Ideale generative KI vs. Realität
Grundlegende LLMs haben jedes Byte Textual content gelesen, das sie finden konnten, und ihre Chatbot-Gegenstücke können zu intelligenten Gesprächen angeregt und gebeten werden, bestimmte Aufgaben auszuführen. Der Zugang zu umfassenden Informationen ist demokratisiert; Sie müssen nicht mehr die richtigen Schlüsselwörter für die Suche herausfinden oder Web sites zum Lesen auswählen. LLMs neigen jedoch dazu, zu schwafeln und reagieren im Allgemeinen mit der statistisch wahrscheinlichsten Antwort, die Sie hören möchten (Speichelleckerei) ein inhärentes Ergebnis des Transformer-Modells. Das Extrahieren von 100 % genauen Informationen aus der Wissensbasis eines LLM führt nicht immer zu vertrauenswürdigen Ergebnissen.
Chat-LLMs sind dafür berüchtigt, Zitate aus wissenschaftlichen Arbeiten oder Gerichtsverfahren zu erfinden, die es gar nicht gibt. Anwälte reichen Klage gegen eine Fluggesellschaft ein enthielt Zitate aus Gerichtsverfahren, die nie stattgefunden haben. Eine Studie aus dem Jahr 2023 berichtetedass ChatGPT, wenn es aufgefordert wird, Zitate einzufügen, nur in 14 % der Fälle Referenzen liefert, die tatsächlich existieren. Quellen zu fälschen, zu schwafeln und Ungenauigkeiten zu liefern, um der Aufforderung nachzukommen, wird als Halluzination bezeichnet, ein riesiges Hindernis, das überwunden werden muss, bevor KI vollständig angenommen und von der Masse als vertrauenswürdig angesehen wird.
Ein Gegenmittel gegen das Erfinden falscher Quellen oder das Auftauchen von Ungenauigkeiten durch LLMs ist die Retrieval-Augmented Technology oder RAG. RAG kann nicht nur die Halluzinationstendenz von LLMs verringern, sondern bietet auch mehrere andere Vorteile.
Zu diesen Vorteilen gehören der Zugriff auf eine aktuelle Wissensbasis, Spezialisierung (z.B durch die Bereitstellung privater Datenquellen), wodurch Modelle mit Informationen ausgestattet werden, die über das hinausgehen, was im parametrischen Speicher abgelegt ist (was kleinere Modelle ermöglicht), und die Möglichkeit besteht, weitere Daten aus legitimen Referenzen heranzuziehen.
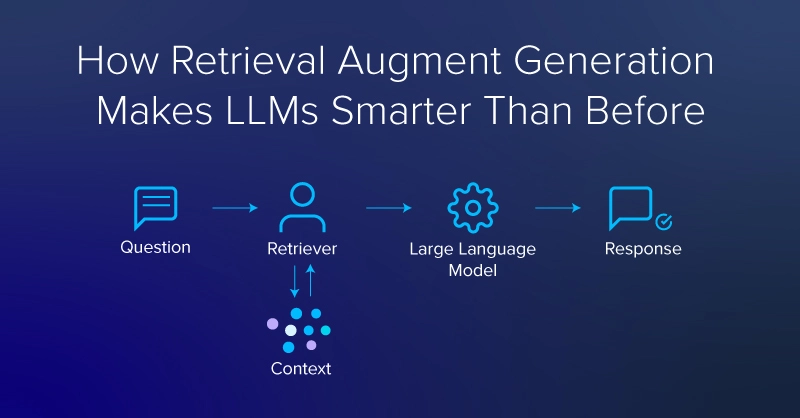
Was ist RAG (Retrieval Augmented Technology)?
Retrieval-Augmented Technology (RAG) ist eine Deep-Studying-Architektur, die in LLMs und Transformer-Netzwerken implementiert ist. Sie ruft relevante Dokumente oder andere Snippets ab und fügt sie dem Kontextfenster hinzu, um zusätzliche Informationen bereitzustellen und einem LLM dabei zu helfen, nützliche Antworten zu generieren. Ein typisches RAG-System hätte zwei Hauptmodule: Abruf und Generierung.
