eine kleine NumPy-Projektreihe, in der ich es tatsächlich versuche etwas bauen mit NumPy, anstatt nur zufällige Funktionen und Dokumentation durchzugehen. Ich hatte immer das Gefühl, dass der beste Weg zum Lernen darin besteht, etwas zu tun. Deshalb wollte ich in diesem Projekt etwas sowohl Praktisches als auch Persönliches schaffen.
Die Idee conflict einfach: Analysieren Sie meine täglichen Gewohnheiten – Schlaf, Lernstunden, Bildschirmzeit, Bewegung und Stimmung – und sehen Sie, wie sie sich auf meine Produktivität und mein allgemeines Wohlbefinden auswirken. Die Daten sind nicht actual; Es ist fiktiv und über einen Zeitraum von 30 Tagen simuliert. Aber das Ziel ist nicht die Genauigkeit der Daten – es geht darum zu lernen, wie man NumPy sinnvoll nutzt.
Lassen Sie uns den Prozess Schritt für Schritt durchgehen.
Schritt 1 – Laden und Verstehen der Daten
Ich begann damit, ein einfaches NumPy-Array zu erstellen, das 30 Zeilen (eine für jeden Tag) und sechs Spalten enthielt – jede Spalte repräsentierte eine andere Gewohnheitsmetrik. Dann habe ich es als gespeichert .npy Datei, damit ich sie später problemlos laden kann.
# TODO: Import NumPy and cargo the .npy information file
import numpy as np
information = np.load(‘activity_data.npy’)Nach dem Laden wollte ich bestätigen, dass alles wie erwartet aussah. Additionally habe ich das überprüft Type (um zu wissen, wie viele Zeilen und Spalten es gab) und die Anzahl der Dimensionen (um zu bestätigen, dass es sich um eine 2D-Tabelle und nicht um eine 1D-Liste handelt).
# TODO: Print array form, first few rows, and so forth.
information.form
information.ndimAUSGABE: 30 Zeilen, 6 Spalten und ndim=2
Ich habe auch die ersten paar Zeilen ausgedruckt, um visuell zu bestätigen, dass jeder Wert in Ordnung conflict – zum Beispiel, dass die Schlafstunden nicht negativ waren oder dass die Stimmungswerte in einem angemessenen Bereich lagen.
# TODO: High 5 rows
information(:5)Ausgabe:
array((( 1. , 6.5, 5. , 4.2, 20. , 6. ),
( 2. , 7.2, 6. , 3.1, 35. , 7. ),
( 3. , 5.8, 4. , 5.5, 0. , 5. ),
( 4. , 8. , 7. , 2.5, 30. , 8. ),
( 5. , 6. , 5. , 4.8, 10. , 6. )))Schritt 2 – Validierung der Daten
Bevor ich eine Analyse durchführte, wollte ich sicherstellen, dass die Daten Sinn ergeben. Dies ist etwas, was wir bei der Arbeit mit fiktiven Daten oft überspringen, aber es ist dennoch eine gute Vorgehensweise.
Additionally habe ich nachgeschaut:
- Keine negativen Schlafstunden
- Keine Stimmung hat einen Wert unter 1 oder über 10
Für den Schlaf bedeutete das, die Schlafspalte (Index 1 in meinem Array) auszuwählen und zu prüfen, ob Werte unter Null lagen.
# Ensure values are affordable (no unfavorable sleep)
information(:, 1) < 0Ausgabe:
array((False, False, False, False, False, False, False, False, False,
False, False, False, False, False, False, False, False, False,
False, False, False, False, False, False, False, False, False,
False, False, False))Das bedeutet, dass es keine Nachteile gibt. Dann habe ich das Gleiche für die Stimmung gemacht. Ich zählte, um herauszufinden, dass die Stimmungsspalte den Index 5 hatte, und überprüfte, ob einer unter 1 oder über 10 lag.
# Is temper out of vary?
information(:, 5) < 1
information(:, 5) > 10Wir haben die gleiche Ausgabe erhalten.
Alles sah intestine aus, additionally konnten wir weitermachen.
Schritt 3 – Aufteilen der Daten in Wochen
Ich hatte 30 Tage Daten und wollte sie Woche für Woche analysieren. Der erste Instinkt conflict, NumPys zu verwenden cut up() Funktion, aber das ist fehlgeschlagen, weil 30 nicht gleichmäßig durch 4 teilbar ist. Additionally habe ich stattdessen verwendet np.array_split()was ungleichmäßige Teilungen ermöglicht.
