Als Pc Imaginative and prescient-Forscher glauben wir, dass jedes Pixel eine Geschichte erzählen kann. Allerdings scheint es in diesem Bereich eine Schreibblockade zu geben, wenn es um die Verarbeitung großer Bilder geht. Große Bilder sind keine Seltenheit mehr – die Kameras, die wir in unseren Taschen tragen, und die, die unseren Planeten umkreisen, machen so große und detailreiche Bilder, dass sie unsere derzeit besten Modelle und {Hardware} bei der Verarbeitung bis an ihre Grenzen bringen. Im Allgemeinen erleben wir einen quadratischen Anstieg des Speicherverbrauchs als Funktion der Bildgröße.
Beim Umgang mit großen Bildern treffen wir heute eine von zwei suboptimalen Entscheidungen: Downsampling oder Zuschneiden. Diese beiden Methoden führen zu erheblichen Informations- und Kontextverlusten in einem Bild. Wir werfen einen weiteren Blick auf diese Ansätze und stellen $x$T vor, ein neues Framework zur Finish-to-Finish-Modellierung großer Bilder auf modernen GPUs, bei dem globaler Kontext effektiv mit lokalen Particulars aggregiert wird.

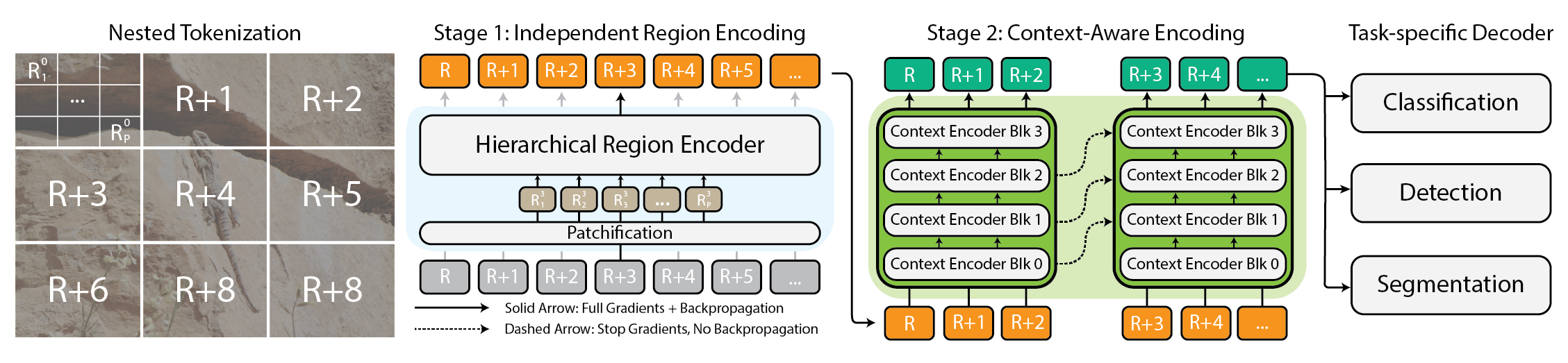
Architektur für das $x$T-Framework.
Warum sich überhaupt mit großen Bildern herumschlagen?
Warum sollte man sich überhaupt mit großen Bildern herumschlagen? Stellen Sie sich vor, Sie sitzen vor dem Fernseher und schauen Ihrem Lieblingsfußballteam zu. Das Spielfeld ist übersät mit Spielern und die Motion findet immer nur auf einem kleinen Teil des Bildschirms statt. Wären Sie jedoch zufrieden, wenn Sie nur einen kleinen Bereich um den Ball herum sehen könnten? Oder wären Sie zufrieden, wenn Sie das Spiel in niedriger Auflösung ansehen könnten? Jeder Pixel erzählt eine Geschichte, egal, wie weit sie voneinander entfernt sind. Dies gilt für alle Bereiche, vom Fernsehbildschirm bis zum Pathologen, der ein Gigapixel-Objektträger betrachtet, um winzige Krebsherde zu diagnostizieren. Diese Bilder sind wahre Schatzkammern an Informationen. Wenn wir diese Fülle nicht vollständig erkunden können, weil unsere Werkzeuge die Karte nicht verarbeiten können, welchen Sinn hat das dann?

Sport macht Spaß, wenn man weiß, was los ist.