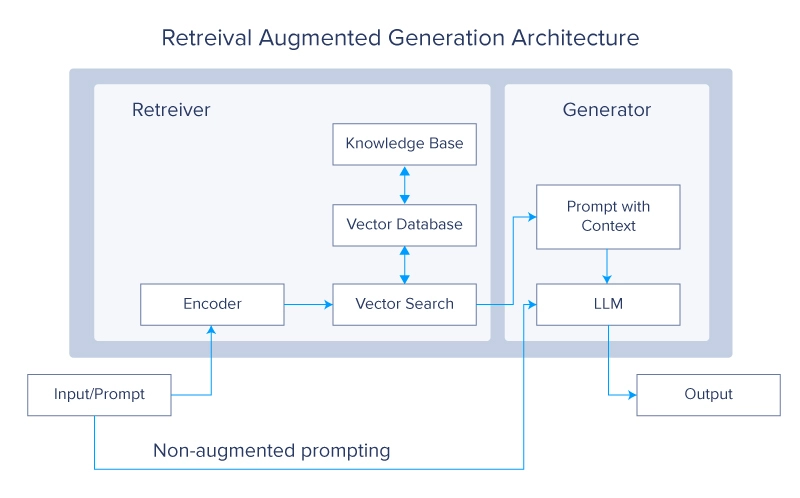
Die wichtigste Referenz für RAG ist ein Artikel von Lewis et al. von Fb. In dem Artikel verwenden die Autoren ein Paar BERT-basierter Dokument-Encoder, um Abfragen und Dokumente zu transformieren, indem sie den Textual content in ein Vektorformat einbetten. Diese Einbettungen werden dann verwendet, um die Prime-okay (normalerweise 5 oder 10) Dokumente über eine Suche mit maximalem inneren Produkt (MIPS). Wie der Identify schon sagt, basiert MIPS auf dem inneren (oder Skalar-)Produkt der codierten Vektordarstellungen der Abfrage und denen in einer Vektordatenbank, die für die Dokumente vorab berechnet wurde und als externer, nichtparametrischer Speicher verwendet wird.
Wie im Stück von Lewis beschrieben et al.RAG wurde entwickelt, um LLMs bei wissensintensiven Aufgaben zu unterstützen, die „von Menschen ohne Zugang zu einer externen Wissensquelle nicht vernünftigerweise ausgeführt werden können“. Wenn Sie eine Open-Ebook- und eine Non-Open-Ebook-Prüfung ablegen, erhalten Sie einen guten Eindruck davon, wie RAG LLM-basierte Systeme ergänzen kann.
RAG mit dem Umarmungsgesicht 🤗 Bibliothek
Lewis et al. haben ihre RAG-Modelle auf dem Hugging Face Hub als Open Supply veröffentlicht, sodass wir mit denselben Modellen experimentieren können, die im Artikel verwendet werden. Eine neue virtuelle Python 3.8-Umgebung mit virtualenv wird empfohlen.
virtualenv my_env --python=python3.8
supply my_env/bin/activateNachdem wir die Umgebung aktiviert haben, können wir mit pip Abhängigkeiten installieren: Transformatoren und Datasets von Hugging Face, die FAISS-Bibliothek von Fb, die RAG für die Vektorsuche verwendet, und PyTorch zur Verwendung als Backend.
pip set up transformers
pip set up datasets
pip set up faiss-cpu==1.8.0
#https://pytorch.org/get-started/regionally/ to
#match the pytorch model to your system
pip set up torchLewis et al. hat zwei verschiedene Versionen von RAG implementiert: rag-sequence und rag-token. Rag-sequence verwendet dasselbe abgerufene Dokument, um die Generierung einer gesamten Sequenz zu erweitern, während rag-token für jedes Token unterschiedliche Snippets verwenden kann. Beide Versionen verwenden dieselben Hugging Face-Klassen für die Tokenisierung und den Abruf, und die API ist weitgehend gleich, aber jede Model hat eine einzigartige Klasse für die Generierung. Diese Klassen werden aus der Transformers-Bibliothek importiert.
from transformers import RagTokenizer, RagRetriever
from transformers import RagTokenForGeneration
from transformers import RagSequenceForGenerationWenn das RagRetriever-Modell mit dem Standarddatensatz „wiki_dpr“ zum ersten Mal instanziiert wird, wird ein umfangreicher Obtain (ca. 300 GB) eingeleitet. Wenn Sie über ein großes Datenlaufwerk verfügen und möchten, dass Hugging Face dieses verwendet (anstelle des Customary-Cache-Ordners auf Ihrem Dwelling-Laufwerk), können Sie eine Shell-Variable festlegen: HF_DATASETS_CACHE.
