
Nachdem ich bei zwei verschiedenen Unternehmen mit sehr unterschiedlichen Entwicklungskulturen Produkte für maschinelles Lernen entwickelt habe, bin ich von den folgenden falschen Annahmen ausgegangen:
- Alle anderen Datenorganisationen machen die Dinge ähnlich wie mein Unternehmen, additionally geht es uns intestine.
- Meine Organisation hinkt anderen Organisationen weit hinterher.
- Meine Organisation ist einzigartig fortschrittlich, additionally können wir uns auf unseren Lorbeeren ausruhen.
Um aus der kleinen Blase meiner Existenz herauszukommen, habe ich im Mai 2019 eine Umfrage in einer privaten Slack-Gruppe und auf Twitter gepostet. Die Umfrage sollte mehr über den Produktionslebenszyklus von Machine-Studying-Modellen in anderen Unternehmen erfahren. Wenn Sie die Fragen der Umfrage selbst sehen (und ausfüllen!) möchten, ist sie dwell Hier.
Vielleicht liegt es an der geringen Stichprobengröße der Umfrage (zum Zeitpunkt des Schreibens dieses Artikels 40 Befragte), aber ich freue mich, berichten zu können, dass es überall Datenorganisationen gibt. Die eindeutigste Schlussfolgerung, die ich daraus ziehen kann, ist, dass es im Produktions-ML-Prozess immer Raum für Verbesserungen gibt.
Trotz der geringen Stichprobengröße werde ich auf einige der Ergebnisse eingehen, insbesondere auf diejenigen, die mich überrascht haben. Wenn Sie sich die Rohdaten ansehen möchten, finden Sie die Ergebnisse unter dieses Google Sheet.
Datenbereinigung
Umfragedaten sind in Pandas normalerweise schwer zu manipulieren, und dieses Szenario ist nicht anders. Entschuldigen Sie den langen, ziemlich langweiligen Code unten. Ich werde kurz Folgendes erwähnen:
- bidict: Mit dieser Bibliothek können Sie Eins-zu-eins-Wörterbücher in Python erstellen. Das bedeutet, dass jeder Wert nur zu einem Schlüssel gehört, was es Ihnen ermöglicht, lange Zeichenfolgen zu übersetzen in Schnecken und umgekehrt.
- Pandas Kategorisch: Dies warfare hilfreich für die Zuordnung von Bin-Bereichen in Umfrageantworten (1–4, 5–10, 10–20 usw.) zu geordneten Kategorien, was später eine einfache Sortierung ermöglicht.
%config InlineBackend.figure_format = 'retina'
from altair import datum
from bidict import bidict
import matplotlib.pyplot as plt
from matplotlib.ticker import FuncFormatter
import numpy as np
import pandas as pd
from pandas.api.sorts import CategoricalDtype
import seaborn as sns
plt.ion()
plt.rcParams('axes.labelsize') = 16
plt.rcParams('axes.titlesize') = 18
plt.rcParams('font.dimension') = 16
plt.rcParams('strains.linewidth') = 2.0
plt.rcParams('strains.markersize') = 6
plt.rcParams('legend.fontsize') = 14
df = pd.read_csv("responses_anon.csv")
renames = bidict({
"Does your organization practice and use machine studying fashions?": "train_models",
"What varieties of machine studying issues are labored on at your organization?": "problem_types",
"How do nearly all of fashions get retrained?": "retrain_method",
"How usually do nearly all of fashions get retrained?": "retrain_frequency",
"How do the outputs of the fashions get served? (examine all that apply)": "output_methods",
"Roughly what number of completely different fashions are serving outputs?": "num_models",
"Which classes of efficiency do you observe?": "perf_tracking_cats",
"How is the mannequin efficiency tracked? (examine all that apply)": "perf_tracking_methods",
"How usually do you examine mannequin efficiency?": "perf_checking_frequency",
"How large is your organization?": "company_size",
"How many individuals are coaching and/or deploying ML fashions at your organization?": "num_ml_employees",
"Can I attain out to you for follow-up questions?": "can_i_followup",
