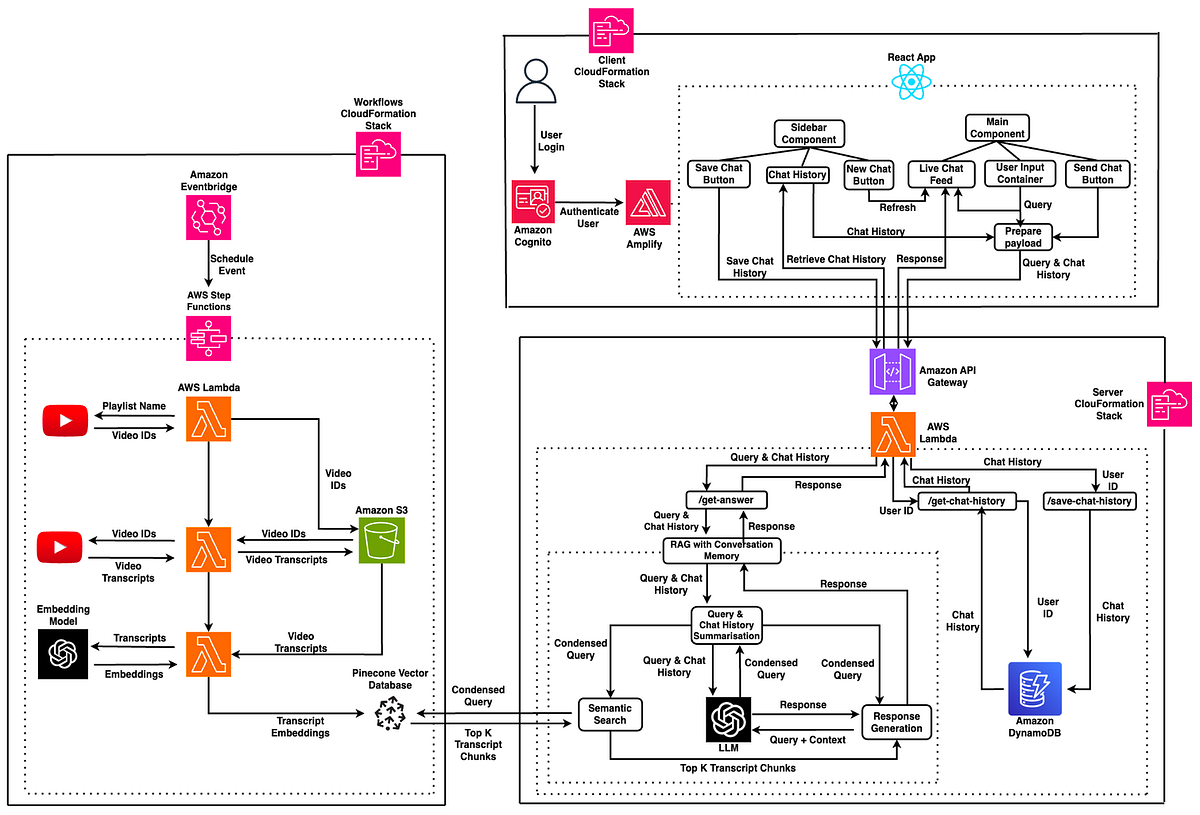
Als letztes besprechen wir den Prozess der Bereitstellung der einzelnen Komponenten auf AWS. Die Datenpipeline, das Backend und das Frontend sind jeweils in ihren eigenen CloudFormation-Stacks (Sammlungen von AWS-Ressourcen) enthalten. Dadurch, dass diese auf diese Weise isoliert bereitgestellt werden können, wird sichergestellt, dass die gesamte App während der Entwicklung nicht unnötigerweise erneut bereitgestellt wird. Ich verwende AWS SAM (Serverless Utility Mannequin), um die Infrastruktur für jede Komponente als Code bereitzustellen, und nutze dabei die SAM-Vorlagenspezifikation und die CLI:
- Die SAM-Vorlagenspezifikation – eine Kurzsyntax, die als Erweiterung von AWS CloudFormation dient, um Sammlungen von AWS-Ressourcen, deren Interaktion und alle erforderlichen Berechtigungen zu definieren und zu konfigurieren.
