Stellen Sie sich vor, Sie fahren mit einem autonomen Fahrzeug durch einen Tunnel, doch ohne dass Sie es merken, hat ein Unfall den Verkehr vor Ihnen zum Erliegen gebracht. Normalerweise müssten Sie sich auf das Auto vor Ihnen verlassen, um zu wissen, dass Sie bremsen sollten. Aber was wäre, wenn Ihr Fahrzeug um das Auto vor Ihnen herumsehen und noch früher bremsen könnte?
Forscher vom MIT und Meta haben eine Laptop-Imaginative and prescient-Technik entwickelt, die einem autonomen Fahrzeug eines Tages genau dies ermöglichen könnte.
Sie haben eine Methode vorgestellt, die physikalisch genaue 3D-Modelle einer gesamten Szene erstellt, einschließlich der verdeckten Bereiche, und zwar mithilfe von Bildern aus einer einzigen Kameraposition. Ihre Technik verwendet Schatten, um zu bestimmen, was sich in verdeckten Teilen der Szene befindet.
Sie nennen ihren Ansatz PlatoNeRF, basierend auf Platons Höhlengleichnis, einer Passage aus der „Politeia“ des griechischen Philosophen. bei dem in einer Höhle angekettete Gefangene die Realität der Außenwelt anhand der Schatten erkennen, die auf die Höhlenwand geworfen werden.
Durch die Kombination von Lidar-Technologie (Gentle Detection and Ranging) mit maschinellem Lernen kann PlatoNeRF genauere Rekonstruktionen der 3D-Geometrie erstellen als einige vorhandene KI-Techniken. Darüber hinaus ist PlatoNeRF besser in der Lage, Szenen reibungslos zu rekonstruieren, in denen Schatten schwer zu erkennen sind, beispielsweise bei starkem Umgebungslicht oder dunklen Hintergründen.
Neben der Verbesserung der Sicherheit autonomer Fahrzeuge könnte PlatoNeRF auch die Effizienz von AR/VR-Headsets steigern, indem es dem Benutzer ermöglicht, die Geometrie eines Raums zu modellieren, ohne herumlaufen und Messungen durchführen zu müssen. Es könnte auch Lagerrobotern helfen, Artikel in unübersichtlichen Umgebungen schneller zu finden.
„Unsere Kernidee struggle, diese beiden Dinge, die in unterschiedlichen Disziplinen bereits gemacht wurden, zusammenzuführen – Multibounce-Lidar und maschinelles Lernen. Es hat sich herausgestellt, dass man, wenn man diese beiden zusammenbringt, viele neue Möglichkeiten findet, das Beste aus beiden Welten zu erkunden und zu nutzen“, sagt Tzofi Klinghoffer, ein MIT-Absolvent in Medienkunst und -wissenschaften, wissenschaftlicher Mitarbeiter in der Digital camera Tradition Group des MIT Media Lab und Hauptautor eines Papier über PlatoNeRF.
Klinghoffer verfasste das Papier zusammen mit seinem Betreuer Ramesh Raskar, Affiliate Professor für Medienkunst und -wissenschaften und Leiter der Digital camera Tradition Group am MIT; dem leitenden Autor Rakesh Ranjan, einem Leiter der KI-Forschung bei Meta Actuality Labs; sowie Siddharth Somasundaram, einem Forschungsassistenten der Digital camera Tradition Group, und Xiaoyu Xiang, Yuchen Fan und Christian Richardt bei Meta. Die Forschungsarbeit wird auf der Konferenz für Laptop Imaginative and prescient und Mustererkennung vorgestellt.
Licht ins Drawback bringen
Die Rekonstruktion einer vollständigen 3D-Szene aus einem Kamerablickwinkel ist ein komplexes Drawback.
Einige maschinelle Lernverfahren verwenden generative KI-Modelle, die zu erraten versuchen, was sich in den verdeckten Bereichen befindet. Diese Modelle können jedoch Objekte vortäuschen, die in Wirklichkeit gar nicht vorhanden sind. Andere Verfahren versuchen, die Formen verborgener Objekte anhand von Schatten in einem Farbbild abzuleiten. Diese Methoden können jedoch Probleme bereiten, wenn die Schatten schwer zu erkennen sind.
