Langextrakt ist ein von Entwickler bei Google Dadurch wird es einfach, unordentliche, unstrukturierte Textual content in saubere, strukturierte Daten zu verwandeln, indem Sie LLMs nutzen. Benutzer können einige wenige Beispiele zusammen mit einem benutzerdefinierten Schema angeben und darauf basieren. Es funktioniert sowohl mit proprietärer als auch mit lokaler LLMs (über Ollama).
Eine erhebliche Menge an Daten im Gesundheitswesen ist unstrukturiert, was es zu einem idealen Bereich macht, in dem ein Device wie dieses von Vorteil sein kann. Klinische Notizen sind lang und voller Abkürzungen und Inkonsistenzen. Wichtige Particulars wie Drogennamen, Dosierungen und insbesondere unerwünschte Arzneimittelreaktionen (ADRs) werden im Textual content begraben. Daher wollte ich für diesen Artikel sehen, ob Langextract in klinischen Notizen eine nachteilige Erkennung von Arzneimittelreaktion (ADR) bewältigen könnte. Noch wichtiger ist, ist es effektiv? Lassen Sie uns in diesem Artikel herausfinden. Beachten Sie, dass Langextract zwar ein Open-Supply-Projekt von Entwicklern bei Google ist, es jedoch kein offiziell unterstütztes Google-Produkt ist.
Nur ein kurzer Hinweis: Ich zeige nur, wie Lanextraden funktioniert. Ich bin kein Arzt, und das ist kein medizinischer Rat.
▶ ️ hier ist detailliert Kaggle Pocket book mit folgen.
Warum ADR Extraktion wichtig ist
Ein Unerwünschte Arzneimittelreaktion (ADR) ist ein schädliches, unbeabsichtigtes Ergebnis, das durch Einnahme eines Medikaments verursacht wird. Diese können von leichten Nebenwirkungen wie Übelkeit oder Schwindel bis hin zu schwerwiegenden Ergebnissen reichen, die möglicherweise medizinische Hilfe erfordern.

Es ist entscheidend für die Patientensicherheit und die schnelle Erkennung von entscheidender Bedeutung und Pharmakovigilanz. Die Herausforderung besteht darin, dass in klinischen Notizen ADRs zusammen mit früheren Bedingungen, Laborergebnissen und einem anderen Kontext begraben werden. Infolgedessen ist es schwierig, sie zu erkennen. Die Verwendung von LLMs zur Erkennung von ADRs ist ein fortlaufender Forschungsbereich. Manche Neuere Arbeiten haben gezeigt, dass LLMs intestine darin sind, rote Fahnen zu heben, aber nicht zuverlässig. Die ADR -Extraktion ist additionally ein guter Stresstest für Langextract, da das Ziel hier darin besteht, festzustellen, ob diese Bibliothek die nachteiligen Reaktionen unter anderen Einheiten in klinischen Notizen wie Medikamenten, Dosierungen, Schweregrad usw. erkennen kann.
