Während ich an meinem Wissensdestillationsproblem zur Absichtsklassifizierung arbeitete, stand ich vor einer rätselhaften Hürde. Mein Aufbau umfasste ein Lehrermodell, das RoBERTa-groß ist (fein abgestimmt auf meine Absichtsklassifizierung), und ein Schülermodell, das ich trainieren wollte, ohne zu viel Genauigkeit im Vergleich zum Lehrer zu verlieren.
Ich habe mit mehreren Zuordnungstechniken experimentiert, jede zweite Ebene mit der Schülerebene verbunden, zwei Lehrerebenen zu einer gemittelt und sogar benutzerdefinierte Gewichtungen zugewiesen, z. B. Geben (0,3 bis l1 und 0,7 bis l2). Aber egal, welche Kombination ich ausprobierte, die Genauigkeit des Lehrers entsprach nie dem Schülermodell.
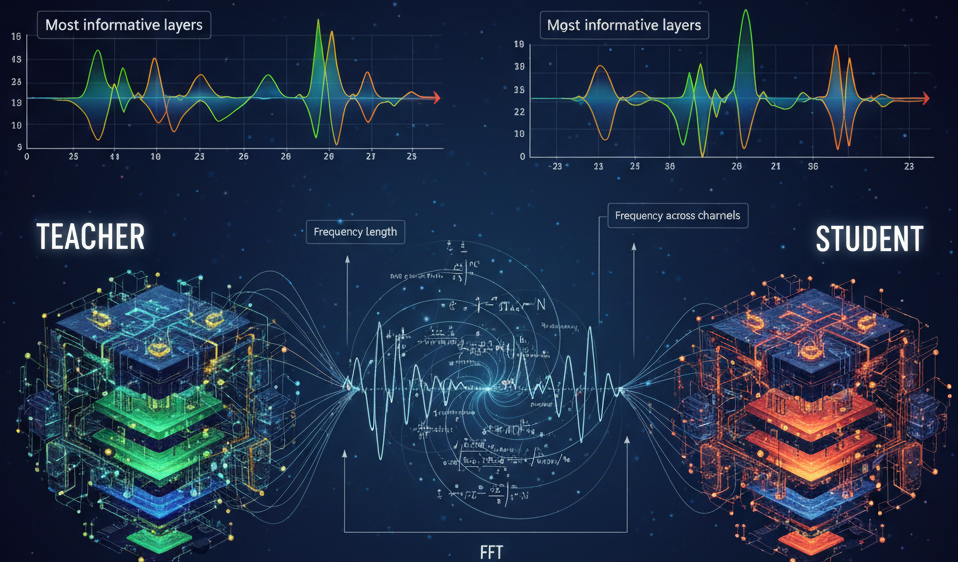
Da begann ich mit der Erkundung wie man die informativsten Ebenen kartiert zu meinem Schülermodell, damit der Schüler seine Leistung maximieren kann. Ich wollte eine Möglichkeit finden, zu quantifizieren, welche Ebene des Lehrermodells für die Destillation wirklich wichtig ist.
Neugierig geworden, beschloss ich, die Idee auf Textdaten zu übertragen – und BOOM!!!, es hat tatsächlich funktioniert!Zum ersten Mal begann mein Schülermodell quick wie sein Lehrer zu denken.
Quelle: Autor
Hier ist die Schichtintensitätsdiagramm meiner Feinabstimmung RoBERTa-groß Modell. Basierend auf den spektralen Erkenntnissen habe ich ausgewählt Schichten 1–9 und 21–23 für meine Studentenmodell Während der Wissensdestillation diejenigen, die die reichhaltigsten Informationen enthalten.
Aus Gründen der Vertraulichkeit kann ich meinen Datensatz oder Code nicht weitergeben, aber ich erkläre Ihnen, wie das geht Der bildbasierte Ansatz des Papiers hat mich inspiriert textbasierte Adaptionund wie Sie darüber nachdenken können, dasselbe zu tun.
Hinter den Kulissen: Wie FFT die spektrale Seele eines Fashions enthüllt
Additionally, fangen wir damit an spektrale Intensitätund tauchen Sie langsam in den wahren Zauberer ein: den Schnelle Fourier-Transformation (FFT).
