
Einführung
In der sich ständig weiterentwickelnden Landschaft der Datenverarbeitungdas Extrahieren strukturierter Informationen aus PDFs bleibt auch im Jahr 2024 eine gewaltige Herausforderung. Während zahlreiche Modelle bei Frage-Antwort-Aufgaben hervorragende Ergebnisse liefern, liegt die wahre Komplexität in der Umwandlung unstrukturierter PDF-Inhalte in organisierte, verwertbare Daten. Lassen Sie uns diese Herausforderung untersuchen und herausfinden, wie Indexify und PaddleOCR die Instruments sein können, die wir zum nahtlosen Extrahieren von Textual content aus PDFs benötigen.
Spoiler: Wir haben es tatsächlich gelöst! Hit cmd/strg+F und suchen Sie nach dem Begriff „Highlight“, um herauszufinden, wie!
Die PDF-Extraktion ist in verschiedenen Bereichen von entscheidender Bedeutung. Sehen wir uns einige gängige Anwendungsfälle an:
- Rechnungen und Quittungen: Diese Dokumente weisen sehr unterschiedliche Formate auf und enthalten komplexe Layouts, Tabellen und manchmal handschriftliche Notizen. Eine genaue Analyse ist für die Automatisierung von Buchhaltungsprozessen unerlässlich.
- Akademische Arbeiten und Abschlussarbeiten: Diese enthalten oft eine Mischung aus Textual content, Diagrammen, Tabellen und Formeln. Die Herausforderung besteht darin, nicht nur Textual content, sondern auch mathematische Gleichungen und wissenschaftliche Notation korrekt zu konvertieren.
- Legale Dokumente: Verträge und Gerichtsakten enthalten in der Regel viele Formatierungsnuancen. Die Wahrung der Integrität der ursprünglichen Formatierung beim Extrahieren von Textual content ist für rechtliche Überprüfungen und die Einhaltung von Vorschriften von entscheidender Bedeutung.
- Historische Archive und Manuskripte: Diese stellen aufgrund von Papierverschleiß, Abweichungen in historischen Handschriften und veralteter Sprache besondere Herausforderungen dar. Die OCR-Technologie muss diese Abweichungen für effektive Forschungs- und Archivierungszwecke verarbeiten können.
- Krankenakten und Rezepte: Diese enthalten oft wichtige handschriftliche Notizen und medizinische Terminologie. Die genaue Erfassung dieser Informationen ist für die Patientenversorgung und die medizinische Forschung von entscheidender Bedeutung.
Natürlich! Hier ist der überarbeitete Textual content im Aktiv:
Indexify ist ein Open-Supply-Datenframework, das die Komplexität der Extraktion unstrukturierter Daten aus beliebigen Quellen bewältigt, wie in Abb. 1 dargestellt. Seine Architektur unterstützt:
- Aufnahme von Millionen unstrukturierter Datenpunkte.
- Extraktions- und Indizierungspipelines in Echtzeit.
- Horizontale Skalierung zur Bewältigung wachsender Datenmengen.
- Schnelle Extraktionszeiten (innerhalb von Sekunden nach Einnahme).
- Versatile Bereitstellung auf verschiedenen Hardwareplattformen (GPUs, TPUs und CPUs).

Wenn Sie mehr über Indexify und dessen Einrichtung für die Extraktion erfahren möchten, lesen Sie unseren 2-minütigenErste Schritte‚ Führung.

Das Herzstück von Indexify sind die Extractors (siehe Abb. 2) – Rechenfunktionen, die unstrukturierte Daten transformieren oder Informationen daraus extrahieren. Diese Extractors können so implementiert werden, dass sie auf jeder {Hardware} laufen, wobei eine einzelne Indexify-Bereitstellung Zehntausende von Extractors in einem Cluster unterstützt.