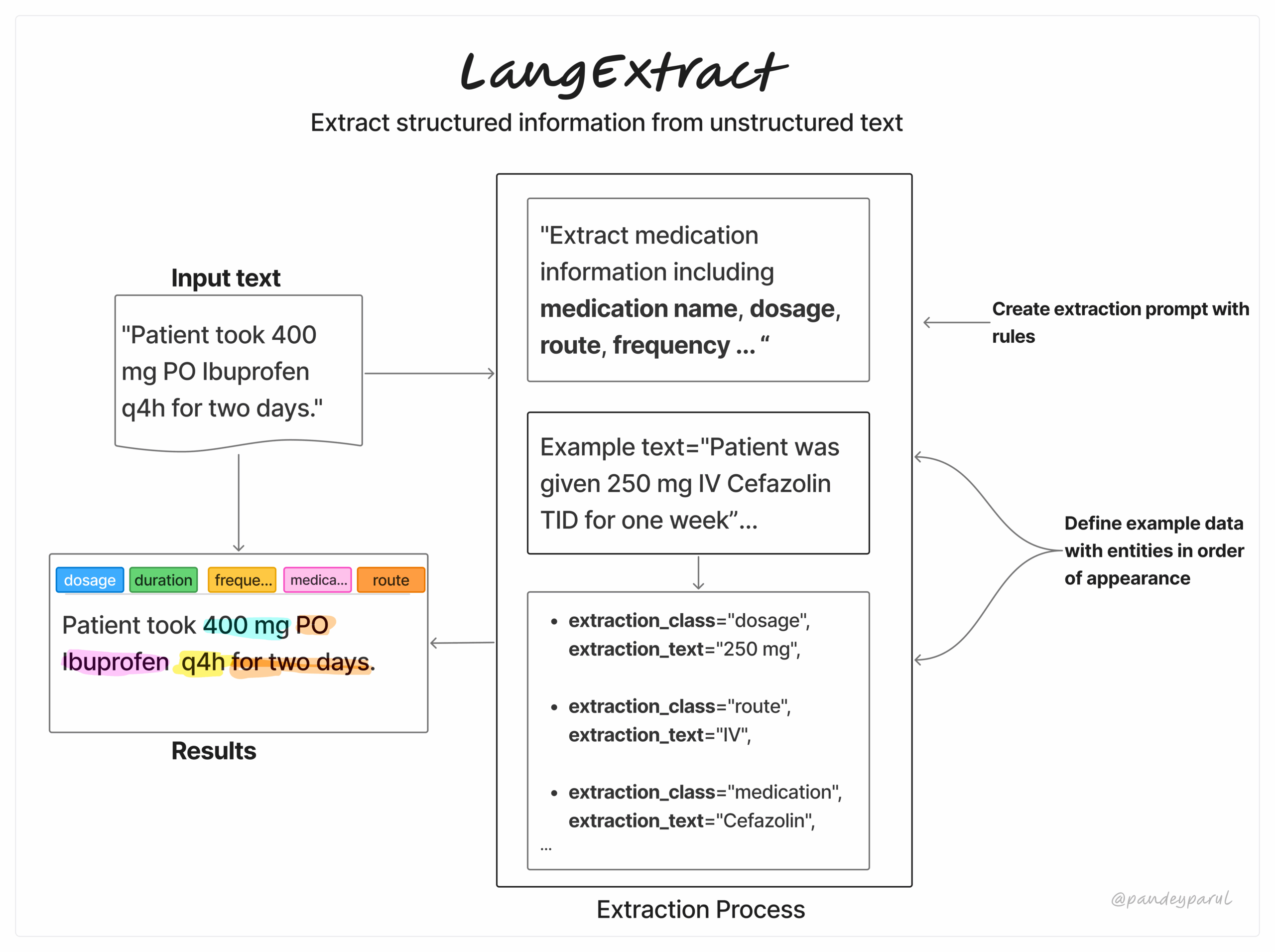
Wie Langextract funktioniert
Bevor wir in die Verwendung einsteigen, lasst uns Langextracts Workflow aufschlüsseln. Es ist ein einfacher dreistufiger Prozess:
- Definieren Sie Ihre Extraktionsaufgabe Durch das Schreiben einer klaren Eingabeaufforderung, die genau angibt, was Sie extrahieren möchten.
- Bieten Sie einige hochwertige Beispiele an Um das Modell in Richtung des von Ihnen erwarteten Codecs und Detaillierungsgrades zu führen.
- Senden Sie Ihren Eingangstext, wählen Sie das Modell und lassen Sie es Langextract verarbeiten. Benutzer können Überprüfen Sie dann die Ergebnisse, visualisieren Sie sie oder geben Sie sie direkt in ihre nachgelagerte Pipeline ein.
