Normalerweise beginnt es auf die gleiche Weise. In einer Führungsbesprechung sagt jemand: „Lasst uns KI nutzen!“ Köpfe nicken, Begeisterung steigt, und bevor Sie es merken, landet der Raum bei der Normal-Schlussfolgerung: „Klar – wir bauen einen Chatbot.“ Dieser Instinkt ist verständlich. Große Sprachmodelle sind mächtig, allgegenwärtig und faszinierend. Sie versprechen einen intuitiven Zugang zu universellem Wissen und Funktionalität.
Das Group geht weg und beginnt mit dem Aufbau. Bald kommt die Demo-Zeit. Es erscheint eine ausgefeilte Chat-Oberfläche, begleitet von selbstbewussten Argumenten darüber, warum es dieses Mal anders sein wird. Zu diesem Zeitpunkt hat es jedoch in der Regel noch nicht die tatsächlichen Benutzer in realen Situationen erreicht, und die Bewertung ist voreingenommen und optimistisch. Jemand im Publikum stellt unweigerlich eine individuelle Frage, was den Bot irritiert. Die Entwickler versprechen, „das Downside“ zu beheben, aber in den meisten Fällen ist das zugrunde liegende Downside systemischer Natur.
Sobald der Chatbot auf den Markt kommt, geht der anfängliche Optimismus oft mit Frustration der Benutzer einher. Hier wird es etwas persönlicher, da ich in den letzten Wochen gezwungen conflict, einige Zeit damit zu verbringen, mit verschiedenen Chatbots zu sprechen. Ich neige dazu, die Interaktion mit Dienstleistern zu verzögern, bis die State of affairs unhaltbar wird und sich einige dieser Fälle gehäuft haben. Lächelnde Chatbot-Widgets waren meine letzte Hoffnung vor einem ewigen Hotline-Anruf, aber:
- Nachdem ich mich auf der Web site meines Autoversicherers angemeldet hatte, bat ich darum, eine unangekündigte Preiserhöhung zu erklären, musste jedoch feststellen, dass der Chatbot keinen Zugriff auf meine Preisdaten hatte. Alles, was es anbieten konnte, conflict die Hotline-Nummer. Autsch.
- Nachdem ein Flug in letzter Minute annulliert wurde, fragte ich den Chatbot der Fluggesellschaft nach dem Grund. Es entschuldigte sich höflich dafür, dass es mir nicht weiterhelfen könne, da die Abfahrtszeit bereits in der Vergangenheit liege. Es conflict jedoch offen, alle anderen Themen zu besprechen.
- Auf einer Telekommunikationsseite fragte ich, warum mein Mobilfunktarif plötzlich abgelaufen sei. Der Chatbot antwortete selbstbewusst, dass er sich zu Vertragsangelegenheiten nicht äußern könne und verwies mich auf die FAQs. Wie erwartet waren diese lang, aber irrelevant.
Diese Interaktionen brachten mich einer Lösung nicht näher und ließen mich am anderen Ende der Freude zurück. Die Chatbots fühlten sich wie Fremdkörper an. Während sie dort saßen, verbrauchten sie Platz, Latenz und Aufmerksamkeit, brachten aber keinen Mehrwert.
Lassen wir die Debatte darüber, ob es sich hierbei um absichtliche dunkle Muster handelt, überspringen. Tatsache ist, dass Legacy-Systeme wie die oben genannten eine schwere Entropielast tragen. Sie verfügen über eine Menge einzigartiger Daten, Kenntnisse und Zusammenhänge. Sobald Sie versuchen, sie in ein allgemeines LLM zu integrieren, prallen zwei Welten aufeinander. Das Modell muss den Kontext Ihres Produkts erfassen, damit es sinnvolle Aussagen zu Ihrer Area treffen kann. Eine ordnungsgemäße Kontextentwicklung erfordert Geschick und Zeit für eine kontinuierliche Bewertung und Iteration. Und bevor Sie überhaupt an diesen Punkt gelangen, müssen Ihre Daten bereit sein, aber in den meisten Organisationen sind die Daten verrauscht, fragmentiert oder fehlen einfach.