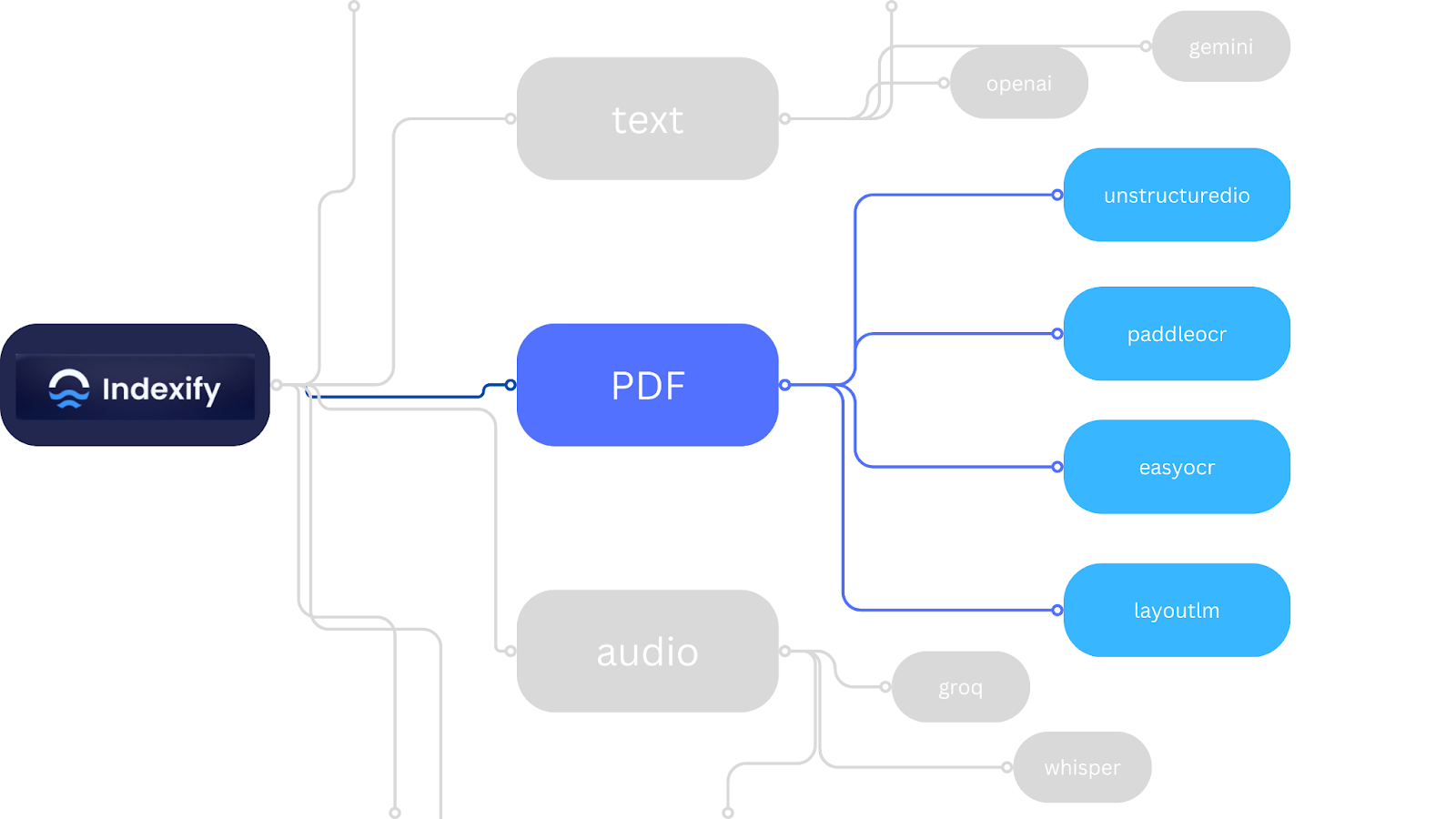
Derzeit unterstützt indexify mehrere Extraktoren für mehrere Modalitäten (siehe Abb. 3). Die vollständige Liste der Indexify-Extraktoren sowie deren Anwendungsfälle finden Sie im Dokumentation.
Der PaddleOCR PDF Extractor, basierend auf der PaddleOCR-Bibliothek, ist ein leistungsstarkes Instrument im Indexify-Ökosystem. Es integriert verschiedene OCR-Algorithmen zur Texterkennung (DB, EAST, SAST) und -erkennung (CRNN, RARE, StarNet, Rosetta, SRN).
Lassen Sie uns die Einrichtung und Verwendung des PaddleOCR Extractor durchgehen:
Hier ist ein Beispiel für die Erstellung einer Pipeline, die Textual content, Tabellen und Bilder aus einem PDF-Dokument extrahiert.
Um dieses Tutorial abzuschließen, müssen Sie drei verschiedene Terminals geöffnet haben:
- Terminal 1, um den Indexify-Server herunterzuladen und auszuführen.
- Terminal 2 zum Ausführen unserer Indexify-Extraktoren, die die strukturierte Extraktion, das Chunking und das Einbetten der aufgenommenen Seiten übernehmen.
- Terminal 3 zum Ausführen unserer Python-Skripte, die beim Laden und Abfragen von Daten von unserem Indexify-Server helfen.
Schritt 1: Starten Sie den Indexify-Server
Beginnen wir zunächst damit, den Indexify-Server herunterzuladen und auszuführen.
Schalter 1
curl https://getindexify.ai | sh
./indexify server -dBeginnen wir mit der Erstellung einer neuen virtuellen Umgebung, bevor wir die erforderlichen Pakete in unserer virtuellen Umgebung installieren.
Terminal 2
python3 -m venv venv
supply venv/bin/activate
pip3 set up indexify-extractor-sdk indexifyWir können dann alle verfügbaren Extraktoren mit dem folgenden Befehl ausführen.
!indexify-extractor obtain tensorlake/paddleocr_extractor
!indexify-extractor join-serverTerminal 3
!python3 -m venv venv
!supply venv/bin/activateErstellen Sie ein Python-Skript, das den Extraktionsgraphen definiert, und führen Sie es aus. Die Schritte 3 bis 5 in diesem Unterabschnitt sollten Teil derselben Python-Datei sein, die nach der Aktivierung des venv in Terminal 3 ausgeführt werden soll.
from indexify import IndexifyClient, ExtractionGraph
shopper = IndexifyClient()
extraction_graph_spec = """
title: 'pdflearner'
extraction_policies:
- extractor: 'tensorlake/paddleocr_extractor'
title: 'pdf_to_text'
"""
extraction_graph = ExtractionGraph.from_yaml(extraction_graph_spec)
shopper.create_extraction_graph(extraction_graph)Dieser Code richtet ein Extraktionsdiagramm namens „pdflearner“ ein, das den PaddleOCR-Extraktor verwendet, um PDFs in Textual content zu konvertieren.
Schritt 4: Laden Sie PDFs aus Ihrer Anwendung hoch
content_id = shopper.upload_file("pdflearner", "/path/to/pdf.file")shopper.wait_for_extraction(content_id)
extracted_content = shopper.get_extracted_content(content_id=content_id, graph_name="pdflearner", policy_name="pdf_to_text")
print(extracted_content)Dieses Snippet lädt eine PDF-Datei hoch, wartet, bis die Extraktion abgeschlossen ist, und ruft dann den extrahierten Inhalt ab und druckt ihn.
Wir glaubten nicht, dass es ein einfacher Prozess sein könnte, in dem man in wenigen Schritten alle Textinformationen sinnvoll extrahieren kann. Additionally testeten wir es mit einer echten Steuerrechnung (siehe Abbildung 4).
