Lernen
Überwachendes Lernen ist eine Kategorie des maschinellen Lernens, die mit beschrifteten Datensätzen Algorithmen trainieren, um Ergebnisse vorherzusagen und Muster zu erkennen.
Im Gegensatz zu unbeaufsichtigtem Lernen werden beaufsichtigte Lernalgorithmen bezeichnet, um die Beziehung zwischen der Eingabe und den Outputs zu erlernen.
Voraussetzung: Lineare Algebra
Angenommen, wir haben eine Regressionsproblem wobei das Modell kontinuierliche Werte vorhersagen muss, indem N -Anzahl von Eingabefunktionen (XI) eingenommen wird.
Der Vorhersagewert wird als eine Funktion genannt Hypothese (H):

Wo:
- θi: I-ter Parameter, der jeder Eingangsfunktion (x_i) entspricht,
- ϵ (Epsilon): Gaußscher Fehler (ϵ ~ n (0, σ²)))
Da die Hypothese für eine einzelne Eingabe einen skalaren Wert (Hθ (x) ∈R) erzeugt, kann sie als DOT -Produkt der bezeichnet werden Transponieren des Parametervektors (θt) und die Function -Vektor für diese Eingabe (x):

Batch -Gradientenabstieg
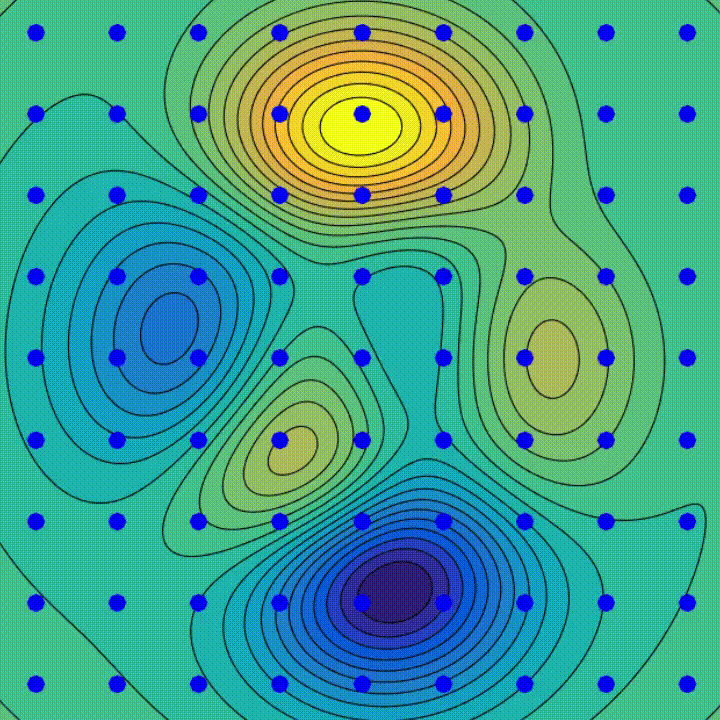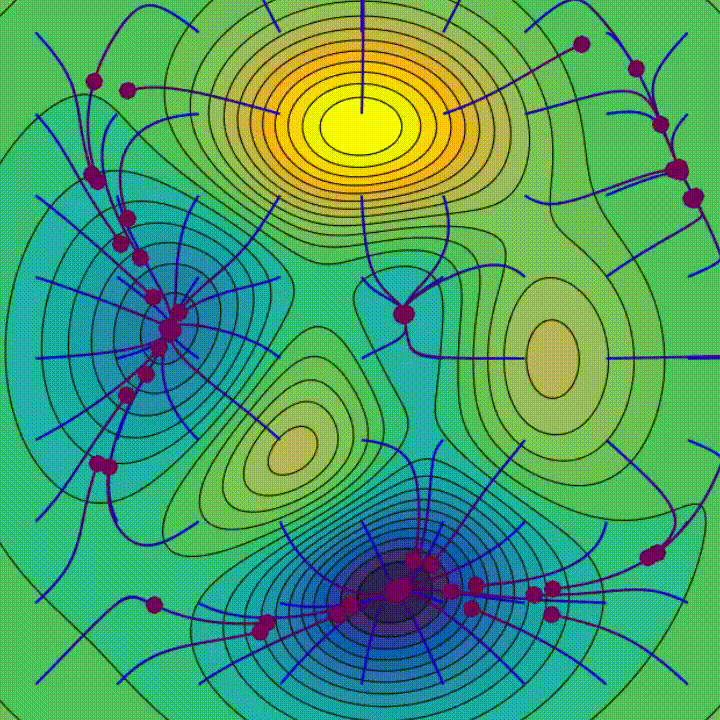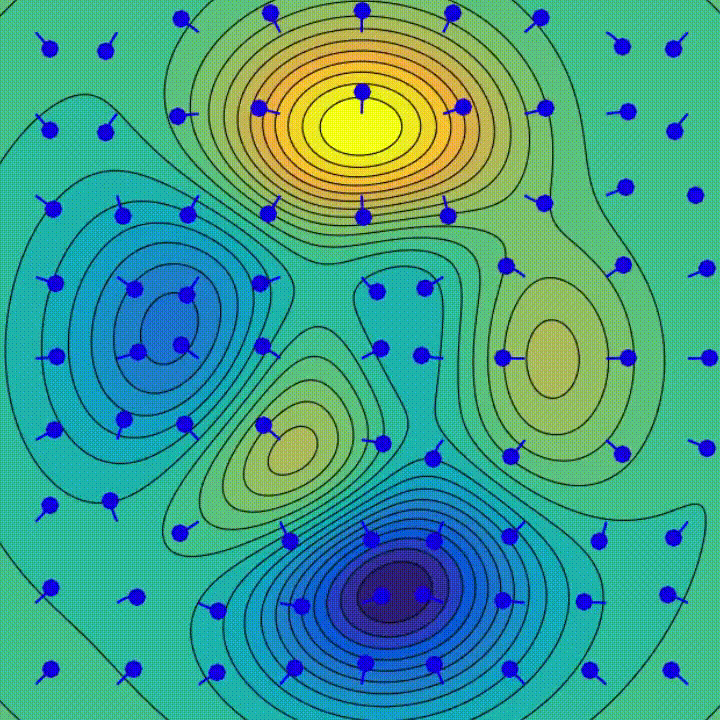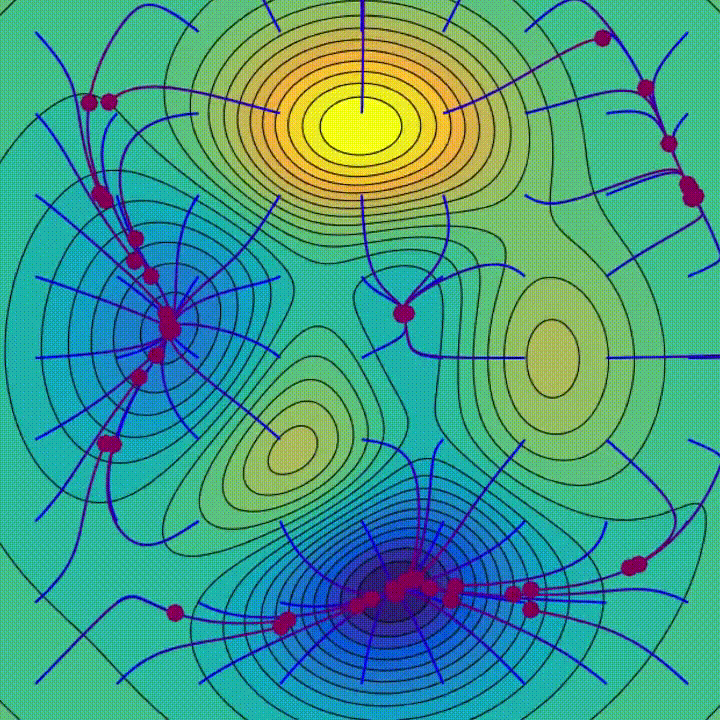
Gradientenabstieg ist ein iterativer Optimierungsalgorithmus, der verwendet wird, um lokale Minima einer Funktion zu finden. Bei jedem Schritt bewegt es sich in die Richtung gegenüber der Richtung des steilsten Abstiegs, um den Wert der Funktion schrittweise zu senken – einfach weiter bergab.
Erinnern Sie sich nun an, wir haben N -Parameter, die sich auf die Vorhersage auswirken. Wir müssen additionally den spezifischen Beitrag des Einzelparameter (θi) entspricht Trainingsdaten (xi)) zur Funktion.
Angenommen, wir setzen die Größe jedes Schritts als Lernrate (α) und finden Sie eine Kostenkurve (j), dann wird der Parameter bei jedem Schritt so abgezogen, dass:

(α: Lernrate, j (θ): cOST -Funktion, ∂/∂θi: partielle Ableitung der Kostenfunktion in Bezug auf θi)
Gradient
Der Gradient repräsentiert die Steigung der Kostenfunktion.