Das hat mir Folgendes gebracht:
- Woche 1 → 8 Tage
- Woche 2 → 8 Tage
- Woche 3 → 7 Tage
- Woche 4 → 7 Tage
# TODO: Slice information into week 1, week 2, week 3, week 4
weekly_data = np.array_split(information, 4)
weekly_dataAusgabe:
(array((( 1. , 6.5, 5. , 4.2, 20. , 6. ),
( 2. , 7.2, 6. , 3.1, 35. , 7. ),
( 3. , 5.8, 4. , 5.5, 0. , 5. ),
( 4. , 8. , 7. , 2.5, 30. , 8. ),
( 5. , 6. , 5. , 4.8, 10. , 6. ),
( 6. , 7.5, 6. , 3.3, 25. , 7. ),
( 7. , 8.2, 3. , 6.1, 40. , 7. ),
( 8. , 6.3, 4. , 5. , 15. , 6. ))),
array((( 9. , 7. , 6. , 3.2, 30. , 7. ),
(10. , 5.5, 3. , 6.8, 0. , 5. ),
(11. , 7.8, 7. , 2.9, 25. , 8. ),
(12. , 6.1, 5. , 4.5, 15. , 6. ),
(13. , 7.4, 6. , 3.7, 30. , 7. ),
(14. , 8.1, 2. , 6.5, 50. , 7. ),
(15. , 6.6, 5. , 4.1, 20. , 6. ),
(16. , 7.3, 6. , 3.4, 35. , 7. ))),
array(((17. , 5.9, 4. , 5.6, 5. , 5. ),
(18. , 8.3, 7. , 2.6, 30. , 8. ),
(19. , 6.2, 5. , 4.3, 10. , 6. ),
(20. , 7.6, 6. , 3.1, 25. , 7. ),
(21. , 8.4, 3. , 6.3, 40. , 7. ),
(22. , 6.4, 4. , 5.1, 15. , 6. ),
(23. , 7.1, 6. , 3.3, 30. , 7. ))),
array(((24. , 5.7, 3. , 6.7, 0. , 5. ),
(25. , 7.9, 7. , 2.8, 25. , 8. ),
(26. , 6.2, 5. , 4.4, 15. , 6. ),
(27. , 7.5, 6. , 3.5, 30. , 7. ),
(28. , 8. , 2. , 6.4, 50. , 7. ),
(29. , 6.5, 5. , 4.2, 20. , 6. ),
(30. , 7.4, 6. , 3.6, 35. , 7. ))))Jetzt lagen die Daten in vier Blöcken vor, und ich konnte jeden einzelnen Teil problemlos analysieren.
Schritt 4 – Berechnung der wöchentlichen Kennzahlen
Ich wollte ein Gefühl dafür bekommen, wie sich jede Gewohnheit von Woche zu Woche verändert. Deshalb habe ich mich auf vier Hauptdinge konzentriert:
- Durchschnittlicher Schlaf
- Durchschnittliche Studienstunden
- Durchschnittliche Bildschirmzeit
- Durchschnittlicher Stimmungswert
Ich habe das Array jeder Woche in einer separaten Variablen gespeichert und dann verwendet np.imply() um die Durchschnittswerte für jede Metrik zu berechnen.
Durchschnittliche Schlafstunden
# retailer into variables
week_1 = weekly_data(0)
week_2 = weekly_data(1)
week_3 = weekly_data(2)
week_4 = weekly_data(3)
# TODO: Compute common sleep
week1_avg_sleep = np.imply(week_1(:, 1))
week2_avg_sleep = np.imply(week_2(:, 1))
week3_avg_sleep = np.imply(week_3(:, 1))
week4_avg_sleep = np.imply(week_4(:, 1))Durchschnittliche Studienstunden
# TODO: Compute common research hours
week1_avg_study = np.imply(week_1(:, 2))
week2_avg_study = np.imply(week_2(:, 2))
week3_avg_study = np.imply(week_3(:, 2))
week4_avg_study = np.imply(week_4(:, 2))Durchschnittliche Bildschirmzeit
# TODO: Compute common display time
week1_avg_screen = np.imply(week_1(:, 3))
week2_avg_screen = np.imply(week_2(:, 3))
week3_avg_screen = np.imply(week_3(:, 3))
week4_avg_screen = np.imply(week_4(:, 3))Durchschnittlicher Stimmungswert
# TODO: Compute common temper rating
week1_avg_mood = np.imply(week_1(:, 5))
week2_avg_mood = np.imply(week_2(:, 5))
week3_avg_mood = np.imply(week_3(:, 5))
week4_avg_mood = np.imply(week_4(:, 5))Um alles leichter lesbar zu machen, habe ich die Ergebnisse dann intestine formatiert.