- Die SAM-CLI – Ein Befehlszeilentool, das unter anderem zum Erstellen und Bereitstellen von Ressourcen gemäß der Definition in einer SAM-Vorlage verwendet wird. Es übernimmt das Packen von Anwendungscode und Abhängigkeiten, die Konvertierung der SAM-Vorlage in die CloudFormation-Syntax und die Bereitstellung von Vorlagen als einzelne Stacks auf CloudFormation.
Anstatt die vollständigen Vorlagen (Ressourcendefinitionen) jeder Komponente beizufügen, werde ich bestimmte interessante Bereiche für jeden Dienst hervorheben, den wir im Verlauf des Beitrags besprochen haben.
Übergabe sensibler Umgebungsvariablen an AWS-Ressourcen:
Externe Komponenten wie die Youtube Knowledge API, die OpenAI API und die Pinecone API werden in der gesamten Anwendung stark genutzt. Obwohl es möglich ist, diese Werte fest in die CloudFormation-Vorlagen zu codieren und als „Parameter“ weiterzugeben, besteht eine sicherere Methode darin, für jeden Wert Geheimnisse in AWS SecretsManager zu erstellen und diese Geheimnisse in der Vorlage wie folgt zu referenzieren:
Parameters:
YoutubeDataAPIKey:
Kind: String
Default: '{{resolve:secretsmanager:youtube-data-api-key:SecretString:youtube-data-api-key}}'
PineconeAPIKey:
Kind: String
Default: '{{resolve:secretsmanager:pinecone-api-key:SecretString:pinecone-api-key}}'
OpenaiAPIKey:
Kind: String
Default: '{{resolve:secretsmanager:openai-api-key:SecretString:openai-api-key}}'
Definieren einer Lambda-Funktion:
Diese Einheiten serverlosen Codes bilden das Rückgrat der Datenpipeline und dienen als Einstiegspunkt zum Backend der Webanwendung. Um diese mit SAM bereitzustellen, müssen Sie lediglich den Pfad zum Code definieren, den die Funktion beim Aufruf ausführen soll, zusammen mit allen erforderlichen Berechtigungen und Umgebungsvariablen. Hier ist ein Beispiel für eine der in der Datenpipeline verwendeten Funktionen:
FetchLatestVideoIDsFunction:
Kind: AWS::Serverless::Perform
Properties:
CodeUri: ../code_uri/.
Handler: chatytt.youtube_data.lambda_handlers.fetch_latest_video_ids.lambda_handler
Insurance policies:
- AmazonS3FullAccess
Atmosphere:
Variables:
PLAYLIST_NAME:
Ref: PlaylistName
YOUTUBE_DATA_API_KEY:
Ref: YoutubeDataAPIKey
Abrufen der Definition der Datenpipeline in der Sprache der Amazon-Staaten:
Um Step Features als Orchestrator für die einzelnen Lambda-Funktionen in der Datenpipeline zu verwenden, müssen wir die Reihenfolge definieren, in der jede ausgeführt werden soll, sowie Konfigurationen wie maximale Wiederholungsversuche in Amazon States Language. Eine einfache Möglichkeit, dies zu tun, ist die Verwendung von Workflow-Studio in der Step Features-Konsole, um den Workflow schematisch zu erstellen und dann die automatisch generierte ASL-Definition des Workflows als Ausgangspunkt zu verwenden, der entsprechend geändert werden kann. Dies kann dann in der CloudFormation-Vorlage verknüpft werden, anstatt vor Ort definiert zu werden:
EmbeddingRetrieverStateMachine:
Kind: AWS::Serverless::StateMachine
Properties:
DefinitionUri: statemachine/embedding_retriever.asl.json
DefinitionSubstitutions:
FetchLatestVideoIDsFunctionArn: !GetAtt FetchLatestVideoIDsFunction.Arn
FetchLatestVideoTranscriptsArn: !GetAtt FetchLatestVideoTranscripts.Arn
FetchLatestTranscriptEmbeddingsArn: !GetAtt FetchLatestTranscriptEmbeddings.Arn
Occasions:
WeeklySchedule:
Kind: Schedule
Properties:
Description: Schedule to run the workflow as soon as per week on a Monday.
