So identifizieren und visualisieren Sie Cluster in Wissensgraphen
In diesem Beitrag identifizieren und visualisieren wir verschiedene Cluster von Krebsarten durch die Analyse Krankheitsontologie als Wissensgraph. Konkret werden wir neo4j in einem Docker-Container einrichten, die Ontologie importieren, Graphcluster und -einbettungen generieren, bevor wir diese Cluster mithilfe der Dimensionsreduktion darstellen und einige Erkenntnisse daraus ableiten. Obwohl wir `disease_ontology` als Beispiel verwenden, können dieselben Schritte verwendet werden, um jede Ontologie oder Graphdatenbank zu untersuchen.

In einer Graphdatenbank werden Daten nicht als Zeilen gespeichert (wie in einer Tabellenkalkulation oder relationalen Datenbank), sondern als Knoten und Beziehungen zwischen Knoten. In der folgenden Abbildung sehen wir beispielsweise, dass Melanom und Karzinom Unterkategorien des Zelltyps Krebstumor sind (dargestellt durch die SCO-Beziehung). Anhand dieser Artwork von Daten können wir deutlich erkennen, dass Melanom und Karzinom verwandt sind, auch wenn dies in den Daten nicht explizit angegeben ist.
Ontologien sind eine formalisierte Reihe von Konzepten und Beziehungen zwischen diesen Konzepten. Sie sind für Pc viel einfacher zu analysieren als freier Textual content und daher leichter zu verstehen. Ontologien werden in den Biowissenschaften häufig verwendet und Sie finden möglicherweise eine Ontologie, die Sie interessiert, unter https://obofoundry.org/. Hier konzentrieren wir uns auf die Krankheitsontologie, die zeigt, wie verschiedene Arten von Krankheiten miteinander in Beziehung stehen.
Neo4j ist ein Software zum Verwalten, Abfragen und Analysieren von Graphdatenbanken. Um die Einrichtung zu vereinfachen, verwenden wir einen Docker-Container.
docker run
-it - rm
- publish=7474:7474 - publish=7687:7687
- env NEO4J_AUTH=neo4j/123456789
- env NEO4J_PLUGINS='("graph-data-science","apoc","n10s")'
neo4j:5.17.0
Im obigen Befehl setzen die Flags `-publish` Ports, damit Python die Datenbank direkt abfragen und uns über einen Browser darauf zugreifen kann. Das Argument `NEO4J_PLUGINS` gibt an, welche Plugins installiert werden sollen. Leider scheint das Home windows-Docker-Picture die Set up nicht bewältigen zu können, daher müssen Sie Neo4j Desktop manuell installieren, um weitermachen zu können. Aber keine Sorge, die anderen Schritte sollten alle trotzdem für Sie funktionieren.
Während neo4j läuft, können Sie auf Ihre Datenbank zugreifen, indem Sie in Ihrem Browser http://localhost:7474/ aufrufen, oder Sie können den Python-Treiber verwenden, um eine Verbindung wie unten beschrieben herzustellen. Beachten Sie, dass wir den Port verwenden, den wir oben mit unserem Docker-Befehl veröffentlicht haben, und dass wir uns mit dem Benutzernamen und dem Passwort authentifizieren, die wir ebenfalls oben definiert haben.
URI = "bolt://localhost:7687"
AUTH = ("neo4j", "123456789")
driver = GraphDatabase.driver(URI, auth=AUTH)
driver.verify_connectivity()
Sobald Sie Ihre Neo4j-Datenbank eingerichtet haben, ist es an der Zeit, einige Daten abzurufen. Das Neo4j-Plug-in n10s ist für den Import und die Handhabung von Ontologien konzipiert. Sie können es verwenden, um Ihre Daten in eine vorhandene Ontologie einzubetten oder die Ontologie selbst zu erkunden. Mit den folgenden Cypher-Befehlen legen wir zunächst einige Konfigurationen fest, um die Ergebnisse sauberer zu gestalten, dann richten wir eine Eindeutigkeitsbeschränkung ein und schließlich importieren wir tatsächlich die Krankheitsontologie.
CALL n10s.graphconfig.init({ handleVocabUris: "IGNORE" });
CREATE CONSTRAINT n10s_unique_uri FOR (r:Useful resource) REQUIRE r.uri IS UNIQUE;
CALL n10s.onto.import.fetch(http://purl.obolibrary.org/obo/doid.owl, RDF/XML);
Um zu sehen, wie dies mit dem Python-Treiber gemacht werden kann, sehen Sie sich hier den vollständigen Code an https://github.com/DAWells/do_onto/blob/foremost/import_ontology.py
Nachdem wir die Ontologie importiert haben, können Sie sie erkunden, indem Sie http://localhost:7474/ in Ihrem Webbrowser öffnen. Auf diese Weise können Sie Ihre Ontologie ein wenig manuell erkunden, aber wir sind am Gesamtbild interessiert, additionally führen wir eine Analyse durch. Insbesondere werden wir Louvain-Clustering durchführen und schnelle zufällige Projektionseinbettungen generieren.