# TODO: Show weekly outcomes clearly
print(f”Week 1 — Common sleep: {week1_avg_sleep:.2f} hrs, Examine: {week1_avg_study:.2f} hrs, “
f”Display time: {week1_avg_screen:.2f} hrs, Temper rating: {week1_avg_mood:.2f}”)
print(f”Week 2 — Common sleep: {week2_avg_sleep:.2f} hrs, Examine: {week2_avg_study:.2f} hrs, “
f”Display time: {week2_avg_screen:.2f} hrs, Temper rating: {week2_avg_mood:.2f}”)
print(f”Week 3 — Common sleep: {week3_avg_sleep:.2f} hrs, Examine: {week3_avg_study:.2f} hrs, “
f”Display time: {week3_avg_screen:.2f} hrs, Temper rating: {week3_avg_mood:.2f}”)
print(f”Week 4 — Common sleep: {week4_avg_sleep:.2f} hrs, Examine: {week4_avg_study:.2f} hrs, “
f”Display time: {week4_avg_screen:.2f} hrs, Temper rating: {week4_avg_mood:.2f}”)Ausgabe:
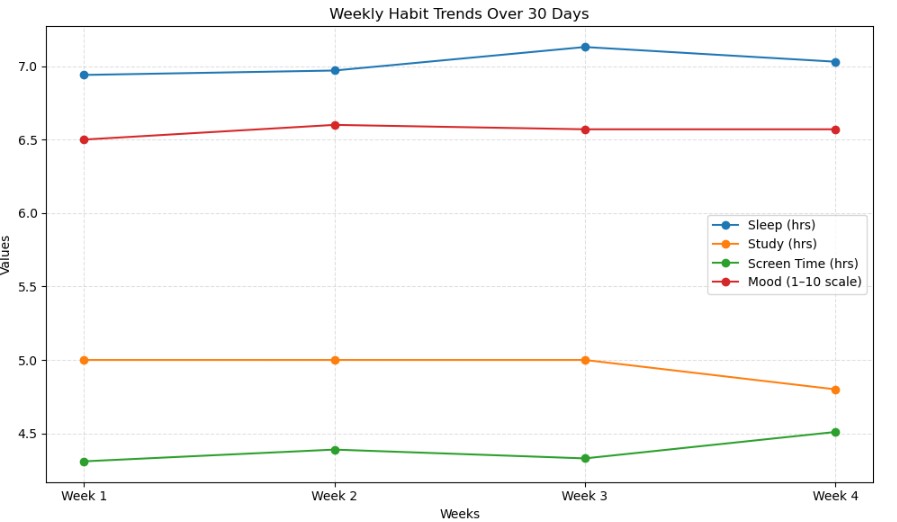
Week 1 – Common sleep: 6.94 hrs, Examine: 5.00 hrs, Display time: 4.31 hrs, Temper rating: 6.50
Week 2 – Common sleep: 6.97 hrs, Examine: 5.00 hrs, Display time: 4.39 hrs, Temper rating: 6.62
Week 3 – Common sleep: 7.13 hrs, Examine: 5.00 hrs, Display time: 4.33 hrs, Temper rating: 6.57
Week 4 – Common sleep: 7.03 hrs, Examine: 4.86 hrs, Display time: 4.51 hrs, Temper rating: 6.57Schritt 5 – Die Ergebnisse verstehen
Nachdem ich die Zahlen ausgedruckt hatte, tauchten einige Muster auf.
Mein Schlafstunden waren in den ersten zwei Wochen ziemlich konstant (ca. 6,9 Stunden), aber in der dritten Woche stiegen sie sprunghaft auf ca. 7,1 Stunden. Das bedeutet, dass ich im Laufe des Monats „besser geschlafen“ habe. Bis zur vierten Woche waren es ungefähr 7,0 Stunden.