Enabled: true
Schedule: cron(0 3 ? * 1 *)
Insurance policies:
- LambdaInvokePolicy:
FunctionName: !Ref FetchLatestVideoIDsFunction
- LambdaInvokePolicy:
FunctionName: !Ref FetchLatestVideoTranscripts
- LambdaInvokePolicy:
FunctionName: !Ref FetchLatestTranscriptEmbeddings
Sehen Hier für die ASL-Definition, die für die in diesem Beitrag besprochene Datenpipeline verwendet wird.
Definieren der API-Ressource:
Da die API für die Internet-App separat vom Entrance-Finish gehostet wird, müssen wir beim Definieren der API-Ressource die CORS-Unterstützung (Cross-Origin Useful resource Sharing) aktivieren:
ChatYTTApi:
Kind: AWS::Serverless::Api
Properties:
StageName: Prod
Cors:
AllowMethods: "'*'"
AllowHeaders: "'*'"
AllowOrigin: "'*'"
Dadurch können die beiden Ressourcen frei miteinander kommunizieren. Die verschiedenen Endpunkte, die über eine Lambda-Funktion zugänglich gemacht werden, können wie folgt definiert werden:
ChatResponseFunction:
Kind: AWS::Serverless::Perform
Properties:
Runtime: python3.9
Timeout: 120
CodeUri: ../code_uri/.
Handler: server.lambda_handler.lambda_handler
Insurance policies:
- AmazonDynamoDBFullAccess
MemorySize: 512
Architectures:
- x86_64
Atmosphere:
Variables:
PINECONE_API_KEY:
Ref: PineconeAPIKey
OPENAI_API_KEY:
Ref: OpenaiAPIKey
Occasions:
GetQueryResponse:
Kind: Api
Properties:
RestApiId: !Ref ChatYTTApi
Path: /get-query-response/
Technique: publish
GetChatHistory:
Kind: Api
Properties:
RestApiId: !Ref ChatYTTApi
Path: /get-chat-history/
Technique: get
UpdateChatHistory:
Kind: Api
Properties:
RestApiId: !Ref ChatYTTApi
Path: /save-chat-history/
Technique: put
Definieren der React-App-Ressource:
AWS Amplify kann Anwendungen mithilfe eines Verweises auf das entsprechende Github-Repository und eines entsprechenden Zugriffstokens erstellen und bereitstellen:
AmplifyApp:
Kind: AWS::Amplify::App
Properties:
Identify: amplify-chatytt-client
Repository: <https://github.com/suresha97/ChatYTT>
AccessToken: '{{resolve:secretsmanager:github-token:SecretString:github-token}}'
IAMServiceRole: !GetAtt AmplifyRole.Arn
EnvironmentVariables:
- Identify: ENDPOINT
Worth: !ImportValue 'chatytt-api-ChatYTTAPIURL'
Sobald auf das Repository selbst zugegriffen werden kann, sucht Ampify nach einer Konfigurationsdatei mit Anweisungen zum Erstellen und Bereitstellen der App:
model: 1
frontend:
phases:
preBuild:
instructions:
- cd consumer
- npm ci
construct:
instructions:
- echo "VITE_ENDPOINT=$ENDPOINT" >> .env
- npm run construct
artifacts:
baseDirectory: ./consumer/dist
information:
- "**/*"
cache:
paths:
- node_modules/**/*
Als Bonus ist es auch möglich, den Prozess der kontinuierlichen Bereitstellung zu automatisieren, indem eine Zweigressource definiert wird, die überwacht und verwendet wird, um die App bei weiteren Commits automatisch erneut bereitzustellen:
AmplifyBranch:
Kind: AWS::Amplify::Department
Properties:
BranchName: essential
AppId: !GetAtt AmplifyApp.AppId
EnableAutoBuild: true
Wenn die Bereitstellung auf diese Weise abgeschlossen ist, ist sie über den von der AWS Amplify-Konsole bereitgestellten Hyperlink für jeden zugänglich. Eine aufgezeichnete Demo der App, auf die auf diese Weise zugegriffen wird, finden Sie hier Hier: