In diesem Artikel lernen Sie praktische Immediate-Engineering-Muster kennen, die große Sprachmodelle für die Zeitreihenanalyse und -prognose nützlich und zuverlässig machen.
Zu den Themen, die wir behandeln werden, gehören:
- Wie man den zeitlichen Kontext einrahmt und nützliche Signale extrahiert
- Wie man LLM-Argumentation mit klassischen statistischen Modellen kombiniert
- So strukturieren Sie Daten und Eingabeaufforderungen für Prognosen, Anomalien und Domänenbeschränkungen
Beginnen wir ohne weitere Verzögerung.
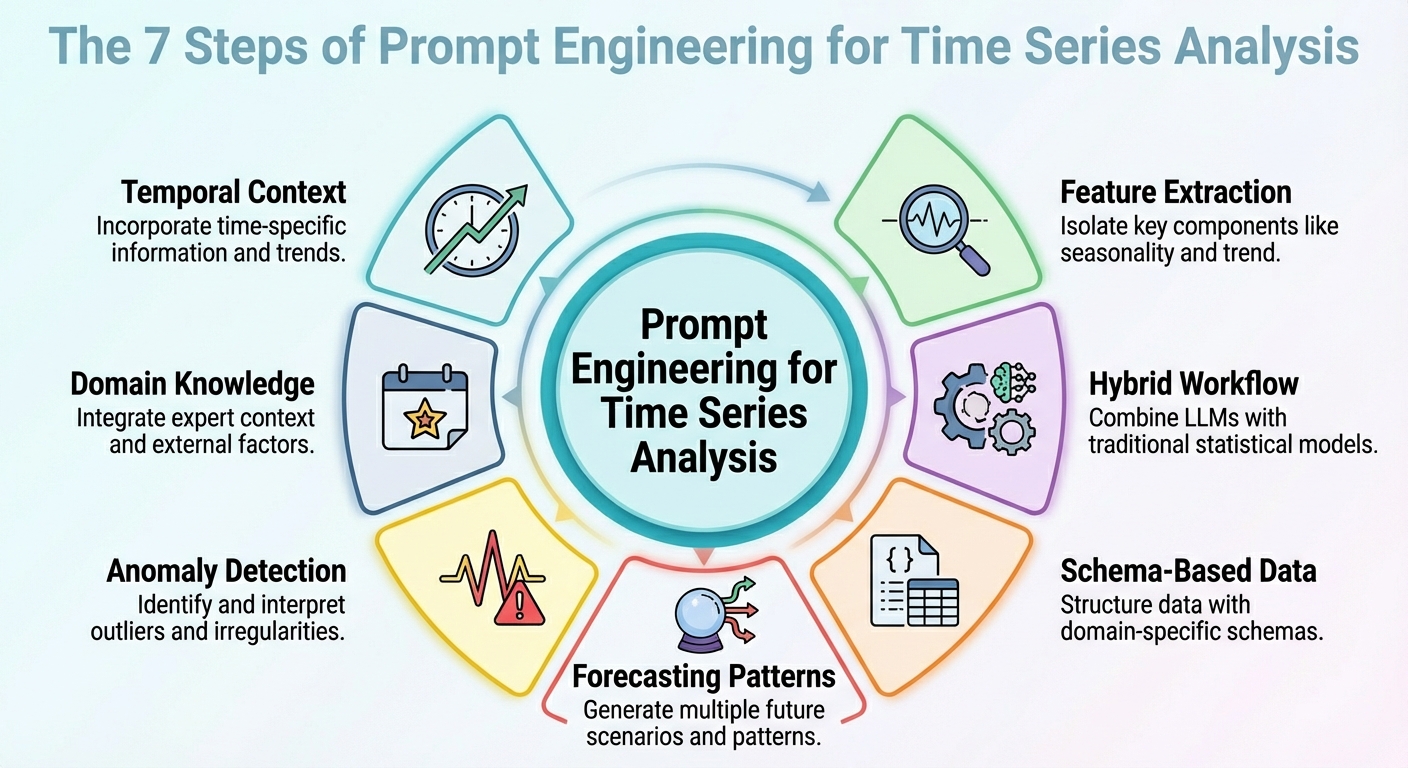
Immediate Engineering für Zeitreihenanalyse
Bild vom Herausgeber
Einführung
So seltsam es auch klingen magazine, große Sprachmodelle (LLMs) können für Datenanalyseaufgaben genutzt werden, einschließlich spezifischer Szenarien wie der Zeitreihenanalyse. Der Schlüssel liegt darin, Ihre Fähigkeiten im Bereich Immediate Engineering korrekt in das spezifische Analyseszenario umzusetzen.
