

Überwachtes Lernen: Die Grundlage der prädiktiven Modellierung
Bild vom Autor
Anmerkung des Herausgebers: Dieser Artikel ist Teil unserer Serie zur Visualisierung der Grundlagen des maschinellen Lernens.
Willkommen zum neuesten Eintrag unserer Reihe zur Visualisierung der Grundlagen des maschinellen Lernens. In dieser Serie wollen wir wichtige und oft komplexe technische Konzepte in intuitive, visuelle Leitfäden herunterbrechen, um Ihnen dabei zu helfen, die Grundprinzipien des Fachgebiets zu beherrschen. Dieser Eintrag konzentriert sich auf überwachtes Lernen, die Grundlage der prädiktiven Modellierung.
Die Grundlage der prädiktiven Modellierung
Überwachtes Lernen gilt allgemein als Grundlage der prädiktiven Modellierung im maschinellen Lernen. Aber warum?
Im Kern handelt es sich um ein Lernparadigma, bei dem ein Modell anhand gekennzeichneter Daten trainiert wird – Beispiele, bei denen sowohl die Eingabemerkmale als auch die korrekten Ausgaben (Grundwahrheit) bekannt sind. Durch das Lernen aus diesen gekennzeichneten Beispielen kann das Modell genaue Vorhersagen zu neuen, unsichtbaren Daten treffen.
Eine hilfreiche Möglichkeit, überwachtes Lernen zu verstehen, ist die Analogie von Lernen mit einem Lehrer. Während des Trainings werden dem Modell Beispiele zusammen mit den richtigen Antworten gezeigt, ähnlich wie ein Schüler, der von einem Lehrer Anleitung und Korrektur erhält. Jede Vorhersage, die das Modell macht, wird mit dem Floor-Fact-Label verglichen, es wird Suggestions gegeben und es werden Anpassungen vorgenommen, um zukünftige Fehler zu reduzieren. Mit der Zeit hilft dieser geführte Prozess dem Modell, die Beziehung zwischen Eingaben und Ausgaben zu verinnerlichen.
Das Ziel des überwachten Lernens besteht darin, eine zuverlässige Zuordnung von Options zu Beschriftungen zu erlernen. Dieser Prozess dreht sich um drei wesentliche Komponenten:
- Erstens ist das Trainingsdatendas aus beschrifteten Beispielen besteht und als Grundlage für das Lernen dient
- Zweitens ist das Lernalgorithmusdas die Modellparameter iterativ anpasst, um Vorhersagefehler in den Trainingsdaten zu minimieren
- Schließlich ist die trainiertes Modell entsteht aus diesem Prozess und ist in der Lage, das Gelernte zu verallgemeinern, um Vorhersagen auf der Grundlage neuer Daten zu treffen
Probleme beim überwachten Lernen lassen sich im Allgemeinen in zwei Hauptkategorien einteilen: Rückschritt Die Aufgaben konzentrieren sich auf die Vorhersage kontinuierlicher Werte wie Immobilienpreise oder Temperaturwerte. Einstufung Zu den Aufgaben hingegen gehört die Vorhersage diskreter Kategorien, etwa die Identifizierung von Spam- und Nicht-Spam-E-Mails oder das Erkennen von Objekten in Bildern. Trotz ihrer Unterschiede Beide basieren auf demselben Grundprinzip des Lernens aus gekennzeichneten Beispielen.
Überwachtes Lernen spielt in vielen realen Anwendungen des maschinellen Lernens eine zentrale Rolle. Typischerweise sind dafür große, qualitativ hochwertige Datensätze mit zuverlässigen Floor-Fact-Labels erforderlich, und der Erfolg hängt davon ab, wie intestine das trainierte Modell über die Daten hinaus, auf denen es trainiert wurde, verallgemeinern kann. Bei effektiver Anwendung ermöglicht überwachtes Lernen Maschinen, genaue, umsetzbare Vorhersagen in einem breiten Spektrum von Bereichen zu treffen.