"Are you interested by the outcomes of this survey?": "interested_in_results",
"If sure to both of the above, what's your electronic mail tackle?": "electronic mail"
})
df = df.rename(columns=renames)
def split_and_rename(splittable_string, rename_func, delim=";"):
return (
rename_func(break up) for break up
in str(splittable_string).break up(delim)
)
def clean_problem_types(df):
df("problem_types") = (
df("problem_types")
.apply(
lambda x: (
y.change("Suggestion methods", "Suggestion Methods")
for y in x.break up(";")
)
)
)
return df
def clean_output_methods(df):
def renamer(val):
if val.startswith("Outputs are written"):
return "written_to_db"
elif val.startswith("An API computes outputs"):
return "realtime_api"
elif val.startswith("An API serves"):
return "precomputed_api"
else:
return val
df("output_methods") = df("output_methods").apply(split_and_rename, args=(renamer,))
return df
def clean_num_models(df):
model_types = CategoricalDtype(
classes=("1", "2-5", "5-10", "10-20", "20-50", "50+"),
ordered=True
)
df("num_models") = df("num_models").astype(model_types)
return df
def clean_perf_tracking_cats(df):
def renamer(val):
if val.startswith("Coaching"):
return "training_data"
if val.startswith("Offline"):
return "offline_test"
if val.startswith("On-line"):
return "on-line"
if val.startswith("nan"):
return "none"
if val.startswith("Submit"):
return "post-hoc"
else:
elevate ValueError(f"Unknown val: {val}")
df("perf_tracking_cats") = df("perf_tracking_cats").apply(split_and_rename, args=(renamer,))
return df
def clean_perf_tracking_methods(df):
def renamer(val):
if val.startswith("Handbook"):
return "handbook"
if val.startswith("Automated"):
return "automated_sql_or_script"
if val.startswith("Customized"):
return "custom_system"
if val.startswith("Third"):
return "third_party"
if val.startswith("Utility"):
return "logs"
if val.startswith("Buying and selling"):
return "aux_metric"
else:
elevate ValueError(f"Unknown val: {val}")
df("perf_tracking_methods") = (
df("perf_tracking_methods")
.apply(lambda x: (renamer(val) for val in str(x).break up(";")))
)
return df
def clean_perf_checking_frequency(df):
df("perf_checking_frequency") = df("perf_checking_frequency").apply(
lambda x: str(x).break up(";")
)
return df
def clean_company_size(df):
company_size_types = CategoricalDtype(
classes=("1-10", "11-50", "51-150", "151-500", "500+"),
ordered=True
)
df("company_size") = df("company_size").astype(company_size_types)
return df
def clean_num_ml_employees(df):
ml_types = CategoricalDtype(
classes=("1-4", "5-10", "11-24", "25-49", "50-100", "100+"),
ordered=True
)
df("num_ml_employees") = df("num_ml_employees").astype(ml_types)
return df
def clear(df):
df = clean_problem_types(df)
df = clean_output_methods(df)
df = clean_num_models(df)
df = clean_perf_tracking_cats(df)
df = clean_perf_tracking_methods(df)
df = clean_perf_checking_frequency(df)
df = clean_company_size(df)
df = clean_num_ml_employees(df)
return df
Kontext des Befragten
Bevor wir uns die Fragen der Umfrage zum maschinellen Lernen ansehen, werfen wir einen Blick auf die demografischen Daten der Umfrageteilnehmer. Wir können feststellen, dass die Mehrheit der Befragten aus größeren Unternehmen stammt.
(Anmerkung des Autors: Dass ich nur bei Startups gearbeitet habe, erkennen Sie an den niedrigen Unternehmensgrößenklassen, die ich in der Umfrage angegeben habe. Hurra, Umfrageverzerrung.)
ax = (
df
.groupby("company_size")
.dimension()
.sort_index(ascending=False)
.plot
.barh()
);
ax.set_xlabel("Variety of Respondents");
ax.set_ylabel("");
ax.set_title(f"Q: {renames.inverse('company_size')}");

Andererseits gibt es in diesen Unternehmen tendenziell weniger Datenexperten, die ML-Modelle einsetzen.
