Verteilungen sind die am häufigsten verwendeten, viele reale Daten sind leider nicht regular. Bei extrem verzerrten Daten ist es für uns verlockend, Log -Transformationen zu verwenden, um die Verteilung zu normalisieren und die Varianz zu stabilisieren. Ich habe kürzlich an einem Projekt gearbeitet, in dem ich den Energieverbrauch von Trainings -KI -Modellen analysierte, wobei Daten von Epoch AI (1) verwendet wurden. Es gibt keine offiziellen Daten zum Energieverbrauch jedes Modells. Daher habe ich sie berechnet, indem ich die Leistung jedes Modells mit seiner Trainingszeit multipliziert habe. Die neue Variable, Energie (in kWh), warfare zusammen mit einigen extremen und übertriebenen Ausreißern sehr rechts (Abb. 1).

Um diese Schiefe und Heteroskedastizität anzugehen, warfare mein erster Instinkt, eine logarithmische Transformation auf die Energievariable anzuwenden. Die Verteilung von log (Energie) sah viel normaler aus (Abb. 2), und ein Shapiro-Wilk-Take a look at bestätigte die Grenznormalität (P ≈ 0,5).

Modellierungsdilemma: Log -Transformation gegen Log Hyperlink
Die Visualisierung sah intestine aus, aber als ich zur Modellierung überging, sah ich ein Dilemma aus: Sollte ich das modellieren Log-transformierte Antwortvariable (log(Y) ~ X)Anwesend oder sollte ich das modellieren ursprüngliche Antwortvariable mit a Log -Hyperlink -Funktion (Y ~ X, hyperlink = “log")? Ich betrachtete auch zwei Verteilungen – Gaußsche (normale) und Gamma -Verteilungen – und kombinierte jede Verteilung mit beiden logarithmischen Ansätzen. Dies gab mir vier verschiedene Modelle wie unten, die alle unter Verwendung von Rs verallgemeinerten linearen Modellen (GLM) angepasst wurden:
all_gaussian_log_link <- glm(Energy_kWh ~ Parameters +
Training_compute_FLOP +
Training_dataset_size +
Training_time_hour +
Hardware_quantity +
Training_hardware,
household = gaussian(hyperlink = "log"), knowledge = df)
all_gaussian_log_transform <- glm(log(Energy_kWh) ~ Parameters +
Training_compute_FLOP +
Training_dataset_size +
Training_time_hour +
Hardware_quantity +
Training_hardware,
knowledge = df)
all_gamma_log_link <- glm(Energy_kWh ~ Parameters +
Training_compute_FLOP +
Training_dataset_size +
Training_time_hour +
Hardware_quantity +
Training_hardware + 0,
household = Gamma(hyperlink = "log"), knowledge = df)
all_gamma_log_transform <- glm(log(Energy_kWh) ~ Parameters +
Training_compute_FLOP +
Training_dataset_size +
Training_time_hour +
Hardware_quantity +
Training_hardware + 0,
household = Gamma(), knowledge = df)Modellvergleich: AIC und diagnostische Diagramme
Ich habe die vier Modelle unter Verwendung von Akaike Data Criterion (AIC) verglichen, was ein Schätzer für Vorhersagefehler ist. Je niedriger die AIC ist, desto besser passt das Modell.
AIC(all_gaussian_log_link, all_gaussian_log_transform, all_gamma_log_link, all_gamma_log_transform)
df AIC
all_gaussian_log_link 25 2005.8263
all_gaussian_log_transform 25 311.5963
all_gamma_log_link 25 1780.8524
all_gamma_log_transform 25 352.5450Unter den vier Modellen haben Modelle, die logarithmisch transformierte Ergebnisse verwenden, viel niedrigere AIC-Werte als diejenigen, die Log-Hyperlinks verwenden. Da der Unterschied in der AIC zwischen logarithmisch transformierten und logarithmischen Hyperlink-Modellen erheblich warfare (311 und 352 gegenüber 1780 und 2005), habe ich auch die Diagnostikdiagramme untersucht, um zu validieren, dass logarithmisch transformierte Modelle besser passen:




