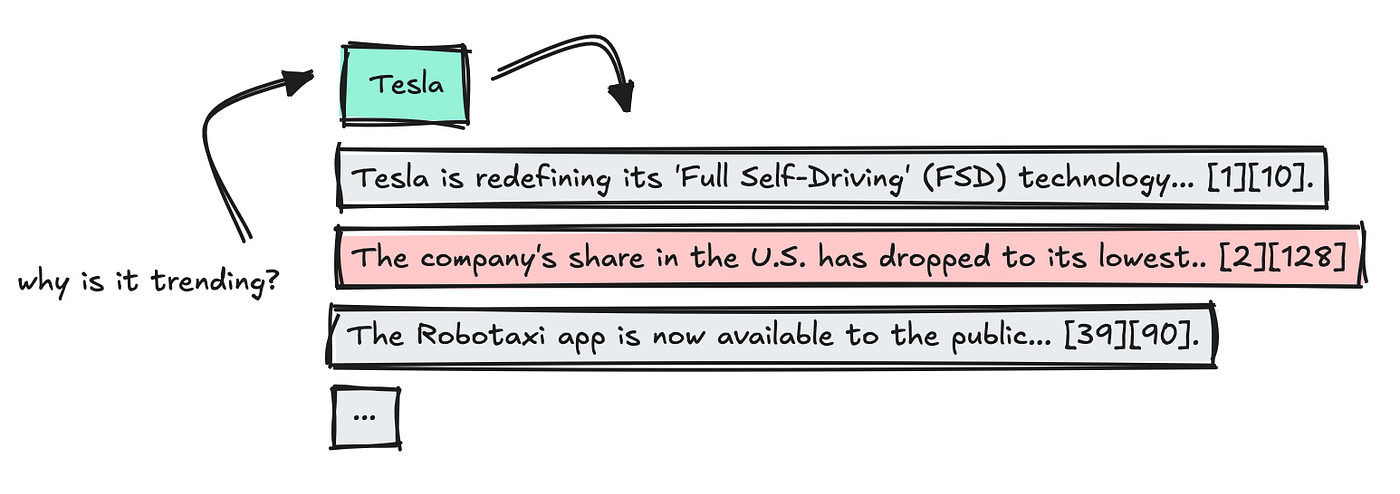
Dies ist eine Artwork schneller Verkettungsprozess, und ich habe es gebaut, um die Zitiermotor von Llamaindex nachzuahmen.
Wenn der Endpunkt zum ersten Mal ein Key phrase gefordert wird, kann es bis zu einer halben Minute dauern. Da das System das Ergebnis vorangetrieben, dauert jede Wiederholungsanforderung nur ein paar Millisekunden.
Solange die Modelle klein genug sind, sind die Kosten, um dies auf ein paar hundert Schlüsselwörtern professional Tag zu betreiben, minimal. Später können das System mehrere Schlüsselwörter parallel ausführen.
Sie können sich jetzt wahrscheinlich vorstellen, dass wir ein System erstellen können, um diese Schlüsselwörter und Fakten zu holen, um verschiedene Berichte mit LLMs zu erstellen.
Wann man mit kleinen gegen größeren Modelle arbeitet
Bevor Sie fortfahren, erwähnen wir nur, dass die Auswahl der richtigen Modellgröße von Bedeutung ist.
Ich denke, das ist im Second in aller Munde.
Es gibt ziemlich fortschrittliche Modelle, die Sie für jeden Workflow verwenden können. Wenn wir jedoch immer mehr LLMs auf diese Anwendungen anwenden, summiert sich die Anzahl der Anrufe professional Lauf schnell und dies kann teuer werden.
Wenn Sie additionally können, verwenden Sie kleinere Modelle.
Sie haben gesehen, dass ich kleinere Modelle verwendet habe, um Quellen in Stücken zu zitieren und zu gruppieren. Andere Aufgaben, die für kleine Modelle hervorragend sind, sind das Routing und die Analyse der natürlichen Sprache in strukturierte Daten.
