

Diffusionsmodelle haben sich in letzter Zeit als De-facto-Customary für die Generierung komplexer, hochdimensionaler Ergebnisse herauskristallisiert. Sie kennen sie vielleicht für ihre Fähigkeit, atemberaubende KI-Kunst und hyperrealistische synthetische Bilderaber sie sind auch in anderen Anwendungen erfolgreich, wie zum Beispiel Arzneimitteldesign Und kontinuierliche Kontrolle. Die Kernidee hinter Diffusionsmodellen ist die iterative Umwandlung von zufälligem Rauschen in eine Probe, wie z. B. ein Bild oder eine Proteinstruktur. Dies wird typischerweise als Most-Probability-Schätzung Downside, bei dem das Modell trainiert wird, um Stichproben zu generieren, die möglichst genau mit den Trainingsdaten übereinstimmen.
Die meisten Anwendungsfälle von Diffusionsmodellen befassen sich jedoch nicht direkt mit der Anpassung der Trainingsdaten, sondern mit einem nachgelagerten Ziel. Wir wollen nicht nur ein Bild, das wie vorhandene Bilder aussieht, sondern eines, das eine bestimmte Artwork von Erscheinungsbild hat; wir wollen nicht nur ein Arzneimittelmolekül, das physikalisch plausibel ist, sondern eines, das so wirksam wie möglich ist. In diesem Beitrag zeigen wir, wie Diffusionsmodelle mithilfe von Reinforcement Studying (RL) direkt auf diese nachgelagerten Ziele trainiert werden können. Dazu optimieren wir Stabile Diffusion auf eine Vielzahl von Zielen, darunter Bildkomprimierbarkeit, vom Menschen wahrgenommene ästhetische Qualität und schnelle Bildausrichtung. Das letzte dieser Ziele nutzt Suggestions von ein großes Imaginative and prescient-Language-Modell um die Leistung des Modells bei ungewöhnlichen Eingabeaufforderungen zu verbessern und zu zeigen, wie Leistungsstarke KI-Modelle können zur gegenseitigen Verbesserung genutzt werden ohne dass ein Mensch involviert ist.
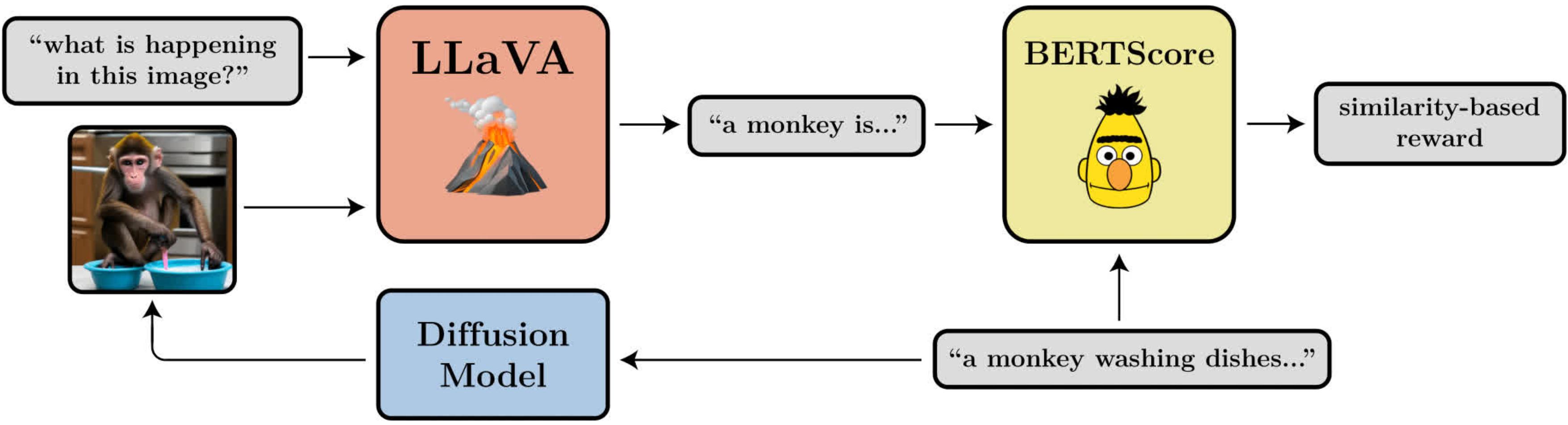
Ein Diagramm, das das Ziel der Immediate-Picture-Ausrichtung veranschaulicht. Es verwendet LLaVAein großes Bildsprachenmodell, um generierte Bilder auszuwerten.