In diesem Beitrag fasse ich die Erkenntnisse aus meinem Buch zusammen Die Kunst der KI-Produktentwicklung und mein letzter Vortrag im Google Internet AI Summit und teilen Sie einen organischeren, inkrementellen Ansatz zur Integration von KI in bestehende Produkte.
Verwendung kleinerer Modelle für eine risikoarme, inkrementelle KI-Integration
„Ich sehe bei der Implementierung von KI mehr Unternehmen, die scheitern, weil sie zu groß anfangen, als wenn sie zu klein anfangen.“ ( Andrew Ng).
KI-Integration braucht Zeit:
- Ihr technisches Group muss die Daten vorbereiten und die verfügbaren Techniken und Instruments erlernen.
- Sie müssen Prototypen erstellen und iterieren, um den optimalen KI-Wert in Ihrem Produkt und Markt zu finden.
- Benutzer müssen ihr Vertrauen kalibrieren, wenn sie zu neuen probabilistischen Erfahrungen wechseln.
Um sich an diese Lernkurven anzupassen, sollten Sie Ihren Benutzern nicht voreilig KI – insbesondere die offene Chat-Funktionalität – zur Verfügung stellen. KI bringt Unsicherheit und Fehler in die Erfahrung ein, was den meisten Menschen nicht gefällt.
Eine effektive Möglichkeit, Ihre KI-Reise im Brownfield-Kontext zu beschleunigen, ist die Verwendung kleiner Sprachmodelle (SLMs), die typischerweise zwischen einigen hundert Millionen und einigen Milliarden Parametern liegen. Sie können flexibel in die vorhandenen Daten und die Infrastruktur Ihres Produkts integriert werden, ohne dass zusätzlicher technologischer Aufwand entsteht.
Wie SLMs trainiert werden
Die meisten SLMs sind von größeren Modellen abgeleitet Wissensdestillation. In diesem Aufbau fungiert ein großes Modell als Lehrer und ein kleineres als Schüler. Als Lehrer diente beispielsweise Googles Gemini Gemma 2 Und Gemma 3 während Metas Lama-Behemoth es trainierte Herde kleinerer Llama 4-Modelle. So wie ein menschlicher Lehrer jahrelanges Lernen zu klaren Erklärungen und strukturierten Lektionen zusammenfasst, destilliert das große Modell seinen riesigen Parameterraum in eine kleinere, dichtere Darstellung, die der Schüler aufnehmen kann. Das Ergebnis ist ein kompaktes Modell, das einen Großteil der Kompetenz des Lehrers beibehält, aber mit weitaus weniger Parametern und deutlich geringeren Rechenkosten arbeitet.

Verwendung von SLMs
Einer der Hauptvorteile von SLMs ist ihre Flexibilität bei der Bereitstellung. Im Gegensatz zu LLMs, die meist über externe APIs verwendet werden, können kleinere Modelle lokal ausgeführt werden, entweder auf der Infrastruktur Ihrer Organisation oder direkt auf dem Gerät des Benutzers:
- Lokale Bereitstellung: Sie können SLMs auf Ihren eigenen Servern oder in Ihrer Cloud-Umgebung hosten und behalten dabei die volle Kontrolle über Daten, Latenz und Compliance. Dieses Setup ist ultimate für Unternehmensanwendungen, bei denen vertrauliche Informationen oder behördliche Einschränkungen APIs von Drittanbietern unpraktisch machen.
📈 Der lokale Einsatz bietet Ihnen zudem versatile Möglichkeiten zur Feinabstimmung da Sie mehr Daten sammeln und auf wachsende Benutzererwartungen reagieren müssen.