ax = (
df
.groupby("num_ml_employees")
.dimension()
.sort_index(ascending=False)
.plot
.barh()
);
ax.set_xlabel("Variety of Respondents");
ax.set_ylabel("");
title = renames.inverse('num_ml_employees')
title = "and/orn ".be a part of(title.break up("and/or"))
ax.set_title(f"Q: {title}");
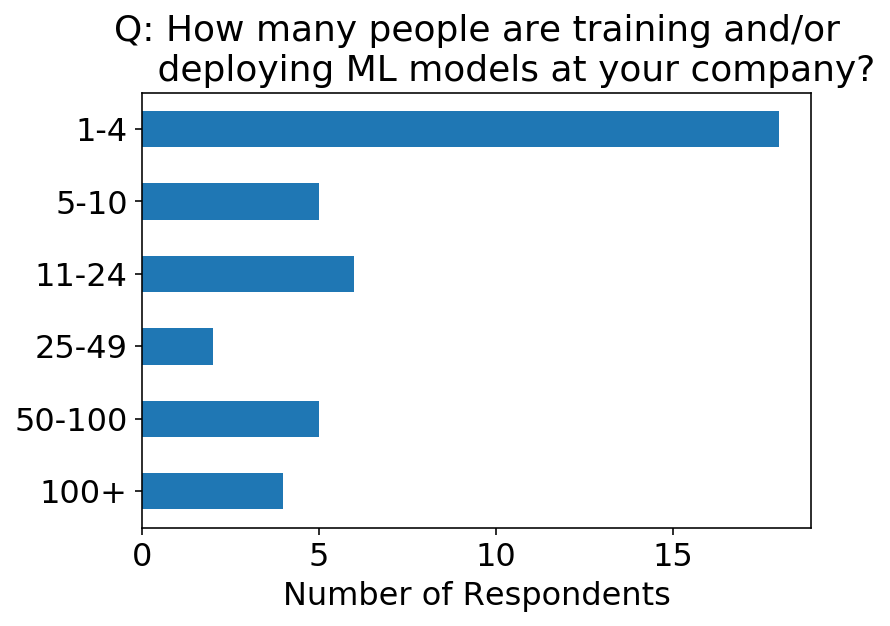
Wir können uns eine Heatmap der beiden obigen Fragen ansehen. Zur Plausibilitätsprüfung ist es intestine zu sehen, dass es keine Befragten gibt, die sagen, dass es mehr ML-Mitarbeiter als Unternehmensmitarbeiter gibt. Ich warfare auch beeindruckt zu sehen, dass es 4 Orte mit über 100 Mitarbeitern gibt, die ML-Modelle einsetzen!
sns.heatmap(
df
.groupby(("company_size", "num_ml_employees"))
.dimension()
.unstack(degree=1),
annot=True
);
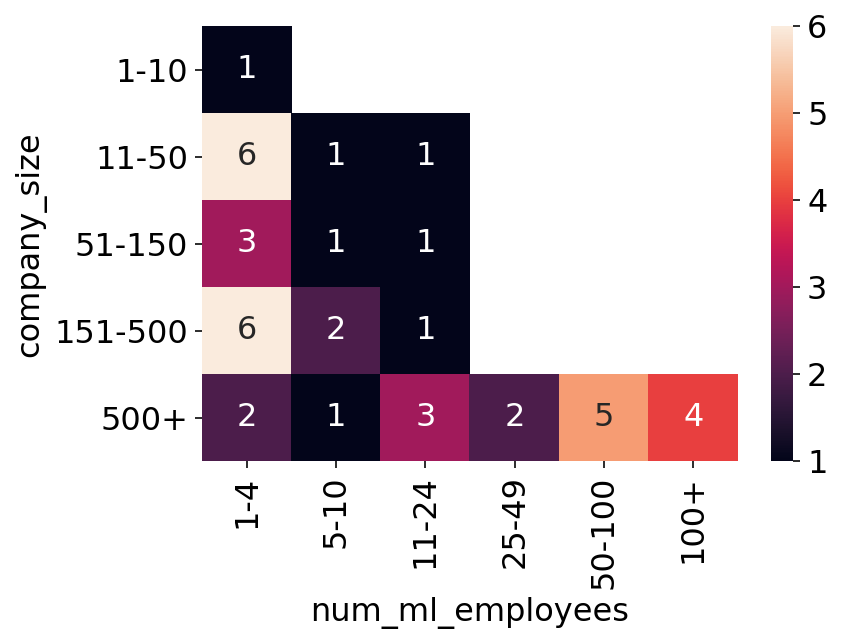
In der Umfrage wurde auch gefragt: „Wie viele verschiedene Modelle liefern ungefähr Ergebnisse?“ Unten sehen wir die Heatmap dieser Frage auf der Y-Achse im Vergleich zur Anzahl der ML-Mitarbeiter auf der X-Achse. Dies gibt uns eine gewisse Vorstellung davon, wie viele Personen professional Modell es im Unternehmen gibt.
