Wir helfen Ihnen, strukturierte Ergebnisse und LLMs besser zu verstehen und optimum zu nutzen

Im vorheriger Artikelwurden wir vorgestellt strukturierte Ausgaben mit OpenAI. Seit der allgemeinen Verfügbarkeitsfreigabe in der ChatCompletions-API (Model 1.40.0), strukturierte Ausgaben wurden in Dutzenden von Anwendungsfällen angewendet und haben zahlreiche Threads hervorgebracht auf OpenAI-Foren.
Unser Ziel in diesem Artikel ist es, Ihnen ein noch tieferes Verständnis zu vermitteln, einige Missverständnisse auszuräumen und Ihnen einige Tipps zu geben, wie Sie diese in verschiedenen Szenarien optimum anwenden können.
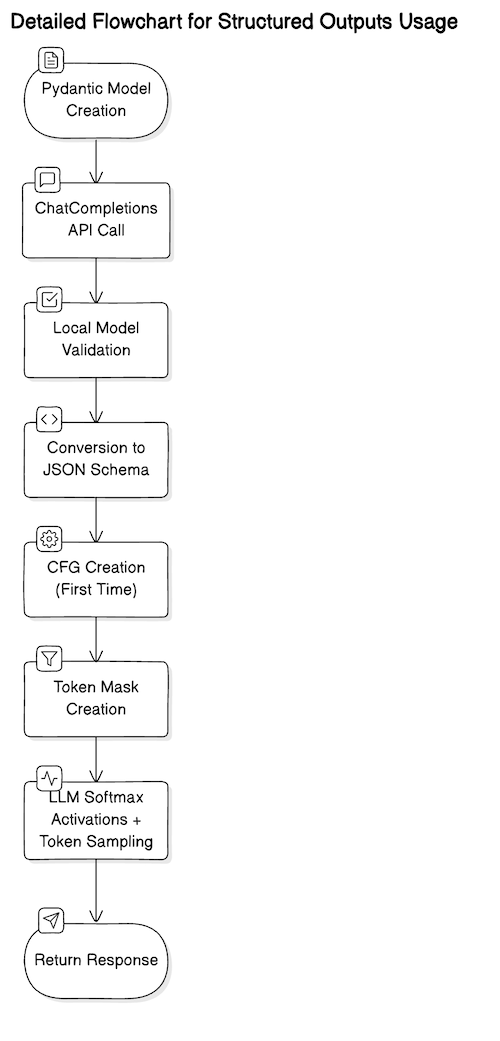
Strukturierte Ausgaben sind eine Möglichkeit, die Ausgabe eines LLM so zu gestalten, dass sie einem vordefinierten Schema folgt – normalerweise einem JSON-Schema. Dies funktioniert, indem das Schema in ein kontextfreie Grammatik (CFG)das während des Token-Sampling-Schritts zusammen mit den zuvor generierten Token verwendet wird, um zu informieren, welche nachfolgenden Token gültig sind. Es ist hilfreich, sich das so vorzustellen, als würde man ein regulärer Ausdruck zur Token-Generierung.
Die OpenAI API-Implementierung verfolgt tatsächlich eine begrenzte Teilmenge der JSON-Schemafunktionen. Mit allgemeineren strukturierten Ausgabelösungen wie Umrisseist es möglich, eine etwas größere Teilmenge des JSON-Schemas zu verwenden und sogar vollständig benutzerdefinierte Nicht-JSON-Schemas zu definieren – solange man Zugriff auf ein offenes Gewichtsmodell hat. Für die Zwecke dieses Artikels gehen wir von der OpenAI-API-Implementierung aus.
Entsprechend JSON Schema Core-Spezifikation, „Das JSON-Schema legt fest, wie ein JSON-Dokument aussehen muss, wie Informationen daraus extrahiert werden und wie mit ihm interagiert wird.“. Das JSON-Schema definiert sechs primitive Typen – Null, Boolean, Objekt, Array, Zahl und Zeichenfolge. Es definiert auch bestimmte Schlüsselwörter, Anmerkungen und bestimmte Verhaltensweisen. Beispielsweise können wir in unserem Schema angeben, dass wir einen array und fügen Sie eine Anmerkung hinzu, die minItems soll sein 5 .