Basierend auf den AIC-Werten und diagnostischen Diagrammen entschied ich mich, das gamma-Modell mit logarithmisch transformiertem Gamma voranzutreiben, da es den zweitniedrigsten AIC-Wert hatte und seine Residuen gegen angepasste Diagramme besser aussehen als das des logarithmischen Gauß-Modells.
Ich machte mich weiter, um zu untersuchen, welche erklärenden Variablen nützlich waren und welche Wechselwirkungen möglicherweise signifikant waren. Das endgültige Modell, das ich ausgewählt habe, warfare:
glm(system = log(Energy_kWh) ~ Training_time_hour * Hardware_quantity +
Training_hardware + 0, household = Gamma(), knowledge = df)Koeffizienten interpretieren
Als ich jedoch anfing, die Koeffizienten des Modells zu interpretieren, fühlte sich etwas aus. Da nur die Antwortvariable logarithmisch transformiert wurde, sind die Auswirkungen der Prädiktoren multiplikativ und wir müssen die Koeffizienten ausfindern, um sie wieder in die ursprüngliche Skala umzuwandeln. Eine Einheitserhöhung von 𝓍 multipliziert das Ergebnis 𝓎 mit Exp (β) oder jede zusätzliche Einheit in 𝓍 führt zu A (Exp (β)-1) × 100 % Änderung der 𝓎 (2).
Wenn wir uns die Ergebnistabelle des folgenden Modells ansehen, haben wir Training_time_Hour, Hardware_quantity, und ihr Interaktionsbegriff Training_time_hour: Hardware_quantity sind kontinuierliche Variablen, so dass ihre Koeffizienten Steigungen darstellen. In der Zwischenzeit, da ich in der Modellformel +0 angegeben habe, alle Ebenen der kategorialen Ebenen Training_hardware Wir wirken als Abschnitt, was bedeutet, dass jeder {Hardware} -Typ als Intercept β₀ fungierte, wenn seine entsprechende Dummy -Variable aktiv warfare.
> glm(system = log(Energy_kWh) ~ Training_time_hour * Hardware_quantity +
Training_hardware + 0, household = Gamma(), knowledge = df)
Coefficients:
Estimate Std. Error t worth Pr(>|t|)
Training_time_hour -1.587e-05 3.112e-06 -5.098 5.76e-06 ***
Hardware_quantity -5.121e-06 1.564e-06 -3.275 0.00196 **
Training_hardwareGoogle TPU v2 1.396e-01 2.297e-02 6.079 1.90e-07 ***
Training_hardwareGoogle TPU v3 1.106e-01 7.048e-03 15.696 < 2e-16 ***
Training_hardwareGoogle TPU v4 9.957e-02 7.939e-03 12.542 < 2e-16 ***
Training_hardwareHuawei Ascend 910 1.112e-01 1.862e-02 5.969 2.79e-07 ***
Training_hardwareNVIDIA A100 1.077e-01 6.993e-03 15.409 < 2e-16 ***
Training_hardwareNVIDIA A100 SXM4 40 GB 1.020e-01 1.072e-02 9.515 1.26e-12 ***
Training_hardwareNVIDIA A100 SXM4 80 GB 1.014e-01 1.018e-02 9.958 2.90e-13 ***
Training_hardwareNVIDIA GeForce GTX 285 3.202e-01 7.491e-02 4.275 9.03e-05 ***
Training_hardwareNVIDIA GeForce GTX TITAN X 1.601e-01 2.630e-02 6.088 1.84e-07 ***
Training_hardwareNVIDIA GTX Titan Black 1.498e-01 3.328e-02 4.501 4.31e-05 ***
Training_hardwareNVIDIA H100 SXM5 80GB 9.736e-02 9.840e-03 9.894 3.59e-13 ***
Training_hardwareNVIDIA P100 1.604e-01 1.922e-02 8.342 6.73e-11 ***
Training_hardwareNVIDIA Quadro P600 1.714e-01 3.756e-02 4.562 3.52e-05 ***
Training_hardwareNVIDIA Quadro RTX 4000 1.538e-01 3.263e-02 4.714 2.12e-05 ***
Training_hardwareNVIDIA Quadro RTX 5000 1.819e-01 4.021e-02 4.524 3.99e-05 ***
Training_hardwareNVIDIA Tesla K80 1.125e-01 1.608e-02 6.993 7.54e-09 ***
Training_hardwareNVIDIA Tesla V100 DGXS 32 GB 1.072e-01 1.353e-02 7.922 2.89e-10 ***
Training_hardwareNVIDIA Tesla V100S PCIe 32 GB 9.444e-02 2.030e-02 4.653 2.60e-05 ***
Training_hardwareNVIDIA V100 1.420e-01 1.201e-02 11.822 8.01e-16 ***
Training_time_hour:Hardware_quantity 2.296e-09 9.372e-10 2.450 0.01799 *
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
(Dispersion parameter for Gamma household taken to be 0.05497984)
Null deviance: NaN on 70 levels of freedom
Residual deviance: 3.0043 on 48 levels of freedom
AIC: 345.39Bei der Umwandlung der Hänge in die prozentuale Änderung der Antwortvariablen warfare der Effekt jeder kontinuierlichen Variablen nahezu Null, sogar leicht negativ: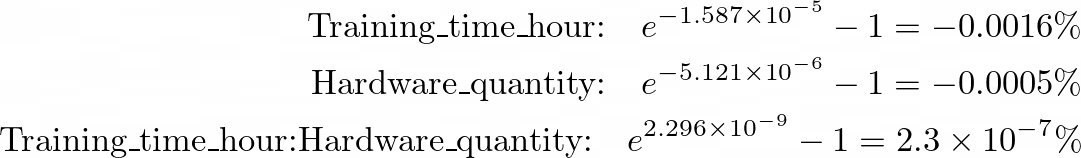
Alle Abschnitte wurden auch auf knapp 1 kWh auf der ursprünglichen Skala umgewandelt. Die Ergebnisse machten keinen Sinn, da mindestens einer der Hänge zusammen mit dem enormen Energieverbrauch wachsen sollte. Ich habe mich gefragt, ob die Verwendung des logarithmischen Modells mit denselben Prädiktoren unterschiedliche Ergebnisse liefern kann. Daher passe ich das Modell erneut an:
glm(system = Energy_kWh ~ Training_time_hour * Hardware_quantity +
Training_hardware + 0, household = Gamma(hyperlink = "log"), knowledge = df)
Coefficients:
Estimate Std. Error t worth Pr(>|t|)
Training_time_hour 1.818e-03 1.640e-04 11.088 7.74e-15 ***
Hardware_quantity 7.373e-04 1.008e-04 7.315 2.42e-09 ***
Training_hardwareGoogle TPU v2 7.136e+00 7.379e-01 9.670 7.51e-13 ***
Training_hardwareGoogle TPU v3 1.004e+01 3.156e-01 31.808 < 2e-16 ***
Training_hardwareGoogle TPU v4 1.014e+01 4.220e-01 24.035 < 2e-16 ***
Training_hardwareHuawei Ascend 910 9.231e+00 1.108e+00 8.331 6.98e-11 ***
Training_hardwareNVIDIA A100 1.028e+01 3.301e-01 31.144 < 2e-16 ***
Training_hardwareNVIDIA A100 SXM4 40 GB 1.057e+01 5.635e-01 18.761 < 2e-16 ***
Training_hardwareNVIDIA A100 SXM4 80 GB 1.093e+01 5.751e-01 19.005 < 2e-16 ***
Training_hardwareNVIDIA GeForce GTX 285 3.042e+00 1.043e+00 2.916 0.00538 **
Training_hardwareNVIDIA GeForce GTX TITAN X 6.322e+00 7.379e-01 8.568 3.09e-11 ***
Training_hardwareNVIDIA GTX Titan Black 6.135e+00 1.047e+00 5.862 4.07e-07 ***
Training_hardwareNVIDIA H100 SXM5 80GB 1.115e+01 6.614e-01 16.865 < 2e-16 ***
Training_hardwareNVIDIA P100 5.715e+00 6.864e-01 8.326 7.12e-11 ***
Training_hardwareNVIDIA Quadro P600 4.940e+00 1.050e+00 4.705 2.18e-05 ***
Training_hardwareNVIDIA Quadro RTX 4000 5.469e+00 1.055e+00 5.184 4.30e-06 ***
Training_hardwareNVIDIA Quadro RTX 5000 4.617e+00 1.049e+00 4.401 5.98e-05 ***
Training_hardwareNVIDIA Tesla K80 8.631e+00 7.587e-01 11.376 3.16e-15 ***
Training_hardwareNVIDIA Tesla V100 DGXS 32 GB 9.994e+00 6.920e-01 14.443 < 2e-16 ***
Training_hardwareNVIDIA Tesla V100S PCIe 32 GB 1.058e+01 1.047e+00 10.105 1.80e-13 ***
Training_hardwareNVIDIA V100 9.208e+00 3.998e-01 23.030 < 2e-16 ***
Training_time_hour:Hardware_quantity -2.651e-07 6.130e-08 -4.324 7.70e-05 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
(Dispersion parameter for Gamma household taken to be 1.088522)
Null deviance: 2.7045e+08 on 70 levels of freedom
Residual deviance: 1.0593e+02 on 48 levels of freedom
AIC: 1775Diesmal, Training_Time Und Hardware_quantität würde den Gesamtenergieverbrauch um 0,18% professional zusätzlicher Stunde bzw. 0,07% professional zusätzlichem Chip erhöhen. In der Zwischenzeit würde ihre Wechselwirkung den Energieverbrauch um 2 × 10 °%verringern. Diese Ergebnisse machten mehr Sinn als Training_Time kann bis zu 7000 Stunden erreichen und Hardware_quantität bis zu 16000 Einheiten.