Die folgende Visualisierung bietet eine kurze Zusammenfassung dieser Informationen zum schnellen Nachschlagen. Du kannst Laden Sie hier ein PDF der Infografik in hoher Auflösung herunter.
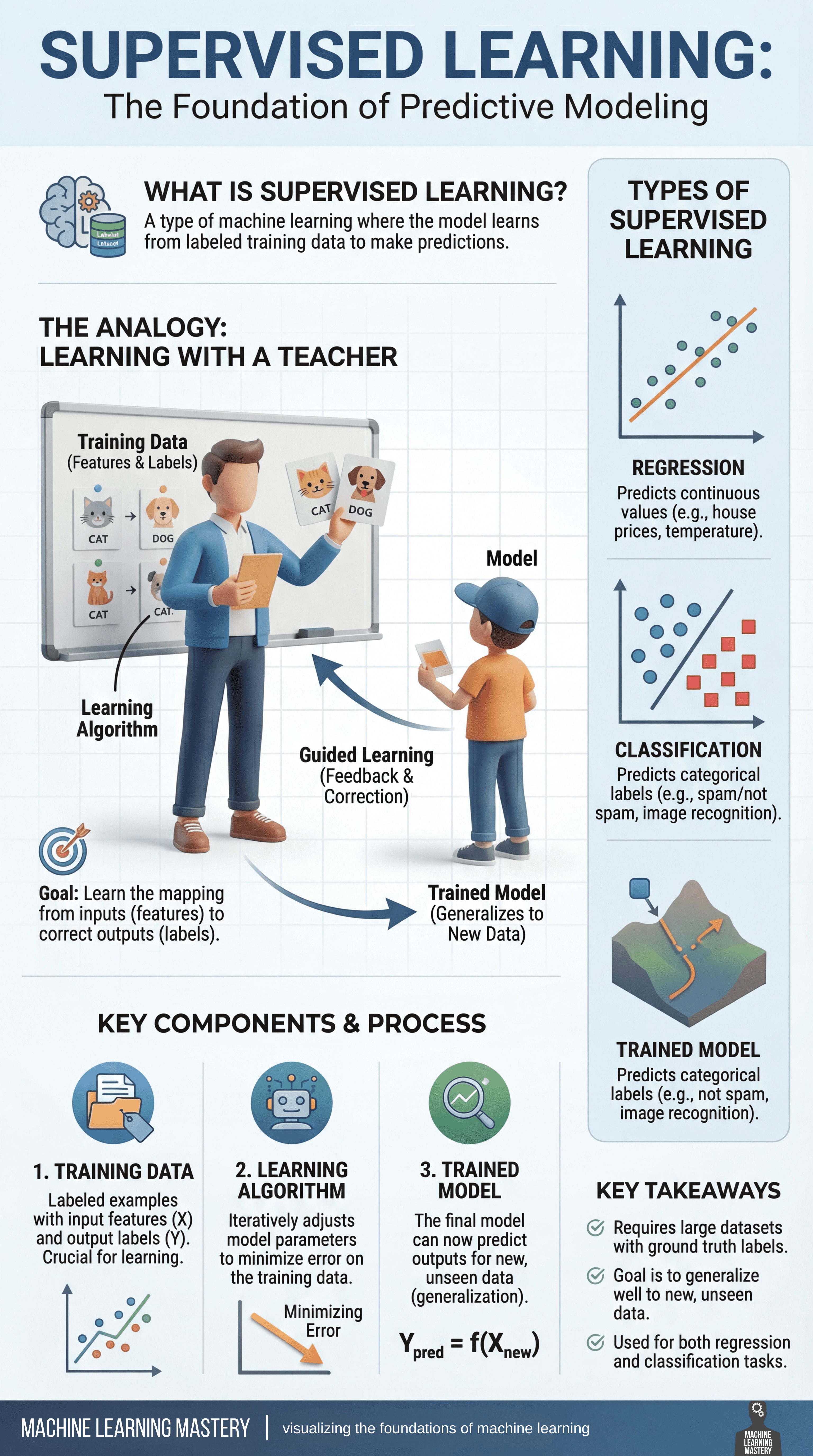
Überwachtes Lernen: Visualisierung der Grundlagen des maschinellen Lernens (zum Vergrößern klicken)
Bild vom Autor
Ressourcen zur Beherrschung des maschinellen Lernens
Dies sind einige ausgewählte Ressourcen, um mehr über überwachtes Lernen zu erfahren:
- Überwachte und unbeaufsichtigte Algorithmen für maschinelles Lernen – In diesem Artikel für Anfänger werden die Unterschiede zwischen überwachtem, unbeaufsichtigtem und halbüberwachtem Lernen erläutert. Er erläutert, wie gekennzeichnete und unbeschriftete Daten verwendet werden, und hebt gängige Algorithmen für jeden Ansatz hervor.
