Verwenden Sie Fälle und Code, um die neue Klasse zu erkunden, die dabei hilft, Entscheidungsschwellen in scikit-learn anzupassen.
Die Model 1.5 von scikit-learn enthält eine neue Klasse, TunedThresholdClassifierCVwodurch die Optimierung von Entscheidungsschwellen von Scikit-Be taught-Klassifikatoren einfacher wird. Eine Entscheidungsschwelle ist ein Grenzwert, der die von einem maschinellen Lernmodell ausgegebenen vorhergesagten Wahrscheinlichkeiten in diskrete Klassen umwandelt. Die Standardentscheidungsschwelle des .predict() Methode von scikit-learn-Klassifikatoren in einer binären Klassifizierungseinstellung ist 0,5. Obwohl dies ein sinnvoller Standardwert ist, ist es selten die beste Wahl für Klassifizierungsaufgaben.
Dieser Beitrag stellt die Klasse TunedThresholdClassifierCV vor und zeigt, wie sie Entscheidungsschwellen für verschiedene binäre Klassifizierungsaufgaben optimieren kann. Diese neue Klasse wird dazu beitragen, die Lücke zwischen Datenwissenschaftlern, die Modelle erstellen, und Geschäftspartnern zu schließen, die Entscheidungen auf Grundlage der Ergebnisse des Modells treffen. Durch die Feinabstimmung der Entscheidungsschwellen können Datenwissenschaftler die Modellleistung verbessern und sie besser an Geschäftsziele anpassen.
In diesem Beitrag werden die folgenden Situationen behandelt, in denen die Anpassung der Entscheidungsschwellenwerte von Vorteil ist:
- Maximieren einer Metrik: Verwenden Sie dies, wenn Sie einen Schwellenwert auswählen, der eine Bewertungsmetrik maximiert, wie etwa die F1-Bewertung.
- Kostensensibles Lernen: Passen Sie den Schwellenwert an, wenn die Kosten für die Fehlklassifizierung eines falsch positiven Ergebnisses nicht den Kosten für die Fehlklassifizierung eines falsch negativen Ergebnisses entsprechen und Sie über eine Kostenschätzung verfügen.
- Tuning unter Zwängen: Optimieren Sie den Betriebspunkt auf der ROC- oder Präzisions-Recall-Kurve, um bestimmte Leistungseinschränkungen zu erfüllen.
Der in diesem Beitrag verwendete Code und Hyperlinks zu Datensätzen sind verfügbar unter GitHub.
Lass uns anfangen! Importiere zunächst die notwendigen Bibliotheken, lies die Daten und teile Trainings- und Testdaten auf.
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
from sklearn.compose import ColumnTransformer
from sklearn.compose import make_column_selector as selector
from sklearn.ensemble import RandomForestClassifier
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import (
RocCurveDisplay,
f1_score,
make_scorer,
recall_score,
roc_curve,
confusion_matrix,
)
from sklearn.model_selection import TunedThresholdClassifierCV, train_test_split
from sklearn.pipeline import make_pipeline
from sklearn.preprocessing import OneHotEncoder, StandardScalerRANDOM_STATE = 26120
Maximieren einer Metrik
Bevor Sie mit dem Modellerstellungsprozess in einem Machine-Studying-Projekt beginnen, müssen Sie unbedingt gemeinsam mit den Beteiligten bestimmen, welche Metrik(en) optimiert werden soll(en). Wenn Sie diese Entscheidung frühzeitig treffen, stellen Sie sicher, dass das Projekt seinen beabsichtigten Zielen entspricht.
Die Verwendung einer Genauigkeitsmetrik in Anwendungsfällen zur Betrugserkennung zur Bewertung der Modellleistung ist nicht superb, da die Daten oft unausgewogen sind und die meisten Transaktionen nicht betrügerisch sind. Der F1-Rating ist das harmonische Mittel aus Präzision und Rückruf und ist eine bessere Metrik für unausgewogene Datensätze wie die Betrugserkennung. Verwenden wir den TunedThresholdClassifierCV Klasse zur Optimierung der Entscheidungsschwelle eines logistischen Regressionsmodells, um den F1-Rating zu maximieren.
