Einführung
Im „sich immer schnell verändern”(!) Das Verständnis von Daten und KI -Architektur battle noch nie kritischer. Allerdings ist etwas, was viele Führungskräfte übersehen, die Bedeutung der Datenteamstruktur.
Während viele von Ihnen dies lesen, identifizieren sich wahrscheinlich als Die Information -Group, etwas, das die meisten nicht erkennen, ist, wie begrenzt diese Denkweise sein kann.
In der Tat wirken sich unterschiedliche Teamstrukturen und Fertigkeitsanforderungen erheblich auf die Fähigkeit eines Unternehmens aus, Daten und KI zu verwenden, um sinnvolle Ergebnisse zu erzielen. Um dies zu verstehen, ist es hilfreich, an eine Analogie zu denken.
Stellen Sie sich einen zweiköpfigen Haushalt vor. John arbeitet von zu Hause aus und Jane geht ins Büro. Es gibt eine Reihe von Hausverwalter Jane, die sich auf John verlässt, was viel einfacher ist, da er die meiste Zeit zu Hause ist.
Jane und John haben Kinder und nachdem sie ein bisschen aufgewachsen sind, hat John doppelt so viel Administrator zu tun! Zum Glück sind die Kinder für die Grundlagen ausgebildet; Sie können sich waschen, aufgeräumt und sogar gelegentlich ein bisschen mit etwas Zwang ausbacken.
Während die Kinder erwachsen werden, ziehen Johns Eltern ein. Im Laufe der Zeit hat sich Johns Rolle ziemlich verändert! Aber er hat es immer zu einer glücklichen, nuklearen Familie gemacht – dank John und Jane.
Zurück zu Daten – John ist ein bisschen wie das Information -Group, und alle anderen sind ein Area -Experte. Sie verlassen sich auf John, aber auf unterschiedliche Weise. Dies hat sich im Laufe der Zeit stark verändert, und wenn es nicht hätte eine Katastrophe gewesen sein.
Im Relaxation dieses Artikels werden wir Johns Reise von einem zentralisierten Hub-and-Spoke zu einem Plattform-Mesh-Information-Group untersuchen.
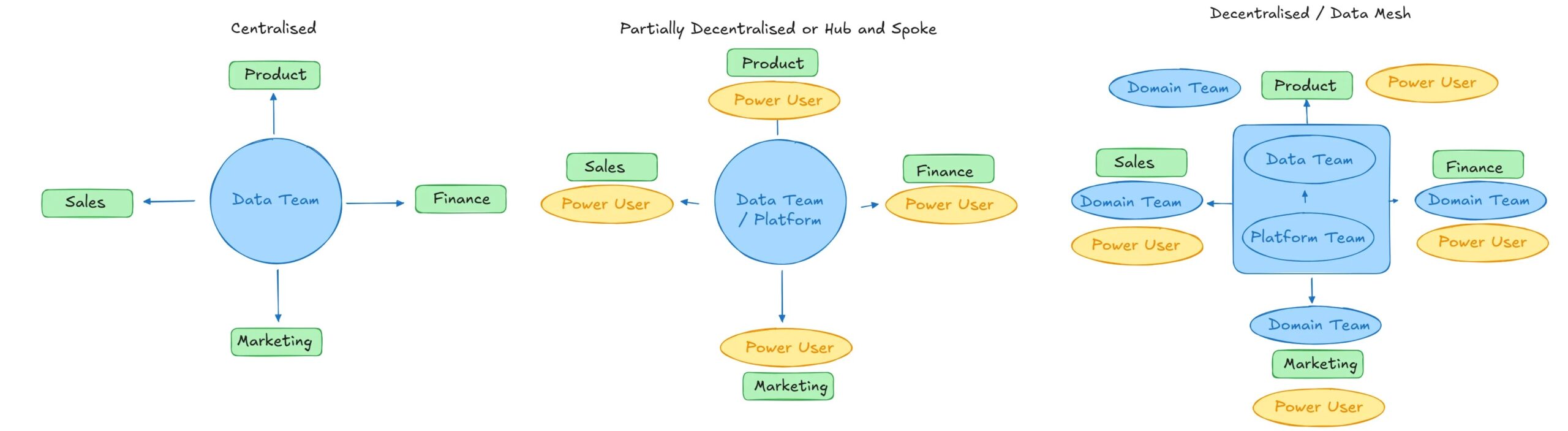
Zentralisierte Groups
Ein zentrales Group ist für viele Dinge verantwortlich, die Ihnen bekannt sein werden:
- Kerndatenplattform und Architektur: Die Frameworks und Instruments, die zur Erleichterung von Daten und KI -Workloads verwendet werden.
- Daten- und KI -Engineering: Zentralisierung und Reinigungsdatensätze; Strukturierung unstrukturierter Daten für KI -Workloads
- BI: Erstellen von Dashboards zur Visualisierung von Erkenntnissen
- AI und ML: Das Coaching und die Bereitstellung von Modellen für die oben genannten sauberen Daten
- Befürwortung für den Wert von Daten und Schulungen, um zu verstehen, wie BI -Instruments verwendet werden können
Dies ist eine Menge Arbeit für ein paar Leute! Tatsächlich ist es praktisch unmöglich, all dies auf einmal zu nageln. Es ist am besten, die Dinge klein und überschaubar zu halten, sich auf einige wichtige Anwendungsfälle zu konzentrieren und leistungsstarke Werkzeuge zu nutzen, um frühzeitig einen Vorsprung zu erzielen.
Möglicherweise erhalten Sie sogar ein Kindermädchen- oder Au -Paar, um bei der Arbeit zu helfen (in diesem Fall – Berater).
Aber dieses Muster hat Mängel. Es ist leicht, in die zu fallen Silofalleein Szenario, in dem das zentrale Group zu einem großen Engpass für Daten und KI -Anfragen wird. Datenteams müssen auch Domänenwissen von Domänenexperten erwerben, um Anfragen effektiv zu beantworten, was ebenfalls zeitaufwändig und hart ist.

Ein Ausweg besteht darin, das Group zu erweitern. Mehr Menschen bedeuten mehr Ausgabe. Es gibt jedoch bessere modernere Ansätze, die die Dinge noch schneller laufen lassen können.
Aber es gibt nur einen John. Was kann er additionally tun?

Teilweise dezentralisiert oder Hub und sprach
Das teilweise dezentrale Setup ist ein attraktives Modell für mittelgroße Organisationen oder kleine, technisch zuerst, bei denen es gibt Technische Fähigkeiten außerhalb des Datenteams.
In der einfachsten Kind wird das Information -Group die BI -Infrastruktur aufrechterhalten, aber nicht der Inhalt selbst. Dies bleibt „Energy -Person“ überlassen, die dies selbst in die Hand nehmen und die BI selbst bauen.
Dies trifft natürlich auf alle möglichen Probleme wie die Silofalle, DatenentdeckungGovernance und Verwirrung. Verwirrung ist besonders schmerzhaft, wenn Menschen, die gesagt werden, dass sie sich selbst erhalten, versuchen, zu scheitern, da die Daten mangelnde Verständnissen mangeln.
Ein immer beliebterer Ansatz ist, dass zusätzliche Schichten des Stapels geöffnet werden. Da ist das Aufstieg des Analyseingenieurs Und Datenanalysten übernehmen zunehmend mehr Verantwortung. Dies beinhaltet die Verwendung von Instruments, die Durchführung von Datenmodellierung, das Erstellen von Finish-to-Finish-Pipelines und das Einsetzen des Unternehmens.
Dies hat zu enormen Problemen geführt, wenn sie falsch implementiert werden. Sie würden Ihren fünfjährigen Sohn nicht um die Obhut Ihrer Ältesten kümmern und sich unbeaufsichtigt um das Haus kümmern.
Insbesondere führt ein Mangel an grundlegenden Datenmodellierungsprinzipien und Information Warehouse -Motoren zu Modellverbreitung und Spiralkosten. Es gibt zwei klassische Beispiele.

Eine davon ist, wenn mehrere Personen versuchen, dasselbe wie Umsatz zu definieren. Advertising and marketing, Finanzen und Produkt haben alle eine andere Model. Dies führt zu unvermeidlichen Argumenten bei vierteljährlichen Geschäftsprüfungen, wenn jede Abteilung mit einer anderen Anzahl berichtet – Analyse -Lähmung.
