Modelle, die mit Ihrem NEO4J -Diagramm verbunden sind, erhalten unglaubliche Flexibilität: Sie können alle Cypher -Abfragen über den NEO4J MCP Cypher Server generieren. Dies ermöglicht es, komplexe Abfragen dynamisch zu generieren, die Datenbankstruktur zu untersuchen und sogar mehrstufige Agenten-Workflows zu ketten.
Um aussagekräftige Abfragen zu generieren, benötigt das LLM das Graph -Schema als Eingabe: die Knotenbezeichnungen, Beziehungstypen und Eigenschaften, die das Datenmodell definieren. Mit diesem Kontext kann das Modell die natürliche Sprache in präzise Cypher übersetzen, Verbindungen entdecken und mit mehreren Hop-Argumentation zusammenketten.

Zum Beispiel, wenn es etwas weiß (Individual)-(:ACTED_IN)->(Film) Und (Individual)-(:DIRECTED)->(Film) Muster in der Grafik kann es sich drehen „Welche Filme bieten Schauspieler, die auch Regie geführt haben?“ in eine gültige Anfrage. Das Schema gibt ihm die Erdung, die erforderlich ist, um sich an alle Diagramme anzupassen und Cypher -Anweisungen zu erzeugen, die sowohl korrekt als auch related sind.
Aber diese Freiheit ist mit Kosten verbunden. Wenn ein LLM nicht überprüft wird, kann sie eine Cypher erzeugen, die weit länger als beabsichtigt läuft oder enorme Datensätze mit tief verschachtelten Strukturen zurückgibt. Das Ergebnis ist nicht nur eine Verschwendung, sondern auch ein ernstes Risiko, das Modell selbst zu überwältigen. Im Second gibt jeder Device -Aufruf seine Ausgabe durch den Kontext des LLM zurück. Das heißt, wenn Sie Instruments anketten, müssen alle Zwischenergebnisse durch das Modell zurückfließen. Die Rückgabe von Tausenden von Zeilen oder die Einbettung von Werten in diese Schleife verwandelt sich schnell in Rauschen, blüht das Kontextfenster auf und verringert die Qualität der folgenden Argumente.

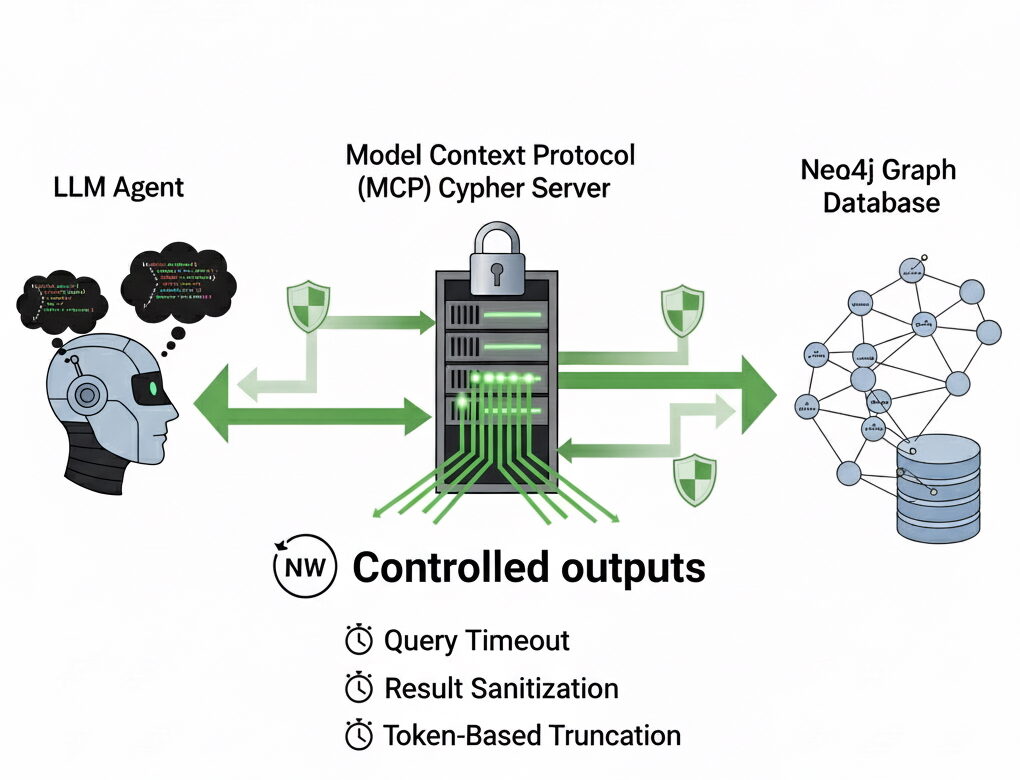
Deshalb ist das Droseln von Antworten wichtig. Ohne Steuerelemente macht dieselbe Leistung, die den NEO4J MCP Cypher Server so überzeugend macht, auch zerbrechlich. Durch Einführung von Zeitüberschreitungen, Ausgabeinhandlungen, Zeilengrenzen und tokenbewusster Kürzung können wir das System reaktionsschnell halten und sicherstellen, dass Abfragergebnisse für die LLM nützlich bleiben, anstatt es in irrelevantem Element zu ertrinken.