Louvain-Clustering ist ein Clustering-Algorithmus für Netzwerke wie dieses. Kurz gesagt, es identifiziert Knotensätze, die stärker miteinander verbunden sind als mit dem größeren Knotensatz; dieser Satz wird dann als Cluster definiert. Bei Anwendung auf eine Ontologie ist es eine schnelle Möglichkeit, einen Satz verwandter Konzepte zu identifizieren. Die schnelle Zufallsprojektion hingegen erzeugt eine Einbettung für jeden Knoten, d. h. einen numerischen Vektor, bei dem mehr ähnliche Knoten mehr ähnliche Vektoren haben. Mit diesen Instruments können wir identifizieren, welche Krankheiten ähnlich sind, und diese Ähnlichkeit quantifizieren.
Um Einbettungen und Cluster zu generieren, müssen wir die Teile unseres Graphen „projizieren“, die uns interessieren. Da Ontologien normalerweise sehr groß sind, ist diese Teilmenge eine einfache Möglichkeit, die Berechnung zu beschleunigen und Speicherfehler zu vermeiden. In diesem Beispiel sind wir nur an Krebs und nicht an anderen Krankheitsarten interessiert. Wir tun dies mit der folgenden Cypher-Abfrage; wir gleichen den Knoten mit der Bezeichnung „Krebs“ und jeden Knoten ab, der durch eine oder mehrere SCO- oder SCO_RESTRICTION-Beziehungen damit verbunden ist. Da wir die Beziehungen zwischen Krebsarten einbeziehen möchten, haben wir eine zweite MATCH-Abfrage, die die verbundenen Krebsknoten und ihre Beziehungen zurückgibt.
MATCH (most cancers:Class {label:"most cancers"})<-(:SCO|SCO_RESTRICTION *1..)-(n:Class)
WITH n
MATCH (n)-(:SCO|SCO_RESTRICTION)->(m:Class)
WITH gds.graph.mission(
"proj", n, m, {}, {undirectedRelationshipTypes: ('*')}
) AS g
RETURN g.graphName AS graph, g.nodeCount AS nodes, g.relationshipCount AS rels
Sobald wir die Projektion haben (die wir „proj“ genannt haben), können wir die Cluster und Einbettungen berechnen und sie in das ursprüngliche Diagramm zurückschreiben. Schließlich können wir durch Abfragen des Diagramms die neuen Einbettungen und Cluster für jeden Krebstyp abrufen, die wir in eine CSV-Datei exportieren können.
CALL gds.fastRP.write(
'proj',
{embeddingDimension: 128, randomSeed: 42, writeProperty: 'embedding'}
) YIELD nodePropertiesWrittenCALL gds.louvain.write(
"proj",
{writeProperty: "louvain"}
) YIELD communityCount
MATCH (most cancers:Class {label:"most cancers"})<-(:SCO|SCO_RESTRICTION *0..)-(n)
RETURN DISTINCT
n.label as label,
n.embedding as embedding,
n.louvain as louvain
Schauen wir uns einige dieser Cluster an, um zu sehen, welche Krebsarten zusammengefasst sind. Nachdem wir die exportierten Daten in einen Pandas-Datenrahmen in Python geladen haben, können wir einzelne Cluster untersuchen.
Cluster 2168 ist eine Gruppe von Bauchspeicheldrüsenkrebserkrankungen.
nodes(nodes.louvain == 2168)("label").tolist()
#array(('"islet cell tumor"',
# '"non-functioning pancreatic endocrine tumor"',
# '"pancreatic ACTH hormone producing tumor"',
# '"pancreatic somatostatinoma"',
# '"pancreatic vasoactive intestinal peptide producing tumor"',
# '"pancreatic gastrinoma"', '"pancreatic delta cell neoplasm"',
# '"pancreatic endocrine carcinoma"',
# '"pancreatic non-functioning delta cell tumor"'), dtype=object)
Cluster 174 ist eine größere Gruppe von Krebserkrankungen, hauptsächlich jedoch Karzinome.
nodes(nodes.louvain == 174)("label")
#array(('"head and neck most cancers"', '"glottis carcinoma"',
# '"head and neck carcinoma"', '"squamous cell carcinoma"',
#...
# '"pancreatic squamous cell carcinoma"',
# '"pancreatic adenosquamous carcinoma"',
#...