Unter Berücksichtigung der verbleibenden Parameter und deren entsprechenden partiellen Ableitungen der Kostenfunktion (J) wird der Gradient der Kostenfunktion bei θ für N -Parameter definiert als:

Gradient ist eine Matrixnotation von Teilleitungen der Kostenfunktion in Bezug auf alle Parameter (θ0 bis θn).
Da die Lernrate ein Skalar (α∈R) ist, wird die Aktualisierungsregel des Algorithmus zum Absenken des Gradientenabstiegs in der Matrixnotation ausgedrückt:

Folglich, Der Parameter (θ) liegt im (n+1) -dimensionalen Raum.
Geografisch geht es bei einem Schritt bergab, der der Lernrate entspricht, bis es die Konvergenz erreicht.

Berechnung
Das Ziel der linearen Regression ist es, die Lücke (MSE) zwischen vorhergesagten Werten und tatsächlichen Werten im Trainingsdatensatz zu minimieren.
Kostenfunktion (objektive Funktion)
Diese Lücke (MSE) ist definiert als eine durchschnittliche Lücke aller Trainingsbeispiele:

Wo
- Jθ: Kostenfunktion (oder Verlustfunktion),
- Hθ: Vorhersage aus dem Modell,
- X: I_th Eingabefunktion,
- y: i_th Zielwert und
- M: Die Anzahl der Trainingsbeispiele.
Der Gradient wird durch das Einnehmen berechnet Teilweise Ableitung der Kostenfunktion in Bezug auf jeden Parameter:

Weil wir haben N+1 Parameter (einschließlich eines Intercept -Time period θ0) und M -Trainingsbeispielen, werden wir mit Matrixnotation einen Gradientenvektor bilden:

In der Matrixnotation, wobei x die Entwurfsmatrix einschließlich des Intercept -Phrases und θ darstellt, ist der Parametervektor, der Gradient ∇θ j (θ) ist angegeben durch:

Der LMS (am wenigsten mittlere Quadrate) Regel ist ein iterativer Algorithmus, der die Parameter des Modells basierend auf dem Fehler zwischen seinen Vorhersagen und den tatsächlichen Zielwerten der Trainingsbeispiele kontinuierlich anpasst.
Die Regel für minimale Mindestquadrate (LMS)
In jedem Epoche des Gradientenabrufs wird jeder Parameter θi aktualisiert, indem ein Bruchteil des durchschnittlichen Fehlers in allen Trainingsbeispielen subtrahiert:

Dieser Prozess ermöglicht es dem Algorithmus, das iterativ zu finden optimale Parameter Das minimiert die Kostenfunktion.
(Hinweis: θi ist ein Parameter, der dem Eingangsfunktion XI zugeordnet ist, und das Ziel des Algorithmus ist es, seinen optimalen Wert zu finden, nicht, dass es sich bereits um einen optimalen Parameter handelt.)
Normale Gleichung
Um das zu finden optimaler Parameter (θ*) Das minimiert die Kostenfunktion, wir können die verwenden Normale Gleichung.
Diese Methode bietet eine analytische Lösung für die lineare Regression, sodass wir den θ -Wert, der die Kostenfunktion minimiert, direkt berechnen kann.
Im Gegensatz zu iterativen Optimierungstechniken findet die normale Gleichung dies optimum, indem Sie direkt für den Punkt gelöst werden, an dem der Gradient Null ist, was sofortige Konvergenz sicherstellt:

Somit:

Dies beruht auf der Annahme, dass die Designmatrix X ist invertierbarDies impliziert, dass alle Eingabefunktionen (von x_0 bis x_n) sind linear unabhängig.
Wenn X nicht invertierbar ist, müssen wir die Eingangsfunktionen anpassen, um ihre gegenseitige Unabhängigkeit zu gewährleisten.