Für Lernstundenes conflict das Gegenteil. In den Wochen eins und zwei waren es durchschnittlich etwa fünf Stunden professional Tag, in der vierten Woche waren es jedoch nur etwa vier Stunden. Grundsätzlich habe ich stark angefangen, aber langsam an Schwung verloren – was sich, ehrlich gesagt, ungefähr richtig anhört.
Dann kam Bildschirmzeit. Das tat ein bisschen weh. In der ersten Woche waren es ungefähr 4,3 Stunden professional Tag, und jede Woche wurden die Werte immer höher. Der klassische Zyklus, bei dem man früh produktiv ist und später im Monat langsam in weitere „Scroll-Pausen“ übergeht.
Endlich conflict es da Stimmung. Mein Stimmungswert begann in der ersten Woche bei etwa 6,5, stieg in der zweiten Woche leicht auf 6,6 und blieb dann für den Relaxation des Zeitraums auf diesem Wert. Es hat sich nicht dramatisch verändert, aber es conflict interessant, einen kleinen Anstieg in der zweiten Woche zu sehen – kurz bevor meine Lernstunden sanken und meine Bildschirmzeit zunahm.
Um die Dinge interaktiv zu gestalten, dachte ich, dass es großartig wäre, sie mit Matplotlib zu visualisieren.

Schritt 6 – Auf der Suche nach Mustern
Nachdem ich nun die Zahlen hatte, wollte ich es wissen Warum In der zweiten Woche stieg meine Laune.
Additionally habe ich die Wochen nebeneinander verglichen. Die zweite Woche hatte im Vergleich zu den späteren Wochen guten Schlaf, viele Lernstunden und relativ wenig Bildschirmzeit.
Das könnte erklären, warum mein Stimmungswert dort seinen Höhepunkt erreichte. Obwohl ich in der dritten Woche mehr schlief, begannen meine Lernstunden zu sinken – vielleicht ruhte ich mich mehr aus, schaffte aber weniger, was meine Stimmung nicht so sehr verbesserte, wie ich erwartet hatte.
Das hat mir an dem Projekt gefallen: Es geht nicht darum, dass die Daten echt sind, sondern darum, wie man das machen kann Verwenden Sie NumPy um Muster, Zusammenhänge und kleine Erkenntnisse zu erforschen. Selbst fiktive Daten können eine Geschichte erzählen, wenn man sie richtig betrachtet.
Schritt 7 – Zusammenfassung und nächste Schritte
In diesem kleinen Projekt habe ich ein paar wichtige Dinge gelernt – sowohl über NumPy als auch über die Strukturierung einer solchen Analyse.
Wir begannen mit einer Rohliste fiktiver Alltagsgewohnheiten, lernten, deren Struktur und Gültigkeit zu überprüfen, sie in sinnvolle Abschnitte (Wochen) aufzuteilen und verwendeten dann einfache NumPy-Operationen, um jedes Section zu analysieren.
Es handelt sich um ein kleines Projekt, das Sie daran erinnert, dass Datenanalyse nicht immer komplex sein muss. Manchmal geht es nur darum, einfache Fragen zu stellen wie „Wie verändert sich meine Bildschirmzeit im Laufe der Zeit?“ oder „Wann fühle ich mich am besten?“
Wenn ich das weiterführen möchte (was ich wahrscheinlich tun werde), gibt es so viele Richtungen, in die ich gehen kann:
- Finden Sie die beste und schlechteste Tage gesamt
- Vergleichen Wochentage vs. Wochenenden
- Oder erstellen Sie sogar einen einfachen „Wohlbefindens-Rating“, der auf der Kombination mehrerer Gewohnheiten basiert
Aber das wird wahrscheinlich für den nächsten Teil der Serie sein.
Im Second bin ich froh, dass ich NumPy auf etwas anwenden konnte, das sich actual und nachvollziehbar anfühlt – nicht nur abstrakte Arrays und Zahlen, sondern auch Gewohnheiten und Emotionen. Das ist die Artwork des Lernens, die hängen bleibt.
Danke fürs Lesen.
Wenn Sie die Serie verfolgen, versuchen Sie, sie anhand Ihrer eigenen fiktiven Daten nachzubilden. Selbst wenn Ihre Zahlen zufällig sind, lernen Sie mit diesem Prozess, wie Sie Arrays wie ein Profi aufteilen, aufteilen und analysieren.