In meinem letzter Beitraghabe ich dringend empfohlen, Machine Studying (ML)-Modelle mit Streaming-Datenbanken zu überwachen. In diesem Beitrag werde ich ein Beispiel dafür demonstrieren, wie dies mit Materialisieren. Wenn Sie direkt zum Code springen möchten, habe ich alles in diesem Beitrag in AIspyein Repo auf GitHub.
DTCallstudie
Nehmen wir an, wir sind ein Machine-Studying-Praktiker, der für Down To Clown arbeitet, ein Direct-to-Shopper-Unternehmen (DTC), das Clownbedarf verkauft. Ein neuer Benutzer, der auf unserer Web site landet, wird als führenWenn dieser Benutzer sein erstes Produkt kauft, sagen wir, er umgewandelt.
Wir haben ein Konvertierungswahrscheinlichkeitsmodell erstellt, um die Wahrscheinlichkeit vorherzusagen, dass ein lead wird konvertieren. Wir modellieren dies als binäres Klassifizierungsproblem und das Ergebnis, das wir vorhersagen, ist, ob der Lead konvertiert wird oder nicht.
Wenn die Konvertierungswahrscheinlichkeit unter einem bestimmten Schwellenwert liegt, bieten wir die lead A coupon um sie zur Konvertierung zu bewegen.
Was soll überwacht werden?
Um dieses Modell zu überwachen, möchten wir zumindest die standardmäßigen Leistungsmetriken für überwachtes Lernen wie Genauigkeit, Präzision, Rückruf und F1-Rating verfolgen. In der Praxis sollten wir uns für eine Metrik interessieren, die besser mit dem Geschäftsziel korreliert, das wir optimieren möchten. Einer der großen Vorteile der Entscheidung, Ihr Modell zu überwachen, besteht darin, dass Sie gezwungen sind, tatsächlich über die wichtigen Metriken nachzudenken und darüber, wie Ihr Modell existiert und sein Ökosystem beeinflusst.
Additionally, was genau versuchen wir zu optimieren? Wahrscheinlich hätten wir beim Erstellen des Modells daran denken sollen, aber das passiert selten.
Beginnen wir mit Geld. Geld ist normalerweise eine gute Sache, die man maximieren sollte. In diesem Fall konzentrieren wir uns auf Nettoumsatz Das ist der Gesamtwert des Conversion-Kaufs abzüglich des Coupons. Wie wirkt sich das Modell auf den Nettoumsatz aus? Wie bei den meisten binären Klassifizierungsmodellen kann es hilfreich sein, zu überlegen, was in jedem Factor des Verwirrung Matrix.
- Wahres Positiv
- Das Modell sagt voraus, dass der Lead konvertiert.
- Es wird daher kein Coupon angeboten.
- Der Benutzer konvertiert.
- Der Nettoumsatz ist der gesamte Konvertierungsbetrag.
- Wahres Negativ:
- Das Modell geht davon aus, dass der Lead nicht konvertiert.
- Es wird ein Coupon angeboten.
- Der Lead konvertiert nicht.
- Der Nettoumsatz beträgt Null.
- Falsch-Positiv:
- Das Modell sagt voraus, dass der Lead konvertiert.
- Es wird daher kein Coupon angeboten.
- Der Lead konvertiert nicht.
- Der Nettoumsatz beträgt Null.
- Falsch negativ:
- Das Modell sagt voraus, dass der Lead nicht konvertiert.
- Es wird ein Coupon angeboten.
- Der Lead konvertiert.
- Der Nettoumsatz ist der gesamte Umrechnungsbetrag abzüglich des Couponbetrags.
Wenn Sie die Szenarien auf diese Weise darstellen, erkennen Sie, dass es eine seltsame Beziehung zwischen „Normal“-Klassifizierungsmetriken und dem Nettoumsatz gibt. Wenn wir den Nettoumsatz maximieren möchten, müssen wir eigentlich die Anzahl der True Positives und False Positives maximieren. Wenn wir jedoch ausschließlich False Positives maximieren würden, indem wir jedem einen Coupon anbieten, hätten wir tatsächlich weniger Der Nettoumsatz stieg, als wenn wir überhaupt kein Modell und keinen Coupon gehabt hätten, abhängig von der Größe der Coupons.