In diesem Artikel werden sieben davon beschrieben schnelle technische Strategien das zur Hebelwirkung genutzt werden kann Zeitreihenanalyse Aufgaben mit LLMs.
Sofern nicht anders angegeben, werden die Beschreibungen dieser Strategien von anschaulichen Beispielen begleitet, die sich um ein Einzelhandelsumsatzdatenszenario drehen, wobei konkret für die Analyse ein Zeitreihendatensatz berücksichtigt wird, der aus täglichen Umsätzen im Zeitverlauf besteht.
1. Kontextualisierung der zeitlichen Struktur
Erstens sollte eine effektive Eingabeaufforderung, um eine nützliche Modellausgabe zu erhalten, eine sein, die dabei hilft, die zeitliche Struktur des Zeitreihendatensatzes zu verstehen. Dazu gehören mögliche Erwähnungen von Aufwärts-/Abwärtstrends, Saisonalität, bekannten Zyklen wie Werbeaktionen oder Feiertagen usw. Diese Kontextinformationen helfen Ihrem LLM, beispielsweise zeitliche Schwankungen als – nun ja, genau das zu interpretieren: Schwankungen und nicht als Rauschen. Zusammenfassend lässt sich sagen, dass die klare Beschreibung der Struktur des Datensatzes im Kontext Ihrer Eingabeaufforderungen oft weiter geht als komplizierte Argumentationsanweisungen in Eingabeaufforderungen.
Beispielaufforderung:
„Hier sind die täglichen Verkäufe (in Einheiten) der letzten 365 Tage. Die Daten zeigen eine wöchentliche Saisonalität (höhere Verkäufe am Wochenende), einen allmählich steigenden langfristigen Pattern und monatliche Spitzen am Ende jedes Monats aufgrund von Zahltagsaktionen. Nutzen Sie dieses Wissen, wenn Sie die nächsten 30 Tage vorhersagen.“
2. Merkmals- und Signalextraktion
Anstatt Ihr Modell zu bitten, direkte Prognosen anhand von Rohzahlen durchzuführen, sollten Sie es doch zunächst dazu auffordern, einige Schlüsselfunktionen zu extrahieren. Dazu können latente Muster, Anomalien und Korrelationen gehören. Die Aufforderung an den LLM, Merkmale und Signale zu extrahieren und in die Eingabeaufforderung zu integrieren (z. B. durch zusammenfassende Statistiken oder Zerlegung), hilft dabei, die Gründe für zukünftige Vorhersagen oder Schwankungen aufzudecken.
Beispielaufforderung:
„Berechnen Sie aus den Verkaufsdaten der letzten 365 Tage die durchschnittlichen Tagesverkäufe und die Standardabweichung, identifizieren Sie alle Tage, an denen die Verkäufe den Mittelwert plus das Doppelte der Standardabweichung überstiegen (d. h. potenzielle Ausreißer), und notieren Sie alle wiederkehrenden wöchentlichen oder monatlichen Muster. Interpretieren Sie dann, welche Faktoren Tage mit hohen Verkäufen oder Rückgängen erklären könnten, und kennzeichnen Sie ungewöhnliche Anomalien.“
3. Hybrider LLM + Statistik-Workflow
Seien wir ehrlich: Isolierte LLMs werden oft mit Aufgaben zu kämpfen haben, die numerische Präzision erfordern und zeitliche Abhängigkeiten in Zeitreihen erfassen. Aus diesem Grund ist die einfache Kombination ihrer Verwendung mit klassischen statistischen Modellen eine Formel, um bessere Ergebnisse zu erzielen. Wie könnte ein solcher hybrider Workflow definiert werden? Der Trick besteht darin, LLM-Argumentation – Excessive-Degree-Interpretation, Hypothesenformulierung und Kontextverständnis – neben quantitative Modelle wie ARIMA, ETS oder andere zu integrieren.
Zum Beispiel, LeMoLE (LLM-erweiterte Mischung aus linearen Experten) ist ein Beispiel für einen Hybridansatz, der lineare Modelle mit von Eingabeaufforderungen abgeleiteten Funktionen anreichert.
Das Ergebnis vereint kontextbezogenes Denken und statistische Genauigkeit: das Beste aus zwei Welten.
4. Schemabasierte Datendarstellung
Während rohe Zeitreihendatensätze in der Regel schlecht geeignete Formate für die Weitergabe als LLM-Eingaben sind, könnte die Verwendung strukturierter Schemata wie JSON oder kompakter Tabellen der Schlüssel sein, der es dem LLM ermöglicht, diese Daten viel zuverlässiger zu interpretieren, wie in mehreren Studien gezeigt wurde.