Simulation
In Wirklichkeit wiederholen wir den Vorgang bis zur Konvergenz durch Einstellung:
- Kostenfunktion und ihr Gradient
- Lernrate
- Toleranz (min. Kostenschwelle, um die Iteration zu stoppen)
- Maximale Anzahl von Iterationen
- Ausgangspunkt
Batch durch Lernrate
Der folgende Codierungsausschnitt zeigt, dass der Prozess des Gradientenabrufs lokal minima einer quadratischen Kostenfunktion durch Lernraten (0,1, 0,3, 0,8 und 0,9) findet:
def cost_func(x):
return x**2 - 4 * x + 1
def gradient(x):
return 2*x - 4
def gradient_descent(gradient, begin, learn_rate, max_iter, tol):
x = begin
steps = (begin) # information studying steps
for _ in vary(max_iter):
diff = learn_rate * gradient(x)
if np.abs(diff) < tol:
break
x = x - diff
steps.append(x)
return x, steps
x_values = np.linspace(-4, 11, 400)
y_values = cost_func(x_values)
initial_x = 9
iterations = 100
tolerance = 1e-6
learning_rates = (0.1, 0.3, 0.8, 0.9)
def gradient_descent_curve(ax, learning_rate):
final_x, historical past = gradient_descent(gradient, initial_x, learning_rate, iterations, tolerance)
ax.plot(x_values, y_values, label=f'Price perform: $J(x) = x^2 - 4x + 1$', lw=1, coloration='black')
ax.scatter(historical past, (cost_func(x) for x in historical past), coloration='pink', zorder=5, label='Steps')
ax.plot(historical past, (cost_func(x) for x in historical past), 'r--', lw=1, zorder=5)
ax.annotate('Begin', xy=(historical past(0), cost_func(historical past(0))), xytext=(historical past(0), cost_func(historical past(0)) + 10),
arrowprops=dict(facecolor='black', shrink=0.05), ha='middle')
ax.annotate('Finish', xy=(final_x, cost_func(final_x)), xytext=(final_x, cost_func(final_x) + 10),
arrowprops=dict(facecolor='black', shrink=0.05), ha='middle')
ax.set_title(f'Studying Price: {learning_rate}')
ax.set_xlabel('Enter function: x')
ax.set_ylabel('Price: J')
ax.grid(True, alpha=0.5, ls='--', coloration='gray')
ax.legend()
fig, axs = plt.subplots(1, 4, figsize=(30, 5))
fig.suptitle('Gradient Descent Steps by Studying Price')
for ax, lr in zip(axs.flatten(), learning_rates):
gradient_descent_curve(ax=ax, learning_rate=lr)
Vorhersage der Kreditkartentransaktion
Lassen Sie uns verwenden ein Beispieldatensatz Auf Kaggle zur Vorhersage der Kreditkartentransaktion unter Verwendung einer linearen Regression mit Batch GD.
1. Datenvorverarbeitung
a) Basisdatenrahmen
Zunächst verschmelzen wir diese vier Dateien aus dem Beispieldatensatz mit IDs als Schlüssel, während wir die Rohdaten sanitieren:
- Transaktion (CSV)
- Benutzer (CSV)
- Kreditkarte (CSV)
- Train_fraud_labels (JSON)
# load transaction knowledge
trx_df = pd.read_csv(f'{dir}/transactions_data.csv')
# sanitize the dataset
trx_df = trx_df(trx_df('errors').isna())
trx_df = trx_df.drop(columns=('merchant_city','merchant_state', 'date', 'mcc', 'errors'), axis='columns')
trx_df('quantity') = trx_df('quantity').apply(sanitize_df)
# merge the dataframe with fraud transaction flag.
with open(f'{dir}/train_fraud_labels.json', 'r') as fp:
fraud_labels_json = json.load(fp=fp)
fraud_labels_dict = fraud_labels_json.get('goal', {})
fraud_labels_series = pd.Collection(fraud_labels_dict, identify='is_fraud')
fraud_labels_series.index = fraud_labels_series.index.astype(int)
merged_df = pd.merge(trx_df, fraud_labels_series, left_on='id', right_index=True, how='left')
merged_df.fillna({'is_fraud': 'No'}, inplace=True)
merged_df('is_fraud') = merged_df('is_fraud').map({'Sure': 1, 'No': 0})
merged_df = merged_df.dropna()
# load card knowledge
card_df = pd.read_csv(f'{dir}/cards_data.csv')
card_df = card_df.change('nan', np.nan).dropna()
card_df = card_df(card_df('card_on_dark_web') == 'No')
card_df = card_df.drop(columns=('acct_open_date', 'card_number', 'expires', 'cvv', 'card_on_dark_web'), axis='columns')
card_df('credit_limit') = card_df('credit_limit').apply(sanitize_df)
# load person knowledge
user_df = pd.read_csv(f'{dir}/users_data.csv')
user_df = user_df.drop(columns=('birth_year', 'birth_month', 'deal with', 'latitude', 'longitude'), axis='columns')
user_df = user_df.change('nan', np.nan).dropna()
user_df('per_capita_income') = user_df('per_capita_income').apply(sanitize_df)
user_df('yearly_income') = user_df('yearly_income').apply(sanitize_df)
user_df('total_debt') = user_df('total_debt').apply(sanitize_df)
# merge transaction and card knowledge
merged_df = pd.merge(left=merged_df, proper=card_df, left_on='card_id', right_on='id', how='internal')
merged_df = pd.merge(left=merged_df, proper=user_df, left_on='client_id_x', right_on='id', how='internal')
merged_df = merged_df.drop(columns=('id_x', 'client_id_x', 'card_id', 'merchant_id', 'id_y', 'client_id_y', 'id'), axis='columns')
merged_df = merged_df.dropna()
# finalize the dataframe
categorical_cols = merged_df.select_dtypes(embody=('object')).columns
df = merged_df.copy()
df = pd.get_dummies(df, columns=categorical_cols, dummy_na=False, dtype=float)
df = df.dropna()
print('Base knowledge body: n', df.head(n=3))
b) Vorverarbeitung
Aus dem Basisdatenrahmen wählen wir geeignete Eingabefunktionen mit:
kontinuierliche Werte und scheinbar lineare Beziehung zur Transaktionsmenge.