Rauschunterdrückung, Diffusionspolitikoptimierung
Wenn wir Diffusion in ein RL-Downside umwandeln, machen wir nur die grundlegendste Annahme: Bei einer gegebenen Probe (z. B. einem Bild) haben wir Zugriff auf eine Belohnungsfunktion, die wir auswerten können, um zu erfahren, wie „intestine“ diese Probe ist. Unser Ziel ist es, dass das Diffusionsmodell Proben generiert, die diese Belohnungsfunktion maximieren.
Diffusionsmodelle werden typischerweise mit einer Verlustfunktion trainiert, die aus der Most-Probability-Schätzung (MLE) abgeleitet wird. Das bedeutet, dass sie dazu angehalten werden, Stichproben zu generieren, die die Trainingsdaten wahrscheinlicher erscheinen lassen. In der RL-Einstellung haben wir keine Trainingsdaten mehr, sondern nur Stichproben aus dem Diffusionsmodell und die damit verbundenen Belohnungen. Eine Möglichkeit, die gleiche MLE-motivierte Verlustfunktion weiterhin zu verwenden, besteht darin, die Stichproben als Trainingsdaten zu behandeln und die Belohnungen einzubeziehen, indem der Verlust für jede Stichprobe mit ihrer Belohnung gewichtet wird. Dies gibt uns einen Algorithmus, den wir belohnungsgewichtete Regression (RWR) nennen, nach Bestehende Algorithmen aus der RL-Literatur.
Dieser Ansatz bringt jedoch einige Probleme mit sich. Einer davon ist, dass RWR kein besonders exakter Algorithmus ist – er maximiert die Belohnung nur ungefähr (siehe Nair et al.Anhang A). Der MLE-inspirierte Verlust für Diffusion ist ebenfalls nicht exakt und wird stattdessen mithilfe eines Variationsgrenze von der tatsächlichen Wahrscheinlichkeit jeder Stichprobe. Das bedeutet, dass RWR die Belohnung durch zwei Näherungsebenen maximiert, was unserer Ansicht nach die Leistung erheblich beeinträchtigt.
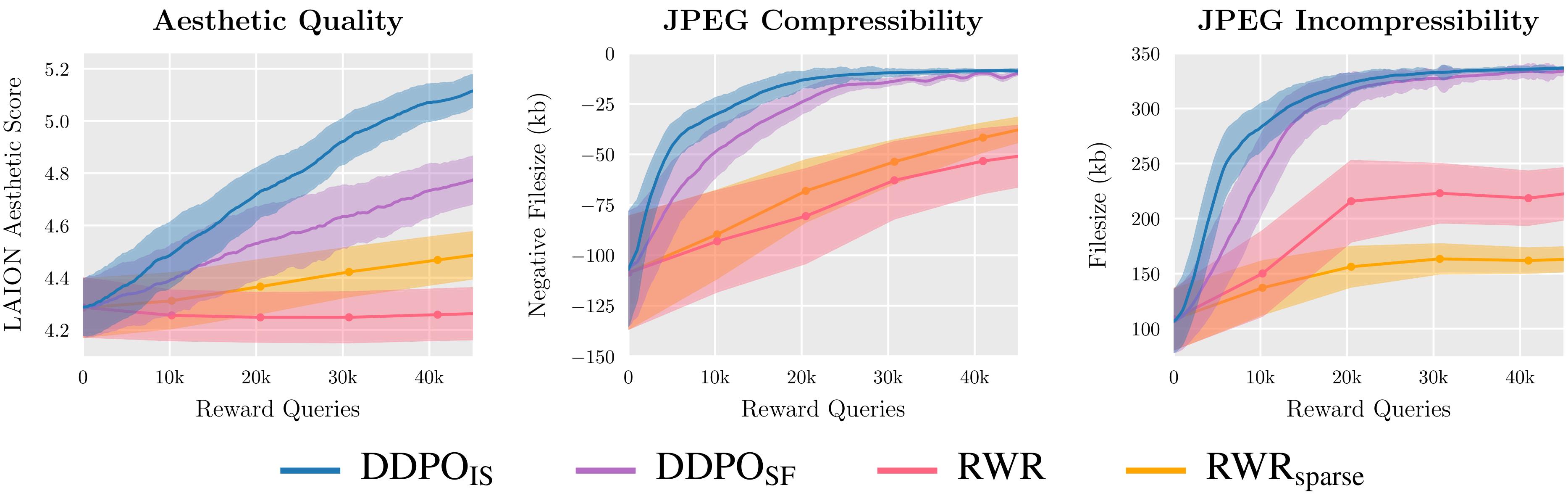
Wir bewerten zwei Varianten von DDPO und zwei Varianten von RWR anhand von drei Belohnungsfunktionen und stellen fest, dass DDPO durchweg die beste Leistung erzielt.
Die wichtigste Erkenntnis unseres Algorithmus, den wir als Denoising Diffusion Coverage Optimization (DDPO) bezeichnen, besteht darin, dass wir die Belohnung der endgültigen Probe besser maximieren können, wenn wir auf die gesamte Abfolge der Denoising-Schritte achten, die uns dorthin geführt haben. Zu diesem Zweck definieren wir den Diffusionsprozess als mehrstufigen Markow-Entscheidungsprozess (MDP). In der MDP-Terminologie: Jeder Entrauschungsschritt ist eine Aktion, und der Agent erhält nur im letzten Schritt jeder Entrauschungstrajektorie eine Belohnung, wenn die endgültige Probe erstellt wird. Dieses Framework ermöglicht es uns, viele leistungsstarke Algorithmen aus der RL-Literatur anzuwenden, die speziell für mehrstufige MDPs entwickelt wurden. Anstatt die ungefähre Wahrscheinlichkeit der endgültigen Probe zu verwenden, verwenden diese Algorithmen die genaue Wahrscheinlichkeit jedes Entrauschungsschritts, die äußerst einfach zu berechnen ist.
Wir haben uns für die Anwendung von Coverage-Gradient-Algorithmen entschieden, da diese einfach zu implementieren sind und bisherige Erfolge bei der Feinabstimmung von SprachmodellenDies führte zu zwei Varianten von DDPO: DDPOSFdas den einfachen Rating-Funktionsschätzer des Coverage-Gradienten verwendet, auch bekannt als VERSTÄRKEN; und DDPOISTdas einen leistungsfähigeren Significance-Sampling-Schätzer verwendet. DDPOIST ist unser Algorithmus mit der besten Leistung und seine Implementierung folgt eng der von proximale Richtlinienoptimierung (PPO).
Feinabstimmung der stabilen Diffusion mit DDPO
Für unsere Hauptergebnisse optimieren wir Stabile Diffusion v1-4 mit DDPOIST. Wir haben vier Aufgaben, jede von ihnen wird durch eine andere Belohnungsfunktion definiert:
- Komprimierbarkeit: Wie einfach lässt sich das Bild mit dem JPEG-Algorithmus komprimieren? Als Belohnung erhält man die unfavorable Dateigröße des Bildes (in kB), wenn es als JPEG gespeichert wird.
- Inkompressibilität: Wie schwer ist das Bild mit dem JPEG-Algorithmus zu komprimieren? Die Belohnung ist die constructive Dateigröße des Bildes (in kB), wenn es als JPEG gespeichert wird.
- Ästhetische Qualität: Wie ästhetisch ansprechend ist das Bild für das menschliche Auge? Die Belohnung ist die Ausgabe des LAION Ästhetik-Prädiktorein neuronales Netzwerk, das auf menschliche Vorlieben trainiert ist.
- Immediate-Bild-Ausrichtung: Wie intestine stellt das Bild dar, was in der Eingabeaufforderung gefragt wurde? Das ist etwas komplizierter: Wir geben das Bild in LLaVAbitten Sie es, das Bild zu beschreiben, und berechnen Sie dann die Ähnlichkeit zwischen dieser Beschreibung und der ursprünglichen Eingabeaufforderung mithilfe von BERTScore.
Da Secure Diffusion ein Textual content-zu-Bild-Modell ist, müssen wir auch eine Reihe von Eingabeaufforderungen auswählen, die wir ihm während der Feinabstimmung geben. Für die ersten drei Aufgaben verwenden wir einfache Eingabeaufforderungen der Type „ein Tier)“Für die Ausrichtung von Eingabeaufforderung und Bild verwenden wir Eingabeaufforderungen der Type „eine (tierische) (Tätigkeit)“wo die Aktivitäten „Geschirr spülen“, „Schach spielen“Und „Fahrrad fahren“. Wir haben festgestellt, dass Secure Diffusion bei diesen ungewöhnlichen Szenarien oft Probleme hatte, Bilder zu produzieren, die der Eingabeaufforderung entsprachen, sodass durch RL-Feinabstimmung viel Raum für Verbesserungen blieb.
Zunächst veranschaulichen wir die Leistung von DDPO bei den einfachen Belohnungen (Kompressibilität, Inkompressibilität und ästhetische Qualität). Alle Bilder werden mit demselben Zufallsstartwert generiert. Im oberen linken Quadranten veranschaulichen wir, was die „normale“ stabile Diffusion für neun verschiedene Tiere generiert; alle RL-fein abgestimmten Modelle zeigen einen klaren qualitativen Unterschied. Interessanterweise tendiert das Modell der ästhetischen Qualität (oben rechts) zu minimalistischen schwarz-weißen Strichzeichnungen und zeigt die Arten von Bildern, die der ästhetische Prädiktor von LAION als „ästhetischer“ betrachtet.

Als Nächstes demonstrieren wir DDPO anhand der komplexeren Aufgabe der Immediate-Picture-Ausrichtung. Hier zeigen wir mehrere Schnappschüsse aus dem Trainingsprozess: Jede Serie von drei Bildern zeigt Beispiele für denselben Immediate und denselben Zufallsstartwert im Zeitverlauf, wobei das erste Beispiel aus der Standardversion von Secure Diffusion stammt. Interessanterweise verschiebt sich das Modell in Richtung eines eher cartoonartigen Stils, was nicht beabsichtigt battle. Wir vermuten, dass dies daran liegt, dass Tiere, die menschenähnliche Aktivitäten ausführen, in den Vortrainingsdaten eher in einem cartoonartigen Stil erscheinen, sodass das Modell in Richtung dieses Stils verschiebt, um sich leichter an den Immediate anzupassen, indem es das nutzt, was es bereits weiß.

Unerwartete Verallgemeinerung
Es hat sich gezeigt, dass bei der Feinabstimmung großer Sprachmodelle mit RL überraschende Verallgemeinerungen auftreten: Beispielsweise wurden Modelle, die nur auf die Befolgung von Anweisungen in Englisch abgestimmt sind, verbessern sich oft in anderen Sprachen. Wir stellen fest, dass das gleiche Phänomen bei Textual content-Bild-Diffusionsmodellen auftritt. Beispielsweise wurde unser Modell der ästhetischen Qualität mithilfe von Eingabeaufforderungen verfeinert, die aus einer Liste von 45 häufig vorkommenden Tieren ausgewählt wurden. Wir stellen fest, dass es nicht nur auf unbekannte Tiere, sondern auch auf Alltagsgegenstände verallgemeinert werden kann.

Unser Immediate-Picture-Alignment-Modell verwendete während des Trainings dieselbe Liste mit 45 häufig vorkommenden Tieren und nur drei Aktivitäten. Wir stellen fest, dass es nicht nur auf unbekannte Tiere, sondern auch auf unbekannte Aktivitäten und sogar auf neuartige Kombinationen aus beidem verallgemeinert werden kann.

Überoptimierung
Es ist bekannt, dass die Feinabstimmung einer Belohnungsfunktion, insbesondere einer erlernten, zu Folgendem führen kann: Überoptimierung der Belohnung wo das Modell die Belohnungsfunktion ausnutzt, um auf nicht nützliche Weise eine hohe Belohnung zu erzielen. Unsere Einstellung ist keine Ausnahme: Bei allen Aufgaben zerstört das Modell schließlich jeden sinnvollen Bildinhalt, um die Belohnung zu maximieren.

Wir haben auch festgestellt, dass LLaVA anfällig für typografische Angriffe ist: bei der Optimierung der Ausrichtung in Bezug auf Eingabeaufforderungen der Type „(n) Tiere“DDPO konnte LLaVA erfolgreich täuschen, indem es stattdessen einen Textual content generierte, der der richtigen Nummer grob ähnelte.

