Für SaaS-Unternehmen (Software program as a Service) ist die Überwachung und Verwaltung ihrer Produktdaten von entscheidender Bedeutung. Für diejenigen, die dies nicht verstehen, wenn sie einen Vorfall bemerken. Der Schaden ist bereits angerichtet. Für Unternehmen in Schwierigkeiten das kann tödlich sein.
Um dies zu verhindern, habe ich einen mit der Datenbank verknüpften n8n-Workflow erstellt, der die Daten täglich analysiert und erkennt, ob es einen Vorfall gibt. In diesem Fall wird ein Protokoll- und Benachrichtigungssystem so schnell wie möglich mit der Untersuchung beginnen. Außerdem habe ich ein Dashboard erstellt, damit das Workforce die Ergebnisse in Echtzeit sehen konnte.

Kontext
Eine auf Datenvisualisierung und automatisiertes Reporting spezialisierte B2B-SaaS-Plattform bedient rund 4500 Kunden, verteilt auf drei Segmente:
- Kleinunternehmen
- Mittelklasse
- Unternehmen
Die wöchentliche Produktnutzung übersteigt 30.000 aktive Konten mit starken Abhängigkeiten von Echtzeitdaten (Pipelines, APIs, Dashboards, Hintergrundjobs).
Das Produktteam arbeitet eng zusammen mit:
- Wachstum (Akquise, Aktivierung, Onboarding)
- Umsatz (Preisgestaltung, ARPU, Abwanderung)
- SRE/Infrastruktur (Zuverlässigkeit, Verfügbarkeit)
- Information Engineering (Pipelines, Datenaktualität)
- Assist und Kundenerfolg

Im vergangenen Jahr verzeichnete das Unternehmen eine steigende Zahl von Vorfällen. Zwischen Oktober und Dezember stieg die Gesamtzahl der Vorfälle von 250 auf 450 Steigerung um 80 %. Mit diesem Anstieg gab es mehr als 45 schwerwiegende und kritische Vorfälle, von denen Tausende von Benutzern betroffen waren. Die am stärksten betroffenen Kennzahlen waren:
- api_error_rate
- checkout_success_rate
- net_mrr_delta
- data_freshness_lag_minutes
- Abwanderungsrate

Wenn Vorfälle auftreten, a Unternehmen wird beurteilt von seinen Kunden basierend auf der Artwork und Weise, wie es damit umgeht und reagiert. Während die Das Produktteam wird geschätzt dafür, wie sie es geschafft und dafür gesorgt haben, dass so etwas nicht noch einmal passiert.
Ein einmaliger Vorfall kann passieren, aber ein zweimaliger Vorfall ist ein Fehler.
Auswirkungen auf das Geschäft
- Höhere Volatilität bei den wiederkehrenden Nettoumsätzen
- Ein auffälliges Rückgang der aktiven Konten über mehrere aufeinanderfolgende Wochen
- Mehrere Unternehmenskunden melden und beschweren sich über das veraltete Dashboard (mit einer Verspätung von mehr als 45 Minuten)

Insgesamt waren zwischen 30.000 und 60.000 Benutzer betroffen. Auch das Vertrauen der Kunden in die Produktzuverlässigkeit litt darunter. Unter den Nichtverlängerungen sind 45 % gaben an, dass dies ihr Hauptgrund sei.
Warum ist dieses Drawback kritisch?
Als Datenplattform kann sich das Unternehmen Folgendes nicht leisten:
- langsame oder veraltete Daten
- API-Fehler
- Pipeline-Ausfälle
- Verpasste oder verzögerte Synchronisierungen
- Ungenaues Dashboard
- Abwanderungen (Herabstufungen, Stornierungen)

Intern verteilten sich die Vorfälle auf mehrere Systeme:
- Ideen zur Produktverfolgung
- Slack für Benachrichtigungen
- PostgreSQL zur Speicherung
- Sogar auf Google Sheets für den Kundensupport