Wir verwenden die Kaggle-Datensatz zur Erkennung von Kreditkartenbetrug um die erste State of affairs vorzustellen, in der wir einen Entscheidungsschwellenwert anpassen müssen. Teilen Sie zunächst die Daten in Trainings- und Testsätze auf und erstellen Sie dann eine Scikit-Be taught-Pipeline, um die Daten zu skalieren und ein logistisches Regressionsmodell zu trainieren. Passen Sie die Pipeline an die Trainingsdaten an, damit wir die ursprüngliche Modellleistung mit der optimierten Modellleistung vergleichen können.
creditcard = pd.read_csv("knowledge/creditcard.csv")
y = creditcard("Class")
X = creditcard.drop(columns=("Class"))X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=RANDOM_STATE, stratify=y
)
# Solely Time and Quantity should be scaled
original_fraud_model = make_pipeline(
ColumnTransformer(
(("scaler", StandardScaler(), ("Time", "Quantity"))),
the rest="passthrough",
force_int_remainder_cols=False,
),
LogisticRegression(),
)
original_fraud_model.match(X_train, y_train)
Es ist noch keine Feinabstimmung erfolgt, aber sie kommt im nächsten Codeblock. Die Argumente für TunedThresholdClassifierCV sind ähnlich wie andere CV Klassen in scikit-learn, wie zum Beispiel GridSearchCVDer Benutzer muss lediglich den ursprünglichen Schätzer übergeben und TunedThresholdClassifierCV speichert den Entscheidungsschwellenwert, der die ausgewogene Genauigkeit maximiert (Customary) unter Verwendung einer 5-fach geschichteten Okay-fachen Kreuzvalidierung (Customary). Dieser Schwellenwert wird auch beim Aufrufen von verwendet .predict(). Allerdings kann jede beliebige scikit-learn Metrik (oder aufrufbare Metrik) als scoring Metrik. Zusätzlich kann der Benutzer die bekannte cv Argument zum Anpassen der Kreuzvalidierungsstrategie.
Erstellen Sie die TunedThresholdClassifierCV Instanz und passen Sie das Modell an die Trainingsdaten an. Übergeben Sie das ursprüngliche Modell und setzen Sie die Bewertung auf „f1“. Wir möchten auch festlegen store_cv_results=True um auf die während der Kreuzvalidierung ausgewerteten Schwellenwerte zuzugreifen und diese zu visualisieren.
tuned_fraud_model = TunedThresholdClassifierCV(
original_fraud_model,
scoring="f1",
store_cv_results=True,
)tuned_fraud_model.match(X_train, y_train)
# common F1 throughout folds
avg_f1_train = tuned_fraud_model.best_score_
# Examine F1 within the take a look at set for the tuned mannequin and the unique mannequin
f1_test = f1_score(y_test, tuned_fraud_model.predict(X_test))
f1_test_original = f1_score(y_test, original_fraud_model.predict(X_test))
print(f"Common F1 on the coaching set: {avg_f1_train:.3f}")
print(f"F1 on the take a look at set: {f1_test:.3f}")
print(f"F1 on the take a look at set (authentic mannequin): {f1_test_original:.3f}")
print(f"Threshold: {tuned_fraud_model.best_threshold_: .3f}")
Common F1 on the coaching set: 0.784
F1 on the take a look at set: 0.796
F1 on the take a look at set (authentic mannequin): 0.733
Threshold: 0.071
Nachdem wir nun den Schwellenwert gefunden haben, der den F1-Rating maximiert, überprüfen Sie tuned_fraud_model.best_score_ um herauszufinden, was der beste durchschnittliche F1-Rating über alle Folds hinweg in der Kreuzvalidierung warfare. Wir können auch sehen, welcher Schwellenwert diese Ergebnisse erzeugt hat, indem wir tuned_fraud_model.best_threshold_Sie können die Metrikwerte über die Entscheidungsschwellenwerte während der Kreuzvalidierung mithilfe der objective_scores_ Und decision_thresholds_ Attribute:
fig, ax = plt.subplots(figsize=(5, 5))
ax.plot(
tuned_fraud_model.cv_results_("thresholds"),
tuned_fraud_model.cv_results_("scores"),
marker="o",
linewidth=1e-3,
markersize=4,
colour="#c0c0c0",
)
ax.plot(
tuned_fraud_model.best_threshold_,
tuned_fraud_model.best_score_,
"^",
markersize=10,
colour="#ff6700",
label=f"Optimum cut-off level = {tuned_fraud_model.best_threshold_:.2f}",
)
ax.plot(
0.5,
f1_test_original,
label="Default threshold: 0.5",
colour="#004e98",
linestyle="--",
marker="X",
markersize=10,
)
ax.legend(fontsize=8, loc="decrease heart")
ax.set_xlabel("Resolution threshold", fontsize=10)
ax.set_ylabel("F1 rating", fontsize=10)
ax.set_title("F1 rating vs. Resolution threshold -- Cross-validation", fontsize=12)

# Verify that the coefficients from the unique mannequin and the tuned mannequin are the identical
assert (tuned_fraud_model.estimator_(-1).coef_ ==
original_fraud_model(-1).coef_).all()
Wir haben dasselbe zugrunde liegende logistische Regressionsmodell verwendet, um zwei verschiedene Entscheidungsschwellenwerte zu bewerten. Die zugrunde liegenden Modelle sind dieselben, was durch die Koeffizientengleichheit in der obigen Assert-Anweisung belegt wird. Optimierung in TunedThresholdClassifierCV wird durch Nachbearbeitungstechniken erreicht, die direkt auf die vom Modell ausgegebenen vorhergesagten Wahrscheinlichkeiten angewendet werden. Es ist jedoch wichtig zu beachten, dass TunedThresholdClassifierCV verwendet standardmäßig die Kreuzvalidierung, um die Entscheidungsschwelle zu finden und eine Überanpassung der Trainingsdaten zu vermeiden.