Im spectralKD-Papierstellen die Autoren ein Framework vor, das uns hilft, Imaginative and prescient Transformer (ViTs) zu sehen, nicht nur das, was sie vorhersagen, sondern auch wie die Informationen in den Schichten fließen. Anstatt sich auf Instinct oder Visualisierung zu verlassen, nutzen sie eine Artwork Spektralanalyse um den Frequenzreichtum der internen Darstellungen des Modells zu messen.
Stellen Sie sich jede Transformer-Ebene wie einen Musiker in einem Orchester vor. Einige Ebenen spielen hohe Töne (feine Particulars), während andere tiefe Töne spielen (breite Funktionen). Die FFT hilft uns, die Musik jedes Spielers separat anzuhören und herauszufiltern, welcher die stärksten Melodien, additionally die informationsreichsten Signale, hat.
Quelle: Autor
Schritt 1: Function-Maps, das Rohmaterial
B ist die Chargengröße C ist die Anzahl der Kanäle und H,W ist die räumliche Höhe und Breite.
Schritt 2: Anwenden der Fourier-Transformation
Die Autoren wenden eine eindimensionale FFT entlang der Kanaldimension an, um diese reellen Aktivierungen in den Frequenzbereich zu übersetzen: F(X)=FFT(X)
Das heisst: Für jeden räumlichen Ort (b, h, w), a 1D-FFT wird über alle Kanäle berechnet. Das Ergebnis ist ein komplexwertiger Tensor (da FFT Actual- und Imaginärteile ausgibt). F(X) sagt uns daher, wie viel von jeder Frequenz in der Darstellung dieser Schicht vorhanden ist.
Und wenn Sie sich fragen: „Warum aber FFT?“ – halte diesen Gedanken fest. Denn später in diesem Weblog werden wir es aufdecken Genau deshalb ist FFT das perfekte Werkzeug um die innere Intensität eines Modells zu messen.
Schritt 3: Frequenzstärke messen
Re(F(X)) ist der wahre Teil, Im(F(X)) ist der Imaginärteil.
Schritt 4: Mittelung über die Karte
Nun wollen wir diese Intensität über alle Positionen im Layer zusammenfassen:
Dieser Schritt gibt uns die durchschnittliche Intensität des einzelnen Kanals an
Und dann können Sie einfach den Durchschnitt aller Kanäle ermitteln. Voilà! Jetzt haben Sie die spektrale Intensität der einzelnen Schicht des Imaginative and prescient Transformer.
Ein Blick in den Frequenzbereich: Die Fourier-Linse von SpectralKD
Schauen wir uns die schnelle Fourier-Transformation an:
Xₖ ist die Eingabesequenz (Ihr Sign, Ihre Funktion oder Ihr Aktivierungsmuster). xₙ ist die Frequenzkomponente am Frequenzindex. N ist die Anzahl der Punkte in der Sequenz (dh die Anzahl der Kanäle oder Options).
Jeder Begriff e⁻ʲ²πᵏⁿ/ᴺ fungiert als rotierender Zeigereine winzige komplexe Welle, die sich durch den Signalraum dreht, und zusammen bilden sie eine der schönsten Ideen in der Signalverarbeitung.
Quelle: Autor (Hier wird ein rotierender Zeiger e⁻ʲ²πᵏⁿ/ᴺ in einer komplexen Ebene mit g
Quelle: Autor (Mitteln Sie alle Punkte in der komplexen Ebene, dann erhalten Sie den Massenschwerpunkt der Zeigereinheit, der nur bei einer bestimmten Frequenz oder Okay seinen Höhepunkt erreicht (im obigen Fall ist es 3))
.OMG! Was ist hier gerade passiert? Lassen Sie es mich aufschlüsseln.
Wenn Sie Ihre versteckten Aktivierungen xₙ (z. B. über Kanäle oder Function-Dimensionen hinweg) mit diesem Zeiger multiplizieren, fragen Sie sich im Wesentlichen:
„Hey, Layer, wie viel davon k-ter Variationstyp enthalten Sie in Ihren Darstellungen?“
Jede Frequenz ok entspricht einer bestimmten Musterskala über die Function-Dimensionen hinweg.
Erfassung niedrigerer k-Werte breite, glatte semantische Strukturen (wie Kontext auf Themenebene), während höhere k-Werte erfasst werden schnelle, feinkörnige Variationen (wie Nuancen auf Token-Ebene oder syntaktische Signale).