Es gab keine einzige Quelle der Wahrheit. Das Produktteam muss alle Daten manuell mit Querverweisen versehen und noch einmal überprüfen, nach Traits suchen und sie zusammensetzen. Es conflict eine Untersuchung und die Lösung eines Rätsels, wodurch sie jede Woche so viele Stunden verloren.
Lösung: Automatisierung einer Vorfallsystemwarnung mit N8N und Erstellung eines Daten-Dashboards. So werden Vorfälle erkannt, verfolgt, gelöst und verstanden.
Warum n8n?
Derzeit gibt es mehrere Automatisierungsplattformen und -lösungen. Aber nicht alle entsprechen den Bedürfnissen und Anforderungen. Es ist wichtig, je nach Bedarf das Richtige auszuwählen.
Die spezifischen Anforderungen bestanden darin, Zugriff auf eine Datenbank zu haben, ohne dass eine API erforderlich ist (n8n unterstützt API), visuelle Arbeitsabläufe und Knoten, die auch für technisch nicht versierte Personen verständlich sind, benutzerdefinierte codierte Knoten, selbst gehostete Optionen und kosteneffektive Skalierung. Unter den vorhandenen Plattformen wie Zapier, Make oder n8n fiel die Wahl additionally auf Letzteres.
Entwerfen des Product Well being Rating

Zunächst müssen die wichtigsten Kennzahlen ermittelt und berechnet werden.
Influence-Rating: einfache Funktion von Schweregrad + Delta + Benutzerskala
impact_score = (
severity_weights(severity) * 10
+ abs(delta_pct) * 0.8
+ np.log1p(affected_users)
)
impact_score = spherical(float(impact_score), 2)Priorität: abgeleitet aus Schweregrad + Auswirkung
if severity == "important" or impact_score > 60:
precedence = "P1"
elif severity == "excessive" or impact_score > 40:
precedence = "P2"
elif severity == "medium":
precedence = "P3"
else:
precedence = "P4"Produktgesundheitsbewertung
def compute_product_health_score(incidents, metrics):
"""
Rating = 100 - sum(penalties)
Manufacturing model handles 15+ elements
"""
# Key perception: penalties have totally different max weights
penalties = {
'quantity': min(40, incident_rate * 13), # 40% max
'severity': calculate_severity_sum(incidents), # 25% max
'customers': min(15, log(customers) / log(50000) * 15), # 15% max
'traits': calculate_business_trends(metrics) # 20% max
}
rating = 100 - sum(penalties.values())
if rating >= 80: return rating, "🟢 Steady"
elif rating >= 60: return rating, "🟡 Underneath watch"
else: return rating, "🔴 In danger"Entwerfen des automatisierten Erkennungssystems mit n8n

Dieses System besteht aus 4 Streams:
- Stream 1: Ruft aktuelle Umsatzkennzahlen ab, identifiziert ungewöhnliche Spitzen in der Abwanderungs-MRR und erstellt bei Bedarf Vorfälle.

const rows = objects.map(merchandise => merchandise.json);
if (rows.size < 8) {
return ();
}
rows.kind((a, b) => new Date(a.date) - new Date(b.date));
const values = rows.map(r => parseFloat(r.churn_mrr || 0));
const lastIndex = rows.size - 1;
const lastRow = rows(lastIndex);
const lastValue = values(lastIndex);
const window = 7;
const baselineValues = values.slice(lastIndex - window, lastIndex);
const imply = baselineValues.scale back((s, v) => s + v, 0) / baselineValues.size;
const variance = baselineValues
.map(v => Math.pow(v - imply, 2))
.scale back((s, v) => s + v, 0) / baselineValues.size;
const std = Math.sqrt(variance);
if (std === 0) {
return ();
}
const z = (lastValue - imply) / std;
const deltaPct = imply === 0 ? null : ((lastValue - imply) / imply) * 100;
if (z > 2) {
const anomaly = {
date: lastRow.date,
metric_name: 'churn_mrr',
baseline_value: imply,
actual_value: lastValue,
z_score: z,
delta_pct: deltaPct,
severity:
deltaPct !== null && deltaPct > 50 ? 'excessive'
: deltaPct !== null && deltaPct > 25 ? 'medium'
: 'low',
};
return ({ json: anomaly });
}
return ();- Stream 2: Monitore verfügen über Nutzungsmetriken, um plötzliche Rückgänge bei Akzeptanz oder Engagement zu erkennen.
Vorfälle werden mit Schweregrad, Kontext und Warnungen an das Produktteam protokolliert.