Kostensensibles Lernen
Kostensensitives Lernen ist eine Artwork maschinellen Lernens, bei dem jeder Artwork von Fehlklassifizierung Kosten zugewiesen werden. Dadurch wird die Modellleistung in Einheiten übersetzt, die die Beteiligten verstehen, z. B. eingesparte Dollarbeträge.
Wir verwenden die TELCO-Kundenabwanderungsdatensatzein binärer Klassifizierungsdatensatz, um den Wert kostensensitiven Lernens zu demonstrieren. Ziel ist es, vorherzusagen, ob ein Kunde abwandern wird oder nicht, basierend auf Merkmalen der demografischen Daten des Kunden, Vertragsdetails und anderen technischen Informationen über das Konto des Kunden. Die Motivation, diesen Datensatz (und einen Teil des Codes) zu verwenden, ist von Dan Beckers Kurs zur Entscheidungsschwellenoptimierung.
knowledge = pd.read_excel("knowledge/Telco_customer_churn.xlsx")
drop_cols = (
"Rely", "Nation", "State", "Lat Lengthy", "Latitude", "Longitude",
"Zip Code", "Churn Worth", "Churn Rating", "CLTV", "Churn Cause"
)
knowledge.drop(columns=drop_cols, inplace=True)# Preprocess the information
knowledge("Churn Label") = knowledge("Churn Label").map({"Sure": 1, "No": 0})
knowledge.drop(columns=("Complete Fees"), inplace=True)
X_train, X_test, y_train, y_test = train_test_split(
knowledge.drop(columns=("Churn Label")),
knowledge("Churn Label"),
test_size=0.2,
random_state=RANDOM_STATE,
stratify=knowledge("Churn Label"),
)
Richten Sie eine grundlegende Pipeline zur Verarbeitung der Daten und zur Generierung von Vorhersagewahrscheinlichkeiten mit einem Random-Forest-Modell ein. Dies dient als Grundlage für den Vergleich mit TunedThresholdClassifierCV.
preprocessor = ColumnTransformer(
transformers=(("one_hot", OneHotEncoder(),
selector(dtype_include="object"))),
the rest="passthrough",
)original_churn_model = make_pipeline(
preprocessor, RandomForestClassifier(random_state=RANDOM_STATE)
)
original_churn_model.match(X_train.drop(columns=("customerID")), y_train);
Die Wahl der Vorverarbeitung und des Modelltyps ist für dieses Tutorial nicht wichtig. Das Unternehmen möchte Kunden, bei denen eine Abwanderung vorhergesagt wird, Rabatte anbieten. Während der Zusammenarbeit mit Stakeholdern erfahren Sie, dass es 80 $ kosten würde, einem Kunden, der nicht abwandern wird (ein falsch positives Ergebnis), einen Rabatt zu gewähren. Sie erfahren auch, dass es 200 $ wert ist, einem Kunden, der abgewandert wäre, einen Rabatt anzubieten. Sie können diese Beziehung in einer Kostenmatrix darstellen:
def cost_function(y, y_pred, neg_label, pos_label):
cm = confusion_matrix(y, y_pred, labels=(neg_label, pos_label))
cost_matrix = np.array(((0, -80), (0, 200)))
return np.sum(cm * cost_matrix)cost_scorer = make_scorer(cost_function, neg_label=0, pos_label=1)
Wir haben die Kostenfunktion auch in einen benutzerdefinierten scikit-learn-Scorer eingebunden. Dieser Scorer wird als scoring Argument im TunedThresholdClassifierCV und um den Gewinn im Testsatz zu bewerten.