# within the shell:
export HF_DATASETS_CACHE="/path/to/knowledge/drive"
# ^^ add to your ~/.bashrc file if you wish to set the variableStellen Sie sicher, dass der Code funktioniert, bevor Sie den vollständigen wiki_dpr-Datensatz herunterladen. Um den großen Obtain zu vermeiden, bis Sie bereit sind, können Sie beim Instanziieren des Retrievers use_dummy_dataset=True übergeben. Sie werden auch einen Tokenizer instanziieren, um Zeichenfolgen in ganzzahlige Indizes (entsprechend Token in einem Vokabular) und umgekehrt umzuwandeln. Sequenz- und Tokenversionen von RAG verwenden denselben Tokenizer. RAG-Sequenz (rag-sequence) und RAG-Token (rag-token) haben jeweils fein abgestimmte (z.B rag-token-nq) und Basisversionen (z.B Rag-Token-Foundation).
tokenizer = RagTokenizer.from_pretrained(
"fb/rag-token-nq")
token_retriever = RagRetriever.from_pretrained(
"fb/rag-token-nq",
index_name="compressed",
use_dummy_dataset=False)
sequence_retriever = RagRetriever.from_pretrained(
"fb/rag-sequence-nq",
index_name="compressed",
use_dummy_dataset=False)
dummy_retriever = RagRetriever.from_pretrained(
"fb/rag-sequence-nq",
index_name="precise",
use_dummy_dataset=True)
token_model = RagTokenForGeneration.from_pretrained(
"fb/rag-token-nq",
retriever=token_retriever)
seq_model = RagTokenForGeneration.from_pretrained(
"fb/rag-sequence-nq",
retriever=seq_retriever)
dummy_model = RagTokenForGeneration.from_pretrained(
"fb/rag-sequence-nq",
retriever=dummy_retriever)Sobald Ihre Modelle instanziiert sind, können Sie eine Abfrage bereitstellen, sie tokenisieren und an die Funktion „Generieren“ des Modells übergeben. Wir vergleichen die Ergebnisse von Rag-Sequence, Rag-Token und RAG mithilfe eines Retrievers mit der Dummy-Model des Wiki_Dpr-Datensatzes. Beachten Sie, dass diese Rag-Modelle nicht zwischen Groß- und Kleinschreibung unterscheiden.
question = "what's the identify of the oldest tree on Earth?"
input_dict = tokenizer.prepare_seq2seq_batch(
question, return_tensors="pt")
token_generated = token_model.generate(**input_dict) token_decoded = token_tokenizer.batch_decode(
token_generated, skip_special_tokens=True)
seq_generated = seq_model.generate(**input_dict)
seq_decoded = seq_tokenizer.batch_decode(
seq_generated, skip_special_tokens=True)
dummy_generated = dummy_model.generate(**input_dict)
dummy_decoded = seq_tokenizer.batch_decode(
dummy_generated, skip_special_tokens=True)
print(f"solutions to question '{question}': ")
print(f"t rag-sequence-nq: {seq_decoded(0)},"
f" rag-token-nq: {token_decoded(0)},"
f" rag (dummy): {dummy_decoded(0)}")>> solutions to question 'What's the identify of the oldest tree on Earth?': Prometheus was the oldest tree found till 2012, with its innermost, extant rings exceeding 4862 years of age.
>> rag-sequence-nq: prometheus, rag-token-nq: prometheus, rag (dummy): 4862Im Allgemeinen ist Rag-Token häufiger richtig als Rag-Sequence (obwohl beide oft richtig sind) und Rag-Sequence ist bei Verwendung eines Retrievers mit einem Dummy-Datensatz häufiger richtig als RAG.