# '"blended epithelial/mesenchymal metaplastic breast carcinoma"',
# '"breast mucoepidermoid carcinoma"'), dtype=object)p
Dies sind sinnvolle Gruppierungen, die entweder auf Organen oder Krebsarten basieren und für die Visualisierung nützlich sind. Die Einbettungen hingegen sind immer noch zu hochdimensional, um sinnvoll visualisiert zu werden. Glücklicherweise ist TSNE eine sehr nützliche Methode zur Dimensionsreduzierung. Hier verwenden wir TSNE, um die Einbettung von 128 Dimensionen auf 2 zu reduzieren, während eng verwandte Knoten weiterhin nahe beieinander bleiben. Wir können überprüfen, ob dies funktioniert hat, indem wir diese beiden Dimensionen als Streudiagramm darstellen und nach den Louvain-Clustern einfärben. Wenn diese beiden Methoden übereinstimmen, sollten wir Knoten sehen, die nach Farbe gruppiert sind.
from sklearn.manifold import TSNEnodes = pd.read_csv("export.csv")
nodes('louvain') = pd.Categorical(nodes.louvain)
embedding = nodes.embedding.apply(lambda x: ast.literal_eval(x))
embedding = embedding.tolist()
embedding = pd.DataFrame(embedding)
tsne = TSNE()
X = tsne.fit_transform(embedding)
fig, axes = plt.subplots()
axes.scatter(
X(:,0),
X(:,1),
c = cm.tab20(Normalize()(nodes('louvain').cat.codes))
)
plt.present()
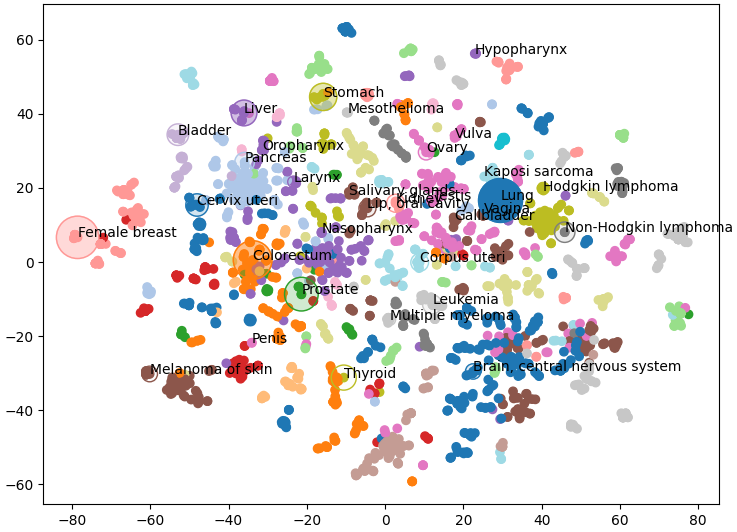
Und genau das sehen wir: Ähnliche Krebsarten werden gruppiert und als Cluster einer einzigen Farbe angezeigt. Beachten Sie, dass einige Knoten einer einzigen Farbe sehr weit voneinander entfernt sind. Dies liegt daran, dass wir einige Farben wiederverwenden müssen, da es 29 Cluster und nur 20 Farben gibt. Dies gibt uns einen guten Überblick über die Struktur unseres Wissensgraphen, aber wir können auch unsere eigenen Daten hinzufügen.
Nachfolgend stellen wir die Häufigkeit der Krebsart als Knotengröße und die Sterblichkeitsrate als Opazität dar (Bray et al 2024). Ich hatte nur für einige Krebsarten Zugriff auf diese Daten, daher habe ich nur diese Knotenpunkte dargestellt. Unten können wir sehen, dass Leberkrebs insgesamt keine besonders hohe Inzidenz aufweist. Die Inzidenzraten von Leberkrebs sind jedoch viel höher als bei anderen Krebsarten innerhalb seines Clusters (violett dargestellt) wie Oropharynx, Larynx und Nasopharynx.
Hier haben wir die Krankheitsontologie verwendet, um verschiedene Krebsarten in Cluster zu gruppieren, was uns den Kontext gibt, um diese Krankheiten zu vergleichen. Hoffentlich hat Ihnen dieses kleine Projekt gezeigt, wie Sie eine Ontologie visuell erkunden und diese Informationen Ihren eigenen Daten hinzufügen können.
Den vollständigen Code für dieses Projekt finden Sie unter https://github.com/DAWells/do_onto.
Bray, F., Laversanne, M., Sung, H., Ferlay, J., Siegel, RL, Soerjomataram, I., & Jemal, A. (2024). Globale Krebsstatistik 2022: GLOBOCAN-Schätzungen der Inzidenz und Mortalität weltweit für 36 Krebsarten in 185 Ländern. CA: eine Krebszeitschrift für Kliniker, 74(3), 229–263.