Wenn Sie feststellen, dass das Modell ins Stocken gerät, können Sie die Aufgabe in kleinere Probleme unterteilen und eine schnelle Verkettung verwenden, zuerst eine Sache tun, dann dieses Ergebnis verwenden, um das nächste und so weiter zu tun.
Sie möchten immer noch größere LLMs verwenden, wenn Sie Muster in sehr großen Texten finden müssen oder wenn Sie mit Menschen kommunizieren.
In diesem Workflow sind die Kosten minimal, da die Daten zwischengespeichert werden, wir für die meisten Aufgaben kleinere Modelle verwenden, und die einzigen einzigartigen großen LLM -Anrufe sind die letzten.
Wie dieser Agent funktioniert
Lassen Sie uns durchgehen, wie der Agent unter der Motorhaube arbeitet. Ich habe den Agenten gebaut, um in Discord zu rennen, aber das liegt hier nicht im Mittelpunkt. Wir werden uns auf die Agentenarchitektur konzentrieren.
Ich habe den Prozess in zwei Teile geteilt: ein Setup und eine Nachricht. Der erste Prozess fordert den Benutzer auf, sein Profil einzurichten.
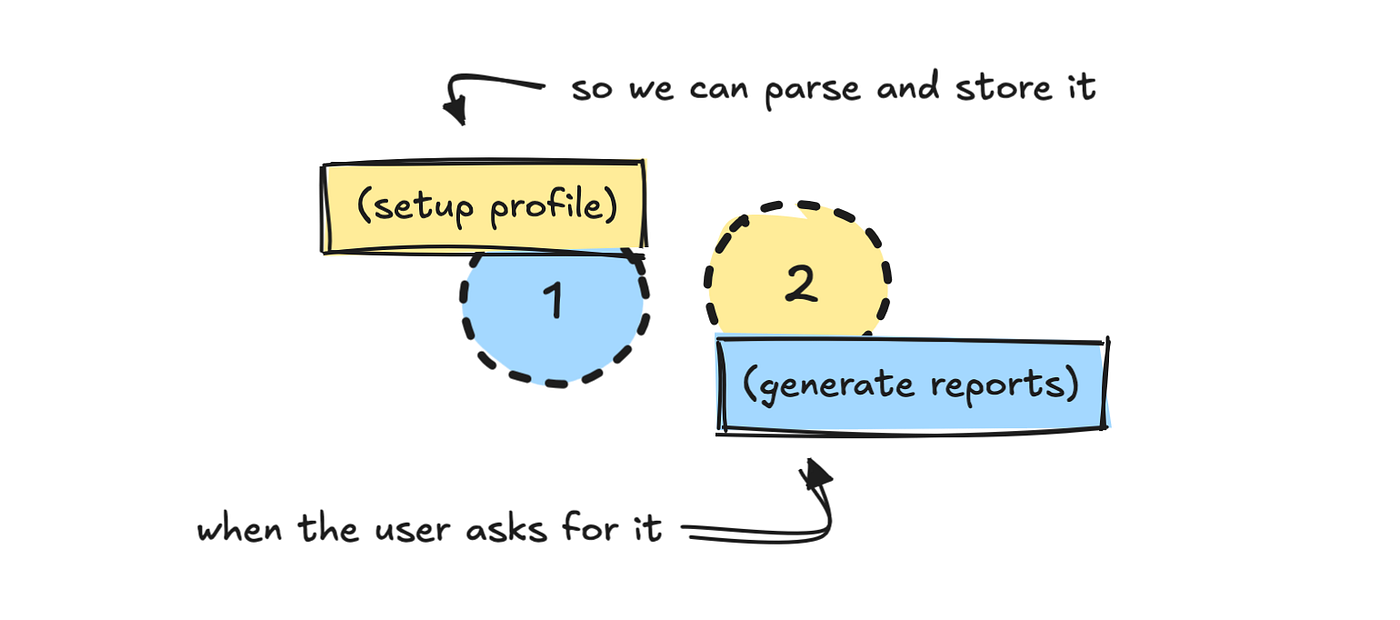
Da ich bereits weiß, wie man mit der Datenquelle arbeitet, habe ich eine ziemlich umfangreiche Systemaufforderung erstellt, mit der die LLM diese Eingaben in etwas umsetzen kann, mit dem wir Daten später abrufen können.