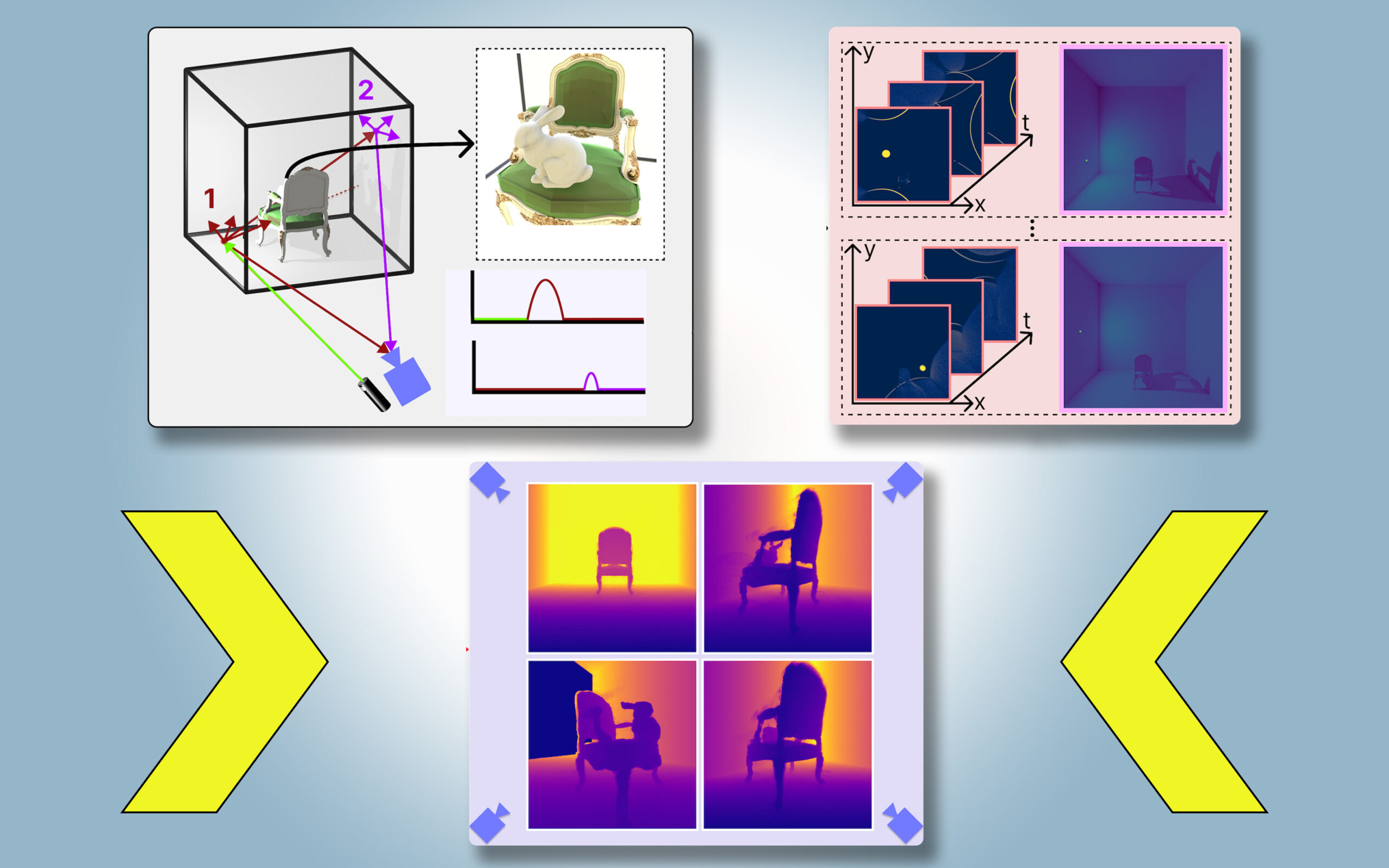
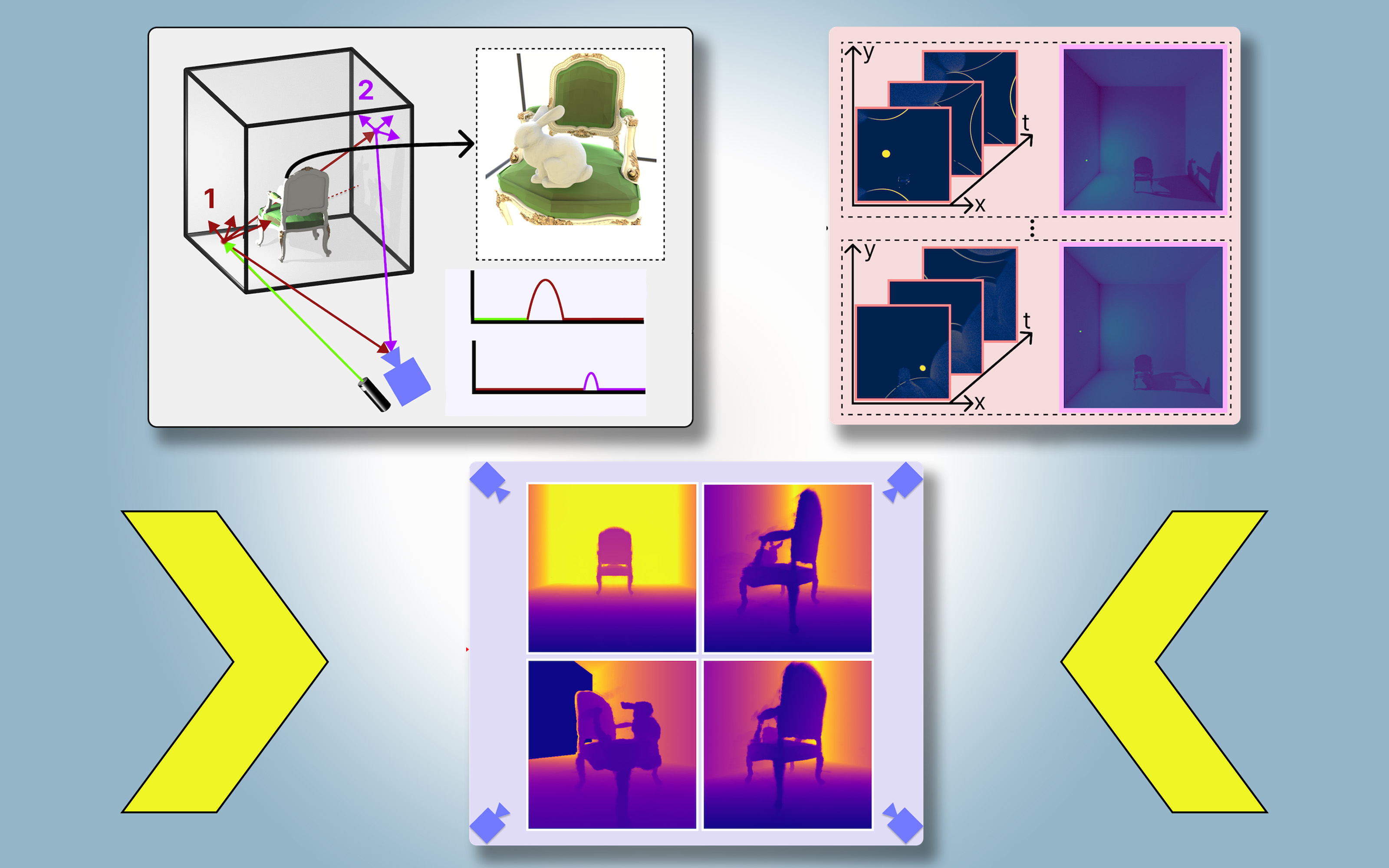
Für PlatoNeRF bauten die MIT-Forscher diese Ansätze aus und verwendeten dabei eine neue Sensormethode namens Single-Photon-Lidar. Lidars kartieren eine 3D-Szene, indem sie Lichtimpulse aussenden und die Zeit messen, die das Licht braucht, um zum Sensor zurückzuprallen. Da Single-Photon-Lidars einzelne Photonen erkennen können, liefern sie Daten mit höherer Auflösung.
Die Forscher verwenden ein Einzelphotonen-Lidar, um einen Zielpunkt in der Szene zu beleuchten. Ein Teil des Lichts wird von diesem Punkt reflektiert und kehrt direkt zum Sensor zurück. Der größte Teil des Lichts wird jedoch gestreut und von anderen Objekten reflektiert, bevor es zum Sensor zurückkehrt. PlatoNeRF basiert auf diesen zweiten Lichtreflexionen.
Indem PlatoNeRF berechnet, wie lange es dauert, bis das Licht zweimal reflektiert wird und dann zum Lidar-Sensor zurückkehrt, erfasst es zusätzliche Informationen über die Szene, einschließlich der Tiefe. Der zweite Lichtreflex enthält außerdem Informationen über Schatten.