Wer hätte gedacht, dass Coupons so kompliziert sein können? Lassen wir die kausale Inferenz von Coupons aus und führen stattdessen einfach ein Experiment durch. Einem kleinen Prozentsatz von Benutzern werden wir absichtlich keinen Coupon anbieten. Dies wird unsere Kontrollgruppe sein. Wir können dann den Nettoumsatz professional Benutzer zwischen der Kontrollgruppe und der Gruppe, die Coupons erhalten kann, sowie standardmäßige überwachte ML-Metriken vergleichen.
Nachdem wir nun unser gefälschtes DTC-Unternehmen eingerichtet haben, erstellen wir eine Simulation. Ein plausibles „Daten produzierendes“ Szenario könnte sein:
- Ich habe einen Backend-Dienst, der Leads, Conversions und Coupondaten in eine relationale Datenbank schreibt.
- Conversion-Vorhersagen werden gesendet als Veranstaltungen vom Entrance-Finish an ein System, das sie zur weiteren Verarbeitung in eine Warteschlange einfügt, beispielsweise Kafka.
In diesem Szenario erstellen wir zunächst zwei Postgres-Tabellen zur Speicherung leads Und coupons.
CREATE TABLE leads (
id SERIAL PRIMARY KEY,
e-mail TEXT NOT NULL,
created_at TIMESTAMP NOT NULL DEFAULT NOW(),
converted_at TIMESTAMP,
conversion_amount INT
);
CREATE TABLE coupons (
id SERIAL PRIMARY KEY,
created_at TIMESTAMP NOT NULL DEFAULT NOW(),
lead_id INT NOT NULL,
-- quantity is in cents.
quantity INT NOT NULL
);
Wenn Benutzer auf unsere Web site gelangen, erstellen wir eine neue lead mit null converted_at Und conversion_amount Felder. Wenn Leads später konvertiert werden, aktualisieren wir diese Felder.
Für Vorhersagen senden wir diese direkt an eine RedPanda*-Warteschlange als JSON-Ereignisse in einem Format wie:
{
"lead_id": 123,
"experiment_bucket": "experiment",
"rating": 0.7,
"label": true,
"predicted_at": "2022-06-09T02:25:09.139888+00:00"
}
*Ich verwende eine RedPanda-Warteschlange statt einer Kafka-Warteschlange, da diese lokal einfacher einzurichten ist. Übrigens ist die API dieselbe.
Was jetzt noch übrig bleibt, ist, all dies tatsächlich zu simulieren. Ich habe ein Python-Skript um genau das zu tun, komplett mit verzögerten Konvertierungen und allem. Damit man nicht tagelang auf die Kennzahlen warten muss, gehe ich davon aus, dass Konvertierungen innerhalb eines 30-Sekunden-Fensters nach der Lead-Erstellung erfolgen.
Darüber hinaus gehen wir davon aus, dass das Konvertierungsvorhersagemodell eine gute Korrelation mit Konvertierungen aufweist, der Schwellenwert bei 0,5 liegt, sowohl die Konvertierungs- als auch die Couponbeträge zufällige, halbwegs believable Werte sind und das Vorzeigen des Coupons die Konvertierungswahrscheinlichkeit erhöht.
Was ist mit Materialize?
Was ist mit Materialize? Was ist überhaupt Materialize?
Denken wir noch einmal darüber nach, was wir berechnen möchten: den Nettoumsatz sowohl für die Kontrollgruppe als auch für die „experimentelle“ Gruppe, die für Coupons in Frage kommt, sowie die standardmäßigen überwachten ML-Kennzahlen. Wir möchten diese Kennzahlen wahrscheinlich auch in Bezug auf Zeit in gewisser Weise. Modellmetriken sind notwendigerweise Aggregatfunktionen, daher müssen wir normalerweise ein Zeitfenster definieren, über das wir sie berechnen. Vielleicht möchten wir die Genauigkeit des Modells für jede Sekunde für ein nachfolgendes 30-Sekunden-Fenster berechnen.