Der Beamte Github -Repository des Instruments enthält detaillierte Beispiele, die mehrere Domänen umfassen, von der Entitätsextraktion in Shakespeares Romeo & Julia bis hin zu Medikamentenidennings in klinischen Notizen und Strukturierung der Radiologieberichte. Schau sie dir an.
Set up
Zuerst müssen wir die installieren LangExtract Bibliothek. Es ist immer eine gute Idee, dies innerhalb eines zu tun Virtuelle Umgebung um Ihre Projektabhängigkeiten isoliert zu halten.
pip set up langextractIdentifizierung unerwünschter Arzneimittelreaktionen in klinischen Notizen mit Langextract & Gemini
Kommen wir nun zu unserem Anwendungsfall. Für diesen Vorgang werde ich Google verwenden Gemini 2.5 Flash Modell. Sie könnten auch verwenden Gemini Professional Für komplexere Argumentationsaufgaben. Sie müssen zuerst Ihren API -Schlüssel einstellen:
export LANGEXTRACT_API_KEY="your-api-key-here"▶ ️ hier ist detailliert Kaggle Pocket book mit folgen.
Schritt 1: Definieren Sie die Extraktionsaufgabe
Lassen Sie uns unsere Aufforderung zum Extrahieren von Medikamenten, Dosierungen, nachteiligen Reaktionen und Maßnahmen erstellen. Wir können auch nach Erwähnung um Schweregrad bitten.
immediate = textwrap.dedent("""
Extract medicine, dosage, hostile response, and motion taken from the textual content.
For every hostile response, embrace its severity as an attribute if talked about.
Use actual textual content spans from the unique textual content. Don't paraphrase.
Return entities within the order they seem.""")
Lassen Sie uns als nächstes ein Beispiel geben, um das Modell zum richtigen Format zu führen:
# 1) Outline the immediate
immediate = textwrap.dedent("""
Extract situation, medicine, dosage, hostile response, and motion taken from the textual content.
For every hostile response, embrace its severity as an attribute if talked about.
Use actual textual content spans from the unique textual content. Don't paraphrase.
Return entities within the order they seem.""")
# 2) Instance
examples = (
lx.information.ExampleData(
textual content=(
"After taking ibuprofen 400 mg for a headache, "
"the affected person developed delicate abdomen ache. "
"They stopped taking the medication."
),
extractions=(
lx.information.Extraction(
extraction_class="situation",
extraction_text="headache"
),
lx.information.Extraction(
extraction_class="medicine",
extraction_text="ibuprofen"
),
lx.information.Extraction(
extraction_class="dosage",
extraction_text="400 mg"
),
lx.information.Extraction(
extraction_class="adverse_reaction",
extraction_text="delicate abdomen ache",
attributes={"severity": "delicate"}
),
lx.information.Extraction(
extraction_class="action_taken",
extraction_text="They stopped taking the medication"
)
)
)
)Schritt 2: Geben Sie die Eingabe an und führen Sie die Extraktion aus
Für die Eingabe verwende ich einen echten klinischen Satz aus dem Ade Corpus v2 Datensatz zum Umarmungsgesicht.
input_text = (
"A 27-year-old man who had a historical past of bronchial bronchial asthma, "
"eosinophilic enteritis, and eosinophilic pneumonia introduced with "
"fever, pores and skin eruptions, cervical lymphadenopathy, hepatosplenomegaly, "
"atypical lymphocytosis, and eosinophilia two weeks after receiving "
"trimethoprim (TMP)-sulfamethoxazole (SMX) remedy."