- Bereitstellung auf dem Gerät über den Browser: Moderne Browser verfügen über integrierte KI-Funktionen, auf die Sie sich verlassen können. Chrome integriert beispielsweise Gemini Nano über integrierte KI-APIswährend Microsoft Edge Phi-4 enthält (siehe Schnelle API-Dokumentation). Das direkte Ausführen von Modellen im Browser ermöglicht Anwendungsfälle mit geringer Latenz und Wahrung der Privatsphäre, z. B. intelligente Textvorschläge, automatisches Ausfüllen von Formularen oder kontextbezogene Hilfe.
Wenn Sie mehr über die technischen Particulars von SLMs erfahren möchten, finden Sie hier einige nützliche Ressourcen:
Lassen Sie uns nun weitermachen und sehen, was Sie mit SLMs aufbauen können, um den Benutzern einen Mehrwert zu bieten und stetige Fortschritte bei Ihrer KI-Integration zu erzielen.
Produktmöglichkeiten für SLMs
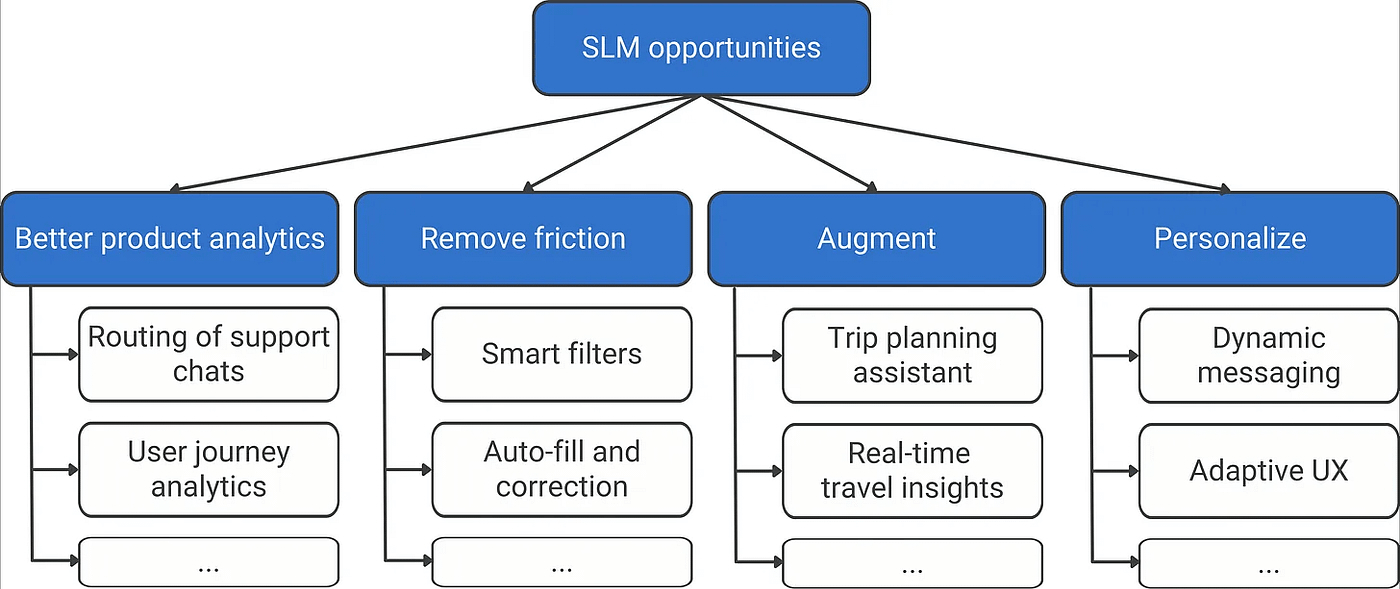
SLMs glänzen bei fokussierten, klar definierten Aufgaben, bei denen der Kontext und die Daten bereits bekannt sind – die Artwork von Anwendungsfällen, die tief in bestehenden Produkten verankert sind. Man kann sie sich eher als spezialisierte, eingebettete Intelligenz denn als Allzweckassistenten vorstellen. Lassen Sie uns einen Blick auf die wichtigsten Chancen werfen, die sie in der Industriebrache freischalten, wie im folgenden Chancenbaum dargestellt.