Genau darin besteht heute die Frustration. Je größer das Bild, desto mehr müssen wir gleichzeitig herauszoomen, um das Gesamtbild zu sehen, und hineinzoomen, um die kleinsten Particulars zu sehen. Dadurch wird es zu einer Herausforderung, den Wald und die Bäume gleichzeitig zu erkennen. Die meisten aktuellen Methoden zwingen uns dazu, uns entweder aus den Augen zu verlieren oder die Bäume zu übersehen, und keine der beiden Optionen ist intestine.
Wie $x$T versucht, das Downside zu beheben
Stellen Sie sich vor, Sie versuchen, ein riesiges Puzzle zu lösen. Anstatt das Ganze auf einmal in Angriff zu nehmen, was überwältigend wäre, beginnen Sie mit kleineren Abschnitten, sehen sich jedes Teil genau an und finden dann heraus, wie es in das Gesamtbild passt. Das ist im Grunde das, was wir mit großen Bildern mit $x$T machen.
$x$T nimmt diese riesigen Bilder und zerlegt sie hierarchisch in kleinere, leichter verdauliche Stücke. Dabei geht es jedoch nicht nur darum, Dinge kleiner zu machen. Es geht darum, jedes Stück für sich zu verstehen und dann mithilfe einiger cleverer Techniken herauszufinden, wie diese Stücke in größerem Maßstab zusammenhängen. Es ist, als würde man mit jedem Teil des Bildes ein Gespräch führen, seine Geschichte erfahren und diese Geschichten dann mit den anderen Teilen teilen, um die vollständige Erzählung zu erhalten.
Verschachtelte Tokenisierung
Der Kern von $x$T ist das Konzept der verschachtelten Tokenisierung. Vereinfacht ausgedrückt ist die Tokenisierung im Bereich der Computervision vergleichbar mit dem Zerlegen eines Bildes in Teile (Token), die ein Modell verarbeiten und analysieren kann. $x$T geht jedoch noch einen Schritt weiter, indem es eine Hierarchie in den Prozess einführt – daher verschachtelt.
Stellen Sie sich vor, Sie sollen einen detaillierten Stadtplan analysieren. Anstatt zu versuchen, die gesamte Karte auf einmal zu erfassen, unterteilen Sie sie in Bezirke, dann in Stadtteile innerhalb dieser Bezirke und schließlich in Straßen innerhalb dieser Stadtteile. Diese hierarchische Aufteilung erleichtert die Verwaltung und das Verständnis der Particulars der Karte, während Sie gleichzeitig den Überblick darüber behalten, wo alles in das Gesamtbild passt. Das ist die Essenz der verschachtelten Tokenisierung – wir teilen ein Bild in Regionen auf, von denen jede in weitere Unterregionen aufgeteilt werden kann, je nach der von einem Imaginative and prescient-Spine erwarteten Eingabegröße (was wir als Regionen-Encoder), bevor sie für die Verarbeitung durch diesen Areas-Encoder patchiert werden. Dieser verschachtelte Ansatz ermöglicht es uns, Options auf lokaler Ebene in verschiedenen Maßstäben zu extrahieren.
Koordinieren von Areas- und Kontext-Encodern
Sobald ein Bild sauber in Token aufgeteilt ist, verwendet $x$T zwei Arten von Encodern, um diese Teile zu verstehen: den Areas-Encoder und den Kontext-Encoder. Jeder spielt eine bestimmte Rolle beim Zusammensetzen der gesamten Geschichte des Bildes.
Der Areas-Encoder ist ein eigenständiger „lokaler Experte“, der unabhängige Regionen in detaillierte Darstellungen umwandelt. Da jedoch jede Area isoliert verarbeitet wird, werden keine Informationen über das gesamte Bild hinweg geteilt. Der Areas-Encoder kann jedes moderne Imaginative and prescient-Spine sein. In unseren Experimenten haben wir hierarchische Imaginative and prescient-Transformatoren verwendet wie Swin Und Hiera und auch CNNs wie ConvNeXt!
