Die sich ständig verändernde Natur der Welt um uns herum stellt eine große Herausforderung für die Entwicklung von KI-Modellen dar. Modelle werden häufig anhand von Längsschnittdaten trainiert, in der Hoffnung, dass die verwendeten Trainingsdaten die Eingaben, die das Modell möglicherweise in der Zukunft erhalten wird, genau wiedergeben. Generell gilt, dass die Standardannahme, dass alle Trainingsdaten gleichermaßen related sind, in der Praxis häufig nicht funktioniert. Die folgende Abbildung zeigt beispielsweise Bilder von KLAR Benchmark für nichtstationäres Lernen, und es veranschaulicht, wie sich visuelle Merkmale von Objekten über einen Zeitraum von 10 Jahren erheblich entwickeln (ein Phänomen, das wir als bezeichnen). langsame Konzeptdrift), was eine Herausforderung für Objektkategorisierungsmodelle darstellt.
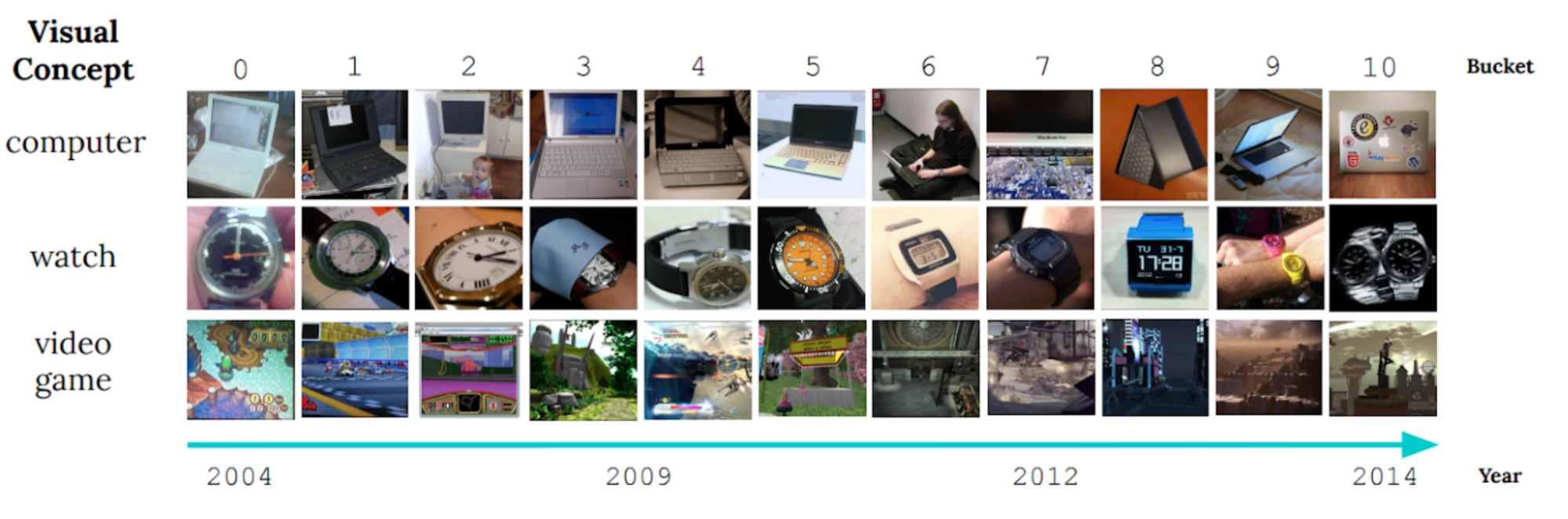 |
| Beispielbilder aus dem CLEAR-Benchmark. (Angepasst von Lin et al.) |
Different Ansätze, wie z on-line Und kontinuierliches LernenAktualisieren Sie ein Modell wiederholt mit kleinen Mengen aktueller Daten, um es auf dem neuesten Stand zu halten. Dadurch werden implizit aktuelle Daten priorisiert, da die Erkenntnisse aus früheren Daten durch nachfolgende Aktualisierungen nach und nach gelöscht werden. In der realen Welt verlieren verschiedene Arten von Informationen jedoch unterschiedlich schnell an Relevanz, sodass es zwei Hauptprobleme gibt: 1) Sie konzentrieren sich aufgrund ihres Designs ausschließlich auf den neuesten Daten und verlieren jegliches Sign von älteren Daten, die gelöscht werden. 2) Beiträge von Dateninstanzen verfallen gleichmäßig über die Zeit unabhängig vom Inhalt der Daten.