Pydantic ist eine Python-Bibliothek, die die JSON-Schemaspezifikation implementiert. Wir verwenden Pydantic, um robuste und wartbare Software program in Python zu erstellen. Da Python eine dynamisch typisierte Sprache ist, denken Datenwissenschaftler nicht unbedingt in Begriffen wie Variablentypen — diese sind oft impliziert in ihrem Code. Eine Frucht würde beispielsweise wie folgt angegeben:
fruit = dict(
identify="apple",
coloration="crimson",
weight=4.2
)
…während eine Funktionsdeklaration, die „Früchte“ aus bestimmten Daten zurückgibt, oft wie folgt angegeben würde:
def extract_fruit(s):
...
return fruit
Pydantic hingegen ermöglicht es uns, eine JSON-Schema-kompatible Klasse mit richtig annotierten Variablen zu generieren und Typhinweisewodurch unser Code lesbarer/wartungsfreundlicher und im Allgemeinen robuster wird, d. h.
class Fruit(BaseModel):
identify: str
coloration: Literal('crimson', 'inexperienced')
weight: Annotated(float, Gt(0))def extract_fruit(s: str) -> Fruit:
...
return fruit
OpenAI tatsächlich empfiehlt dringend die Verwendung von Pydantic zum Angeben von Schemata, im Gegensatz zur direkten Angabe des „rohen“ JSON-Schemas. Dafür gibt es mehrere Gründe. Erstens hält sich Pydantic garantiert an die JSON-Schemaspezifikation, sodass Sie zusätzliche Schritte vor der Validierung sparen. Zweitens ist es bei größeren Schemata weniger ausführlich, sodass Sie schneller sauberen Code schreiben können. Schließlich ist die openai Das Python-Paket erledigt tatsächlich einige Verwaltungsaufgaben, wie das Setzen additionalProperties Zu False für Sie, während Sie bei der manuellen Definition Ihres Schemas mit JSON Stellen Sie diese manuell einfür jedes Objekt in Ihrem Schema (wenn Sie dies nicht tun, führt dies zu einem ziemlich ärgerlichen API-Fehler).
Wie bereits erwähnt, bietet die ChatCompletions-API eine begrenzte Teilmenge der vollständigen JSON-Schemaspezifikation. Es gibt zahlreiche Schlüsselwörter, die noch nicht unterstützt werdenwie zum Beispiel minimal Und most für Zahlen und minItems Und maxItems für Arrays – Anmerkungen, die ansonsten sehr nützlich wären, um Halluzinationen zu reduzieren oder die Ausgabegröße einzuschränken.
Bestimmte Formatierungsfunktionen sind ebenfalls nicht verfügbar. Beispielsweise würde das folgende Pydantic-Schema zu einem API-Fehler führen, wenn es an response_format in ChatCompletions:
class NewsArticle(BaseModel):
headline: str
subheading: str
authors: Record(str)
date_published: datetime = Subject(None, description="Date when article was revealed. Use ISO 8601 date format.")
Es würde scheitern, weil openai Paket hat keine Formatverarbeitung für datetime Sie müssten additionally stattdessen date_published als str und führen Sie nachträglich eine Formatvalidierung (z. B. Konformität mit ISO 8601) durch.
Zu den weiteren wichtigen Einschränkungen gehören:
- Halluzinationen sind immer noch möglich – wenn Sie beispielsweise Produkt-IDs extrahieren, würden Sie in Ihrem Antwortschema Folgendes definieren:
product_ids: Record(str); während die Ausgabe garantiert eine Liste von Zeichenfolgen (Produkt-IDs) erzeugt, können die Zeichenfolgen selbst halluziniert sein. In diesem Anwendungsfall möchten Sie die Ausgabe daher möglicherweise anhand eines vordefinierten Satzes von Produkt-IDs validieren. - Die Leistung ist begrenzt bei
4096Tokens oder die niedrigere Zahl, die Sie innerhalb desmax_tokensParameter — auch wenn das Schema genau befolgt wird, wird die Ausgabe, wenn sie zu groß ist, abgeschnitten und es entsteht ein ungültiges JSON — besonders ärgerlich bei sehr großen Batch-API Arbeitsplätze! - Tief verschachtelte Schemata mit vielen Objekteigenschaften kann zu API-Fehlern führen — es gibt eine Begrenzung der Tiefe und Breite Ihres Schemas, aber im Allgemeinen ist es am besten, bei flachen und einfachen Strukturen zu bleiben – nicht nur, um API-Fehler zu vermeiden, sondern auch, um möglichst viel Leistung aus den LLMs herauszuholen (LLMs haben im Allgemeinen Probleme, tief verschachtelte Strukturen zu berücksichtigen).