sns.heatmap(
df
.groupby(("num_models", "num_ml_employees"))
.dimension()
.unstack(degree=1),
annot=True
);

Modelltraining
Als ich meinen letzten Job antrat, erbte ich ein ML-System, bei dem ein Modell lokal trainiert werden musste, das eingelegte Modell per SCP auf eine EC2-Instanz hochgeladen und die API auf dieser Instanz neu gestartet werden musste, damit sie das neue Modell aufnahm. Einerseits warfare das bei einem Produktionsdienst ziemlich furchterregend, und ich habe den Prozess definitiv mehr als einmal vermasselt. Andererseits führten wir ein Experiment durch, um zu sehen, ob das Modell es überhaupt wert warfare, additionally könnte man das vielleicht als unsere Einhaltung des Grundsatzes betrachten, keine vorzeitige Optimierung vorzunehmen. Trotzdem gewann das Modell das Experiment, und wir richteten schließlich eine automatische Batch-Neuschulung des Modells ein.
Ich schätze, ich habe einfach angenommen, dass andere Leute das auch getan haben, weil ich es schließlich eingerichtet habe. Den Antworten auf die Fragen unten zufolge scheint das nicht der Fall zu sein. Es könnte jedoch viele Erklärungen geben. Es ist verdammt viel Arbeit, um an den Punkt zu gelangen, an dem beliebig ein anderes System oder eine andere Particular person nutzt die Ergebnisse Ihres Modells. Es ist noch mehr Arbeit, den Produktionsworkflow zu automatisieren. Die Organisationen einiger Befragten sind möglicherweise jung. Andererseits müssen einige Modelle selten neu trainiert werden (z. B. word2vec von Grund auf).
ax = df.retrain_method.value_counts(normalize=True).plot.barh();
ax.set_title(renames.inverse("retrain_method"));
ax.set_ylabel("Retrain Methodology");
ax.set_xlabel("% of Respondents");
ax.xaxis.set_major_formatter(FuncFormatter('{0:.0%}'.format))

Die nächste Frage betrifft, wie oft die Modelle neu trainiert werden. Wir sehen hier, dass die beliebteste Antwort „Zufällig“ ist, gefolgt von „Monatlich“, was wahrscheinlich nicht überraschend ist, da viele Modelle manuell neu trainiert werden. Eine Sache, die ich hervorheben sollte, ist, dass verschiedene Modelltypen unterschiedliche Trainingshäufigkeiten erfordern. Die Leistung von Empfehlungssystemen verbessert sich erheblich mit beliebig Daten über einen Benutzer (das sogenannte „Kaltstart“-Downside). Daher sollte man sie so oft wie möglich mit den neuesten Daten neu trainieren. Eine logistische Regression mit wenigen Merkmalen profitiert möglicherweise nicht sehr von einem erneuten Coaching, da die Komplexität des Modells bereits mit kleineren Daten gesättigt ist.