df = df(df('is_fraud') == 0)
df = df(('quantity', 'per_capita_income', 'yearly_income', 'credit_limit', 'credit_score', 'current_age'))Dann werden wir Ausreißer darüber hinaus filtern 3 Standardabweichungen vom Mittelwert weg:
def filter_outliers(df, column, std_threshold) -> pd.DataFrame:
imply = df(column).imply()
std = df(column).std()
upper_bound = imply + std_threshold * std
lower_bound = imply - std_threshold * std
filtered_df = df((df(column) <= upper_bound) | (df(column) >= lower_bound))
return filtered_df
df = df.change(to_replace='NaN', worth=0)
df = filter_outliers(df=df, column='quantity', std_threshold=3)
df = filter_outliers(df=df, column='per_capita_income', std_threshold=3)
df = filter_outliers(df=df, column='credit_limit', std_threshold=3)Schließlich nehmen wir den Logarithmus des Zielwerts quantity Um verzerrte Verteilung zu mindern:
df('quantity') = df('quantity') + 1
df('amount_log') = np.log(df('quantity'))
df = df.drop(columns=('quantity'), axis='columns')
df = df.dropna()*Eine hinzugefügt Menge Um unfavourable Unendlichkeiten in zu vermeiden Betrag_log Spalte.
Abschlussdatenrahmen:

c) Transformator
Jetzt können wir den endgültigen Datenrahmen in Zug-/Testdatensätze aufteilen und umwandeln:
categorical_features = X.select_dtypes(embody=('object')).columns.tolist()
categorical_transformer = Pipeline(steps=(('imputer', SimpleImputer(technique='most_frequent')),('onehot', OneHotEncoder(handle_unknown='ignore'))))
numerical_features = X.select_dtypes(embody=('int64', 'float64')).columns.tolist()
numerical_transformer = Pipeline(steps=(('imputer', SimpleImputer(technique='imply')), ('scaler', StandardScaler())))
preprocessor = ColumnTransformer(
transformers=(
('num', numerical_transformer, numerical_features),
('cat', categorical_transformer, categorical_features)
)
)
X_train_processed = preprocessor.fit_transform(X_train)
X_test_processed = preprocessor.rework(X_test)2. Definieren von Batch GD -Regressser
class BatchGradientDescentLinearRegressor:
def __init__(self, learning_rate=0.01, n_iterations=1000, l2_penalty=0.01, tol=1e-4, endurance=10):
self.learning_rate = learning_rate
self.n_iterations = n_iterations
self.l2_penalty = l2_penalty
self.tol = tol
self.endurance = endurance
self.weights = None
self.bias = None