Okay, wir müssen additionally aggregierte Metriken als Funktion der Zeit berechnen und unsere Daten stammen aus mehreren Quellen (Postgres + RedPanda). Materialize bewältigt beide Anforderungen recht intestine.
In Bezug auf die Datenquellen habe ich strategisch Datenquellen ausgewählt, die sehr intestine mit Materialize zusammenarbeiten. Sehr schön. Sie können direkt replizieren Postgres-Tabellen nach Materialize, und soweit ich das beurteilen kann, funktioniert es einfach. Sie können die Replikation mit einigen SQL-Anweisungen in Materialize einrichten:
CREATE MATERIALIZED SOURCE IF NOT EXISTS pg_source FROM POSTGRES
-- Fill in with your individual connection credentials.
CONNECTION 'host=postgres person=postgres dbname=default'
PUBLICATION 'mz_source'
WITH (timestamp_frequency_ms = 100);
-- From that supply, create views for all tables being replicated.
-- This can embrace the leads and coupons tables.
CREATE VIEWS FROM SOURCE pg_source;
Die Verbindung zur RedPanda-Warteschlange ist auch nicht schlecht. Ich protokolliere Vorhersageereignisse in einem conversion_predictions Thema, sodass Sie oben eine Ansicht erstellen können, um JSON in so etwas wie eine normale, abfragbare SQL-Tabelle zu konvertieren:
-- Create a brand new supply to learn conversion predictions
-- from the conversion_predictions matter on RedPanda.
CREATE SOURCE IF NOT EXISTS kafka_conversion_predictions
FROM KAFKA BROKER 'redpanda:9092' TOPIC 'conversion_predictions'
FORMAT BYTES;
-- Conversion predictions are encoded as JSON and consumed as uncooked bytes.
-- We are able to create a view to decode this right into a nicely typed format, making
-- it simpler to make use of.
CREATE VIEW IF NOT EXISTS conversion_predictions AS
SELECT
CAST(information->>'lead_id' AS BIGINT) AS lead_id
, CAST(information->>'experiment_bucket' AS VARCHAR(255)) AS experiment_bucket
, CAST(information->>'predicted_at' AS TIMESTAMP) AS predicted_at
, CAST(information->>'rating' AS FLOAT) AS rating
, CAST(information->>'label' AS INT) AS label
FROM (
SELECT
CONVERT_FROM(information, 'utf8')::jsonb AS information
FROM kafka_conversion_predictions
);
Übrigens werden Sie feststellen, dass mein Materialize-„Code“ nur SQL ist. Materialize ist eine Datenbank und folgt dem Postgres-SQL-Dialekt mit einigen zusätzlichen „Dingen“.
Das wichtigste zusätzliche „Ding“ ist die materialisierte Ansicht. Eine materialisierte Ansicht ermöglicht es Ihnen, eine SQL-Abfrage zu schreiben, die so etwas wie eine normale Tabelle erstellt (obwohl es eine Ansicht ist), und diese „Tabelle“ bleibt auf dem neuesten Stand, wenn sich die Daten ändern. Immer wenn neue Daten eingehen (z. B. ein Vorhersageereignis in unserer RedPanda-Warteschlange) oder aktuelle Daten aktualisiert werden (z. B. ein Lead konvertiert), werden materialisierte Ansichten, die von Vorhersagen oder Konvertierungen abhängen, automatisch aktualisiert. Das magazine zwar einfach klingen, und es Ist einfach zu bedienen, wodurch sichergestellt wird, dass materialisierte Ansichten verwaltet werden können leistungsfähig und mit geringer Latenz ist keine triviale Angelegenheit; aber Materialize macht genau das.
Sobald meine Datenquellen in Materialize eingebunden sind, kann ich sie abfragen oder materialisierte Ansichten darüber erstellen (und diese Ansichten dann abfragen). Wichtig ist, dass ich Verknüpfungen zwischen verschiedenen Datenquellen schreiben kann. Dies struggle eine der wichtigsten Anforderungen, die ich in meinem letzter Beitragund diese Anforderung wird von vielen modernen Datenbanken nicht ohne Weiteres erfüllt.