1. Bessere Produktanalysen
Bevor Sie Benutzern KI-Funktionen zugänglich machen, suchen Sie nach Möglichkeiten, Ihr Produkt von innen heraus zu verbessern. Die meisten Produkte erzeugen bereits einen kontinuierlichen Strom unstrukturierter Texte – Help-Chats, Hilfeanfragen, In-App-Suggestions. SLMs können diese Daten in Echtzeit analysieren und Erkenntnisse liefern, die sowohl Produktentscheidungen als auch das unmittelbare Benutzererlebnis beeinflussen. Hier einige Beispiele:
- Markieren und leiten Sie Help-Chats weiter Sobald sie auftreten, leiten wir technische Probleme an die richtigen Groups weiter.
- Abwanderungssignale während einer Sitzung kennzeichnenwas zu rechtzeitigen Interventionen führt.
- Schlagen Sie relevante Inhalte oder Aktionen vor basierend auf dem aktuellen Kontext des Benutzers.
- Erkennen Sie wiederholte Reibungspunkte während der Benutzer noch im Movement ist, nicht Wochen später in einer Retrospektive.
Diese internen Enabler halten das Risiko gering, schaffen gleichzeitig einen Mehrwert und geben Ihrem Group Zeit zum Lernen. Sie stärken Ihre Datengrundlage und bereiten Sie auf künftig sichtbarere, benutzerorientierte KI-Funktionen vor.
2. Reibung beseitigen
Machen Sie als Nächstes einen Schritt zurück und prüfen Sie die bereits vorhandenen UX-Schulden. Auf dem Markt sind die meisten Produkte nicht gerade der Traum eines jeden Designers. Sie wurden unter den technischen und architektonischen Zwängen ihrer Zeit entworfen. Mit KI haben wir nun die Möglichkeit, einige dieser Einschränkungen aufzuheben, Reibungsverluste zu reduzieren und schnellere, intuitivere Erlebnisse zu schaffen.
Ein gutes Beispiel sind die intelligenten Filter auf suchbasierten Web sites wie Reserving.com. Traditionell verwenden diese Seiten lange Hear mit Kontrollkästchen und Kategorien, die versuchen, alle möglichen Benutzerpräferenzen abzudecken. Sie sind umständlich zu entwerfen und zu verwenden, und am Ende finden viele Benutzer nicht die Einstellung, die ihnen wichtig ist.
Die sprachbasierte Filterung ändert dies. Anstatt durch eine komplexe Taxonomie zu navigieren, geben Benutzer einfach ein, was sie wollen (zum Beispiel „tierfreundliche Inns in Strandnähe“), und das Modell übersetzt es hinter den Kulissen in eine strukturierte Abfrage.

Suchen Sie im weiteren Sinne nach Bereichen in Ihrem Produkt, in denen Benutzer Ihre interne Logik – Ihre Kategorien, Strukturen oder Terminologie – anwenden müssen, und ersetzen Sie diese durch Interaktion in natürlicher Sprache. Immer wenn Benutzer ihre Absichten direkt zum Ausdruck bringen können, beseitigen Sie eine Schicht kognitiver Reibung und machen das Produkt intelligenter und benutzerfreundlicher.