In unserer jüngsten Arbeit: „Instanzbedingte Zeitskalen des Verfalls für instationäres Lernen„Wir schlagen vor, jeder Instanz während des Trainings eine Wichtigkeitsbewertung zuzuweisen, um die Modellleistung bei zukünftigen Daten zu maximieren. Um dies zu erreichen, verwenden wir ein Hilfsmodell, das diese Ergebnisse unter Verwendung der Trainingsinstanz und ihres Alters erstellt. Dieses Modell wird gemeinsam mit dem Primärmodell erlernt. Wir gehen beide oben genannten Herausforderungen an und erzielen erhebliche Fortschritte gegenüber anderen robusten Lernmethoden anhand einer Reihe von Benchmark-Datensätzen für instationäres Lernen. Zum Beispiel auf einem jüngster groß angelegter Benchmark Für instationäres Lernen (~39 Millionen Fotos über einen Zeitraum von 10 Jahren) zeigen wir bis zu 15 % relative Genauigkeitsgewinne durch erlernte Neugewichtung von Trainingsdaten.
Die Herausforderung der Konzeptdrift für überwachtes Lernen
Um quantitative Einblicke in die langsame Konzeptdrift zu gewinnen, haben wir Klassifikatoren auf einer Foundation erstellt aktuelle Fotokategorisierungsaufgabe, bestehend aus etwa 39 Millionen Fotos, die über einen Zeitraum von 10 Jahren von Social-Media-Web sites stammen. Wir verglichen das Offline-Coaching, bei dem alle Trainingsdaten mehrmals in zufälliger Reihenfolge durchlaufen wurden, mit dem kontinuierlichen Coaching, bei dem die Daten jeden Monat mehrmals in sequentieller (zeitlicher) Reihenfolge iterierten. Wir haben die Modellgenauigkeit sowohl während des Trainingszeitraums als auch während eines darauffolgenden Zeitraums gemessen, in dem beide Modelle eingefroren waren, additionally nicht weiter auf der Grundlage neuer Daten aktualisiert wurden (siehe unten). Am Ende des Trainingszeitraums (linkes Feld, X-Achse = 0) haben beide Ansätze die gleiche Datenmenge gesehen, weisen jedoch eine große Leistungslücke auf. Das ist wegen katastrophales Vergessen, ein Drawback beim kontinuierlichen Lernen, bei dem das Wissen eines Modells über Daten zu Beginn der Trainingssequenz auf unkontrollierte Weise verringert wird. Andererseits hat das Vergessen seine Vorteile: Während des Testzeitraums (siehe rechts) verschlechtert sich das kontinuierlich trainierte Modell viel weniger schnell als das Offline-Modell, da es weniger von älteren Daten abhängig ist. Der Rückgang der Genauigkeit beider Modelle im Testzeitraum ist eine Bestätigung dafür, dass sich die Daten tatsächlich im Laufe der Zeit weiterentwickeln und beide Modelle zunehmend an Relevanz verlieren.
 |
| Vergleich von Offline- und kontinuierlich trainierten Modellen für die Fotoklassifizierungsaufgabe. |
Zeitkritische Neugewichtung von Trainingsdaten
Wir entwerfen eine Methode, die die Vorteile des Offline-Lernens (die Flexibilität der effektiven Wiederverwendung aller verfügbaren Daten) und des kontinuierlichen Lernens (die Möglichkeit, ältere Daten herunterzuspielen) kombiniert, um langsame Konzeptdrift zu bewältigen. Wir bauen auf Offline-Lernen auf und fügen dann eine sorgfältige Kontrolle des Einflusses vergangener Daten und ein Optimierungsziel hinzu, die beide darauf ausgelegt sind, den Modellverfall in der Zukunft zu reduzieren.