self.historical past = {'loss': (), 'grad_norm': (), 'weight':(), 'bias': (), 'val_loss': ()}
self.best_weights = None
self.best_bias = None
self.best_val_loss = float('inf')
self.epochs_no_improve = 0
def _mse_loss(self, y_true, y_pred, weights):
m = len(y_true)
loss = (1 / (2 * m)) * np.sum((y_pred - y_true)**2)
l2_term = (self.l2_penalty / (2 * m)) * np.sum(weights**2)
return loss + l2_term
def match(self, X_train, y_train, X_val=None, y_val=None):
n_samples, n_features = X_train.form
self.weights = np.zeros(n_features)
self.bias = 0
for i in vary(self.n_iterations):
y_pred = np.dot(X_train, self.weights) + self.bias
dw = (1 / n_samples) * np.dot(X_train.T, (y_pred - y_train)) + (self.l2_penalty / n_samples) * self.weights
db = (1 / n_samples) * np.sum(y_pred - y_train)
loss = self._mse_loss(y_train, y_pred, self.weights)
gradient = np.concatenate((dw, (db)))
grad_norm = np.linalg.norm(gradient)
# replace historical past
self.historical past('weight').append(self.weights(0))
self.historical past('loss').append(loss)
self.historical past('grad_norm').append(grad_norm)
self.historical past('bias').append(self.bias)
# descent
self.weights -= self.learning_rate * dw
self.bias -= self.learning_rate * db
if X_val is just not None and y_val is just not None:
val_y_pred = np.dot(X_val, self.weights) + self.bias
val_loss = self._mse_loss(y_val, val_y_pred, self.weights)
self.historical past('val_loss').append(val_loss)
if val_loss < self.best_val_loss - self.tol:
self.best_val_loss = val_loss
self.best_weights = self.weights.copy()
self.best_bias = self.bias
self.epochs_no_improve = 0
else:
self.epochs_no_improve += 1
if self.epochs_no_improve >= self.endurance:
print(f"Early stopping at iteration {i+1} (validation loss didn't enhance for {self.endurance} epochs)")
self.weights = self.best_weights
self.bias = self.best_bias
break
if (i + 1) % 100 == 0:
print(f"Iteration {i+1}/{self.n_iterations}, Loss: {loss:.4f}", finish="")
if X_val is just not None:
print(f", Validation Loss: {val_loss:.4f}")
else:
go
def predict(self, X_test):
return np.dot(X_test, self.weights) + self.bias3. Vorhersage & Bewertung
mannequin = BatchGradientDescentLinearRegressor(learning_rate=0.001, n_iterations=10000, l2_penalty=0, tol=1e-5, endurance=5)
mannequin.match(X_train_processed, y_train.values)