Zu Beginn erstelle ich eine nicht materialisiert Ansicht meiner conversion_predictions_dataset. Dies dient als mein kanonischer Datensatz von Vorhersagen, verknüpft mit Ergebnissen. Diese Ansicht ist nicht materialisiert, was bedeutet, dass sie sofort berechnet wird, wenn wir eine Abfrage darauf ausführen, anstatt kontinuierlich aktualisiert und gespeichert zu werden.
-- At every second, calculate the dataset of conversion predictions and outcomes over
-- the trailing 30 seconds.
CREATE VIEW IF NOT EXISTS conversion_prediction_dataset AS
WITH backbone AS (
SELECT
leads.created_at AS timestamp
, leads.id AS lead_id
FROM leads
WHERE
-- The under circumstances outline "hopping home windows" of interval 2 seconds and window measurement
-- 30 seconds. Principally, each 2 seconds, we're taking a look at a trailing 30 second
-- window of knowledge.
-- See https://materialize.com/docs/sql/patterns/temporal-filters/#hopping-windows
-- for more information
mz_logical_timestamp() >= 2000 * (EXTRACT(EPOCH FROM leads.created_at)::bigint * 1000 / 2000)
AND mz_logical_timestamp() < 30000 * (2000 + EXTRACT(EPOCH FROM leads.created_at)::bigint * 1000 / 2000)
)
, predictions AS (
SELECT
backbone.lead_id
, conversion_predictions.experiment_bucket
, conversion_predictions.predicted_at
, conversion_predictions.rating
, conversion_predictions.label::BOOL
FROM backbone
LEFT JOIN conversion_predictions
ON conversion_predictions.lead_id = backbone.lead_id
)
, outcomes AS (
SELECT
backbone.lead_id
, CASE
WHEN
leads.converted_at IS NULL THEN FALSE
WHEN
leads.converted_at <= (leads.created_at + INTERVAL '30 seconds')
THEN TRUE
ELSE FALSE
END AS worth
, CASE
WHEN
leads.converted_at IS NULL THEN NULL
WHEN
-- Ensure to solely use conversion information that was identified
-- _as of_ the lead created at second.
leads.converted_at <= (leads.created_at + INTERVAL '30 seconds')
THEN leads.converted_at
ELSE NULL
END AS lead_converted_at
, CASE
WHEN
leads.converted_at IS NULL THEN NULL
WHEN
leads.converted_at <= (leads.created_at + INTERVAL '30 seconds')
THEN leads.conversion_amount
ELSE NULL
END AS conversion_amount
, coupons.quantity AS coupon_amount
FROM backbone
LEFT JOIN leads ON leads.id = backbone.lead_id
LEFT JOIN coupons ON coupons.lead_id = backbone.lead_id
)
SELECT
date_trunc('second', backbone.timestamp) AS timestamp_second
, backbone.lead_id
, predictions.experiment_bucket
, predictions.rating AS predicted_score
, predictions.label AS predicted_value
, outcomes.worth AS outcome_value
, outcomes.conversion_amount
, outcomes.coupon_amount
FROM backbone
LEFT JOIN predictions ON predictions.lead_id = backbone.lead_id
LEFT JOIN outcomes ON outcomes.lead_id = backbone.lead_id
Schließlich kommen wir zum materialisiert Ansicht. Dazu verwende ich die oben genannte Ansicht, um Modellmetriken jede Sekunde für ein nachfolgendes 30-Sekunden-Fenster zu berechnen.
-- At every second, calculate the efficiency metrics of the
-- conversion prediction mannequin over the trailing 30 seconds.
CREATE MATERIALIZED VIEW IF NOT EXISTS classifier_metrics AS
WITH aggregates AS (
-- Calculate numerous efficiency metrics aggregations.