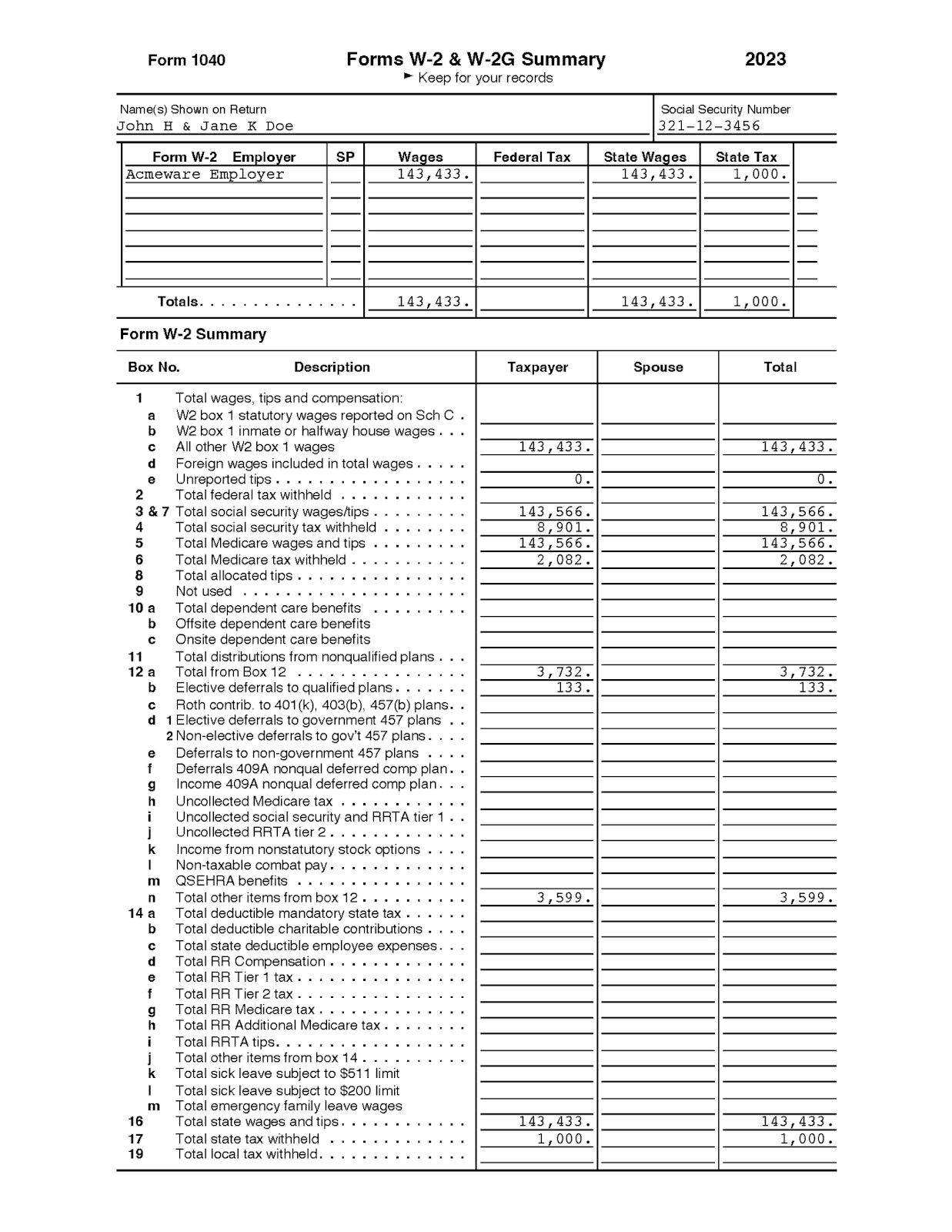
(Content material(content_type="textual content/plain", knowledge=b"Type 1040nForms W-2 & W-2G Summaryn2023nKeep on your recordsn Identify(s) Proven on ReturnnSocial Safety NumbernJohn H & Jane Okay Doen321-12-3456nEmployernSPnFederal TaxnState WagesnState TaxnForm W-2nWagesnAcmeware Employern143,433.n143,433.n1,000.nTotals.n143,433.n143,433.n1,000.nForm W-2 SummarynBox No.nDescriptionnTaxpayernSpousenTotalnTotal wages, suggestions and compensation:n1nanW2 field 1 statutory wages reported on Sch CnW2 field 1 inmate or midway home wages .n6ncnAll different W2 field 1 wagesn143,433.n143,433.ndnForeign wages included in whole wagesnen0.n0.n2nTotal federal tax withheldn 3 & 7 Whole social safety wages/suggestions .n143,566.n143,566.n4nTotal social safety tax withheldn8,901.n8,901.n5nTotal Medicare wages and tipsn143,566.n143,566.n6nTotal Medicare tax withheld . :n2,082.n2,082.n8nTotal allotted suggestions .n9nNot usedn10 anTotal dependent care benefitsnbnOffsite dependent care benefitsncnOnsite dependent care benefitsn11n Whole distributions from nonqualified plansn12 anTotal from Field 12n3,732.n3,732.nElective deferrals to certified plansn133.n133.ncnRoth contrib. to 401(ok), 403(b), 457(b) plans .n.n1 Elective deferrals to authorities 457 plansn2 Non-elective deferrals to gov't 457 plans .nenDeferrals to non-government 457 plansnfnDeferrals 409A nonqual deferred comp plan .n6nIncome 409A nonqual deferred comp plan .nhnUncollected Medicare tax :nUncollected social safety and RRTA tier 1njnUncollected RRTA tier 2 . . .nknIncome from nonstatutory inventory optionsnNon-taxable fight paynmnQSEHRA benefitsnTotal different objects from field 12 .nnn3,599.n3,599.n14 an Whole deductible necessary state tax .nbnTotal deductible charitable contributionsncnTotal state deductible worker bills .ndn Whole RR Compensation .nenTotal RR Tier 1 tax .nfnTotal RR Tier 2 tax . -nTotal RR Medicare tax .ngnhnTotal RR Further Medicare tax .ninTotal RRTA suggestions. : :njnTotal different objects from field 14nknTotal sick depart topic to $511 limitnTotal sick depart topic to $200 limitnmnTotal emergency household depart wagesn16nTotal state wages and suggestions .n143,433.n143,433.n17nTotal state tax withheldn1,000.n1,000.n19nTotal native tax withheld .", options=(Characteristic(feature_type="metadata", title="metadata", worth={'sort': 'textual content'}, remark=None)), labels={}))
Obwohl das Extrahieren von Textual content nützlich ist, müssen wir diesen Textual content häufig in strukturierte Daten zerlegen. So können Sie mit Indexify bestimmte Felder aus Ihren PDFs extrahieren (der gesamte Workflow ist in Abbildung 5 dargestellt).
from indexify import IndexifyClient, ExtractionGraph, SchemaExtractorConfig, Content material, SchemaExtractor
shopper = IndexifyClient()
schema = {
'properties': {
'invoice_number': {'title': 'Bill Quantity', 'sort': 'string'},