PROMPT_PROFILE_NOTES = """
You might be tasked with defining a person persona based mostly on the person's profile abstract.
Your job is to:
1. Choose a brief persona description for the person.
2. Choose probably the most related classes (main and minor).
3. Select key phrases the person ought to monitor, strictly following the foundations beneath (max 6).
4. Resolve on time interval (based mostly solely on what the person asks for).
5. Resolve whether or not the person prefers concise or detailed summaries.
Step 1. Persona
- Write a brief description of how we must always take into consideration the person.
- Examples:
- CMO for non-technical product → "non-technical, skip jargon, give attention to product key phrases."
- CEO → "solely embrace extremely related key phrases, no technical overload, straight to the purpose."
- Developer → "technical, eager about detailed developer dialog and technical phrases."
(...)
"""
Ich habe auch ein Schema für die Ausgänge definiert, die ich brauche:
class ProfileNotesResponse(BaseModel):
persona: str
major_categories: Record(str)
minor_categories: Record(str)
key phrases: Record(str)
time_period: str
concise_summaries: boolOhne Domänenwissen über die API und wie sie funktioniert, ist es unwahrscheinlich, dass ein LLM herausfinden würde, wie dies selbst zu tun ist.
Sie könnten versuchen, ein umfangreicheres System aufzubauen, bei dem das LLM zuerst versucht, die API oder die Systeme zu lernen, die sie verwenden sollen, aber das würde den Workflow unvorhersehbarer und kostspieliger machen.
Bei solchen Aufgaben versuche ich immer strukturierte Ausgänge im JSON -Format zu verwenden. Auf diese Weise können wir das Ergebnis validieren, und wenn die Validierung fehlschlägt, führen wir es erneut aus.
Dies ist der einfachste Weg, um mit LLMs in einem System zu arbeiten, insbesondere wenn kein Mensch in der Schleife ist, um zu überprüfen, was das Modell zurückgibt.
Sobald die LLM das Benutzerprofil in die Eigenschaften übersetzt hat, die wir im Schema definiert haben, speichern wir das Profil irgendwo. Ich habe MongoDB verwendet, aber das ist elective.
Das Speichern der Persönlichkeit ist nicht streng erforderlich, aber Sie müssen übersetzen, was der Benutzer sagt, in ein Formular, mit dem Sie Daten generieren können.
Erzeugen der Berichte
Schauen wir uns an, was im zweiten Schritt passiert, wenn der Benutzer den Bericht auslöst.
Wenn der Benutzer die trifft /information Der Befehl, mit oder ohne Zeitraumsatz, holen wir zuerst die von uns gespeicherten Benutzerprofildaten.
Dies gibt dem System den Kontext, den es benötigt, um relevante Daten zu holen, wobei sowohl Kategorien als auch Schlüsselwörter mit dem Profil gebunden sind. Die Standardzeit ist wöchentlich.
Aus diesem Grund erhalten wir eine Liste von High- und Development -Key phrases für den ausgewählten Zeitraum, der für den Benutzer interessant ist.

Ohne diese Datenquelle wäre es schwierig gewesen, so etwas so etwas zu erstellen. Die Daten müssen im Voraus erstellt werden, damit die LLM ordnungsgemäß damit funktioniert.
Nach dem Abrufen von Schlüsselwörtern könnte es sinnvoll sein, einen LLM -Schritt hinzuzufügen, in dem Schlüsselwörter für den Benutzer irrelevant sind. Das habe ich hier nicht gemacht.
Je unnötigere Informationen ein LLM übergeben, desto schwieriger wird es, sich auf das zu konzentrieren, was wirklich wichtig ist. Ihre Aufgabe ist es, sicherzustellen, dass alles, was Sie füttern, für die tatsächliche Frage des Benutzers related ist.
Als nächstes verwenden wir den früher vorbereiteten Endpunkt, der zwischengespeicherte „Fakten“ für jedes Schlüsselwort enthält. Dies gibt uns bereits überprüft und sortierte Informationen für jeden.