Angenommen, wir möchten ein Modell trainieren, M, angesichts einiger Trainingsdaten, die im Laufe der Zeit gesammelt wurden. Wir schlagen außerdem vor, ein Hilfsmodell zu trainieren, das jedem Punkt basierend auf seinem Inhalt und Alter eine Gewichtung zuweist. Dieses Gewicht skaliert den Beitrag dieses Datenpunkts im Trainingsziel für M. Das Ziel der Gewichte besteht darin, die Leistung zu verbessern M auf zukünftige Daten.
In unsere ArbeitWir beschreiben, wie das Hilfsmodell aussehen kann meta-gelernt, dh nebenher gelernt M auf eine Weise, die das Lernen des Modells erleichtert M selbst. Eine wichtige Designentscheidung des Hilfsmodells besteht darin, dass wir instanz- und altersbezogene Beiträge faktorisiert heraustrennen. Konkret legen wir die Gewichtung fest, indem wir Beiträge aus mehreren verschiedenen festen Zeitskalen des Zerfalls kombinieren und eine ungefähre „Zuordnung“ einer bestimmten Instanz zu ihren am besten geeigneten Zeitskalen lernen. Wir stellen in unseren Experimenten fest, dass diese Type des Hilfsmodells aufgrund seiner Kombination aus Einfachheit und Ausdruckskraft viele andere von uns in Betracht gezogene Alternativen übertrifft, die von uneingeschränkten Gelenkfunktionen bis hin zu einer einzelnen Zeitskala des Zerfalls (exponentiell oder linear) reichen. Ausführliche Informationen finden Sie im Papier.
Instanzgewichtsbewertung
Die obere Abbildung unten zeigt, dass unser erlerntes Hilfsmodell tatsächlich moderner aussehende Objekte in der Gewichtung erhöht CLEAR-Objekterkennungsherausforderung; Ältere Objekte werden entsprechend herabgesetzt. Bei näherer Betrachtung (untere Abbildung unten, verlaufsbasiert Function-Wichtigkeit (Bewertung) sehen wir, dass sich das Hilfsmodell auf das primäre Objekt im Bild konzentriert, im Gegensatz beispielsweise zu Hintergrundmerkmalen, die fälschlicherweise mit dem Alter der Instanz korrelieren.
 |
| Beispielbilder aus dem KLAR Benchmark (Kamera- und Computerkategorien), denen von unserem Hilfsmodell jeweils die höchste bzw. niedrigste Gewichtung zugewiesen wurde. |
 |
| Function-Wichtigkeitsanalyse unseres Hilfsmodells anhand von Beispielbildern aus dem KLAR Benchmark. |
Ergebnisse
Gewinne aus großen Datenmengen
Wir studieren zunächst das Große Fotokategorisierungsaufgabe (PCAT) auf der YFCC100M-Datensatz Wie bereits erwähnt, werden die Daten der ersten fünf Jahre für das Coaching und die der nächsten fünf Jahre als Testdaten verwendet. Unsere Methode (unten rot dargestellt) verbessert sich erheblich gegenüber der Basislinie ohne Neugewichtung (schwarz) sowie vielen anderen robusten Lerntechniken. Interessanterweise opfert unsere Methode bewusst die Genauigkeit der fernen Vergangenheit (Trainingsdaten werden in der Zukunft wahrscheinlich nicht wieder auftauchen) im Austausch für deutliche Verbesserungen im Testzeitraum. Außerdem verschlechtert sich unsere Methode wie gewünscht im Testzeitraum weniger als andere Basislinien.