SELECT
timestamp_second
, experiment_bucket
, COUNT(DISTINCT lead_id) AS num_leads
, SUM((predicted_value AND outcome_value)::INT)
AS true_positives
, SUM((predicted_value AND not outcome_value)::INT)
AS false_positives
, SUM((NOT predicted_value AND not outcome_value)::INT)
AS true_negatives
, SUM((NOT predicted_value AND not outcome_value)::INT)
AS false_negatives
, SUM(conversion_amount)::FLOAT / 100 AS conversion_revenue_dollars
, (SUM(conversion_amount) - SUM(COALESCE(coupon_amount, 0)))::FLOAT / 100
AS net_conversion_revenue_dollars
FROM conversion_prediction_dataset
GROUP BY 1, 2
)
-- Ultimate metrics
SELECT
timestamp_second
, experiment_bucket
, num_leads
, true_positives
, false_positives
, true_negatives
, false_negatives
, conversion_revenue_dollars
, net_conversion_revenue_dollars
, true_positives::FLOAT
/ NULLIF(true_positives + false_positives, 0)
AS precision
, true_positives::FLOAT
/ NULLIF(true_positives + false_negatives, 0)
AS recall
, true_positives::FLOAT
/ NULLIF(
true_positives
+ 1.0 / 2.0 * (false_positives + false_negatives)
, 0
)
AS f1_score
FROM aggregates
Visualisieren
Meine Simulation erstellt additionally Daten sowohl in Postgres als auch in RedPandas, ich habe diese Datenquellen in Materialize eingebunden und aktualisiere nun kontinuierlich eine materialisierte Ansicht aggregierter Leistungsmetriken. Was mache ich mit dieser materialisierten Ansicht? Wie wäre es mit einem Dashboard?
Beim Durchlesen der Materialize Demos auf GitHub (auf das ich mich sehr großzügig verlassen habe, um meine eigene Demo für diesen Beitrag zu erstellen) habe ich gesehen, dass es eine Reihe von Beispielen gibt, die materialisierte Ansichten visualisieren mit Metabase. Metabase ist So’ne Artwork wie ein Open-Supply-Looker. Für unsere Zwecke können wir Metabase verwenden, um ein Diagramm der Felder unserer materialisierten Ansicht als Funktion der Zeit zu erstellen, und wir können das Diagramm sogar so einrichten, dass es jede Sekunde aktualisiert wird.