tuned_churn_model = TunedThresholdClassifierCV(
original_churn_model,
scoring=cost_scorer,
store_cv_results=True,
)tuned_churn_model.match(X_train.drop(columns=("CustomerID")), y_train)
# Calculate the revenue on the take a look at set
original_model_profit = cost_scorer(
original_churn_model, X_test.drop(columns=("CustomerID")), y_test
)
tuned_model_profit = cost_scorer(
tuned_churn_model, X_test.drop(columns=("CustomerID")), y_test
)
print(f"Unique mannequin revenue: {original_model_profit}")
print(f"Tuned mannequin revenue: {tuned_model_profit}")
Unique mannequin revenue: 29640
Tuned mannequin revenue: 35600
Der Gewinn ist im optimierten Modell höher als im Unique. Auch hier können wir die objektive Metrik gegenüber den Entscheidungsschwellenwerten darstellen, um die Auswahl der Entscheidungsschwellenwerte für Trainingsdaten während der Kreuzvalidierung zu visualisieren:
fig, ax = plt.subplots(figsize=(5, 5))
ax.plot(
tuned_churn_model.cv_results_("thresholds"),
tuned_churn_model.cv_results_("scores"),
marker="o",
markersize=3,
linewidth=1e-3,
colour="#c0c0c0",
label="Goal rating (utilizing cost-matrix)",
)
ax.plot(
tuned_churn_model.best_threshold_,
tuned_churn_model.best_score_,
"^",
markersize=10,
colour="#ff6700",
label="Optimum cut-off level for the enterprise metric",
)
ax.legend()
ax.set_xlabel("Resolution threshold (likelihood)")
ax.set_ylabel("Goal rating (utilizing cost-matrix)")
ax.set_title("Goal rating as a operate of the choice threshold")

In Wirklichkeit ist es aus geschäftlicher Sicht nicht realistisch, allen Instanzen, die auf die gleiche Weise falsch klassifiziert wurden, statische Kosten zuzuweisen. Es gibt fortgeschrittenere Methoden, um den Schwellenwert anzupassen, indem jeder Instanz im Datensatz ein Gewicht zugewiesen wird. Dies wird behandelt in Beispiel für kostensensitives Lernen von scikit-learn.
Tuning unter Zwängen
Diese Methode wird derzeit nicht in der scikit-learn-Dokumentation behandelt, ist aber ein gängiger Geschäftsfall für Anwendungsfälle der binären Klassifizierung. Die Methode „Tuning unter Einschränkung“ findet eine Entscheidungsschwelle, indem sie einen Punkt auf den ROC- oder Präzisions-Recall-Kurven identifiziert. Der Punkt auf der Kurve ist der Maximalwert einer Achse bei Einschränkung der anderen Achse. Für diese exemplarische Vorgehensweise verwenden wir den Diabetes-Datensatz der Pima-Indianer. Dies ist eine binäre Klassifizierungsaufgabe, um vorherzusagen, ob eine Individual Diabetes hat.
Stellen Sie sich vor, Ihr Modell wird als Screeningtest für eine Bevölkerung mit durchschnittlichem Risiko verwendet, der auf Millionen von Menschen angewendet wird. In den USA gibt es schätzungsweise 38 Millionen Menschen mit Diabetes. Das sind etwa 11,6 % der Bevölkerung. Die Spezifität des Modells sollte additionally hoch sein, damit es Millionen von Menschen nicht falsch diagnostiziert und sie unnötigen Bestätigungstests zuweist. Nehmen wir an, Ihr imaginärer CEO hat mitgeteilt, dass er eine Falsch-Positiv-Charge von mehr als 2 % nicht tolerieren wird. Lassen Sie uns ein Modell erstellen, das dies erreicht, indem wir TunedThresholdClassifierCV.