Hier kommt nun der spaßige Teil: Wenn eine Schicht mit einem bestimmten Frequenzmuster in Resonanz steht, stimmt die Multiplikation der Fourier-Transformation perfekt überein und die Summe in der Fourier-Formel ergibt a starke Resonanz dafür ok.
Wenn nicht, heben sich die Rotationen auf, was bedeutet, dass die Frequenz bei der Darstellung dieser Ebene keine große Rolle spielt.
Die Fourier-Transformation fügt additionally nichts Neues hinzu; Es geht lediglich darum, herauszufinden, wie unsere Ebene Informationen über verschiedene Abstraktionsskalen hinweg kodiert.
Es ist, als würde man herauszoomen und erkennen:
Einige Schichten summen leise mit sanften, konzeptionellen Bedeutungen (tiefe Frequenzen),
Andere summen mit scharfen, detaillierten Interaktionen zwischen Token (hohe Frequenzen).
Die FFT im Grunde wandelt die verborgenen Zustände einer Ebene in einen Frequenz-Fingerabdruck um – eine Karte der Arten von Informationen, auf die sich diese Ebene konzentriert.
Und genau das nutzt SpectralKD, um herauszufinden, um welche Ebenen es sich handelt tatsächlich die schwere Arbeit erledigen während der Wissensdestillation.
Vom Sehen zur Sprache: Wie die spektrale Intensität meinen Absichtsklassifikator leitete
Quelle: Autor
Ein Schichtaktivierungstensor sei:
Wo:
N = Anzahl Proben (Chargengröße)
L = Sequenzlänge (Anzahl der Token/Zeitschritte)
H = verborgene Dimension (Anzahl der von der Ebene erzeugten Kanäle/Options)
Jede Probe i hat eine Aktivierungsmatrix Xᵢ ∈ Rᴸ ˣ ᴴ (Sequenzpositionen x versteckte Merkmale)
Jetzt können Sie erneut die FFT dieses Xᵢ berechnen und dann die Frequenzlänge mithilfe der Actual- und Imaginärkomponenten messen und über die Kanäle und dann für jede Ebene mitteln.
Frequenzlänge:
Häufigkeit über Kanäle hinweg:
Häufigkeit über eine Ebene:
Hier, Okay ist die Anzahl der aufbewahrten Behälter.
Abschluss
Ihre Analyse zeigt zwei wichtige Erkenntnisse:
Nicht alle Schichten tragen gleichermaßen dazu bei. In einheitlichen Transformatorarchitekturen nur wenige früh Und Finale Schichten weisen eine starke spektrale Aktivität auf, die wahren „Hotspots“ des Informationsflusses.
Verschiedene Transformatortypen, ähnliche Melodien. Trotz architektonischer Unterschiede weisen sowohl hierarchische als auch einheitliche Transformatoren überraschend ähnliche Spektralmuster auf, was auf eine universelle Artwork und Weise hinweist, wie diese Modelle Wissen lernen und darstellen.
Aufbauend auf diesen Erkenntnissen stellt SpectralKD eine vor einfache, parameterfreie Wissensdestillation (KD) Strategie. Durch die selektive Anpassung des Spektralverhaltens der frühen und letzten Schichten zwischen einem Lehrer- und einem Schülermodell lernt der Schüler dies ahmen Sie die Spektralsignatur des Lehrers nachauch in Zwischenschichten, die nie explizit ausgerichtet wurden.
Die Ergebnisse in der Arbeit sind bemerkenswert: Der destillierte Scholar (DeiT-Tiny) erreicht nicht nur die Leistung von Benchmarks wie ImageNet-1K, sondern auch lernt, wie der Lehrer spektral zu denkenund erfasst sowohl lokale als auch globale Informationen auf bemerkenswerte Weise Treue.
Letztendlich überbrückt SpectralKD Interpretierbarkeit und Destillationund bietet eine neue Möglichkeit, zu visualisieren, was im Inneren von Transformatoren während des Lernens passiert. Es eröffnet eine neue Forschungsrichtung, nennen die Autoren „Destillationsdynamik“eine Reise darüber, wie Wissen selbst zwischen Lehrer- und Schülernetzwerken fließt, oszilliert und harmoniert.