In meinem letzten Unternehmen strebten wir eine tägliche Neuschulung der Modelle an, einfach weil wir das konnten (die Daten waren klein) und wir auf diese Weise Fehler in den Daten schneller erkennen konnten.
ax = df.retrain_frequency.value_counts(normalize=True).plot.barh();
ax.set_title(renames.inverse("retrain_frequency"));
ax.set_ylabel("Retrain Frequency");
ax.set_xlabel("% of Respondents");
ax.xaxis.set_major_formatter(FuncFormatter('{0:.0%}'.format))

Wir können die beiden obigen Fragen aufteilen und die Umschulungshäufigkeit für Modelle betrachten, die automatisch im Vergleich zu manuell umgeschult werden. Wie erwartet werden die meisten manuell umgeschulten Modelle mit zufälliger Häufigkeit umgeschult, während automatisch umgeschulte Modelle eine festgelegte Häufigkeit haben.
fig, axs = plt.subplots(2, 1, figsize=(6, 8));
axs = axs.flatten();
df.question("retrain_method == 'Mechanically (e.g. a batch job)'").groupby("retrain_frequency").dimension().plot.barh(ax=axs(0));
df.question("retrain_method == 'Manually'").groupby("retrain_frequency").dimension().plot.barh(ax=axs(1));
axs(0).set_title("Computerized Retraining");
axs(1).set_title("Handbook Retraining");
axs(1).set_xlabel("Variety of Respondents");
# Set similar x-scale for each axes
xlims = checklist(zip(*(ax.get_xlim() for ax in axs)))
xlim = min(xlims(0)), max(xlims(1))
axs(0).set_xlim(xlim);
axs(1).set_xlim(xlim);
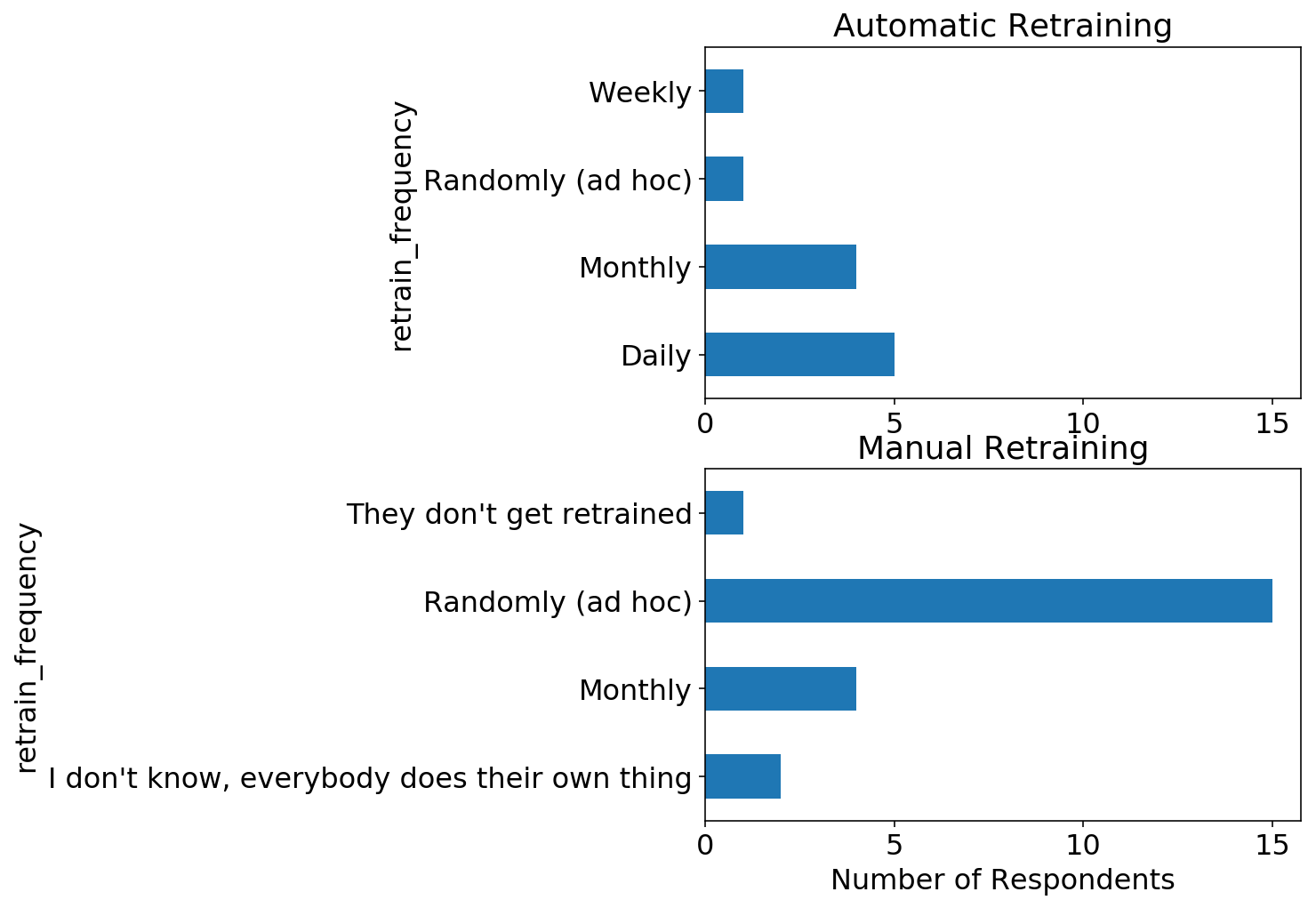
Modellbereitstellung und -überwachung
Damit ich im vorherigen Abschnitt nicht boastful klinge, als ich über das zufällige, manuelle Umlernen der Leute sprach, warfare ich complete beeindruckt von der Raffinesse der Modellbereitstellungs- und Überwachungs-Setups der Befragten. Die erste Frage, die ich zur Modellbereitstellung stellte, warfare
Wie werden die Ausgaben der Modelle bereitgestellt? (alle zutreffenden Antworten ankreuzen)