)Lassen Sie uns als nächstes Langextract mit dem Gemini-2,5-Flash-Modell ausführen.
end result = lx.extract(
text_or_documents=input_text,
prompt_description=immediate,
examples=examples,
model_id="gemini-2.5-flash",
api_key=LANGEXTRACT_API_KEY
)Schritt 3: Zeigen Sie die Ergebnisse an
Sie können die extrahierten Einheiten mit Positionen anzeigen
print(f"Enter: {input_text}n")
print("Extracted entities:")
for entity in end result.extractions:
position_info = ""
if entity.char_interval:
begin, finish = entity.char_interval.start_pos, entity.char_interval.end_pos
position_info = f" (pos: {begin}-{finish})"
print(f"• {entity.extraction_class.capitalize()}: {entity.extraction_text}{position_info}")
Langextract identifiziert die korrekt die unerwünschte Arzneimittelreaktion Ohne es mit den bereits bestehenden Bedingungen des Patienten zu verwechseln, was bei dieser Artwork von Aufgabe eine zentrale Herausforderung darstellt.
Wenn Sie es visualisieren möchten, wird dies erstellen .jsonl Datei. Sie können das laden .jsonl Datei durch Aufrufen der Visualisierungsfunktion und erstellt eine HTML -Datei für Sie.
lx.io.save_annotated_documents(
(end result),
output_name="adr_extraction.jsonl",
output_dir="."
)
html_content = lx.visualize("adr_extraction.jsonl")
# Show the HTML content material straight
show((html_content))
Arbeiten mit längeren klinischen Notizen
Echte klinische Notizen sind oft viel länger als das oben gezeigte Beispiel. Zum Beispiel finden Sie hier eine tatsächliche Notiz aus der Ade-Corpus-V2 Datensatz unter dem MIT -Lizenz. Sie können darauf zugreifen Umarmtes Gesicht oder Zenodo.

Um längere Texte mit Langextract zu verarbeiten, führen Sie den gleichen Workflow bei, fügen jedoch drei Parameter hinzu:
Extraction_Passe Führen Sie mehrere Pässe über den Textual content aus, um weitere Particulars zu erhalten und den Rückruf zu verbessern.
Max_worker Steuerelemente parallele Verarbeitung, sodass größere Dokumente schneller behandelt werden können.
max_char_buffer Teilen den Textual content in kleinere Stücke auf, was dem Modell hilft, auch dann genau zu bleiben, wenn die Eingabe sehr lang ist.
end result = lx.extract(
text_or_documents=input_text,
prompt_description=immediate,
examples=examples,
model_id="gemini-2.5-flash",
extraction_passes=3,
max_workers=20,
max_char_buffer=1000
)Hier ist die Ausgabe. Für die Kürze zeige ich hier nur einen Teil der Ausgabe.

Wenn Sie möchten, können Sie auch die URL eines Dokuments direkt an die übergeben text_or_documents Parameter.
Verwenden von Langextract mit lokalen Modellen über Ollama
Langextract ist nicht auf proprietäre APIs beschränkt. Sie können es auch mit lokalen Modellen durchführen Ollama. Dies ist besonders nützlich, wenn Sie mit Datenschutz-sensitiven klinischen Daten arbeiten, die Ihre sichere Umgebung nicht verlassen können. Sie können Ollama lokal einrichten, Ihr bevorzugtes Modell ziehen und Langextract darauf hinweisen. Vollständige Anweisungen finden Sie in der offizielle Dokumente.
Abschluss
Wenn Sie ein Informationsabrufsystem oder eine Anwendung mit Metadatenextraktion erstellen, kann Langextract Ihnen eine erhebliche Menge an Vorverarbeitungsaufwand ersparen. In meinen ADR -Experimenten führte Langextract intestine ab und identifizierte Medikamente, Dosierungen und Reaktionen korrekt. Ich habe festgestellt, dass die Ausgabe direkt von der Qualität der wenigen Schussbeispiele des Benutzers abhängt, was bedeutet, dass LLMs das schwere Heben durchführen, aber immer noch ein wichtiger Teil der Schleife bleiben. Die Ergebnisse waren ermutigend, aber da klinische Daten ein hohes Risiko sind, sind weiterhin breitere und strengere Exams in verschiedenen Datensätzen erforderlich, bevor sie zur Produktionsanwendung bewegt werden.