3. Erweitern
Da Ihre Benutzererfahrung aufgeräumt ist, ist es an der Zeit, über Erweiterungen nachzudenken – das Hinzufügen kleiner, nützlicher KI-Funktionen zu Ihrem Produkt. Anstatt das Kernerlebnis neu zu erfinden, schauen Sie sich an, was Benutzer bereits rund um Ihr Produkt tun – die Nebenaufgaben, Problemumgehungen oder externen Instruments, auf die sie angewiesen sind, um ihr Ziel zu erreichen. Können fokussierte KI-Modelle ihnen helfen, es schneller oder intelligenter zu machen?
Beispielsweise könnte eine Reise-App einen kontextbezogenen Reisenotizgenerator integrieren, der Reisedetails zusammenfasst oder Nachrichten für Mitreisende verfasst. Ein Produktivitätstool könnte einen Besprechungszusammenfassungsgenerator umfassen, der Diskussionen oder Aktionspunkte aus Textnotizen zusammenfasst, ohne Daten an die Cloud zu senden.
Diese Funktionen entwickeln sich organisch aus dem tatsächlichen Benutzerverhalten und erweitern den Kontext Ihres Produkts, anstatt ihn neu zu definieren.
4. Personalisieren
Erfolgreiche Personalisierung ist der heilige Gral der KI. Es kehrt die traditionelle Dynamik um: Anstatt die Benutzer zu bitten, Ihr Produkt zu lernen und sich an es anzupassen, passt sich Ihr Produkt jetzt wie ein intestine sitzender Handschuh an sie an.
Wenn Sie anfangen, sollten Sie Ihren Ehrgeiz im Zaum halten – Sie brauchen keinen vollständig adaptiven Assistenten. Nehmen Sie stattdessen kleine, risikoarme Anpassungen daran vor, was Benutzer sehen, wie Informationen formuliert werden oder welche Optionen zuerst angezeigt werden. Auf der Inhaltsebene kann die KI Ton und Stil anpassen, indem sie beispielsweise prägnante Formulierungen für Experten und erklärendere Formulierungen für Neulinge verwendet. Auf der Erfahrungsebene können adaptive Schnittstellen erstellt werden. Beispielsweise könnte ein Projektmanagement-Device die relevantesten Aktionen („Aufgabe erstellen“, „Replace teilen“, „Zusammenfassung erstellen“) basierend auf den bisherigen Arbeitsabläufen des Benutzers anzeigen.
⚠️ Wenn die Personalisierung schiefgeht, schwindet schnell das Vertrauen. Benutzer spüren, dass sie persönliche Daten gegen ein Erlebnis eingetauscht haben, das sich nicht besser anfühlt. Führen Sie die Personalisierung daher erst ein, wenn Ihre Daten dafür bereit sind.
Warum „klein“ mit der Zeit gewinnt
Jede erfolgreiche KI-Funktion – sei es eine Analyseverbesserung, ein reibungsloser UX-Touchpoint oder ein personalisierter Schritt in einem größeren Ablauf – stärkt Ihre Datengrundlage und baut die Iterationskraft und KI-Kenntnisse Ihres Groups auf. Es schafft auch die Grundlage für spätere größere, komplexere Anwendungen. Wenn Ihre „kleinen“ Funktionen zuverlässig funktionieren, werden sie zu wiederverwendbaren Komponenten in größeren Workflows oder modularen Agentensystemen (vgl. Nvidias Artikel). Kleine Sprachmodelle sind die Zukunft der Agenten-KI).
Zusammenfassend:
✅ Fangen Sie klein an – Bevorzugen Sie eine schrittweise Verbesserung gegenüber Störungen.
✅ Experimentieren Sie schnell — Kleinere Modelle bedeuten geringere Kosten und schnellere Feedbackschleifen.
✅ Seien Sie vorsichtig — intern beginnen; Führen Sie benutzerorientierte KI ein, sobald Sie sie validiert haben.
✅ Bauen Sie Ihre Iterationskraft auf – Stetiger, kontinuierlicher Fortschritt übertrifft Schlagzeilenprojekte.
Ursprünglich veröffentlicht unter https://jannalipenkova.substack.com.