y_pred = mannequin.predict(X_test_processed)Ausgabe:
Der fünf Eingangsfunktionen, per_capita_income zeigte die höchste Korrelation mit der Transaktionsmenge: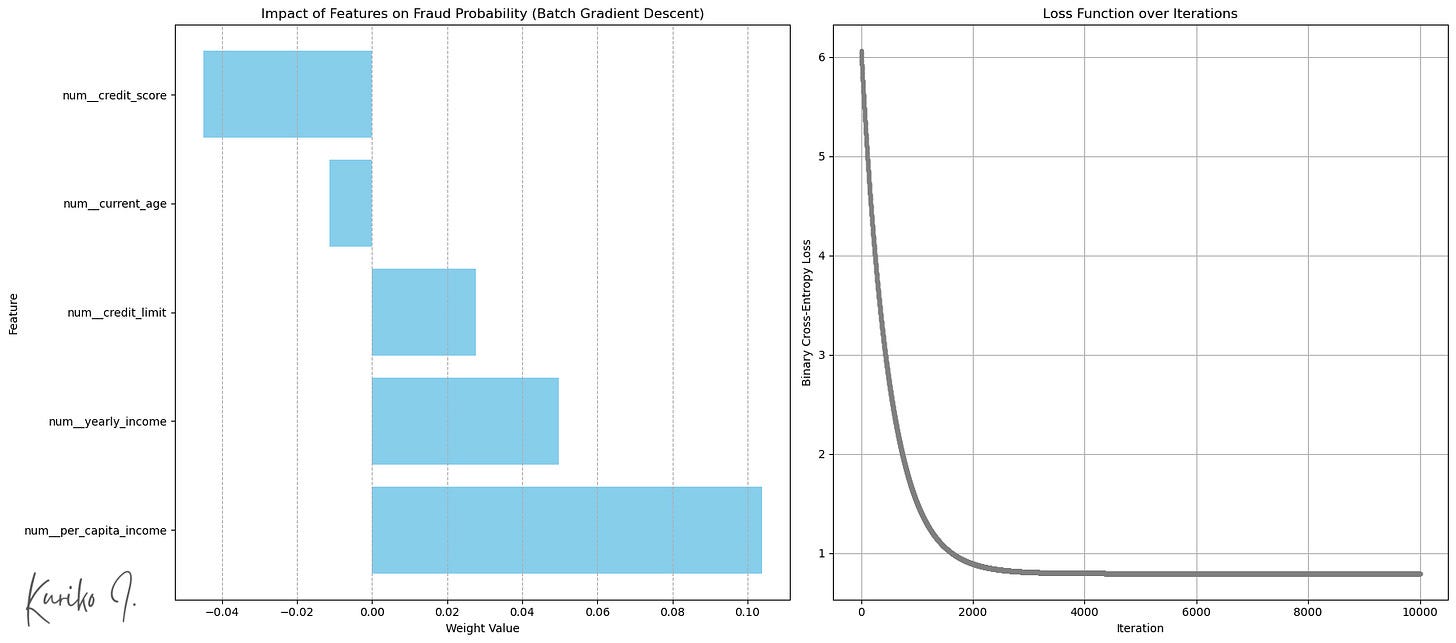
(Hyperlinks: Gewicht nach Eingangsfunktionen (unten: Mehr Transaktion), rechts: Kostenfunktion (Learning_Rate = 0,001, I = 10.000, M = 50.000, n = 5))
Mittlerer quadratischer Fehler (MSE): 1,5752
R-Quadrat: 0,0206
Mittlerer absoluter Fehler (MAE): 1.0472
Zeitkomplexität: Coaching: O (n²m + n³) + Vorhersage: O (n)
Raumkomplexität: O (NM)
(M: Trainingsbeispielgröße, N: Eingabefunktionsgröße, Annahme m >>> n)
Stochastischer Gradientenabstieg
Batch GD verwendet der gesamte Trainingsdatensatz Um den Gradienten in jedem Iterationsschritt (Epoche) zu berechnen, was rechnerisch teuer ist, insbesondere wenn wir Millionen von Datensatz haben.
Stochastischer Gradientenabstieg (SGD) auf der anderen Seite,
- Normalerweise mischt die Trainingsdaten zu Beginn jeder Epoche,
- zufällig auswählen A einzel Trainingsbeispiel in jeder Iteration,
- berechnet den Gradienten mit dem Beispiel und berechnet und
- Aktualisiert die Gewichte und Verzerrungen des Modells Nach der Verarbeitung jedes einzelnen Trainingsbeispiels.
Dies führt zu vielen Gewichtsaktualisierungen professional Epoche (entspricht der Anzahl der Trainingsmuster), vielen schnellen und rechenintensiven Aktualisierungen, die auf einzelnen Datenpunkten basieren, Erlauben, es viel schneller durch große Datensätze zu iterieren.
Simulation
Ähnlich wie bei Batch GD werden wir die SGD -Klasse definieren und die Vorhersage ausführen:
class StochasticGradientDescentLinearRegressor:
def __init__(self, learning_rate=0.01, n_iterations=100, l2_penalty=0.01, random_state=None):
self.learning_rate = learning_rate
self.n_iterations = n_iterations
self.l2_penalty = l2_penalty
self.random_state = random_state
self._rng = np.random.default_rng(seed=random_state)
self.weights_history = ()
self.bias_history = ()
self.loss_history = ()
self.weights = None
self.bias = None
def _mse_loss_single(self, y_true, y_pred):
return 0.5 * (y_pred - y_true)**2
def match(self, X, y):
n_samples, n_features = X.form
self.weights = self._rng.random(n_features)
self.bias = 0.0
for epoch in vary(self.n_iterations):
permutation = self._rng.permutation(n_samples)
