von mir Maschinelles Lernen „Adventskalender“. Ich möchte Ihnen für Ihre Unterstützung danken.
Ich erstelle diese Google Sheet-Dateien seit Jahren. Sie entwickelten sich nach und nach. Aber wenn es Zeit ist, sie zu veröffentlichen, brauche ich immer Stunden, um alles neu zu ordnen, das Format zu bereinigen und sie angenehm lesbar zu machen.
Heute ziehen wir um DBSCAN.
DBSCAN lernt kein parametrisches Modell
Genau wie LOF ist DBSCAN nicht ein parametrisches Modell. Es gibt keine zu speichernde Formel, keine Regeln, keine Schwerpunkte und nichts Kompaktes, das später wiederverwendet werden könnte.
Wir müssen das behalten gesamter Datensatz denn die Dichtestruktur hängt von allen Punkten ab.
Sein vollständiger Identify ist Dichtebasiertes räumliches Clustering von Anwendungen mit Rauschen.
Aber Vorsicht: Diese „Dichte“ ist keine Gaußsche Dichte.
es ist ein zählbasiert Vorstellung von Dichte. Nur „wie viele Nachbarn wohnen in meiner Nähe“.
Warum DBSCAN etwas Besonderes ist
Wie der Identify schon sagt, ist dies bei DBSCAN der Fall zwei Dinge gleichzeitig:
- es findet Cluster
- es markiert Anomalien (die Punkte, die zu keinem Cluster gehören)
Genau aus diesem Grund stelle ich die Algorithmen in dieser Reihenfolge vor:
- okay-bedeutet Und GMM Sind Clustering-Modelle. Sie geben ein kompaktes Objekt aus: Schwerpunkte für k-Mittelwerte, Mittelwerte und Varianzen für GMM.
- Isolationswald Und LOF Sind reine Anomalieerkennungsmodelle. Ihr einziges Ziel ist es, ungewöhnliche Punkte zu finden.
- DBSCAN sitzt dazwischen. Es macht beides Clustering und Anomalieerkennungbasierend nur auf dem Begriff der Nachbarschaftsdichte.
Ein winziger Datensatz, um die Dinge intuitiv zu halten
Wir bleiben bei demselben winzigen Datensatz, den wir für LOF verwendet haben: 1, 2, 3, 7, 8, 12
Wenn Sie sich diese Zahlen ansehen, sehen Sie bereits zwei kompakte Gruppen:
einer in der Nähe 1–2–3noch einer in der Nähe 7–8Und 12 alleine leben.
DBSCAN fängt genau diese Instinct ein.
Zusammenfassung in 3 Schritten
DBSCAN fragt drei einfache Fragen für jeden Punkt:
- Wie viele Nachbarn haben Sie in einem kleinen Umkreis (eps)?
- Haben Sie genügend Nachbarn, um ein Kernpunkt (MinPts) zu werden?
- Wenn wir die Kernpunkte kennen, zu welcher verbundenen Gruppe gehören Sie?
Hier ist die Zusammenfassung des DBSCAN-Algorithmus in 3 Schritte:

Beginnen wir Schritt für Schritt.
DBSCAN in 3 Schritten
Nachdem wir nun die Idee von Dichte und Nachbarschaften verstanden haben, lässt sich DBSCAN sehr einfach beschreiben.
Alles, was der Algorithmus tut, passt hinein drei einfache Schritte.
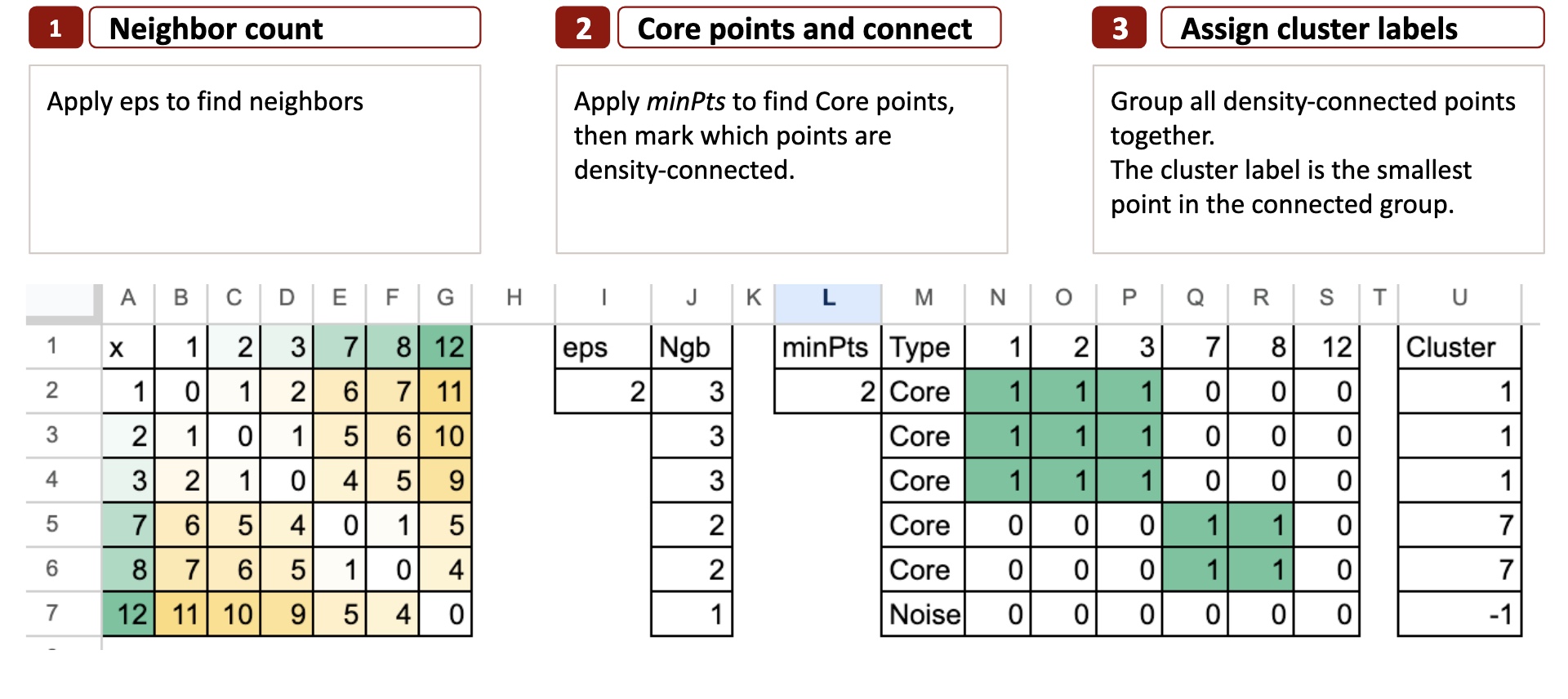
Schritt 1 – Zählen Sie die Nachbarn
Das Ziel besteht darin, zu überprüfen, wie viele Nachbarn jeder Punkt hat.
Wir nehmen einen kleinen Radius namens eps.
Für jeden Punkt schauen wir uns alle anderen Punkte an und markieren diejenigen, deren Abstand kleiner als eps ist.
Das sind die Nachbarn.
Dies gibt uns die erste Vorstellung von der Dichte:
ein Punkt mit vielen Nachbarn liegt in einer dichten Area,
Ein Punkt mit wenigen Nachbarn lebt in einer kargen Area.
Für ein eindimensionales Spielzeugbeispiel wie unseres ist eine häufige Wahl:
EPS = 2
Wir zeichnen um jeden Punkt ein kleines Intervall mit dem Radius 2.
Warum heißt es eps?
Der Identify eps kommt vom griechischen Buchstaben ε (Epsilon)das in der Mathematik traditionell zur Darstellung von a verwendet wird kleine Menge oder ein kleiner Radius um einen Punkt.
Additionally in DBSCAN, eps ist wörtlich „der kleine Nachbarschaftsradius“.
Es beantwortet die Frage:
Wie weit schauen wir uns an jedem Punkt um?
In Excel besteht der erste Schritt additionally darin, die zu berechnen Paarweise Distanzmatrixdann zählen Sie, wie viele Nachbarn jeder Punkt innerhalb von EPS hat.

Schritt 2 – Kernpunkte und Konnektivitätsdichte
Da wir nun die Nachbarn aus Schritt 1 kennen, bewerben wir uns minPt zu entscheiden, welche Punkte sind Kern.
minPts bedeutet hier Mindestpunktzahl.
Dies ist die kleinste Anzahl von Nachbarn, die ein Punkt haben muss (innerhalb des EPS-Radius), um als a zu gelten Kern Punkt.
Ein Punkt ist Kern, wenn er mindestens hat minPt Nachbarn drinnen eps.
Andernfalls kann es passieren Grenze oder Lärm.
Mit EPS = 2 Und minPts = 2wir haben 12, die nicht Core sind.
Sobald die Kernpunkte bekannt sind, prüfen wir einfach, um welche Punkte es sich handelt Dichte erreichbar von ihnen. Wenn ein Punkt durch die Bewegung von einem Kernpunkt zu einem anderen innerhalb von EPS erreicht werden kann, gehört er zur selben Gruppe.
In Excel können wir dies als einfache Konnektivitätstabelle darstellen, die zeigt, welche Punkte durch Kernnachbarn verbunden sind.
Diese Konnektivität wird von DBSCAN verwendet, um in Schritt 3 Cluster zu bilden.

Schritt 3 – Cluster-Beschriftungen zuweisen
Ziel ist es, Konnektivität in tatsächliche Cluster umzuwandeln.
Sobald die Konnektivitätsmatrix fertig ist, erscheinen die Cluster auf natürliche Weise.
DBSCAN gruppiert einfach alle verbundenen Punkte.
Um jeder Gruppe einen einfachen und reproduzierbaren Namen zu geben, verwenden wir eine sehr intuitive Regel:
Die Clusterbezeichnung ist der kleinste Punkt in der verbundenen Gruppe.
Zum Beispiel:
- Gruppe {1, 2, 3} wird zum Cluster 1
- Gruppe {7, 8} wird zu Cluster 7
- Ein Punkt wie 12 ohne Kernnachbarn wird Lärm
Genau das werden wir in Excel anhand von Formeln darstellen.

Letzte Gedanken
DBSCAN ist perfekt, um die Idee der lokalen Dichte zu vermitteln.
Es gibt keine Wahrscheinlichkeit, keine Gaußsche Formel, keinen Schätzschritt.
Nur Entfernungen, Nachbarn und ein kleiner Radius.
Aber diese Einfachheit schränkt es auch ein.
Da DBSCAN für alle einen festen Radius verwendet, kann es nicht angepasst werden, wenn der Datensatz Cluster unterschiedlicher Maßstäbe enthält.
HDBSCAN behält die gleiche Instinct bei, schaut aber auf alle Radien und hält, was stabil bleibt.
Es ist weitaus robuster und kommt der natürlichen Wahrnehmung von Clustern durch den Menschen viel näher.