Der andere zählt. Nehmen wir an, Finance will Einnahmen für den Monat, aber das Produkt möchte wissen, was es sieben Tage lang rollt. „Das ist einfach“, sagt der Analyst. „Ich werde nur einige materialisierte Ansichten mit diesen Metriken in ihnen erstellen.“
Wie jeder Dateningenieur weiß, ist dieser Rolling -Zählbetrieb ziemlich teuer, insbesondere wenn die Granularität tagsüber oder stundenweise sein muss. Seit dann benötigen Sie einen Kalender, um das Modell zu „fächern“. Bevor Sie es wissen, gibt es rolling_30_day_sales Anwesend rolling_7_day_sales Anwesend rolling_45_day_sales und so weiter. Diese Modelle kosten eine Größenordnung mehr als erforderlich.
Einfach nach der niedrigsten Granularität zu fragen (täglich), das Materialieren und die Erstellung von Ansichten stromabwärts gelöst werden, kann dieses Downside lösen, müsste jedoch eine zentrale Ressource erfordern.
Ein frühes Hub- und Spoke -Modell muss eine klare Verantwortung haben, wenn das Wissen außerhalb des Datenteams jung oder jugendlich ist.

Wenn Groups wachsen, entstehen auch Legacy, nur Code-Frameworks wie Apache Airflow, zu einem Downside: mangelnde Sichtbarkeit. Personen außerhalb des Datenteams, die versuchen, zu verstehen, was los ist, werden auf zusätzliche Instruments angewiesen, um zu verstehen, was Finish-to-Finish-UIs passiert, da die UIs mit Legacy keine Metadaten aus verschiedenen Quellen aggregieren.
Es ist unerlässlich, diese Informationen an Domänenexperten zu ermitteln. Wie oft wurde Ihnen mitgeteilt, dass die „Daten nicht richtig aussehen“, nur um zu erkennen, nachdem Sie alles manuell verfolgt haben, dass es sich um ein Downside auf der Seite des Datenproduzenten handelte?
Durch die Erhöhung der Sichtbarkeit sind Domänenexperten direkt mit Eigentümern von Quelldaten oder -prozessen verbunden, wodurch die Korrekturen schneller sein können. Dadurch werden unnötige Final, Kontextschalter und Tickets für das Information -Group entfernt.
Hub und sprachen (rein)
Ein reiner Hub und ein reine Hub sind ein bisschen wie die Delegation Ihrer jugendlichen Kinder mit spezifischen Verantwortung in klaren Leitplanken. Sie geben ihnen nicht nur Aufgaben, die Mülleimer herauszunehmen und ihr Zimmer zu reinigen – Sie fragen nach dem, was Sie wollen, wie ein „sauberes und ordentliches Zimmer“, und Sie vertrauen darauf, dass sie dies tun. Anreize funktionieren hier intestine.
In einem reinen Hub- und Spoke -Ansatz verwaltet das Information -Group die Plattform und lässt sie sie nutzen. Sie erstellen die Frameworks zum Erstellen und Bereitstellen von KI- und Datenpipelines und verwalten die Zugriffskontrolle.
Domänenexperten können Sachen von Finish-to-Finish erstellen, wenn sie müssen. Dies bedeutet, dass sie Daten verschieben, modellieren können, die Pipeline orchestrieren und sie mit KI oder Dashboards aktivieren können, wie sie es für richtig halten.
Oft wird das zentrale Group auch ein bisschen davon tun. Wenn Datenmodelle in allen Domänen komplex und überlappend sind, sollten sie quick immer die Bereitstellung von Kerndatenmodellen übernehmen. Der Schwanz sollte den Hund nicht wedeln.

Dies ähnelt einer Datenprodukt -Denkweise – während ein Finanzteam das Eigentum für die Investition und Reinigung von ERP -Daten übernehmen könnte, würde das zentrale Group wichtige Datenprodukte wie die Tabelle der Kunden oder die Tabelle für Rechnungen besitzen.
Diese Struktur ist sehr mächtig, da sie sehr kollaborativ ist. Es funktioniert oft nur, wenn Area -Groups ein ziemlich hohes Maß an technischer Kenntnis haben.
Hier gibt es immer Plattformen, die gemeinsame Code und No-Code zusammenfassen, da es immer eine harte technische Abhängigkeit vom zentralen Group gibt.
Ein weiteres Merkmal dieses Musters ist Coaching und Unterstützung. Das zentrale Group oder Hub verbringen einige Zeit damit, die Speichen zu unterstützen und zu verbessern, um KI- und Datenworkflows effizient in Leitplanken zu erstellen.