- Stream 3: Sammelt für jeden offenen Vorfall zusätzlichen Kontext aus der Datenbank (z. B. Abwanderung nach Land oder Plan), generiert mithilfe von KI eine klare Grundursachenhypothese und schlägt die nächsten Schritte vor, sendet einen zusammenfassenden Bericht an Slack und per E-Mail und aktualisiert den Vorfall

- Stream 4: Jeden Morgen fasst der Workflow alle Vorfälle des Vortages zusammen, erstellt eine Notion-Seite zur Dokumentation und sendet einen Bericht an das Führungsteam

Wir haben ähnliche Erkennungsknoten für 8 verschiedene Metriken eingesetzt und die Z-Rating-Richtung basierend darauf angepasst, ob Erhöhungen oder Verringerungen problematisch waren.
Der Der KI-Agent erhält zusätzlichen Kontext durch SQL-Abfragen (Abwanderung nach Land, nach Plan, nach Phase), um genauere Ursachenhypothesen zu generieren. Und all diese Daten werden täglich gesammelt und per E-Mail versendet.
Der Workflow generiert täglich zusammenfassende Berichte, in denen alle Vorfälle nach Metrik und Schweregrad zusammengefasst und per E-Mail und Slack an die Beteiligten verteilt werden.
Das Armaturenbrett
Das Dashboard konsolidiert alle Signale an einem Ort. Eine automatische Produktgesundheitsbewertung mit eine 0-100-Foundation berechnet sich mit:
- Vorfallvolumen
- Schweregradgewichtung
- Offener vs. gelöster Standing
- Anzahl der betroffenen Benutzer
- Geschäftstrends (MRR)
- Nutzungstrends (aktive Konten)
Eine Segmentaufschlüsselung, um zu ermitteln, welche Kundengruppen am stärksten betroffen sind:

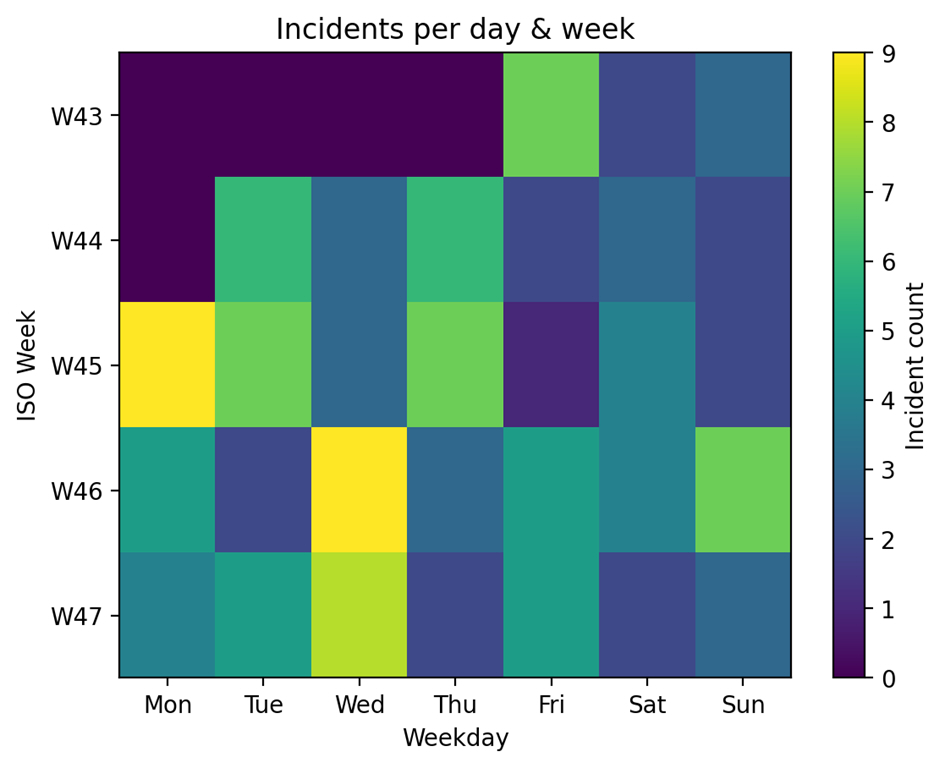
Eine wöchentliche Heatmap und Zeitreihen-Trenddiagramme zur Identifizierung wiederkehrender Muster:

Und eine detaillierte Vorfallansicht, zusammengestellt von:
- Geschäftskontext
- Dimension und Phase
- Grundursachenhypothese
- Artwork des Vorfalls
- Eine KI-Zusammenfassung zur Beschleunigung der Kommunikation und Diagnosen aus dem n8n-Workflow

Diagnose:
Der Produktgesundheitsscore vermerkt das tatsächliche Produkt 24/100 mit dem Standing „gefährdet“ mit:
- 45 Hohe und kritische Vorfälle
- 36 Vorfälle in den letzten 7 Tagen
- 33.385 geschätzte betroffene Benutzer. Negativer Development bei Abwanderung und DAU
- Mehrere Spitzen bei api_error_rate und Rückgänge bei checkout_success_rate

Größte Auswirkung professional Phase:
- Unternehmen → Kritische Probleme mit der Aktualität der Daten
- Mittelstand → wiederkehrende Vorfälle bei der Funktionseinführung
- KMU → Schwankungen bei Onboarding und Aktivierung

Auswirkungen
Das Ziel dieses Dashboards besteht nicht nur darin, Vorfälle zu analysieren und Muster zu erkennen, sondern der Organisation auch eine schnellere Reaktion mit einem detaillierten Überblick zu ermöglichen.

Uns ist ein aufgefallen 35 % Reduzierung kritischer Vorfälle nach 2 Monaten. Die SRE- und DATA-Groups identifizierten dank der einheitlichen Daten die wiederkehrende Grundursache einiger schwerwiegender Probleme und konnten diese beheben und die Wartung überwachen. Dank der KI-Zusammenfassungen und aller Metriken hat sich die Reaktionszeit bei Vorfällen erheblich verbessert, sodass sie wissen, wo Nachforschungen angestellt werden müssen.
Eine KI-gestützte Ursachenanalyse

Der Einsatz von KI kann viel Zeit sparen. Vor allem, wenn eine Untersuchung in verschiedenen Datenbanken erforderlich ist und Sie nicht wissen, wo Sie anfangen sollen. Das Hinzufügen eines KI-Agenten zur Schleife kann sparen Sie viel Zeit dank seiner Geschwindigkeit bei der Datenverarbeitung. Um dies zu erreichen, a detaillierte aufforderung ist notwendig, da der Agent einen Menschen ersetzen wird. Um möglichst genaue Ergebnisse zu erhalten, muss additionally auch die KI den Kontext verstehen und eine Anleitung erhalten. Andernfalls könnte es Nachforschungen anstellen und irrelevante Schlussfolgerungen ziehen. Vergessen Sie nicht Stellen Sie sicher, dass Sie die Ursache des Issues vollständig verstehen.
You're a Product Information & Income Analyst.
We detected an incident:
{{ $json.incident }}
Right here is churn MRR by nation (high offenders first):
{{ $json.churn_by_country }}
Right here is churn MRR by plan:
{{ $json.churn_by_plan }}
1. Summarize what occurred in easy enterprise language.
2. Establish essentially the most impacted segments (nation, plan).
3. Suggest 3-5 believable hypotheses (product points, value adjustments, bugs, market occasions).
4. Suggest 3 concrete subsequent steps for the Product staff.Es ist unbedingt zu beachten, dass nach Erhalt der Ergebnisse eine abschließende Kontrolle erforderlich ist, um sicherzustellen, dass die Analyse korrekt durchgeführt wurde. KI ist ein Werkzeug, Aber es kann auch schief gehen, additionally nicht nur darauf; Es ist ein hilfreiches Werkzeug. Für dieses System schlägt die KI vor Die drei wahrscheinlichsten Grundursachen für jeden Vorfall.