Das Schöne an der Verwendung eines sehr konventionellen Datenbank-basierten Techniques wie Materialize ist, dass wir das gesamte Ökosystem an Instruments nutzen können, die rund um Datenbanken entwickelt wurden.
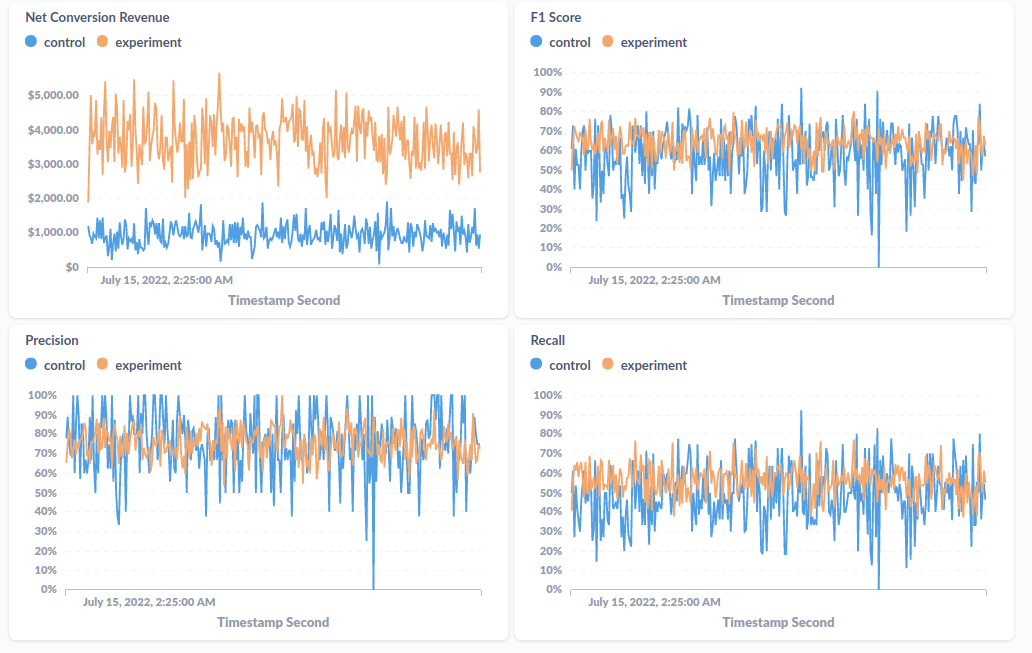
Ich werde Sie nicht mit Einzelheiten zur Einrichtung des Metabase-Dashboards langweilen, aber ich werde Ihnen für die Nachwelt einen Screenshot davon zeigen, wie dieses Dashboard aussieht:
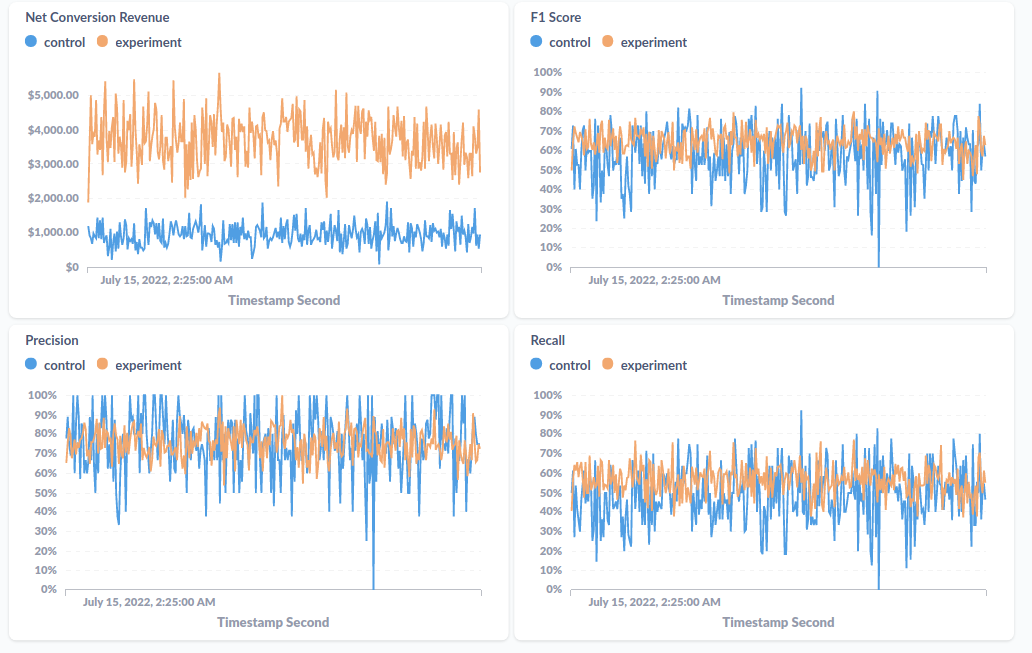
Was als nächstes?
Es wäre cool, ein leichtes Framework darum herum zu bauen. So etwas wie:
Sie verbinden Ihre Daten mit Materialize und bringen sie in eine einzige Ansicht, ähnlich wie meine conversion_predictions_dataset Ansicht oben. Wenn Sie das tun, erstellt das Framework schöne materialisierte Ansichten für standardmäßige überwachte ML-Metriken, benutzerdefinierte Metriken usw. sowie Unterstützung für das Aufteilen und Zerteilen von Metriken in alle von Ihnen eingeschlossenen Dimensionen.
Damit könnte man zumindest anfangen. Man hofft, dass es schnell einsatzbereit ist, aber je mehr man investiert, desto mehr bekommt man auch heraus. Senden Sie Ihre Modellnamen und -versionen mit den Vorhersagen, und diese werden zu natürlichen Dimensionen. Fügen Sie Unterstützung für Experimente und Plugins für Bibliotheken von Drittanbietern hinzu. Wer weiß, vielleicht fügen Sie sogar einen Characteristic Retailer hinzu.
…
Ich möchte mich bedanken Tatsächlich hat niemand diesen Blogbeitrag gelesen, bevor er veröffentlicht wurde, deshalb möchte ich mich bei niemandem bedanken. Die ganze Schuld trage ich selbst.