Derzeit gibt es keine allgemeingültige Methode zur Vermeidung einer Überoptimierung und wir heben dieses Downside als einen wichtigen Bereich für künftige Arbeiten hervor.
Abschluss
Wenn es darum geht, komplexe, hochdimensionale Ergebnisse zu erzeugen, sind Diffusionsmodelle kaum zu übertreffen. Bisher waren sie jedoch vor allem bei Anwendungen erfolgreich, bei denen es darum ging, Muster aus sehr großen Datenmengen zu lernen (beispielsweise Bildunterschriftenpaare). Wir haben eine Methode gefunden, Diffusionsmodelle effektiv zu trainieren, die über das Mustervergleichen hinausgeht – und ohne dass unbedingt Trainingsdaten erforderlich sind. Die Möglichkeiten werden nur durch die Qualität und Kreativität Ihrer Belohnungsfunktion begrenzt.
Die Artwork und Weise, wie wir DDPO in dieser Arbeit verwendet haben, ist von den jüngsten Erfolgen bei der Feinabstimmung von Sprachmodellen inspiriert. Die GPT-Modelle von OpenAI, wie Secure Diffusion, werden zunächst mit riesigen Mengen an Internetdaten trainiert; sie werden dann mit RL feinabgestimmt, um nützliche Instruments wie ChatGPT zu erstellen. Normalerweise wird ihre Belohnungsfunktion aus menschlichen Vorlieben gelernt, aber Andere Greif zu kürzlich haben herausgefunden, wie man leistungsstarke Chatbots mit Belohnungsfunktionen auf Foundation von KI-Suggestions erstellen kann. Im Vergleich zum Chatbot-Regime sind unsere Experimente klein und in ihrem Umfang begrenzt. Aber angesichts des enormen Erfolgs dieses Paradigmas „Vortrainieren + Feinabstimmen“ in der Sprachmodellierung scheint es sich durchaus zu lohnen, es in der Welt der Diffusionsmodelle weiter zu verfolgen. Wir hoffen, dass andere auf unserer Arbeit aufbauen können, um große Diffusionsmodelle zu verbessern, nicht nur für die Textual content-zu-Bild-Generierung, sondern für viele spannende Anwendungen wie Videogenerierung, Musikgeneration, Bildbearbeitung, Proteinsynthese, Robotikund mehr.
Darüber hinaus ist das Paradigma „Vortrainieren + Feinabstimmen“ nicht die einzige Möglichkeit, DDPO zu verwenden. Solange Sie eine gute Belohnungsfunktion haben, hindert Sie nichts daran, von Anfang an mit RL zu trainieren. Obwohl dieser Ansatz noch unerforscht ist, ist dies ein Ort, an dem die Stärken von DDPO wirklich zum Tragen kommen könnten. Reines RL wird seit langem in einer Vielzahl von Bereichen eingesetzt, von Spiele spielen Zu Robotermanipulation Zu Kernfusion Zu Chipdesign. Wenn man die leistungsstarke Ausdruckskraft von Diffusionsmodellen hinzufügt, hat man das Potenzial, bestehende RL-Anwendungen auf die nächste Ebene zu heben – oder sogar neue zu entdecken.
Dieser Beitrag basiert auf dem folgenden Dokument:
Wenn Sie mehr über DDPO erfahren möchten, können Sie sich die Papier, Webseite, ursprünglicher Codeoder holen Sie sich die Modellgewichte auf Hugging FaceWenn Sie DDPO in Ihrem eigenen Projekt verwenden möchten, lesen Sie meine PyTorch + LoRA-Implementierung wo Sie Secure Diffusion mit weniger als 10 GB GPU-Speicher feinabstimmen können!
Wenn DDPO Ihre Arbeit inspiriert, zitieren Sie es bitte mit:
@misc{black2023ddpo,
title={Coaching Diffusion Fashions with Reinforcement Studying},
creator={Kevin Black and Michael Janner and Yilun Du and Ilya Kostrikov and Sergey Levine},
12 months={2023},
eprint={2305.13301},
archivePrefix={arXiv},
primaryClass={cs.LG}
}