Für diesen Teil des Tutorials definieren wir eine Einschränkungsfunktion, die verwendet wird, um die maximale True-Optimistic-Charge bei einer False-Optimistic-Charge von 2 % zu ermitteln.
def max_tpr_at_tnr_constraint_score(y_true, y_pred, max_tnr=0.5):
fpr, tpr, thresholds = roc_curve(y_true, y_pred, drop_intermediate=False)
tnr = 1 - fpr
tpr_at_tnr_constraint = tpr(tnr >= max_tnr).max()
return tpr_at_tnr_constraintmax_tpr_at_tnr_scorer = make_scorer(
max_tpr_at_tnr_constraint_score, max_tnr=0.98)
knowledge = pd.read_csv("knowledge/diabetes.csv")
X_train, X_test, y_train, y_test = train_test_split(
knowledge.drop(columns=("Final result")),
knowledge("Final result"),
stratify=knowledge("Final result"),
test_size=0.2,
random_state=RANDOM_STATE,
)
Erstellen Sie zwei Modelle, ein logistisches Regressionsmodell, das als Basismodell dient, und das andere TunedThresholdClassifierCV Dies wird das Foundation-Logistik-Regressionsmodell umschließen, um das vom CEO festgelegte Ziel zu erreichen. Im abgestimmten Modell setzen Sie scoring=max_tpr_at_tnr_scorer. Auch hier ist die Wahl des Modells und der Vorverarbeitung für dieses Tutorial nicht wichtig.
# A baseline mannequin
original_model = make_pipeline(
StandardScaler(), LogisticRegression(random_state=RANDOM_STATE)
)
original_model.match(X_train, y_train)# A tuned mannequin
tuned_model = TunedThresholdClassifierCV(
original_model,
thresholds=np.linspace(0, 1, 150),
scoring=max_tpr_at_tnr_scorer,
store_cv_results=True,
cv=8,
random_state=RANDOM_STATE,
)
tuned_model.match(X_train, y_train)
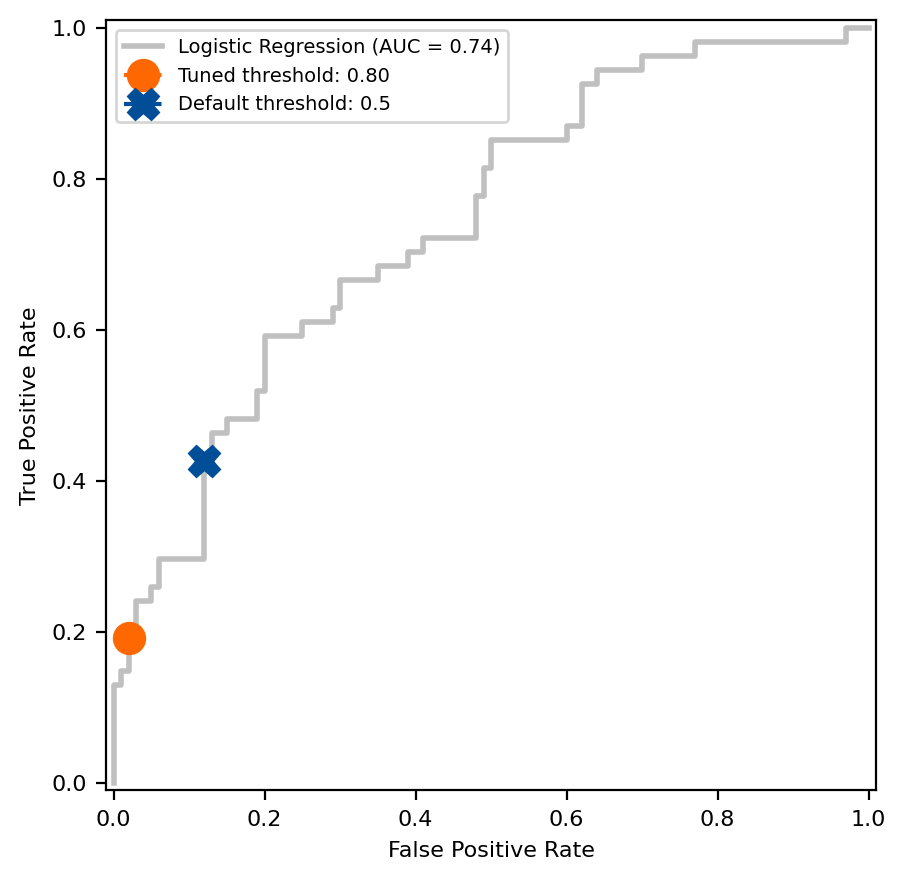
Vergleichen Sie die Differenz zwischen dem Standardentscheidungsschwellenwert von 0,5 der Scikit-Be taught-Schätzer und dem Wert, der mithilfe des Tuning-under-Constraint-Ansatzes auf der ROC-Kurve ermittelt wurde.
