Einführung
Mein vorherige Beiträge schaute auf den Moor-Commonplace-Entscheidungsbaum und das Wunder eines zufälligen Waldes. Um das Triplett zu vervollständigen, werde ich visuell erforschen!
Es gibt eine Reihe von Gradienten -steigerten Baumbibliotheken, darunter Xgboost, Catboost und LightGBM. Dafür werde ich jedoch Sklearns verwenden. Warum? Einfach, weil ich im Vergleich zu den anderen leichter visualisieren konnte. In der Praxis neige ich dazu, die anderen Bibliotheken mehr als die Sklearn zu verwenden; In diesem Projekt geht es jedoch um visuelles Lernen, nicht um reine Leistung.
Grundsätzlich ist eine GBT eine Kombination von Bäumen, die nur zusammenarbeiten. Während ein einzelner Entscheidungsbaum (einschließlich eines aus einem zufälligen Wald) eine anständige Vorhersage für sich selbst machen kann, ist es unwahrscheinlich, dass ein einzelner Baum aus einem GBT etwas Nutzbares gibt.
Darüber hinaus wie immer keine Theorie, keine Mathematik – nur Handlungen und Hyperparameter. Ich werde nach wie vor das California Housing Dataset über Scikit-Study (CC-by) verwenden, dem gleichen allgemeinen Prozess wie in meinen vorherigen Beiträgen beschrieben, der Code ist bei https://github.com/jamesdeluk/data-projects/tree/primary/visualising- bushesund alle Bilder unten werden von mir erstellt (abgesehen von der GIF, die von stammt aus Tenor).
Ein grundlegender Gradienten steigerter Baum
Beginnend mit einem grundlegenden GBT: gb = GradientBoostingRegressor(random_state=42). Ähnlich wie bei anderen Baumtypen die Standardeinstellungen für min_samples_splitAnwesend min_samples_leafAnwesend max_leaf_nodes sind 2, 1, None jeweils. Interessanterweise der Commonplace max_depth ist 3, nicht None Wie bei Entscheidungsbäumen/zufälligen Wäldern. Bemerkenswerte Hyperparameter, die ich später mehr prüfen werde learning_rate (Wie steil der Gradient ist, Commonplace 0,1) und n_estimators (Ähnlich wie der zufällige Wald – die Anzahl der Bäume).
Die Anpassung dauerte 2,2 Sekunden, die Vorhersage dauerte 0,005s und die Ergebnisse:
| Metrisch | max_depth = keine |
|---|---|
| Mae | 0,369 |
| Mape | 0,216 |
| MSE | 0,289 |
| Rmse | 0,538 |
| R² | 0,779 |
Additionally schneller als der Commonplace -Zufallswald, aber etwas schlechtere Leistung. Für meinen gewählten Block prognostizierte es 0,803 (tatsächlich 0,894).
Visualisierung
Deshalb bist du hier, oder?
Der Baum
Ähnlich wie zuvor können wir einen einzelnen Baum zeichnen. Dies ist der erste, auf das zugegriffen wird gb.estimators_(0, 0):

Ich habe diese in den vorherigen Beiträgen erklärt, additionally werde ich es hier nicht wieder tun. Eine Sache, die ich Ihnen jedoch aufmerksam machen werde: Beachten Sie, wie schrecklich die Werte sind! Drei der Blätter haben sogar unfavorable Werte, von denen wir wissen, dass sie nicht der Fall sein können. Aus diesem Grund arbeitet ein GBT nur als kombiniertes Ensemble, nicht als getrennte eigenständige Bäume wie in einem zufälligen Wald.
Vorhersagen und Fehler
Meine bevorzugte Möglichkeit, GBTs zu visualisieren gb.staged_predict. Für meinen gewählten Block:

Erinnern Sie sich an das Standardmodell haben 100 Schätzer? Nun, hier sind sie. Die anfängliche Vorhersage struggle weit weg – 2! Aber jedes Mal, wenn es lernte (erinnere dich learning_rate?) Und kam dem wahren Wert näher. Natürlich wurde es in den Trainingsdaten geschult, nicht in diesen spezifischen Daten, sodass der Endwert ausgeschaltet struggle (0,803, additionally etwa 10% Rabatt), aber Sie können den Prozess deutlich sehen.
In diesem Fall erreichte es nach etwa 50 Iterationen einen ziemlich stabilen Zustand. Später werden wir sehen, wie man in dieser Section aufhört, die Iterierung zu vermeiden, um Zeit und Geld zu verschwenden.
In ähnlicher Weise kann der Fehler (dh die Vorhersage abzüglich des wahren Wertes) aufgetragen werden. Dies gibt uns natürlich das gleiche Diagramm, einfach mit unterschiedlichen Y-Achse-Werten:

Gehen wir einen Schritt weiter! Die Testdaten haben über 5000 Blöcke vorherzusagen. Wir können jeweils für jede Iteration alle durchlaufen und sie alle vorhersagen!