- Hochdynamische oder beliebige Schemata sind nicht möglich – wenngleich Rekursion wird unterstütztist es nicht möglich, ein hochdynamisches Schema aus beispielsweise einer Liste beliebiger Schlüssel-Wert-Objekte zu erstellen, d. h.
({"key1": "val1"}, {"key2": "val2"}, ..., {"keyN": "valN"})da die „Schlüssel“ in diesem Fall muss vordefiniert sein; in einem solchen Szenario besteht die beste Possibility darin, überhaupt keine strukturierten Ausgaben zu verwenden, sondern sich stattdessen für den Commonplace-JSON-Modus zu entscheiden und die Anweisungen zur Ausgabestruktur in der Systemaufforderung bereitzustellen.
Vor diesem Hintergrund können wir nun einige Anwendungsfälle mit Tipps und Tips durchgehen, wie sich die Leistung bei der Verwendung strukturierter Ausgaben verbessern lässt.
Schaffen von Flexibilität durch optionale Parameter
Nehmen wir an, wir erstellen eine Internet Scraping-Anwendung, deren Ziel darin besteht, bestimmte Komponenten von den Webseiten zu sammeln. Für jede Webseite stellen wir das Roh-HTML in der Benutzereingabeaufforderung bereit, geben in der Systemeingabeaufforderung spezifische Scraping-Anweisungen und definieren das folgende Pydantic-Modell:
class Webpage(BaseModel):
title: str
paragraphs: Optionally available(Record(str)) = Subject(None, description="Textual content contents enclosed inside <p></p> tags.")
hyperlinks: Optionally available(Record(str)) = Subject(None, description="URLs specified by `href` area inside <a></a> tags.")
photographs: Optionally available(Record(str)) = Subject(None, description="URLs specified by the `src` area throughout the <img></img> tags.")
Wir würden die API dann wie folgt aufrufen …
response = shopper.beta.chat.completions.parse(
mannequin="gpt-4o-2024-08-06",
messages=(
{
"function": "system",
"content material": "You're to parse HTML and return the parsed web page parts."
},
{
"function": "person",
"content material": """
<html>
<title>Structured Outputs Demo</title>
<physique>
<img src="check.gif"></picture>
<p>Good day world!</p>
</physique>
</html>
"""
}
),
response_format=Webpage
)
…mit folgender Antwort:
{
'photographs': ('check.gif'),
'hyperlinks': None,
'paragraphs': ('Good day world!'),
'title': 'Structured Outputs Demo'
}
An die API übermitteltes Antwortschema mithilfe strukturierter Ausgaben muss alle angegebenen Felder zurückgeben. Wir können jedoch optionale Felder „emulieren“ und mehr Flexibilität hinzufügen, indem wir Optionally available Typannotation. Wir könnten eigentlich auch verwenden Union(Record(str), None) — sie sind syntaktisch genau gleich. In beiden Fällen erhalten wir eine Konvertierung zu anyOf Schlüsselwort gemäß der JSON-Schemaspezifikation. Im obigen Beispiel gibt es keine <a></a> Tags auf der Webseite vorhanden sind, gibt die API immer noch die hyperlinks Feld, aber es ist eingestellt auf None .
Reduzierung von Halluzinationen durch Enumerationen
Wir haben bereits erwähnt, dass das LLM, selbst wenn es garantiert dem vorgegebenen Antwortschema folgt, dennoch die tatsächlichen Werte halluzinieren kann. Hinzu kommt, dass ein Aktuelles Papier stellte fest, dass das Aufzwingen eines festen Schemas für die Ausgaben tatsächlich dazu führt, dass das LLM halluziniert oder seine Denkfähigkeiten nachlassen.