 |
| Vergleich unserer Methode und relevanter Basislinien im PCAT-Datensatz. |
Breite Anwendbarkeit
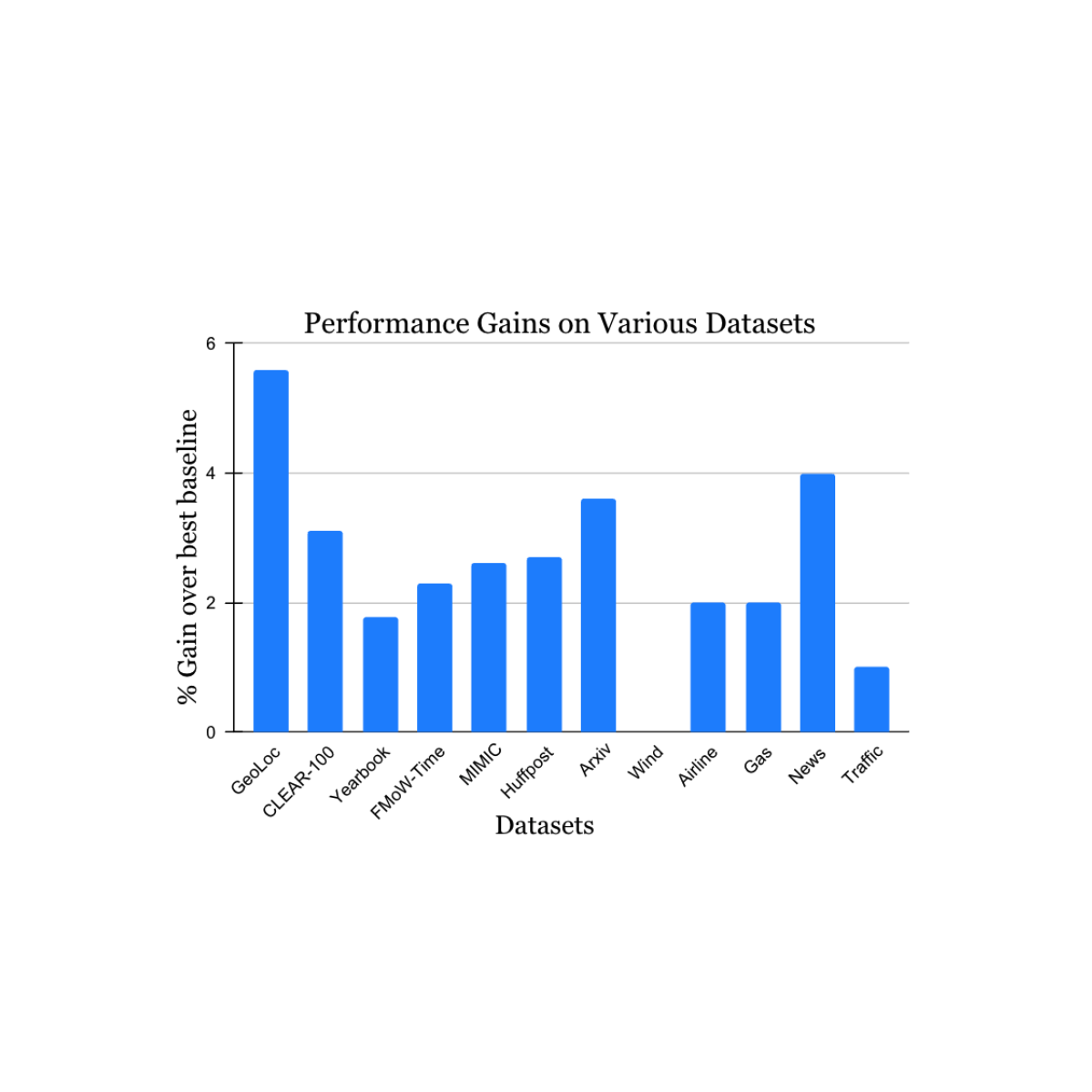
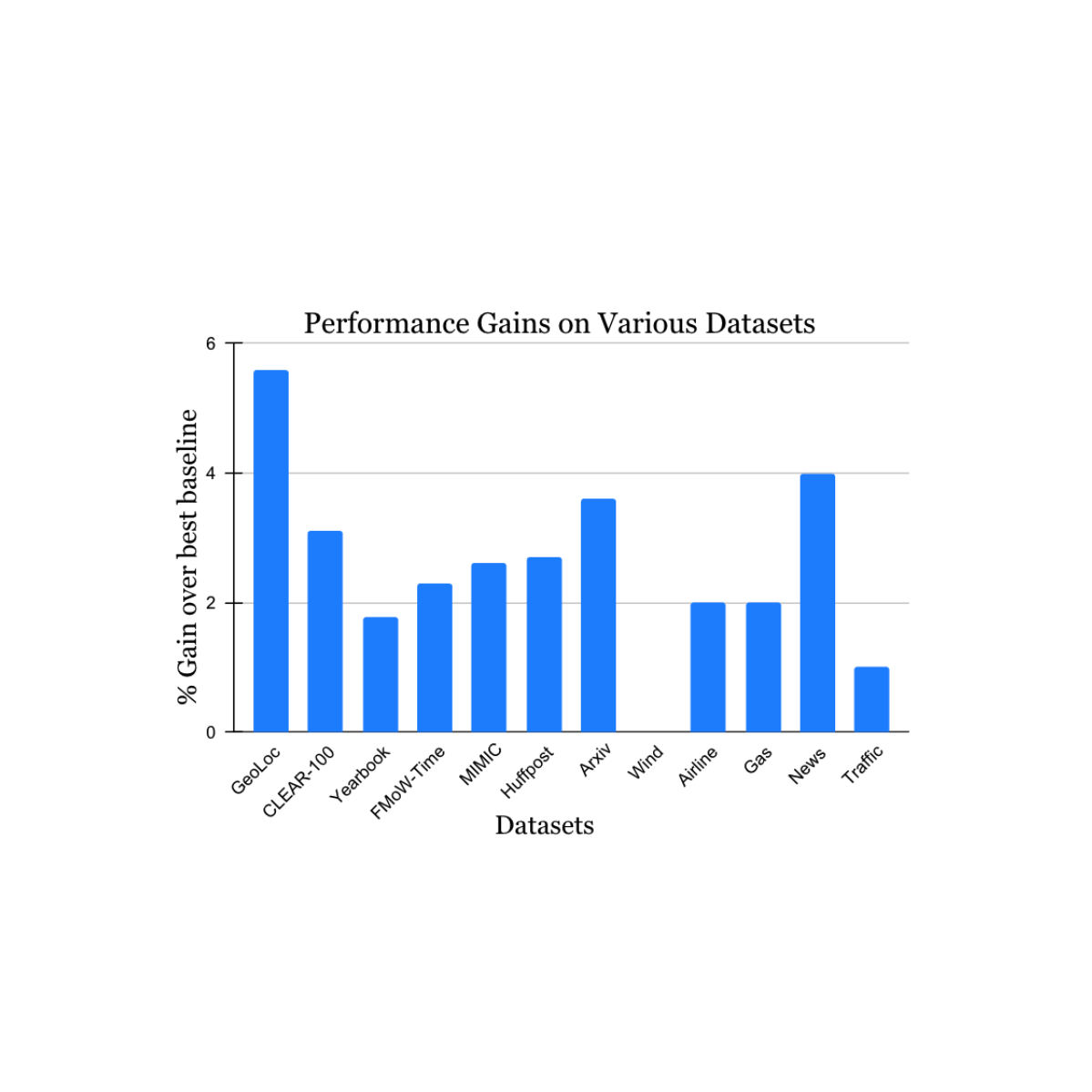
Wir validierten unsere Ergebnisse anhand einer Vielzahl von Datensätzen zu instationären Lernherausforderungen, die aus der akademischen Literatur stammen (siehe 1, 2, 3, 4 für Particulars), die Datenquellen und -modalitäten (Fotos, Satellitenbilder, Social-Media-Texte, Krankenakten, Sensorwerte, Tabellendaten) und Größen (von 10.000 bis 39 Millionen Instanzen) umfasst. Wir berichten von erheblichen Zuwächsen im Testzeitraum im Vergleich zur nächstgelegenen veröffentlichten Benchmark-Methode für jeden Datensatz (siehe unten). Beachten Sie, dass die bisher bekannteste Methode für jeden Datensatz unterschiedlich sein kann. Diese Ergebnisse zeigen die breite Anwendbarkeit unseres Ansatzes.