Ich liebe diese Handlung.

Sie alle beginnen um 2, explodieren aber über die Iterationen. Wir wissen Erster Beitrag), so dass sich dies aus Vorhersagen (von ~ 0,3 bis ~ 5,5) ausbreitet.
Wir können auch die Fehler zeichnen:

Auf den ersten Blick scheint es ein bisschen seltsam zu sein-wir würden erwarten, dass sie beispielsweise bei ± 2 und auf 0 konvergieren. Sehen Sie sich jedoch vorsichtig an-dies geschieht für die meisten-es ist auf der linken Seite der Handlung, den ersten 10 Iterationen oder so zu sehen. Das Drawback ist, dass es bei über 5000 Zeilen auf diesem Grundstück viele überlappende Überlappungen gibt, sodass die Ausreißer sich mehr herausheben lassen. Vielleicht gibt es eine bessere Möglichkeit, diese zu visualisieren? Wie wäre es mit …

Der mediane Fehler beträgt 0,05 – was sehr intestine ist! Der IQR ist weniger als 0,5, was ebenfalls anständig ist. Obwohl es einige schreckliche Vorhersagen gibt, sind die meisten anständig.
Hyperparameterabstimmung
Entscheidungsbaum -Hyperparameter
Wie zuvor vergleichen wir, wie die Hyperparameter im ursprünglichen Entscheidungsbaumposten mit den Standardhyperparametern von GBTs gelten learning_rate = 0.1, n_estimators = 100. Der min_samples_leafAnwesend min_samples_splitUnd max_leaf_nodes Einer hat auch max_depth = 10um es zu einem fairen Vergleich mit früheren Beiträgen und miteinander zu machen.