Beispiel für ein JSON-Snippet, das zusammen mit einer Eingabeaufforderung übergeben werden soll:
|
{ „Verkäufe“: ( {„Datum“: „01.12.2024“, „Einheiten“: 120}, {„Datum“: „02.12.2024“, „Einheiten“: 135}, ..., {„Datum“: „30.11.2025“, „Einheiten“: 210} ), „Metadaten“: { „Frequenz“: „täglich“, „Saisonalität“: („wöchentlich“, „Monatsende“), „Area“: „retail_sales“ } } |
Aufforderung, die JSON-Daten mit Folgendem zu versehen:
„Anhand der oben genannten JSON-Daten und Metadaten analysieren Sie die Zeitreihe und prognostizieren die Verkäufe der nächsten 30 Tage.“
5. Geführte Prognosemuster
Das Entwerfen und ordnungsgemäße Strukturieren von Prognosemustern innerhalb der Eingabeaufforderung – beispielsweise kurzfristige vs. langfristige Horizonte oder die Simulation spezifischer „Was-wäre-wenn“-Szenarien – kann dabei helfen, das Modell so zu steuern, dass es besser nutzbare Antworten liefert. Dieser Ansatz ist effektiv, um äußerst umsetzbare Erkenntnisse für Ihre gewünschte Analyse zu generieren.
Beispiel:
|
Aufgabe A — Kurz–Begriff (nächste 7 Tage): Vorhersage erwartet Verkäufe. Aufgabe B — Lang–Begriff (nächste 30 Tage): Bieten A Grundlinie Vorhersage Plus zwei Szenarien: – Szenario 1 (Regular Bedingungen) – Szenario 2 (mit A geplant Förderung An Tage 10–15)
In Zusatz, bieten A 95% Vertrauen Intervall für beide Szenarien. |
6. Aufforderungen zur Anomalieerkennung
Dieser ist eher aufgabenspezifisch und konzentriert sich auf die richtige Erstellung von Eingabeaufforderungen, die nicht nur dabei helfen können, mit LLMs Prognosen zu erstellen, sondern auch Anomalien zu erkennen – in Kombination mit statistischen Methoden – und ihre wahrscheinlichen Ursachen zu begründen oder sogar Vorschläge zu machen, was untersucht werden sollte. Der Schlüssel liegt wiederum darin, zunächst mit herkömmlichen Zeitreihentools eine Vorverarbeitung durchzuführen und dann das Modell zur Interpretation der Ergebnisse aufzufordern.
Beispielaufforderung:
„Kennzeichnen Sie mithilfe der JSON-Verkaufsdaten zunächst jeden Tag, an dem die Verkäufe um mehr als das Doppelte der wöchentlichen Standardabweichung vom Wochendurchschnitt abweichen. Erklären Sie dann für jeden gekennzeichneten Tag mögliche Ursachen (z. B. Nichtvorräte, Werbeaktionen, externe Ereignisse) und empfehlen Sie, ob eine Untersuchung erforderlich ist (z. B. Bestandsprotokolle überprüfen, Marketingkampagne, Ladenbesucherverkehr).“
7. Domänenbasiertes Denken
Domänenwissen wie saisonale Muster im Einzelhandel, Feiertagseffekte usw. liefern wertvolle Erkenntnisse, und die Einbettung dieser Erkenntnisse in Eingabeaufforderungen hilft LLMs dabei, Analysen und Vorhersagen durchzuführen, die aussagekräftiger und auch interpretierbarer sind. Dies läuft darauf hinaus, die Relevanz des „Datensatzkontexts“ sowohl semantisch als auch domänenspezifisch als Leuchtturm zu nutzen, der die Modellbegründung leitet.
Eine Meldung wie diese könnte dem LLM dabei helfen, Spitzen am Monatsende oder Umsatzrückgänge aufgrund von Feiertagsrabatten besser zu antizipieren:
„Dies sind die täglichen Verkaufsdaten einer Einzelhandelskette. Die Verkäufe steigen tendenziell am Ende jedes Monats an (Kunden erhalten Gehälter), sinken an Feiertagen und steigen bei Werbeveranstaltungen. Gelegentlich kommt es auch zu Lagerknappheit, was bei bestimmten SKUs zu Einbrüchen führt. Nutzen Sie dieses Fachwissen, wenn Sie die Reihen analysieren und Prognosen erstellen.“
Zusammenfassung
In diesem Artikel wurden sieben verschiedene Strategien beschrieben, die größtenteils durch neuere Studien begründet und unterstützt werden, um mithilfe von LLMs effektivere Eingabeaufforderungen für Zeitreihenanalyse- und Prognoseaufgaben zu erstellen.