mit folgenden Optionen:
- Die Ausgaben werden in eine Datenbank geschrieben und von einem anderen System verwendet.
- Eine API liefert vorkalkulierte Ausgaben
- Eine API berechnet Ergebnisse in Echtzeit
Betrachtet man das Diagramm unten, ist es beeindruckend zu sehen, dass 60 % der Unternehmen der Befragten Modelle als Echtzeit-APIs einsetzen. Dies ist ziemlich schwierig, da das Modell wahrscheinlich typische technische SLAs wie geringe Latenz und Verfügbarkeit erfüllen muss.
total_respondents = len(df)
ax = (
df
.explode("output_methods")
.question("output_methods in ('precomputed_api', 'realtime_api', 'written_to_db')")
("output_methods")
.value_counts() / total_respondents
).plot.barh();
ax.xaxis.set_major_formatter(FuncFormatter('{0:.0%}'.format));
ax.set_title("fashionsn ".be a part of(renames.inverse("output_methods").break up("fashions")));
ax.set_xlabel("Proportion of Respondents");

Ich habe auch nach den überwachten Kennzahlen und der Artwork und Weise gefragt, wie sie überwacht werden:
Q: Welche Leistungskategorien verfolgen Sie?
A:
- Trainingsdatenmetriken (z. B. die AUC eines Klassifikators auf den Trainingsdaten)
- Offline-Testdatenmetriken (z. B. die AUC eines Klassifikators für zurückgehaltene Testdaten)
- On-line-Metriken (z. B. Vergleichen von Vorhersagen zum Zeitpunkt der Modellbereitstellung mit Ergebnissen)
Q: Wie wird die Leistung des Modells verfolgt? (alle zutreffenden Optionen ankreuzen)
A:
- Manuelle SQL-Abfragen/Skripte
- Automatisierte SQL-Abfragen/Skripte
- Maßgeschneidertes Überwachungssystem
- Drittanbietersystem
Auch hier bin ich von der Komplexität beeindruckt. On-line-Kennzahlen müssen unbedingt verfolgt werden, sobald ein Modell in Produktion ist, aber sie sind auch die am schwierigsten zu verfolgenden Kennzahlen. Dennoch verfolgen >60 % der Befragten diese Daten.