'date': {'title': 'Date', 'sort': 'string'},
'account_number': {'title': 'Account Quantity', 'sort': 'string'},
'proprietor': {'title': 'Proprietor', 'sort': 'string'},
'deal with': {'title': 'Tackle', 'sort': 'string'},
'last_month_balance': {'title': 'Final Month Steadiness', 'sort': 'string'},
'current_amount_due': {'title': 'Present Quantity Due', 'sort': 'string'},
'registration_key': {'title': 'Registration Key', 'sort': 'string'},
'due_date': {'title': 'Due Date', 'sort': 'string'}
},
'required': ('invoice_number', 'date', 'account_number', 'proprietor', 'deal with', 'last_month_balance', 'current_amount_due', 'registration_key', 'due_date')
'title': 'Person',
'sort': 'object'
}
examples = str((
{
"sort": "object",
"properties": {
"employer_name": {"sort": "string", "title": "Employer Identify"},
"employee_name": {"sort": "string", "title": "Worker Identify"},
"wages": {"sort": "quantity", "title": "Wages"},
"federal_tax_withheld": {"sort": "quantity", "title": "Federal Tax
Withheld"},
"state_wages": {"sort": "quantity", "title": "State Wages"},
"state_tax": {"sort": "quantity", "title": "State Tax"}
},
"required": ("employer_name", "employee_name", "wages",
"federal_tax_withheld", "state_wages", "state_tax")
},
{
"sort": "object",
"properties": {
"booking_reference": {"sort": "string", "title": "Reserving Reference"},
"passenger_name": {"sort": "string", "title": "Passenger Identify"},
"flight_number": {"sort": "string", "title": "Flight Quantity"},
"departure_airport": {"sort": "string", "title": "Departure Airport"},
"arrival_airport": {"sort": "string", "title": "Arrival Airport"},
"departure_time": {"sort": "string", "title": "Departure Time"},
"arrival_time": {"sort": "string", "title": "Arrival Time"} },
"required": ("booking_reference", "passenger_name", "flight_number","departure_airport", "arrival_airport", "departure_time", "arrival_time")
}
))
extraction_graph_spec = """
title: 'invoice-learner'
extraction_policies:
- extractor: 'tensorlake/paddleocr_extractor'
title: 'pdf-extraction'
- extractor: 'schema_extractor'
title: 'text_to_json'
input_params:
service: 'openai'
example_text: {examples}
content_source: 'invoice-learner'
"""
extraction_graph = ExtractionGraph.from_yaml(extraction_graph_spec)
shopper.create_extraction_graph(extraction_graph)
content_id = shopper.upload_file("invoice-learner", "/path/to/pdf.pdf")
print(content_id)
shopper.wait_for_extraction(content_id)
extracted_content = shopper.get_extracted_content(content_id=content_id, graph_name="invoice-learner", policy_name="text_to_json")
print(extracted_content)Dieses erweiterte Beispiel zeigt, wie mehrere Extraktoren verkettet werden. Zunächst wird PaddleOCR verwendet, um Textual content aus der PDF-Datei zu extrahieren. Anschließend wird ein Schemaextraktor angewendet, um den Textual content basierend auf dem definierten Schema in strukturierte JSON-Daten zu zerlegen.