Haftungsausschluss: Ich arbeite bei NEO4J, und dies spiegelt meine Erforschung potenzieller zukünftiger Verbesserungen der aktuellen Implementierung wider.
Der Server ist auf verfügbar Github.
Kontrollierte Ausgänge
Wie verhindern wir, dass außer Kontrolle geratene Fragen und übergroße Antworten unsere LLM überwältigen? Die Antwort besteht nicht darin, zu beschränken, welche Arten von Cypher ein Agent als der gesamte Punkt des NEO4J MCP -Servers schreiben kann, besteht darin, die vollständige Ausdrucksleistung des Diagramms aufzudecken. Stattdessen legen wir kluge Einschränkungen auf wie viel kommt zurück und Wie lange Eine Abfrage darf laufen. In der Praxis bedeutet dies, drei Schutzschichten einzuführen: Zeitüberschreitungen, Ergebniseinstimmungen und tokenbewusster Kürzung.
Abfragen von Zeitüberschreitungen
Der erste Schutz ist einfach: Jede Abfrage erhält ein Zeitbudget. Wenn das LLM etwas Teueres erzeugt, wie ein riesiges kartesischer Produkt oder ein Durchqueren über Millionen von Knoten, fällt es schnell aus, anstatt den gesamten Workflow zu hängen.
Wir stellen dies als Umgebungsvariable auf, QUERY_TIMEOUTdie standardmäßig zehn Sekunden standhält. Innen sind Fragen eingewickelt neo4j.Question mit dem angewendeten Zeitlimit. Auf diese Weise liest und schreibt Respekt die gleiche gebundene. Allein diese Änderung macht den Server viel robuster.
Bereinigung verrauschte Werte
Moderne Grafiken befinden sich oft Vektoren einbetten zu Knoten und Beziehungen. Diese Vektoren können Hunderte oder sogar Tausende von Floating-Punkt-Zahlen professional Entität betragen. Sie sind für die Ähnlichkeitssuche unerlässlich, aber wenn sie in einen LLM -Kontext übergeben, sind sie reines Geräusch. Das Modell kann nicht direkt über sie argumentieren und sie verbrauchen eine große Menge an Token.
Um dies zu lösen, werden die Ergebnisse rekursiv mit einer einfachen Python -Funktion rekursiv abgerundet. Übergroße Hear werden fallen gelassen, verschachtelte Diktate werden beschnitten, und nur Werte, die in eine vernünftige Grenze passen (standardmäßig hear unter 52 Elementen) erhalten bleiben.
Token-bewusstes Kürzung
Schließlich können selbst sanitäre Ergebnisse ausführlich sein. Um zu garantieren, dass sie immer passen, führen wir sie durch einen Tokenizer und schneiden auf maximal 2048 Token mit OpenAIs auf tiktoken Bibliothek.
encoding = tiktoken.encoding_for_model("gpt-4")
tokens = encoding.encode(payload)
payload = encoding.decode(tokens(:2048))Dieser letzte Schritt sorgt für die Kompatibilität mit jedem LLM, den Sie verbinden, unabhängig davon, wie groß die Zwischendaten sein könnten. Es ist wie ein Sicherheitsnetz, in dem die früheren Schichten nicht gefiltert werden, um den Kontext zu vermeiden.
YAML -Antwortformat
Darüber hinaus können wir die Kontextgröße mithilfe von YAML -Antworten weiter reduzieren. Derzeit werden die Antworten von Neo4J Cypher MCP als JSON zurückgegeben, was einen zusätzlichen Overhead einführt. Durch die Umwandlung dieser Wörterbücher in YAML können wir die Anzahl der Token in unseren Eingabeaufforderungen reduzieren, die Kosten senken und die Latenz verbessern.
yaml.dump(
response,
default_flow_style=False,
sort_keys=False,
width=float('inf'),
indent=1, # Compact however nonetheless structured
allow_unicode=True,
)Zusammenbinden
Mit diesen Schichten – Timeouts, Desinfektion und Kürzung – bleibt der NEO4J MCP CYPHER -Server vollständig fähig, aber weitaus disziplinierter. Die LLM kann immer noch jede Anfrage versuchen, aber die Antworten sind immer begrenzt und kontextfreundlich zu einem LLM. Die Verwendung von YAML als Reaktionsformat hilft auch, die Token -Anzahl zu senken.
Anstatt das Modell mit großen Datenmengen zu überfluten, geben Sie gerade genug Struktur zurück, um es clever zu halten. Und das ist letztendlich der Unterschied zwischen einem Server, der sich spröde und einem für LLMs speziell anfühlt.
Der Code für den Server ist auf verfügbar Github.