„Welche Artwork von Kontext liefert der Retriever?“, fragen Sie sich vielleicht. Um das herauszufinden, können wir den Generierungsprozess dekonstruieren. Mit dem wie oben instanziierten seq_retriever und seq_model fragen wir ab: „Wie heißt der älteste Baum der Erde?“
question = "what's the identify of the oldest tree on Earth?"
inputs = tokenizer(question, return_tensors="pt")
input_ids = inputs("input_ids")
question_hidden_states = seq_model.question_encoder(input_ids)(0)
docs_dict = seq_retriever(input_ids.numpy(),
question_hidden_states.detach().numpy(),
return_tensors="pt")
doc_scores = torch.bmm(
question_hidden_states.unsqueeze(1),
docs_dict("retrieved_doc_embeds")
.float().transpose(1, 2)).squeeze(1)
generated = mannequin.generate(
context_input_ids=docs_dict("context_input_ids"),
context_attention_mask=
docs_dict("context_attention_mask"),
doc_scores=doc_scores)
generated_string = tokenizer.batch_decode(
generated,
skip_special_tokens=True)
contexts = tokenizer.batch_decode(
docs_dict("context_input_ids"),
attention_mask=docs_dict("context_attention_mask"),
skip_special_tokens=True)
best_context = contexts(doc_scores.argmax())Wir können unser Modell so codieren, dass die Variable „bester Kontext“ gedruckt wird, um zu sehen, was erfasst wurde
print(f" based mostly on the retrieved context"
f":nnt {best_context}: n")basierend auf dem abgerufenen Kontext:
Prometheus (tree) / In a clonal organism, nonetheless, the person clonal stems should not practically so previous, and no a part of the organism is especially previous at any given time. Till 2012, Prometheus was thus the oldest "non-clonal" organism but found, with its innermost, extant rings exceeding 4862 years of age. Within the Fifties dendrochronologists had been making lively efforts to search out the oldest residing tree species as a way to use the evaluation of the rings for numerous analysis functions, such because the analysis of former climates, the courting of archaeological ruins, and addressing the essential scientific query of most potential lifespan. Bristlecone pines // what's the identify of the oldest tree on earth?print(f" rag-sequence-nq solutions '{question}'"
f" with '{generated_string(0)}'")Wir können die Antwort auch ausdrucken, indem wir den generated_string Variable. Die Rag-Sequenz-NQ antwortet auf „Wie heißt der älteste Baum der Erde?“ mit „Prometheus“.
Was können Sie mit RAG tun?
In den letzten anderthalb Jahren gab es eine wahre Explosion an LLMs und LLM-Instruments. Das in Lewis verwendete BART-Basismodell et al. betrug nur 400 Millionen Parameter, weit entfernt von der aktuellen Technology von LLMs, die bei „Lite“-Varianten normalerweise im Milliardenparameterbereich beginnen. Außerdem sind viele Modelle, die heute trainiert, zusammengeführt und optimiert werden, multimodal und kombinieren Texteingaben und -ausgaben mit Bildern oder anderen tokenisierten Datenquellen. Die Kombination von RAG mit anderen Instruments kann komplexe Funktionen aufbauen, aber die zugrunde liegenden Modelle sind nicht immun gegen die üblichen LLM-Mängel. Die Probleme der Speichelleckerei, Halluzination und Zuverlässigkeit bei LLMs bleiben alle bestehen und laufen Gefahr, mit der zunehmenden Nutzung von LLMs zuzunehmen.
Die offensichtlichsten Anwendungen für RAG sind Variationen der konversationellen semantischen Suche, aber vielleicht umfassen sie auch die Einbindung multimodaler Eingaben oder die Generierung von Bildern als Teil der Ausgabe. Beispielsweise kann RAG in LLMs mit Fachwissen Softwaredokumentation erstellen, mit der man chatten kann. Oder RAG könnte verwendet werden, um interaktive Notizen in einer Literaturübersicht für ein Forschungsprojekt oder eine Abschlussarbeit zu machen.
Durch die Einbindung der Funktion zum „Denkketten-Argumentieren“ könnten Sie einen eher agentenorientierten Ansatz wählen, um Ihren Modellen die Möglichkeit zu geben, das RAG-System abzufragen und komplexere Frage- und Argumentationsstränge zusammenzustellen.
Es ist auch sehr wichtig, sich bewusst zu machen, dass RAG die üblichen LLM-Fallen (Halluzination, Speichelleckerei usw.) nicht löst und nur als Mittel dient, um Ihr LLM zu lindern oder zu einer nischenspezifischeren Antwort zu führen. Die Endpunkte, die letztendlich wichtig sind, sind spezifisch für Ihren Anwendungsfall, die Informationen, die Sie Ihrem Modell zuführen, und wie das Modell fein abgestimmt wird.
Kevin Vu verwaltet Weblog von Exxact Corp und arbeitet mit vielen seiner talentierten Autoren zusammen, die über verschiedene Aspekte des Deep Studying schreiben.