Eine bessere Abstimmung mit dem Führungsteam und eine datenbasierte Berichterstattung. Mit tiefergehenden Analysen wurde alles datengesteuerter, nicht mehr Instinct oder Berichte durch Segmentierung. Dies führte auch zu einem verbesserten Prozess.
Fazit und Erkenntnisse
Zusammenfassend lässt sich sagen, dass der Aufbau eines Produktgesundheits-Dashboards mehrere Vorteile hat:
- Erkennen Sie damaging Traits (MRR, DAU, Engagement) früher
- Reduzieren Sie kritische Vorfälle durch die Identifizierung von Grundursachenmustern
- Verstehen Sie die tatsächlichen Auswirkungen auf das Geschäft (betroffene Benutzer, Abwanderungsrisiko)
- Priorisieren Sie die Produkt-Roadmap basierend auf Risiko und Auswirkungen
- Richten Sie Produkte, Daten, SRE und Umsatz auf einer einzigen Informationsquelle aus
Genau das fehlt vielen Unternehmen: ein einheitlicher Datenansatz.

Der Einsatz des n8n-Workflows hat in zweierlei Hinsicht geholfen: Die Probleme konnten so schnell wie möglich gelöst werden und die Daten konnten an einem Ort gesammelt werden. Das Automatisierungstool trug dazu bei, den Zeitaufwand für diese Aufgabe zu reduzieren, da das Unternehmen noch im laufenden Betrieb conflict.
Lektionen für Produktteams

- Fangen Sie einfach an: Der Aufbau eines Automatisierungssystems und eines Dashboards muss klar definiert sein. Sie erstellen kein Produkt für die Kunden, sondern ein Produkt für Ihre Mitarbeiter. Es ist wichtig, dass Sie die Bedürfnisse jedes Groups verstehen, da es Ihre Hauptbenutzer sind. Halten Sie sich vor diesem Hintergrund zunächst an das Produkt, das Ihr MVP sein und alle Ihre Anforderungen erfüllen wird. Dann können Sie es verbessern, indem Sie Funktionen oder Metriken hinzufügen.
- Einheitliche Kennzahlen sind wichtiger als eine perfekte Erkennung: Wir müssen bedenken, dass ihnen nicht nur die Zeitersparnis, sondern auch das Verständnis zu verdanken ist. Eine gute Erkennung ist unerlässlich, aber wenn die Metriken ungenau sind, wird die eingesparte Zeit dadurch verschwendet, dass die Groups nach den Metriken suchen, die über verschiedene Umgebungen verteilt sind
- Automatisierung spart 10 Stunden professional Woche der manuellen Untersuchung: Durch die Automatisierung einiger manueller und wiederkehrender Aufgaben sparen Sie Stunden bei der Untersuchung, da wir beim Workflow für Vorfallwarnungen direkt wissen, wo wir zuerst nachforschen müssen, welche Hypothese die Ursache hat und welche Maßnahmen wir ergreifen müssen.
- Dokumentieren Sie alles: Eine ordnungsgemäße und detaillierte Dokumentation ist ein Muss und ermöglicht allen Beteiligten ein klares Verständnis und eine klare Sicht auf das Geschehen. Auch die Dokumentation ist ein Datenelement.
Wer bin ich?
Ich bin Yassin, ein Projektmanager, der sich auf Information Science spezialisiert hat, um die Lücke zwischen Geschäftsentscheidungen und technischen Systemen zu schließen. Das Erlernen von Python, SQL und Analytics hat es mir ermöglicht, Produkterkenntnisse und Automatisierungsworkflows zu entwerfen, die die Anforderungen der Groups mit dem Verhalten der Daten verbinden. Lasst uns weitermachen Linkedin