# Get the fpr and tpr of the unique mannequin
original_model_proba = original_model.predict_proba(X_test)(:, 1)
fpr, tpr, thresholds = roc_curve(y_test, original_model_proba)
closest_threshold_to_05 = (np.abs(thresholds - 0.5)).argmin()
fpr_orig = fpr(closest_threshold_to_05)
tpr_orig = tpr(closest_threshold_to_05)# Get the tnr and tpr of the tuned mannequin
max_tpr = tuned_model.best_score_
constrained_tnr = 0.98
# Plot the ROC curve and examine the default threshold to the tuned threshold
fig, ax = plt.subplots(figsize=(5, 5))
# Be aware that this would be the similar for each fashions
disp = RocCurveDisplay.from_estimator(
original_model,
X_test,
y_test,
identify="Logistic Regression",
colour="#c0c0c0",
linewidth=2,
ax=ax,
)
disp.ax_.plot(
1 - constrained_tnr,
max_tpr,
label=f"Tuned threshold: {tuned_model.best_threshold_:.2f}",
colour="#ff6700",
linestyle="--",
marker="o",
markersize=11,
)
disp.ax_.plot(
fpr_orig,
tpr_orig,
label="Default threshold: 0.5",
colour="#004e98",
linestyle="--",
marker="X",
markersize=11,
)
disp.ax_.set_ylabel("True Optimistic Charge", fontsize=8)
disp.ax_.set_xlabel("False Optimistic Charge", fontsize=8)
disp.ax_.tick_params(labelsize=8)
disp.ax_.legend(fontsize=7)

Die Methode „Tuned Underneath Constraint“ ergab einen Schwellenwert von 0,80, was bei der Kreuzvalidierung der Trainingsdaten zu einer durchschnittlichen Sensitivität von 19,2 % führte. Vergleichen Sie Sensitivität und Spezifität, um zu sehen, wie sich der Schwellenwert im Testsatz verhält. Hat das Modell die Spezifitätsanforderung des CEO im Testsatz erfüllt?
# Common sensitivity and specificity on the coaching set
avg_sensitivity_train = tuned_model.best_score_# Name predict from tuned_model to calculate sensitivity and specificity on the take a look at set
specificity_test = recall_score(
y_test, tuned_model.predict(X_test), pos_label=0)
sensitivity_test = recall_score(y_test, tuned_model.predict(X_test))
print(f"Common sensitivity on the coaching set: {avg_sensitivity_train:.3f}")
print(f"Sensitivity on the take a look at set: {sensitivity_test:.3f}")
print(f"Specificity on the take a look at set: {specificity_test:.3f}")
Common sensitivity on the coaching set: 0.192
Sensitivity on the take a look at set: 0.148
Specificity on the take a look at set: 0.990
Abschluss
Das neue TunedThresholdClassifierCV Der Kurs ist ein leistungsstarkes Device, mit dem Sie ein besserer Datenwissenschaftler werden können, indem Sie mit Unternehmensleitern teilen, wie Sie zu einer Entscheidungsschwelle gekommen sind. Sie haben gelernt, wie Sie das neue scikit-learn verwenden TunedThresholdClassifierCV Klasse, um eine Metrik zu maximieren, kostensensitives Lernen durchzuführen und eine Metrik unter Einschränkungen zu optimieren. Dieses Tutorial sollte weder umfassend noch fortgeschritten sein. Ich wollte die neue Funktion vorstellen und ihre Leistungsfähigkeit und Flexibilität bei der Lösung binärer Klassifizierungsprobleme hervorheben. Ausführliche Anwendungsbeispiele finden Sie in der scikit-learn-Dokumentation, im Benutzerhandbuch und in den Beispielen.
Ein großes Dankeschön an Guillaume Lemaître für seine Arbeit an diesem Function.
Danke fürs Lesen. Viel Spaß beim Tunen.
Datenlizenzen:
Kreditkartenbetrug: DbCL
Diabetes der Pima-Indianer: CC0
Telko-Abwanderung: gewerbliche Nutzung OK