Hier kommt der Kontextencoder ins Spiel, der Guru für das große Ganze. Seine Aufgabe ist es, die detaillierten Darstellungen der Regionsencoder zu übernehmen und zusammenzufügen, um sicherzustellen, dass die Erkenntnisse aus einem Token im Kontext der anderen betrachtet werden. Der Kontextencoder ist im Allgemeinen ein Langsequenzmodell. Wir experimentieren mit Transformator-XL (und unsere Variante davon heißt Hyper) Und Mambaobwohl Sie verwenden könnten Langformer und andere neue Fortschritte in diesem Bereich. Obwohl diese Langsequenzmodelle im Allgemeinen für Sprache entwickelt werden, zeigen wir, dass sie effektiv für visuelle Aufgaben eingesetzt werden können.
Die Magie von $x$T besteht darin, wie diese Komponenten – die verschachtelte Tokenisierung, die Areas-Encoder und die Kontext-Encoder – zusammenkommen. Indem $x$T das Bild zunächst in handhabbare Teile zerlegt und diese Teile dann sowohl isoliert als auch in Verbindung systematisch analysiert, gelingt es $x$T, die Detailtreue des Originalbilds beizubehalten und gleichzeitig den Fernkontext in den übergeordneten Kontext zu integrieren. während riesige Bilder durchgehend auf moderne GPUs passen.
Ergebnisse
Wir evaluieren $x$T anhand anspruchsvoller Benchmark-Aufgaben, die von etablierten Pc Imaginative and prescient-Baselines bis hin zu anspruchsvollen Aufgaben für große Bilder reichen. Insbesondere experimentieren wir mit iNaturalist 2018 zur feinkörnigen Artenklassifizierung, xView3-SAR zur kontextabhängigen Segmentierung und MS-COCO zur Erkennung.
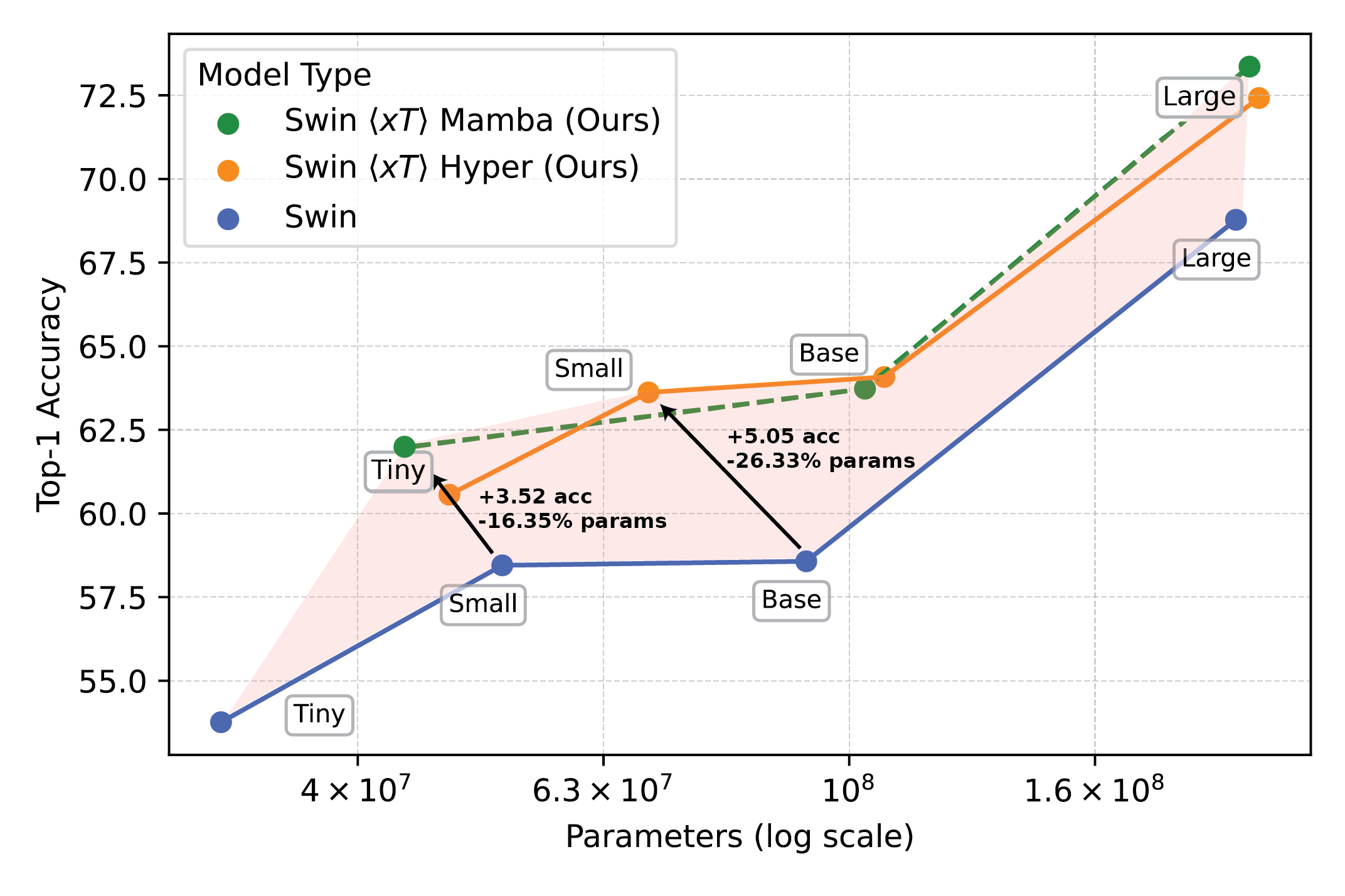
Leistungsstarke Bildverarbeitungsmodelle im Einsatz mit $x$T setzen neue Maßstäbe für nachgelagerte Aufgaben, wie etwa die detaillierte Klassifizierung von Arten.
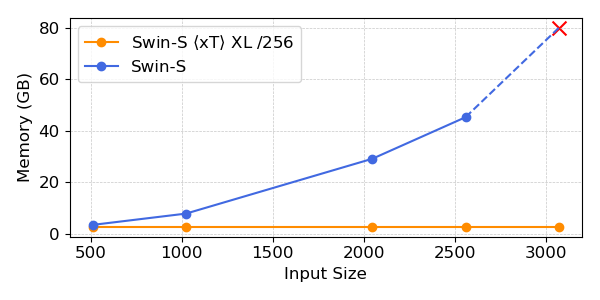