| Modell | max_depth = keine | max_depth = 10 | min_samples_leaf = 10 | min_samples_split = 10 | max_leaf_nodes = 100 |
|---|---|---|---|---|---|
| Passzeit (en) | 10.889 | 7.009 | 7.101 | 7.015 | 6.167 |
| Zeit (en) vorhersagen | 0,089 | 0,019 | 0,015 | 0,018 | 0,013 |
| Mae | 0,454 | 0,304 | 0,301 | 0,302 | 0,301 |
| Mape | 0,253 | 0,177 | 0,174 | 0,174 | 0,175 |
| MSE | 0,496 | 0,222 | 0,212 | 0,217 | 0,210 |
| Rmse | 0,704 | 0,471 | 0,46 | 0,466 | 0,458 |
| R² | 0,621 | 0,830 | 0,838 | 0,834 | 0,840 |
| Ausgewählte Vorhersage | 0,885 | 0,906 | 0,962 | 0,918 | 0,923 |
| Ausgewählter Fehler | 0,009 | 0,012 | 0,068 | 0,024 | 0,029 |
Im Gegensatz zu Entscheidungsbäumen und zufälligen Wäldern erzielte der tiefere Baum weitaus schlechter! Und dauerte länger, um zu passen. Das Erhöhen der Tiefe von 3 (der Commonplace) auf 10 hat die Ergebnisse verbessert. Die anderen Einschränkungen führten zu weiteren Verbesserungen und zeigten erneut, wie alle Hyperparameter eine Rolle spielen können.
Learning_rate
GBTs arbeiten nach Vorhersagen nach jeder Iteration basierend auf dem Fehler. Je höher die Anpassung (auch bekannt als der Gradient, auch bekannt als die Lernrate), desto mehr ändert sich die Vorhersage zwischen Iterationen.
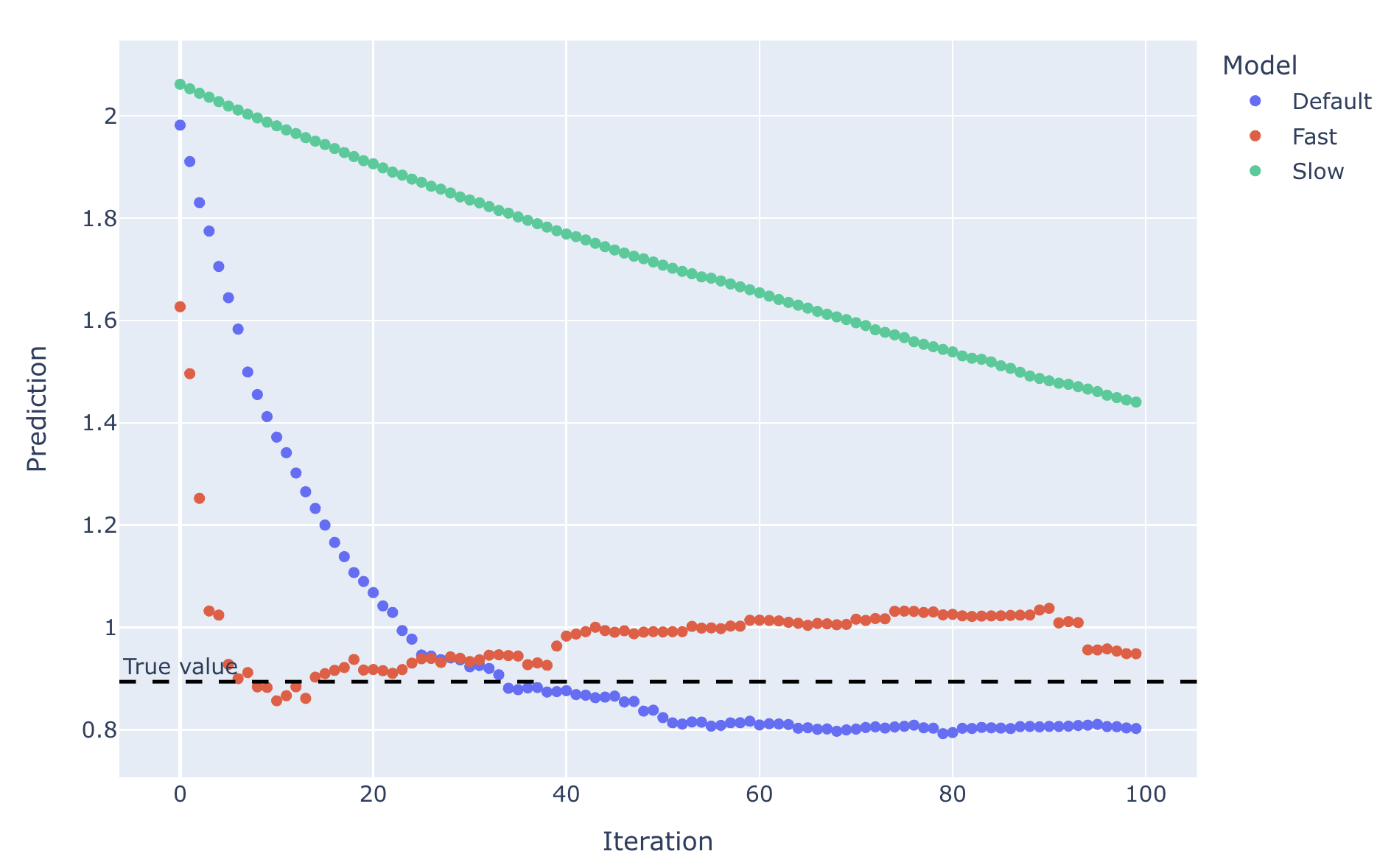
Es gibt einen klaren Kompromiss für die Lernrate. Vergleich der Lernraten von 0,01 (langsam), 0,1 (Commonplace) und 0,5 (schnell) über 100 Iterationen:

Eine schnellere Lernraten können schneller zum richtigen Wert erreichen, aber es ist wahrscheinlicher, dass sie über Korrorie und über den wahren Wert hinausgehen (denken Sie an Fischschwanz in einem Auto) und können zu Oszillationen führen. Langsame Lernraten erreichen möglicherweise nie den richtigen Wert (denken Sie daran, das Lenkrad nicht genug zu drehen und direkt in einen Baum zu fahren). Wie für die Statistiken:
| Modell | Commonplace | Schnell | Langsam |
|---|---|---|---|
| Passzeit (en) | 2.159 | 2.288 | 2.166 |
| Zeit (en) vorhersagen | 0,005 | 0,004 | 0,015 |
| Mae | 0,370 | 0,338 | 0,629 |
| Mape | 0,216 | 0,197 | 0,427 |
| MSE | 0,289 | 0,247 | 0,661 |
| Rmse | 0,538 | 0,497 | 0,813 |
| R² | 0,779 | 0,811 | 0,495 |
| Ausgewählte Vorhersage | 0,803 | 0,949 | 1.44 |
| Ausgewählter Fehler | 0,091 | 0,055 | 0,546 |
Es überrascht nicht, dass das langsame Lernmodell schrecklich struggle. Für diesen Block struggle Quick etwas besser als der Commonplace insgesamt. Wir können jedoch auf der Handlung sehen, wie zumindest für den gewählten Block die letzten 90 Iterationen waren, die das schnelle Modell genauer als das Commonplace -Einstellungsmodell hatten – wenn wir bei 40 Iterationen angehalten hätten, wäre das Standardmodell zumindest für den ausgewählten Block weitaus besser gewesen. Die Freuden der Visualisierung!
n_estimatoren
Wie oben erwähnt, geht die Anzahl der Schätzer Hand in Hand mit der Lernrate. Im AllgemeinenJe mehr Schätzer desto besser, da es mehr Iterationen zum Messen und Anpassung des Fehlers bietet – obwohl dies zu einem zusätzlichen Zeitkosten kommt.
Wie oben zu sehen, ist eine ausreichend hohe Anzahl von Schätzern für eine niedrige Lernrate besonders wichtig, um sicherzustellen, dass der richtige Wert erreicht wird. Erhöhung der Anzahl der Schätzer auf 500:

Mit genügend Iterationen erreichte der langsame Lernen GBT den wahren Wert. Tatsächlich kamen sie alle viel näher. Die Statistiken bestätigen dies:
| Modell | Defaultmore | Fastmore | Slowmore |
|---|---|---|---|
| Passzeit (en) | 12.254 | 12.489 | 11.918 |
| Zeit (en) vorhersagen | 0,018 | 0,014 | 0,022 |
| Mae | 0,323 | 0,319 | 0,410 |
| Mape | 0,187 | 0,185 | 0,248 |
| MSE | 0,232 | 0,228 | 0,338 |
| Rmse | 0,482 | 0,477 | 0,581 |
| R² | 0,823 | 0,826 | 0,742 |
| Ausgewählte Vorhersage | 0,841 | 0,921 | 0,858 |
| Ausgewählter Fehler | 0,053 | 0,027 | 0,036 |
Es ist nicht überraschend, dass die Anzahl der Schätzer die Anzahl der Schätzer um das Fünffache erhöhte, die Zeit auf signifikant passen (in diesem Fall um das sechsfache, aber das kann nur ein einmaliges sein). Wir haben jedoch die Punktzahlen der beschränkten Bäume oben noch nicht übertroffen – ich denke, wir müssen eine Hyperparameter -Suche durchführen, um zu sehen, ob wir sie schlagen können. Auch für den gewählten Block, wie in der Handlung zu sehen ist, hat sich nach etwa 300 Iterationen keine der Modelle wirklich verbessert. Wenn dies in allen Daten konsistent ist, waren die zusätzlichen 700 Iterationen nicht erforderlich. Ich habe früher erwähnt, wie es möglich ist, keine Zeit zu verschwenden, ohne sich zu verbessern. Jetzt ist es an der Zeit, das zu prüfen.
n_iter_no_change, validation_fraction und tol
Es ist möglich, dass zusätzliche Iterationen das Endergebnis nicht verbessern, aber es braucht noch Zeit, um sie zu betreiben. Hier kommt frühes Stopp ins Spiel.
Es gibt drei relevante Hyperparameter. Der erste, n_iter_no_changeist, wie viele Iterationen es für „keine Veränderung“ gibt, bevor keine Iterationen mehr durchgeführt werden. tol(Erance) ist, wie groß die Änderung der Validierungsbewertung als „keine Änderung“ klassifiziert werden sollte. Und validation_fraction ist, wie viel der Trainingsdaten als Validierungssatz verwendet werden soll, um die Validierungsbewertung zu generieren (beachten Sie, dass dies von den Testdaten getrennt ist).
Vergleich eines 1000-Schätzungs-GBT mit einem mit einem ziemlich aggressiven frühen Stopp- n_iter_no_change=5, validation_fraction=0.1, tol=0.005 – Letzterer hörte nach nur 61 Schätzern auf (und dauerte daher nur 5 ~ 6% der Zeit):