Der Schemaextraktor ist interessant, da er es Ihnen ermöglicht, sowohl das Schema zu verwenden als auch das Schema aus dem Sprachmodell Ihrer Wahl abzuleiten, indem Sie Lernen mit wenigen Versuchen.
Wir tun dies, indem wir über den Parameter example_text einige Beispiele übergeben, wie das Schema aussehen soll. Je klarer und ausführlicher die Beispiele sind, desto besser ist das abgeleitete Schema.
Lassen Sie uns die Ausgabe dieses Entwurfs untersuchen:
(Content material(content_type="textual content/plain", knowledge=b'{"Type":"1040","Types W-2 & W-2G Abstract":{"Yr":2023,"Preserve on your information":true,"Identify(s) Proven on Return":"John H & Jane Okay Doe","Social Safety Quantity":"321-12-3456","Employer":{"Identify":"Acmeware Employer","Federal Tax":"SP","State Wages":143433,"State Tax":1000},"Totals":{"Wages":143433,"State Wages":143433,"State Tax":1000}},"Type W-2 Abstract":{"Field No.":{"Description":{"Taxpayer":"John H Doe","Partner":"Jane Okay Doe","Whole":"John H & Jane Okay Doe"}},"Whole wages, suggestions and compensation":{"W2 field 1 statutory wages reported on Sch C":143433,"W2 field 1 inmate or midway home wages":0,"All different W2 field 1 wages":143433,"Overseas wages included in whole wages":0},"Whole federal tax withheld":0,"Whole social safety wages/suggestions":143566,"Whole social safety tax withheld":8901,"Whole Medicare wages and suggestions":143566,"Whole Medicare tax withheld":2082,"Whole allotted suggestions":0,"Whole dependent care advantages":{"Offsite dependent care advantages":0,"Onsite dependent care advantages":0},"Whole distributions from nonqualified plans":0,"Whole from Field 12":{"Elective deferrals to certified plans":3732,"Roth contrib. to 401(ok), 403(b), 457(b) plans":133,"Elective deferrals to authorities 457 plans":0,"Non-elective deferrals to gov't 457 plans":0,"Deferrals to non-government 457 plans":0,"Deferrals 409A nonqual deferred comp plan":0,"Earnings 409A nonqual deferred comp plan":0,"Uncollected Medicare tax":0,"Uncollected social safety and RRTA tier 1":0,"Uncollected RRTA tier 2":0,"Earnings from nonstatutory inventory choices":0,"Non-taxable fight pay":0,"QSEHRA advantages":0,"Whole different objects from field 12":3599},"Whole deductible necessary state tax":0,"Whole deductible charitable contributions":0,"Whole state deductible worker bills":0,"Whole RR Compensation":0,"Whole RR Tier 1 tax":0,"Whole RR Tier 2 tax":0,"Whole RR Medicare tax":0,"Whole RR Further Medicare tax":0,"Whole RRTA suggestions":0,"Whole different objects from field 14":0,"Whole sick depart topic to $511 restrict":0,"Whole sick depart topic to $200 restrict":0,"Whole emergency household depart wages":0,"Whole state wages and suggestions":143433,"Whole state tax withheld":1000,"Whole native tax withheld":0}}, options=(Characteristic(feature_type="metadata", title="textual content", worth={'mannequin': 'gpt-3.5-turbo-0125', 'completion_tokens': 204, 'prompt_tokens': 692}, remark=None)), labels={}))Ja, das ist schwer zu lesen, deshalb wollen wir das in Abbildung 6 für Sie näher erläutern.