Auch hier ist es schwierig, die Sichtbarkeit mit älteren Orchestrierungsrahmen zu bieten. Zentrale Groups werden belastet sein, wie die Metadatenspeicher auf dem neuesten Stand zu halten, z. B. Datenkataloge, sodass Geschäftsbenutzer verstehen können, was los ist.
Die Different – Upskill -Area -Experten, um tiefe Python -Experience -Lernrahmen mit steilen Lernkurven zu haben, ist noch schwieriger zu ziehen.
Plattformgitter/Datenprodukt
Der natürliche Endpunkt in unserer theoretischen Haushaltsreise führt uns zu den viel kritisierten Datennetz oder Plattform -Mesh -Ansatz.
In diesem Haushalt wird erwartet, dass alle ihre Verantwortung sind. Kinder sind alle erwachsen und können sich verlassen, um das Haus in Ordnung zu halten und sich um seine Bewohner zu kümmern. Es gibt enge Zusammenarbeit und jeder arbeitet nahtlos zusammen.
Klingt ziemlich idealistisch, denkst du nicht!?
In der Praxis ist es selten so einfach. Es ist eine todsichere Möglichkeit, die Kontrolle zu verlieren und die Dinge zu verlangsamen.
Selbst wenn Sie Instruments zwischen Groups standardisieren würden, würden Finest Practices immer noch leiden.
Ich habe mit unzähligen Groups in massiven Organisationen wie Einzelhandelsketten oder Fluggesellschaften gesprochen, und das Vermeiden eines Netzes ist keine Possibility, da mehrere Geschäftsabteilungen voneinander abhängen.
Diese Groups verwenden unterschiedliche Instruments. Einige nutzen Luftstrominstanzen und ältere Rahmenbedingungen, die vor Jahren von Beratern erstellt wurden. Andere verwenden die neueste Technologie und einen vollständigen, aufgeblähten, modernen Datenstapel.
Sie alle kämpfen mit dem gleichen Downside; Zusammenarbeit, Kommunikation und orchestrierende Flüsse in verschiedenen Groups.
Die Implementierung einer einzigen übergreifenden Plattform zum Erstellen von Daten und KI -Workflows hier kann helfen. A Einheitliche Kontrollebene ist quick wie ein Orchestrator von Orchestratoren, der Metadaten an verschiedenen Orten aggregiert und zeigt, dass die Abstammungslinien zwischen den Domänen enden.
Natürlich sorgt es für ein effektives Kontrollflugzeug, in dem sich jeder versammeln kann, um Pipelines zu debuggen, zu kommunizieren und sich zu erholen – alles ohne sich auf ein zentrales Information Engineering -Group zu verlassen, das sonst ein Engpass wäre.
Es gibt klare Analogien dafür in der Software program -Engineering. Oft führt Code zu Protokollen, die von einem einzelnen Software wie Datadog zusammengefasst werden. Diese Plattformen bieten einen einzelnen Ort, um alles zu sehen (oder nicht), Warnungen und Zusammenarbeit für die Auflösung von Vorfällen.
Zusammenfassung
Organisationen sind wie Familien. So sehr wir die Idee einer großen, glücklichen und autarken Familie mögen, es gibt oft Verantwortlichkeiten, die wir tragen müssen, damit die Dinge zunächst zum Laufen bringen.
Während sie reifen, kommen die Mitglieder der Unabhängigkeit näher, wie Johns Kinder. Andere finden ihren Platz als abhängige, aber loyale Stakeholder wie Johns Eltern.
Organisationen sind nicht anders. Datenteams reifen vor Do-ERs in zentralisierten Groups, um in Hub zu erlangen und Architekturen zu sprechen. Schließlich werden die meisten Organisationen Dutzende, wenn nicht Hunderte von Menschen haben, die in ihren eigenen Speichen wegweisende Daten und KI -Workflows sind.
Sobald dies geschieht, ist es wahrscheinlich, dass die Artwork und Weise, wie Daten und KI in kleinen, agilen Organisationen verwendet werden, der Komplexität viel größerer Unternehmen ähneln, in denen die Zusammenarbeit und die Orchestrierung in verschiedenen Groups unvermeidlich sind.
Das Verständnis, wo sich Organisationen in Bezug auf diese Muster befinden, ist unerlässlich. Der Versuch, eine Denkweise für Daten wie Produkte in einem unreifen Unternehmen zu erzwingen oder sich an ein großes zentrales Group in einer großen und ausgereiften Organisation zu halten, führt zu einer Katastrophe.
Viel Glück 🍀