total_respondents = len(df)
ax = (
df
.explode("perf_tracking_cats")
.question("perf_tracking_cats in ('training_data', 'offline_test', 'on-line')")
("perf_tracking_cats")
.value_counts() / total_respondents
).plot.barh();
ax.xaxis.set_major_formatter(FuncFormatter('{0:.0%}'.format));
ax.set_title(renames.inverse("perf_tracking_cats"));
ax.set_xlabel("Proportion of Respondents");

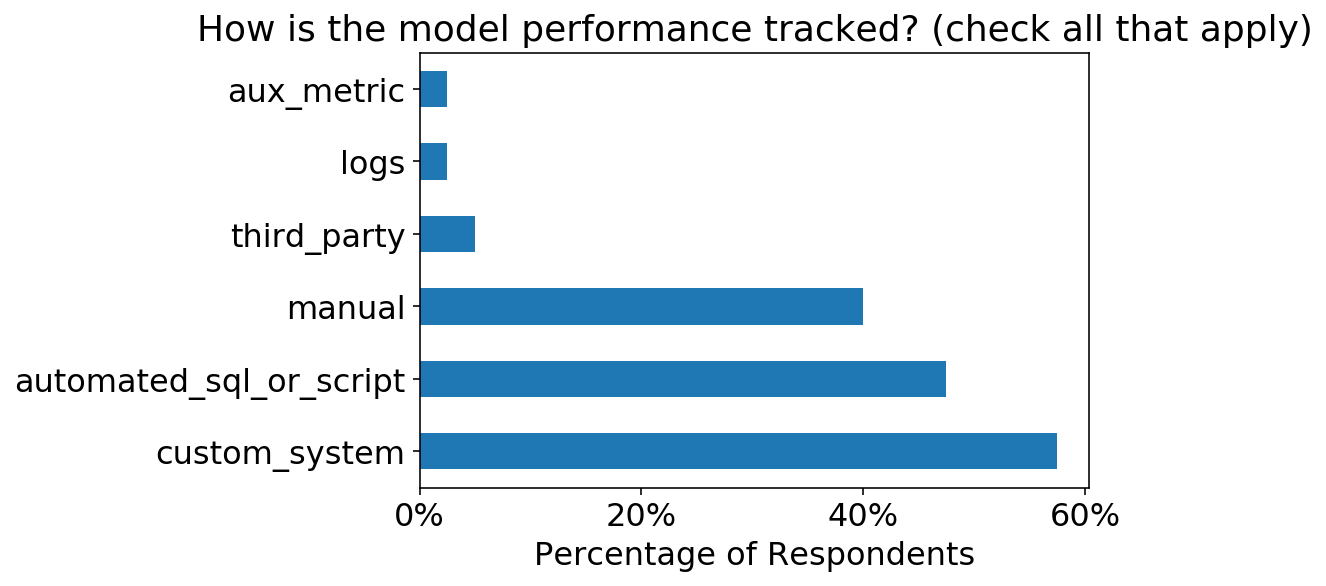
Außerdem ist es cool zu sehen, dass >50 % der Befragten entweder automatisierte Skripte oder benutzerdefinierte Überwachungssysteme eingerichtet haben.
total_respondents = len(df)
ax = (
df("perf_tracking_methods")
.explode()
.value_counts() / total_respondents
).plot.barh();
ax.xaxis.set_major_formatter(FuncFormatter('{0:.0%}'.format));
ax.set_title(renames.inverse("perf_tracking_methods"));
ax.set_xlabel("Proportion of Respondents");
Ich habe auch gefragt, wie oft die Modellleistung verfolgt wird. Wir können sehen, dass die beliebteste Frequenz wöchentlich ist, was der typische Rhythmus ist, in dem ich in der Vergangenheit die automatische Verfolgung für diese Dinge eingerichtet habe. Ob ich tatsächlich sehen bei den Kennzahlen ist jede Woche eine andere Geschichte…
total_respondents = len(df)
opts = (
"Every day",
"Weekly",
"Month-to-month",
"Not often",
"I do not examine the efficiency"
)
ax = (
df
.explode("perf_checking_frequency")
.question("perf_checking_frequency in @opts")
("perf_checking_frequency")
.value_counts() / total_respondents
).loc(opts).plot.barh();
ax.xaxis.set_major_formatter(FuncFormatter('{0:.0%}'.format));
ax.set_title(renames.inverse("perf_checking_frequency"));
ax.set_xlabel("Proportion of Respondents");