Schlüssel zum Mitnehmen: Für die Wahl des richtigen Lernparadigmas ist es von grundlegender Bedeutung, zu wissen, wann beschriftete und unbeschriftete Daten zu verwenden sind. - Einfaches Tutorial zur linearen Regression für maschinelles Lernen – Dieses praktische, anfängerfreundliche Tutorial führt in die einfache lineare Regression ein und erklärt, wie ein lineares Modell verwendet wird, um die Beziehung zwischen einer einzelnen Eingabevariablen und einer numerischen Ausgabe zu beschreiben und vorherzusagen.
Schlüssel zum Mitnehmen: Einfache lineare Regression modelliert Beziehungen mithilfe einer Linie, die durch erlernte Koeffizienten definiert wird. - Lineare Regression für maschinelles Lernen – Dieser Einführungsartikel bietet einen umfassenderen Überblick über die lineare Regression und behandelt die Funktionsweise des Algorithmus, wichtige Annahmen und seine Anwendung in realen Arbeitsabläufen für maschinelles Lernen.
Schlüssel zum Mitnehmen: Die lineare Regression dient als zentraler Basisalgorithmus für numerische Vorhersageaufgaben. - 4 Arten von Klassifizierungsaufgaben beim maschinellen Lernen – In diesem Artikel werden die vier Haupttypen von Klassifizierungsproblemen – binäre, Multi-Klassen-, Multi-Label- und unausgeglichene Klassifizierung – anhand klarer Erklärungen und praktischer Beispiele erläutert.
Schlüssel zum Mitnehmen: Die richtige Identifizierung der Artwork des Klassifizierungsproblems leitet die Modellauswahl und Bewertungsstrategie. - Eins-gegen-Relaxation und Eins-gegen-Eins für die Klassifizierung mehrerer Klassen – In diesem praktischen Tutorial wird erklärt, wie binäre Klassifikatoren mithilfe der One-vs-Relaxation- und One-vs-One-Strategien auf Probleme mit mehreren Klassen erweitert werden können, mit Anleitungen dazu, wann die einzelnen Strategien zu verwenden sind.
Schlüssel zum Mitnehmen: Mehrklassenprobleme können gelöst werden, indem man sie in mehrere binäre Klassifizierungsaufgaben zerlegt.
Halten Sie Ausschau nach weiteren Einträgen in unserer Reihe zur Visualisierung der Grundlagen des maschinellen Lernens.
Über Matthew Mayo
Matthew Mayo (@mattmayo13) hat einen Grasp-Abschluss in Informatik und ein Diplom in Knowledge Mining. Als geschäftsführender Herausgeber von KDnuggets & Statistikund Mitherausgeber bei Beherrschung des maschinellen LernensZiel von Matthew ist es, komplexe datenwissenschaftliche Konzepte zugänglich zu machen. Zu seinen beruflichen Interessen zählen die Verarbeitung natürlicher Sprache, Sprachmodelle, Algorithmen für maschinelles Lernen und die Erforschung neuer KI. Seine Mission ist es, das Wissen in der Datenwissenschaftsgemeinschaft zu demokratisieren. Matthew programmiert seit seinem sechsten Lebensjahr.