Eine Möglichkeit, diese Einschränkungen zu überwinden, besteht darin, so viel wie möglich Enumerationen zu verwenden. Enumerationen beschränken die Ausgabe auf einen sehr spezifischen Satz von Token und setzen für alles andere eine Wahrscheinlichkeit von Null. Nehmen wir beispielsweise an, Sie versuchen, die Produktähnlichkeitsergebnisse zwischen einem Zielprodukt das enthält eine description und ein einzigartiges product_id Und High-5-Produkte die mithilfe einer Vektorähnlichkeitssuche (z. B. mithilfe einer Kosinus-Distanzmetrik) ermittelt wurden. Jedes dieser High-5-Produkte enthält auch die entsprechende Textbeschreibung und eine eindeutige ID. In Ihrer Antwort möchten Sie lediglich die Neubewertung 1–5 als Liste erhalten (z. B. (1, 4, 3, 5, 2) ), anstatt eine Liste mit neu bewerteten Produkt-ID-Zeichenfolgen zu erhalten, die möglicherweise halluziniert oder ungültig sind. Wir richten unser Pydantic-Modell wie folgt ein …
class Rank(IntEnum):
RANK_1 = 1
RANK_2 = 2
RANK_3 = 3
RANK_4 = 4
RANK_5 = 5class RerankingResult(BaseModel):
ordered_ranking: Record(Rank) = Subject(description="Supplies ordered rating 1-5.")
…und führen Sie die API wie folgt aus:
response = shopper.beta.chat.completions.parse(
mannequin="gpt-4o-2024-08-06",
messages=(
{
"function": "system",
"content material": """
You're to rank the similarity of the candidate merchandise towards the goal product.
Rating must be orderly, from essentially the most comparable, to the least comparable.
"""
},
{
"function": "person",
"content material": """
## Goal Product
Product ID: X56HHGHH
Product Description: 80" Samsung LED TV## Candidate Merchandise
Product ID: 125GHJJJGH
Product Description: NVIDIA RTX 4060 GPU
Product ID: 76876876GHJ
Product Description: Sony Walkman
Product ID: 433FGHHGG
Product Description: Sony LED TV 56"
Product ID: 777888887888
Product Description: Blueray Sony Participant
Product ID: JGHHJGJ56
Product Description: BenQ PC Monitor 37" 4K UHD
"""
}
),
response_format=RerankingResult
)
Das Endergebnis ist einfach:
{'ordered_ranking': (3, 5, 1, 4, 2)}
So stufte das LLM den Sony LED-Fernseher (d. h. Artikelnummer „3“ in der Liste) und den BenQ PC-Monitor (d. h. Artikelnummer „5“) als die beiden ähnlichsten Produktkandidaten ein, d. h. die ersten beiden Elemente der ordered_ranking Liste!
In diesem Artikel haben wir uns eingehend mit strukturierten Ausgaben befasst. Wir haben das JSON-Schema und die Pydantic-Modelle vorgestellt und diese mit der ChatCompletions-API von OpenAI verbunden. Wir haben eine Reihe von Beispielen durchgegangen und einige optimale Möglichkeiten zur Lösung dieser Probleme mit strukturierten Ausgaben aufgezeigt. Um einige wichtige Erkenntnisse zusammenzufassen:
- Strukturierte Ausgaben, wie sie von OpenAI API und anderen Drittanbieter-Frameworks unterstützt werden, implementieren nur eine Teilmenge der JSON-Schemaspezifikation – Wenn Sie sich besser über die Funktionen und Einschränkungen informieren, können Sie die richtigen Designentscheidungen treffen.
- Verwenden von Pydantisch oder ähnliche Frameworks, die die JSON-Schemaspezifikation genau verfolgen, werden dringend empfohlen, da Sie damit gültigen und saubereren Code erstellen können.
- Obwohl Halluzinationen immer noch zu erwarten sind, gibt es verschiedene Möglichkeiten, diese zu mildern, einfach durch die Wahl des Reaktionsschemas; zum Beispiel durch Verwendung von Enumerationen sofern angemessen.
Über den Autor
Armin Catovic ist Vorstandssekretär bei Stockholm KIund Vizepräsident und Senior ML/AI Engineer bei der EQT-Gruppemit 18 Jahren Ingenieurerfahrung in Australien, Südostasien, Europa und den USA sowie einer Reihe von Patenten und erstklassigen, von Experten begutachteten KI-Veröffentlichungen.