 |
| Leistungssteigerung unserer Methode bei einer Vielzahl von Aufgaben zur Untersuchung natürlicher Konzeptdrift. Unsere gemeldeten Gewinne liegen für jeden Datensatz im Vergleich zur bisher bekanntesten Methode. |
Erweiterungen zum kontinuierlichen Lernen
Abschließend betrachten wir eine interessante Erweiterung unserer Arbeit. In der oben genannten Arbeit wurde beschrieben, wie Offline-Lernen erweitert werden kann, um Konzeptabweichungen mithilfe von Ideen zu bewältigen, die durch kontinuierliches Lernen inspiriert sind. Allerdings ist Offline-Lernen manchmal nicht durchführbar – beispielsweise, wenn die Menge der verfügbaren Trainingsdaten zu groß ist, um sie zu verwalten oder zu verarbeiten. Wir haben unseren Ansatz für kontinuierliches Lernen auf einfache Weise angepasst, indem wir eine zeitliche Neugewichtung vorgenommen haben im Rahmen von Jeder Datenbereich wird zur sequentiellen Aktualisierung des Modells verwendet. Dieser Vorschlag weist noch einige Einschränkungen des kontinuierlichen Lernens auf, z. B. werden Modellaktualisierungen nur für die aktuellsten Daten durchgeführt und alle Optimierungsentscheidungen (einschließlich unserer Neugewichtung) werden nur für diese Daten getroffen. Nichtsdestotrotz übertrifft unser Ansatz das reguläre kontinuierliche Lernen sowie eine Vielzahl anderer kontinuierlich lernender Algorithmen im Vergleich zur Fotokategorisierung (siehe unten). Da unser Ansatz die Ideen vieler hier verglichener Basislinien ergänzt, erwarten wir in Kombination mit ihnen noch größere Gewinne.
 |
| Ergebnisse unserer an kontinuierliches Lernen angepassten Methode im Vergleich zu den neuesten Baselines. |
Abschluss
Wir haben die Herausforderung der Datendrift beim Lernen angegangen, indem wir die Stärken früherer Ansätze kombiniert haben – Offline-Lernen mit seiner effektiven Wiederverwendung von Daten und kontinuierliches Lernen mit seinem Schwerpunkt auf neueren Daten. Wir hoffen, dass unsere Arbeit dazu beiträgt, die Robustheit des Modells gegenüber Konzeptdrift in der Praxis zu verbessern und mehr Interesse und neue Ideen für die Bewältigung des allgegenwärtigen Issues des langsamen Konzeptdrifts zu wecken.
Danksagungen
Wir danken Mike Mozer für viele interessante Diskussionen in der frühen Section dieser Arbeit sowie sehr hilfreiche Ratschläge und Rückmeldungen während der Entwicklung.