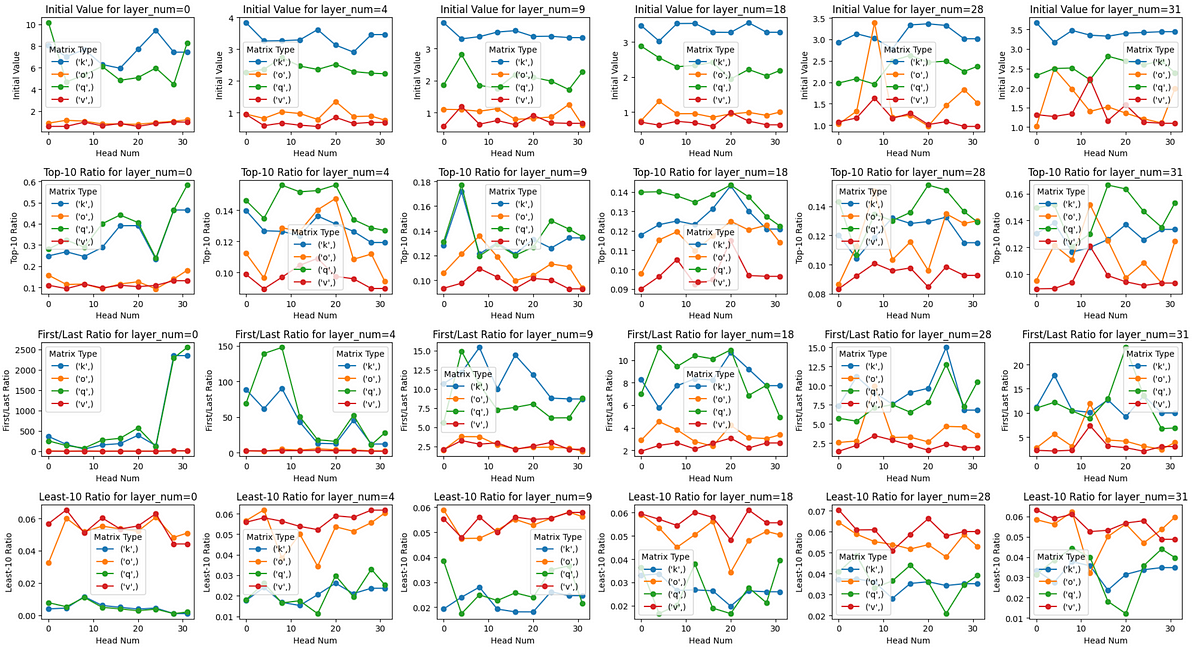
Kommen wir nun zum eigentlichen Thema dieses Artikels. Analysieren der (Q, Okay, V, O)-Matrizen des Llama-3–8B-Instruct-Modells anhand ihrer singulären Werte!
Der Code
Lassen Sie uns zunächst alle für diese Analyse benötigten Pakete importieren.
import transformers
import torch
import numpy as np
from transformers import AutoConfig, LlamaModel
from safetensors import safe_open
import os
import matplotlib.pyplot as plt
Dann laden wir das Modell herunter und speichern es in unserem lokalen /tmpVerzeichnis.
MODEL_ID = "meta-llama/Meta-Llama-3-8B-Instruct"
!huggingface-cli obtain {MODEL_ID} --quiet --local-dir /tmp/{MODEL_ID}
Wenn Sie über viele GPUs verfügen, ist der folgende Code für Sie möglicherweise nicht related. Wenn Sie jedoch wie ich nur über wenige GPUs verfügen, ist der folgende Code sehr nützlich, um nur bestimmte Ebenen des LLama-3–8B-Modells zu laden.
def load_specific_layers_safetensors(mannequin, model_name, layer_to_load):
state_dict = {}
recordsdata = (f for f in os.listdir(model_name) if f.endswith('.safetensors'))
for file in recordsdata:
filepath = os.path.be a part of(model_name, file)
with safe_open(filepath, framework="pt") as f:
for key in f.keys():
if f"layers.{layer_to_load}." in key:
new_key = key.exchange(f"mannequin.layers.{layer_to_load}.", 'layers.0.')
state_dict(new_key) = f.get_tensor(key)missing_keys, unexpected_keys = mannequin.load_state_dict(state_dict, strict=False)
if missing_keys:
print(f"Lacking keys: {missing_keys}")
if unexpected_keys:
print(f"Surprising keys: {unexpected_keys}")
Der Grund dafür ist, dass die kostenlose Stufe der Google Colab GPU nicht ausreicht, um LLama-3–8B zu laden, selbst mit fp16 Präzision. Darüber hinaus erfordert diese Analyse die Arbeit an fp32 Präzision durch die Artwork und Weise, wie die np.linalg.svd aufgebaut ist. Als nächstes können wir die Hauptfunktion definieren, um singuläre Werte für eine gegebene matrix_type , layer_number Und head_number.
def get_singular_values(model_path, matrix_type, layer_number, head_number):
"""
Computes the singular values of the desired matrix within the Llama-3 mannequin.Parameters:
model_path (str): Path to the mannequin
matrix_type (str): Kind of matrix ('q', 'ok', 'v', 'o')
layer_number (int): Layer quantity (0 to 31)
head_number (int): Head quantity (0 to 31)
Returns:
np.array: Array of singular values
"""
assert matrix_type in ('q', 'ok', 'v', 'o'), "Invalid matrix sort"
assert 0 <= layer_number < 32, "Invalid layer quantity"
assert 0 <= head_number < 32, "Invalid head quantity"
# Load the mannequin just for that particular layer since we have now restricted RAM even after utilizing fp16
config = AutoConfig.from_pretrained(model_path)
config.num_hidden_layers = 1
mannequin = LlamaModel(config)
load_specific_layers_safetensors(mannequin, model_path, layer_number)
# Entry the desired layer
# All the time index 0 since we have now loaded for the particular layer
layer = mannequin.layers(0)
# Decide the dimensions of every head
num_heads = layer.self_attn.num_heads
head_dim = layer.self_attn.head_dim
# Entry the desired matrix
weight_matrix = getattr(layer.self_attn, f"{matrix_type}_proj").weight.detach().numpy()
if matrix_type in ('q','o'):
begin = head_number * head_dim
finish = (head_number + 1) * head_dim
else: # 'ok', 'v' matrices
# Regulate the head_number primarily based on num_key_value_heads
# That is accomplished since llama3-8b use Grouped Question Consideration
num_key_value_groups = num_heads // config.num_key_value_heads
head_number_kv = head_number // num_key_value_groups
begin = head_number_kv * head_dim
finish = (head_number_kv + 1) * head_dim
# Extract the weights for the desired head
if matrix_type in ('q', 'ok', 'v'):
weight_matrix = weight_matrix(begin:finish, :)
else: # 'o' matrix
weight_matrix = weight_matrix(:, begin:finish)
# Compute singular values
singular_values = np.linalg.svd(weight_matrix, compute_uv=False)
del mannequin, config
return record(singular_values)
Es ist erwähnenswert, dass wir die Gewichte für den angegebenen Kopf auf den Okay-, Q- und V-Matrizen durch zeilenweises Aufteilen extrahieren können, da dies implementiert wird durch Umarmendes Gesicht.

(d_out,d_in). Quelle: Bild vom Autor.Was die O-Matrix betrifft, können wir dank der linearen Algebra eine spaltenweise Aufteilung durchführen, um die Gewichte für den angegebenen Kopf des O-Gewichts zu extrahieren! Einzelheiten sind in der folgenden Abbildung zu sehen.