Wir führen parallel Key phrase -Anrufe aus, um die Dinge zu beschleunigen, aber die erste Particular person, die ein neues Key phrase anfordert, muss noch etwas länger warten.
Sobald die Ergebnisse vorliegen, kombinieren wir die Daten, entfernen Duplikate und analysieren die Zitate, sodass jede Tatsache über eine Schlüsselwortnummer auf eine bestimmte Quelle zurückbleibt.
Anschließend führen wir die Daten über einen Eingabeaufforderungsprozess aus. Das erste LLM findet 5 bis 7 Themen und richtet sie nach Relevanz, basierend auf dem Benutzerprofil. Es zieht auch die wichtigsten Punkte heraus.
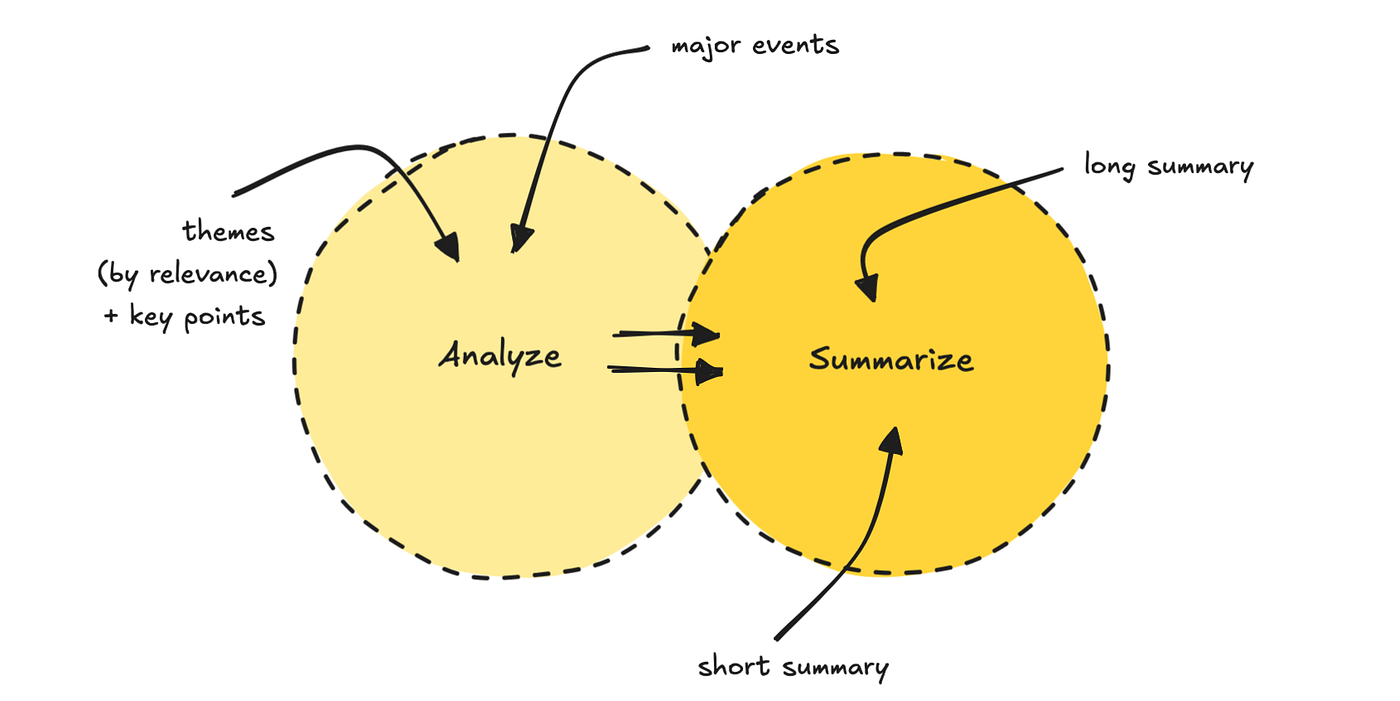
Der zweite LLM -Go verwendet sowohl die Themen als auch die Originaldaten, um zwei verschiedene Zusammenfassungslängen zusammen mit einem Titel zu generieren.