Das bedeutet, dass unsere Textdaten nach diesem Schritt erfolgreich in ein strukturiertes JSON-Format extrahiert wurden. Die Daten können komplex angeordnet, ungleichmäßig verteilt, horizontal, vertikal oder diagonal ausgerichtet sein, große Schriftarten oder kleine Schriftarten verwenden – egal, welches Design sie haben, es funktioniert einfach!
Damit ist das Drawback, das wir uns ursprünglich vorgenommen hatten, praktisch gelöst. Wir können endlich im Tom Cruise-Stil „Mission erfüllt“ schreien!
Während der PaddleOCR-Extraktor für die Textextraktion aus PDFs leistungsstark ist, liegt die wahre Stärke von Indexify in seiner Fähigkeit, mehrere Extraktoren miteinander zu verketten und so anspruchsvolle Datenverarbeitungspipelines zu erstellen. Lassen Sie uns genauer untersuchen, warum Sie möglicherweise zusätzliche Extraktoren verwenden möchten und wie Indexify diesen Prozess nahtlos und effizient macht.
Mit den Extraktionsdiagrammen von Indexify können Sie eine Sequenz von Extraktoren in Streaming-Manier auf aufgenommene Inhalte anwenden. Jeder Schritt in einem Extraktionsdiagramm wird als Extraktionsrichtlinie bezeichnet. Dieser Ansatz bietet mehrere Vorteile:
- Modulare Verarbeitung: Teilen Sie komplexe Extraktionsaufgaben in kleinere, überschaubare Schritte auf.
- Flexibilität: Einfaches Ändern oder Ersetzen einzelner Extraktoren, ohne die gesamte Pipeline zu beeinträchtigen.
- Effizienz: Verarbeiten Sie Daten im Streaming-Verfahren und reduzieren Sie so Latenz und Ressourcennutzung.
Herkunftsverfolgung
Indexify verfolgt die Herkunft transformierter Inhalte und extrahierter Funktionen aus der Quelle. Diese Funktion ist entscheidend für:
- Datenamt: Verstehen Sie, wie Ihre Daten verarbeitet und transformiert wurden.
- Debuggen: Verfolgen Sie Probleme problemlos bis zu ihrer Quelle zurück.
- Einhaltung: Erfüllen Sie gesetzliche Vorschriften, indem Sie eine klare Prüfspur der Datentransformationen pflegen.
Während PaddleOCR sich durch die Textextraktion auszeichnet, können auch andere Extraktoren einen erheblichen Mehrwert für Ihre Datenverarbeitungspipeline darstellen.
Warum Indexify wählen?
Indexify glänzt in Szenarien, in denen:
- Sie haben es mit einer großen Menge an Dokumenten zu tun (> 1000).
- Ihr Datenvolumen wächst mit der Zeit.
- Sie benötigen zuverlässige und verfügbare Aufnahmepipelines.
- Sie arbeiten mit multimodalen Daten oder kombinieren mehrere Modelle in einer einzigen Pipeline.
- Das Benutzererlebnis Ihrer Anwendung hängt von aktuellen Daten ab.
Abschluss
Das Extrahieren strukturierter Daten aus PDFs muss kein Kopfzerbrechen bereiten. Mit Indexify und einer Reihe leistungsstarker Extraktoren wie PaddleOCR können Sie Ihren Workflow optimieren, große Mengen an Dokumenten verarbeiten und mit Leichtigkeit aussagekräftige, strukturierte Daten extrahieren. Egal, ob Sie Rechnungen, akademische Arbeiten oder andere Arten von PDF-Dokumenten verarbeiten, Indexify bietet die Instruments, die Sie benötigen, um unstrukturierte Daten in wertvolle Erkenntnisse umzuwandeln.
Bereit, Ihren PDF-Extraktionsprozess zu optimieren? Probieren Sie Indexify aus und erleben Sie die Leichtigkeit intelligenter, skalierbarer Datenextraktion!