Um die Unterschiede besser zu visualisieren, habe ich zwei Diagramme erstellt, in denen die Vorhersagen (als gestrichelte Linien gezeigte) von beiden Modellen verglichen wurden. Das linke Feld verwendete das logarithmisch transformierte Gamma-GLM-Modell, bei dem die gestrichelten Linien nahezu flach und nahezu Null waren, nirgends in der Nähe der angepassten festen Linien von Rohdaten. Andererseits verwendete das rechte Bedienfeld das Gamma-Gamma-Modell mit Protokoll, bei dem die gestrichelten Linien viel genauer mit den tatsächlichen Anpassungslinien ausgerichtet waren.
test_data <- df(, c("Training_time_hour", "Hardware_quantity", "Training_hardware"))
prediction_data <- df %>%
mutate(
pred_energy1 = exp(predict(glm3, newdata = test_data)),
pred_energy2 = predict(glm3_alt, newdata = test_data, kind = "response"),
)
y_limits <- c(min(df$Energy_KWh, prediction_data$pred_energy1, prediction_data$pred_energy2),
max(df$Energy_KWh, prediction_data$pred_energy1, prediction_data$pred_energy2))
p1 <- ggplot(df, aes(x = Hardware_quantity, y = Energy_kWh, shade = Training_time_group)) +
geom_point(alpha = 0.6) +
geom_smooth(technique = "lm", se = FALSE) +
geom_smooth(knowledge = prediction_data, aes(y = pred_energy1), technique = "lm", se = FALSE,
linetype = "dashed", measurement = 1) +
scale_y_log10(limits = y_limits) +
labs(x="{Hardware} Amount", y = "log of Vitality (kWh)") +
theme_minimal() +
theme(legend.place = "none")
p2 <- ggplot(df, aes(x = Hardware_quantity, y = Energy_kWh, shade = Training_time_group)) +
geom_point(alpha = 0.6) +
geom_smooth(technique = "lm", se = FALSE) +
geom_smooth(knowledge = prediction_data, aes(y = pred_energy2), technique = "lm", se = FALSE,
linetype = "dashed", measurement = 1) +
scale_y_log10(limits = y_limits) +
labs(x="{Hardware} Amount", shade = "Coaching Time Degree") +
theme_minimal() +
theme(axis.title.y = element_blank())
p1 + p2
Warum die Protokolltransformation fehlschlägt
Um den Grund zu verstehen, warum das logarithmische Modell die zugrunde liegenden Effekte nicht als logarithmisch verknüpfte Modell erfassen kann, gehen wir durch, was passiert, wenn wir eine Protokolltransformation auf die Antwortvariable anwenden:
Nehmen wir an, y ist gleich einer Funktion von x plus dem Fehlerbegriff:

Wenn wir eine Protokolltransformation auf Y anwenden, komprimieren wir tatsächlich sowohl F (x) als auch den Fehler:

Das heißt, wir modellieren eine völlig neue Antwortvariable, log (y). Wenn wir unsere eigene Funktion anschließen g (x) – in meinem Fall g (x) = Training_time_Hour*Hardware_quantity + Training_hardware– Es wird versucht, die kombinierten Effekte sowohl des „geschrumpften“ F (x) als auch des Fehlerbegriffs zu erfassen.
Im Gegensatz dazu modellieren wir, wenn wir einen Log -Hyperlink verwenden, immer noch das ursprüngliche y, nicht die transformierte Model. Stattdessen exponentiert das Modell unsere eigene Funktion G (x), um Y vorherzusagen.

Das Modell minimiert dann die Differenz zwischen dem tatsächlichen y und dem vorhergesagten Y. Auf diese Weise bleibt die Fehlerbegriffe auf der ursprünglichen Skala intakt:

Abschluss
Log-Transformieren einer Variablen entspricht nicht der Verwendung eines Protokoll-Hyperlinks und liefert möglicherweise nicht immer zuverlässige Ergebnisse. Unter der Haube verändert eine logarithmische Transformation die Variable selbst und verzerrt sowohl die Variation als auch die Rauschen. Das Verständnis dieses subtilen mathematischen Unterschieds hinter Ihren Modellen ist genauso wichtig wie der Versuch, das am besten passende Modell zu finden.
(1) Epoche ai. Daten zu bemerkenswerten KI -Modellen . Abgerufen von https://epoch.ai/knowledge/notable-ai-models
(2) Bibliothek der Universität von Virginia. Interpretation von Protokolltransformationen in einem linearen Modell.Abgerufen von https://library.virginia.edu/knowledge/articles/interpreting-log-transformations-in-a-linear-model