Wir können dies tun, um sicherzustellen, dass die kognitive Belastung des Modells reduziert wird.
Dieser letzte Schritt zum Erstellen des Berichts braucht die meiste Zeit, da ich ein Argumentationsmodell wie GPT-5 verwendet habe.
Sie könnten es gegen etwas schnelleres austauschen, aber ich finde, dass fortgeschrittene Modelle in diesem letzten Zeug besser sind.
Der vollständige Vorgang dauert einige Minuten, je nachdem, wie viel an diesem Tag bereits zwischengespeichert wurde.
Schauen Sie sich das fertige Ergebnis unten an.
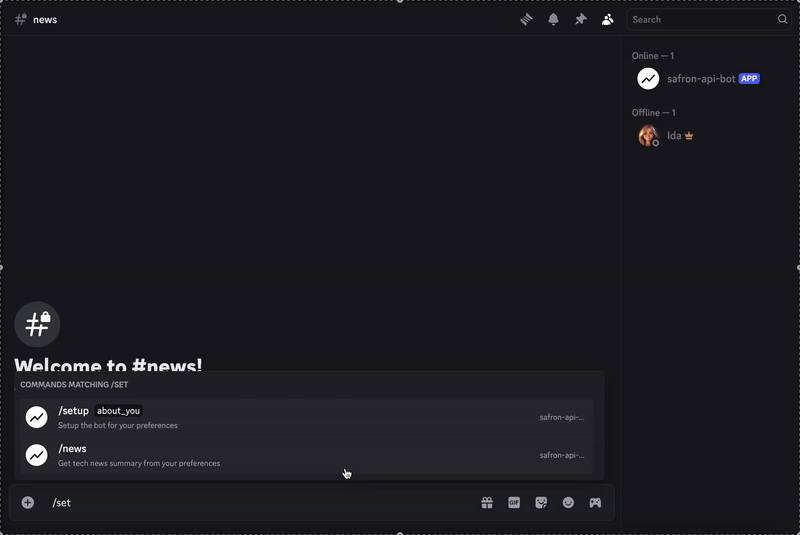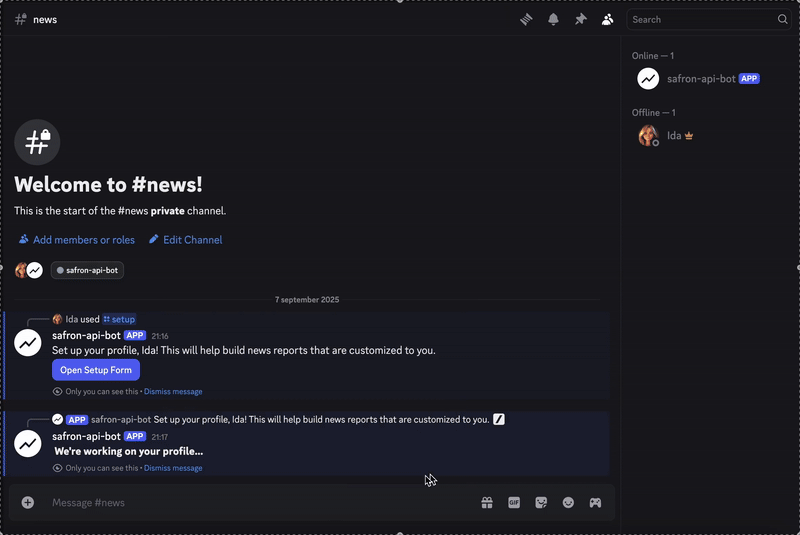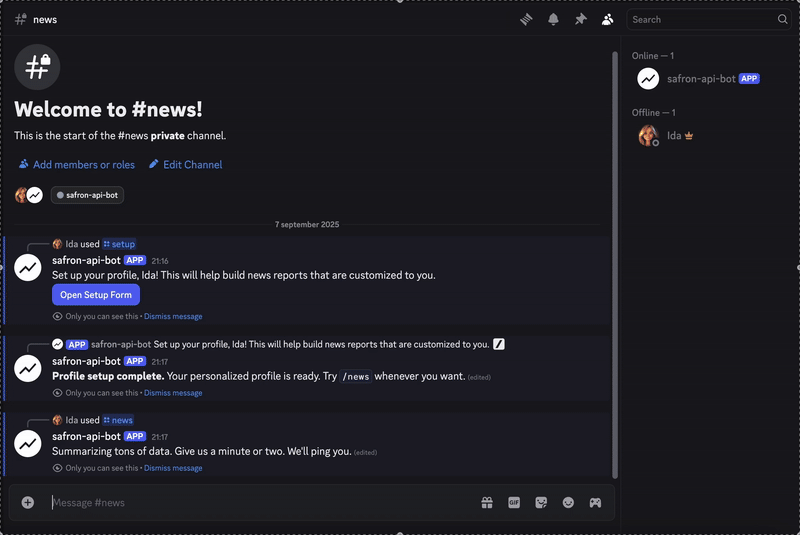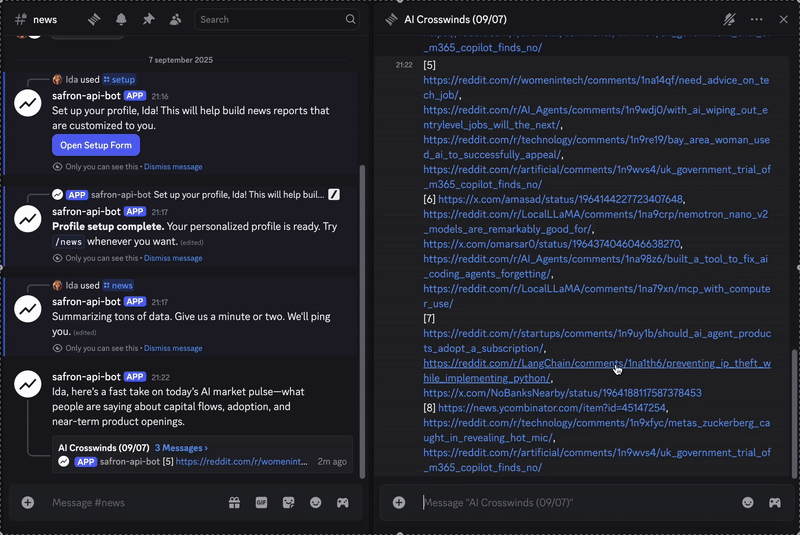
Wenn Sie sich den Code ansehen und diesen Bot selbst erstellen möchten, können Sie ihn finden Hier. Wenn Sie nur einen Bericht erstellen möchten, können Sie sich diesem anschließen Kanal.
Ich habe einige Pläne, es zu verbessern, aber ich freue mich, Suggestions zu hören, wenn Sie es nützlich finden.
Und wenn Sie eine Herausforderung wünschen, können Sie sie in etwas anderes umbauen, wie ein Inhaltsgenerator.
Anmerkungen zu Bauagenten
Jeder Agent, den Sie bauen, wird anders sein. Dies ist additionally keineswegs eine Blaupause für den Bau mit LLMs. Sie können jedoch das Maß an Software program -Engineering erkennen, das dieser Anforderungen annimmt.
LLMs entfernen zumindest vorerst die Notwendigkeit einer guten Software program- und Dateningenieure nicht.
Für diesen Workflow verwende ich hauptsächlich LLMs, um die natürliche Sprache in JSON zu übersetzen und das dann durch das System programmatisch zu bewegen. Es ist der einfachste Weg, den Agentenprozess zu kontrollieren, aber auch nicht das, was die Leute normalerweise vorstellen, wenn sie an AI -Anwendungen denken.
Es gibt Situationen, in denen es splendid ist, ein frei bewegenderes Agent zu verwenden, insbesondere wenn sich ein Mensch in der Schleife befindet.
Trotzdem haben Sie hoffentlich etwas gelernt oder Inspiration bekommen, etwas selbst zu bauen.
Wenn du meinem Schreiben folgen willst, folge mir hier, mein WebseiteAnwesend Substanzoder LinkedIn.
❤