X_shuffled = X(permutation)
y_shuffled = y(permutation)
epoch_loss = 0
for i in vary(n_samples):
xi = X_shuffled(i)
yi = y_shuffled(i)
y_pred = np.dot(xi, self.weights) + self.bias
dw = xi * (y_pred - yi) + self.l2_penalty * self.weights
db = y_pred - yi
self.weights -= self.learning_rate * dw
self.bias -= self.learning_rate * db
epoch_loss += self._mse_loss_single(yi, y_pred)
if n_features >= 2:
self.weights_history.append(self.weights(:2).copy())
elif n_features == 1:
self.weights_history.append(np.array((self.weights(0), 0)))
self.bias_history.append(self.bias)
self.loss_history.append(self._mse_loss_single(yi, y_pred) + (self.l2_penalty / (2 * n_samples)) * (np.sum(self.weights**2) + self.bias**2)) # Approx L2
print(f"Epoch {epoch+1}/{self.n_iterations}, Loss: {epoch_loss/n_samples:.4f}")
def predict(self, X):
return np.dot(X, self.weights) + self.bias
mannequin = StochasticGradientDescentLinearRegressor(learning_rate=0.001, n_iterations=200, random_state=42)
mannequin.match(X=X_train_processed, y=y_train.values)
y_pred = mannequin.predict(X_test_processed)Ausgabe:
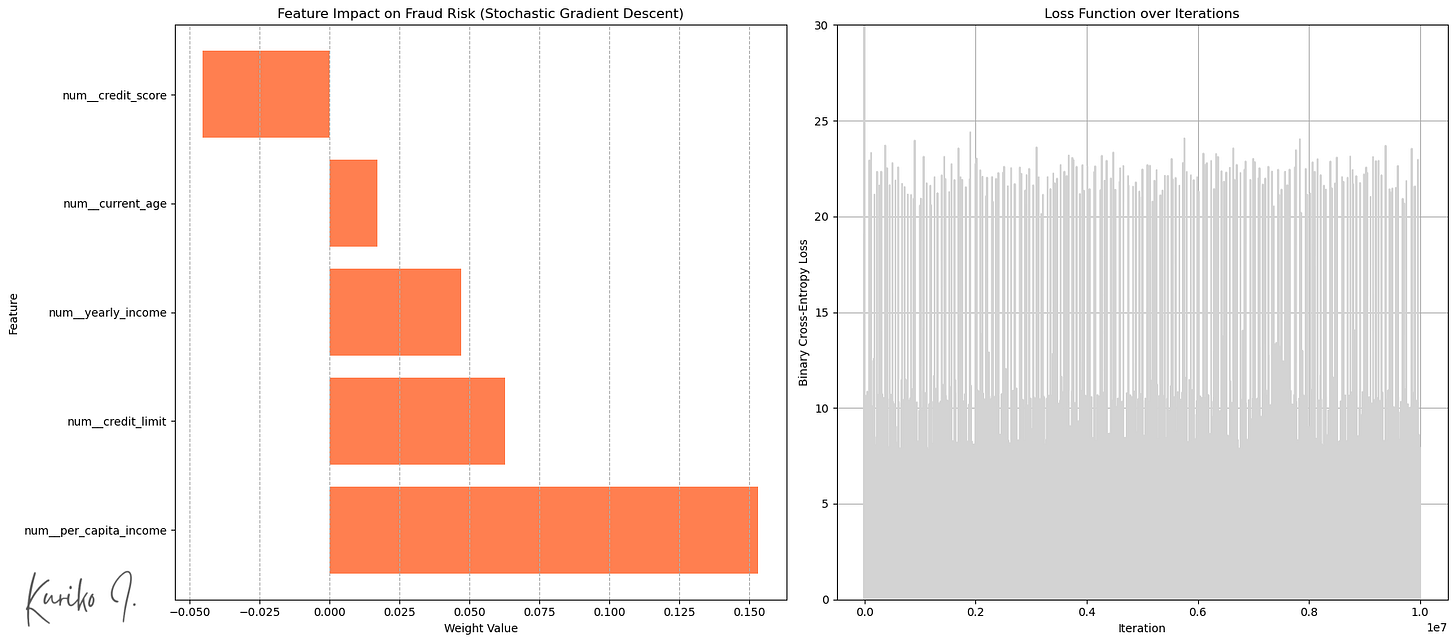
Hyperlinks: Gewicht nach Eingangsfunktionen, rechts: Kostenfunktion (Learning_rate= 0,001, i = 200, m = 50.000, n = 5)
SGD eingeführt Zufälligkeit in den Optimierungsprozess (Abb. Recht).
Das „Lärm“ kann dem Algorithmus helfen Aus den flachen lokalen Minima- oder Sattelpunkten herausspringen und finden möglicherweise bessere Regionen des Parameterraums.
Ergebnisse:
Mittlerer quadratischer Fehler (MSE): 1,5808
R-Quadrat: 0,0172
Mittlerer absoluter Fehler (MAE): 1.0475
Zeitkomplexität: Coaching: O (n²m + n³) + Vorhersage: O (n)
Raumkomplexität: O (n)
(M: Trainingsbeispielgröße, N: Eingabefunktionsgröße, Annahme m >>> n)
Abschluss
Während die Einfaches lineares Modell Rahmen effizient ist seine inhärente Einfachheit häufig daran, komplexe Beziehungen innerhalb der Daten aufzunehmen.
Unter Berücksichtigung der Kompromisse Von verschiedenen Modellierungsansätzen gegen bestimmte Ziele ist für die Erreichung optimaler Ergebnisse von wesentlicher Bedeutung.
Referenz
Alle Bilder, sofern nicht anders angegeben, werden vom Autor.
Der Artikel verwendet synthetische Daten, Lizenziert unter Apache 2.0 für den kommerziellen Gebrauch.
Autor: Kuriko Iwai