Wie erwartet waren die Ergebnisse jedoch schlechter:
| Modell | Commonplace | Früh aufhalten |
|---|---|---|
| Passzeit (en) | 24.843 | 1.304 |
| Zeit (en) vorhersagen | 0,042 | 0,003 |
| Mae | 0,313 | 0,396 |
| Mape | 0,181 | 0,236 |
| MSE | 0,222 | 0,321 |
| Rmse | 0,471 | 0,566 |
| R² | 0,830 | 0,755 |
| Ausgewählte Vorhersage | 0,837 | 0,805 |
| Ausgewählter Fehler | 0,057 | 0,089 |
Aber wie immer, die Frage zu stellen: Lohnt es sich, die Zeit zu investieren, um die Riode um 10percentzu verbessern oder den Fehler um 20percentzu verringern?
Bayes -Suche
Sie haben das wahrscheinlich erwartet. Die Suchräume:
search_spaces = {
'learning_rate': (0.01, 0.5),
'max_depth': (1, 100),
'max_features': (0.1, 1.0, 'uniform'),
'max_leaf_nodes': (2, 20000),
'min_samples_leaf': (1, 100),
'min_samples_split': (2, 100),
'n_estimators': (50, 1000),
}Die meisten ähneln meinen vorherigen Beiträgen; Der einzige zusätzliche Hyperparameter ist learning_rate.
Es dauerte bisher am längsten bei 96 Minuten (~ 50% mehr als der zufällige Wald!). Die besten Hyperparameter sind:
best_parameters = OrderedDict({
'learning_rate': 0.04345459461297153,
'max_depth': 13,
'max_features': 0.4993693929975871,
'max_leaf_nodes': 20000,
'min_samples_leaf': 1,
'min_samples_split': 83,
'n_estimators': 325,
})max_featuresAnwesend max_leaf_nodesUnd min_samples_leafsind dem abgestimmten Zufallswald sehr ähnlich. n_estimators ist auch, und es richtet sich an das, was das gewählte Blockdiagramm vorgeschlagen hat – die zusätzlichen 700 Iterationen waren meist unnötig. Im Vergleich zum abgestimmten Zufallswald sind die Bäume jedoch nur ein Drittel so tief und min_samples_split ist weit höher als wir bisher gesehen haben. Der Wert von learning_rate struggle nicht allzu überraschend, basierend auf dem, was wir oben gesehen haben.
Und die quervalidierten Ergebnisse:
| Metrisch | Bedeuten | Std |
|---|---|---|
| Mae | -0.289 | 0,005 |
| Mape | -0.161 | 0,004 |
| MSE | -0.200 | 0,008 |
| Rmse | -0.448 | 0,009 |
| R² | 0,849 | 0,006 |
Von allen bisherigen Modellen ist dies die beste, mit kleineren Fehlern, höherem R² und niedrigeren Abweichungen!
Schließlich ist unser alter Freund, die Field, plant:

Abschluss
Und so kommen wir an den drei häufigsten Arten von baumbasierten Modellen am Ende meiner Mini-Serie.
Ich hoffe, dass Sie jetzt besser verstehen, wie die verschiedenen Modelle funktionieren, ohne die Gleichungen betrachten zu müssen, und (b) Ihre eigenen Diagramme verwenden, um Ihre eigenen Modelle zu stimmen, wenn Sie verschiedene Möglichkeiten zur Visualisierung von Bäumen sehen. Es kann auch beim Stakeholder -Administration helfen – Führungskräfte bevorzugen hübsche Bilder zu Zahlenzahlen. Wenn Sie ihnen additionally eine Baumhandlung zeigen, können Sie verstehen, warum das, was sie Sie bitten, unmöglich ist.
Basierend auf diesem Datensatz und diesen Modellen steigerte der Gradient dem zufälligen Wald etwas überlegen und beide waren einem einzigen Entscheidungsbaum weit überlegen. Dies magazine jedoch daran gelangen, dass die GBT 50% mehr Zeit hatte, um nach besseren Hyperparametern zu suchen (sie sind normalerweise rechenintensiver – schließlich waren es die gleiche Anzahl von Iterationen). Es ist auch erwähnenswert, dass GBTs eine höhere Tendenz haben, zu überwältigen als zufällige Wälder. Und während der Entscheidungsbaum eine schlechtere Leistung hatte, ist es dies weit schneller – und in einigen Anwendungsfällen ist dies wichtiger. Wie bereits erwähnt, gibt es auch andere Bibliotheken mit Vor- und Nachteilen-beispielsweise verhandelt Catboost kategoriale Daten außerhalb des Field, während andere GBT-Bibliotheken in der Regel kategoriale Daten vorverarbeitet werden müssen (z. B. One-HOT- oder Kennzeichnungscodierung). Oder wenn Sie sich wirklich mutig fühlen, wie wäre es, die verschiedenen Baumtypen in einem Ensemble zu stapeln, um noch bessere Leistung zu erzielen?
Wie auch immer, bis zum nächsten Mal!