Das System verfolgt die sekundären Lichtstrahlen – die vom Zielpunkt zu anderen Punkten in der Szene reflektiert werden – um zu bestimmen, welche Punkte im Schatten liegen (aufgrund fehlenden Lichts). Anhand der Place dieser Schatten kann PlatoNeRF auf die Geometrie verborgener Objekte schließen.
Das Lidar beleuchtet nacheinander 16 Punkte und erfasst mehrere Bilder, die zur Rekonstruktion der gesamten 3D-Szene verwendet werden.
„Jedes Mal, wenn wir einen Punkt in der Szene beleuchten, erzeugen wir neue Schatten. Da wir all diese verschiedenen Beleuchtungsquellen haben, schießen viele Lichtstrahlen umher, sodass wir den Bereich herausarbeiten, der verdeckt ist und außerhalb des sichtbaren Auges liegt“, sagt Klinghoffer.
Eine gewinnbringende Kombination
Der Schlüssel zu PlatoNeRF ist die Kombination von Multibounce-Lidar mit einem speziellen Typ von maschinellem Lernmodell, das als Neural Radiance Subject (NeRF) bezeichnet wird. Ein NeRF kodiert die Geometrie einer Szene in die Gewichte eines neuronalen Netzwerks, was dem Modell eine starke Fähigkeit verleiht, neue Ansichten einer Szene zu interpolieren oder abzuschätzen.
Diese Interpolationsfähigkeit führe in Kombination mit Multibounce-Lidar auch zu hochpräzisen Szenenrekonstruktionen, sagt Klinghoffer.
„Die größte Herausforderung bestand darin, herauszufinden, wie man diese beiden Dinge kombiniert. Wir mussten wirklich über die Physik des Lichttransports mit Multibounce-Lidar nachdenken und darüber, wie man das mit maschinellem Lernen modellieren kann“, sagt er.
Sie verglichen PlatoNeRF mit zwei gängigen Alternativmethoden, von denen eine nur Lidar verwendet, und die andere nur ein NeRF mit einem Farbbild nutzt.
Sie stellten fest, dass ihre Methode beide Techniken übertraf, insbesondere wenn der Lidar-Sensor eine geringere Auflösung hatte. Dies würde ihren Ansatz praktischer für den Einsatz in der realen Welt machen, wo Sensoren mit geringerer Auflösung in kommerziellen Geräten üblich sind.
„Vor etwa 15 Jahren erfand unsere Gruppe die erste Kamera, die um Ecken ‚sehen‘ konnte. Sie funktionierte, indem sie mehrfache Lichtreflexionen oder ‚Lichtechos‘ ausnutzte. Diese Techniken verwendeten spezielle Laser und Sensoren und nutzten drei Lichtreflexionen. Seitdem ist die Lidar-Technologie gängiger geworden, was zu unserer Forschung an Kameras führte, die durch Nebel sehen können. Diese neue Arbeit nutzt nur zwei Lichtreflexionen, was bedeutet, dass das Sign-Rausch-Verhältnis sehr hoch ist und die Qualität der 3D-Rekonstruktion beeindruckend ist“, sagt Raskar.
In Zukunft möchten die Forscher mehr als zwei Lichtreflexe verfolgen, um zu sehen, wie sich dadurch die Szenenrekonstruktion verbessern lässt. Darüber hinaus möchten sie weitere Deep-Studying-Techniken anwenden und PlatoNeRF mit Farbbildmessungen kombinieren, um Texturinformationen zu erfassen.
„Kamerabilder von Schatten wurden schon lange als Mittel zur 3D-Rekonstruktion untersucht. Diese Arbeit befasst sich nun erneut mit dem Drawback im Zusammenhang mit Lidar und zeigt, dass die Genauigkeit der rekonstruierten verborgenen Geometrie deutlich verbessert wurde. Die Arbeit zeigt, wie clevere Algorithmen in Kombination mit gewöhnlichen Sensoren außergewöhnliche Fähigkeiten ermöglichen können – einschließlich der Lidar-Systeme, die viele von uns heute in der Tasche tragen“, sagt David Lindell, Assistenzprofessor im Fachbereich Informatik der Universität Toronto, der an dieser Arbeit nicht beteiligt struggle.