Unsere Experimente zeigen, dass $x$T bei allen nachgelagerten Aufgaben mit weniger Parametern eine höhere Genauigkeit erreichen kann und dabei viel weniger Speicher professional Area verbraucht als modernste Baselines*Wir können Bilder mit einer Größe von bis zu 29.000 x 25.000 Pixeln auf 40 GB A100 modellieren, während vergleichbare Basiswerte bereits bei 2.800 x 2.800 Pixeln nicht mehr genügend Speicher haben.
Leistungsstarke Bildverarbeitungsmodelle im Einsatz mit $x$T setzen neue Maßstäbe für nachgelagerte Aufgaben, wie etwa die detaillierte Klassifizierung von Arten.
*Abhängig von Ihrem gewählten Kontextmodell, wie z. B. Transformer-XL.
Warum das wichtiger ist, als Sie denken
Dieser Ansatz ist nicht nur cool, er ist auch notwendig. Für Wissenschaftler, die den Klimawandel verfolgen, oder Ärzte, die Krankheiten diagnostizieren, ist er ein Wendepunkt. Er bedeutet, Modelle zu entwickeln, die die ganze Geschichte verstehen, nicht nur Bruchstücke. In der Umweltüberwachung beispielsweise kann die Fähigkeit, sowohl die größeren Veränderungen in weiten Landschaften als auch die Particulars bestimmter Gebiete zu erkennen, dabei helfen, das Gesamtbild der Klimaauswirkungen zu verstehen. Im Gesundheitswesen könnte er den Unterschied ausmachen, ob eine Krankheit frühzeitig erkannt wird oder nicht.
Wir behaupten nicht, alle Probleme der Welt auf einmal gelöst zu haben. Wir hoffen, dass wir mit $x$T die Tür zu dem geöffnet haben, was möglich ist. Wir betreten eine neue Ära, in der wir bei der Klarheit oder Breite unserer Imaginative and prescient keine Kompromisse eingehen müssen. $x$T ist unser großer Schritt in Richtung Modelle, die die Feinheiten großformatiger Bilder mühelos bewältigen können.
Es gibt noch viel mehr zu erforschen. Die Forschung wird sich weiterentwickeln und hoffentlich auch unsere Fähigkeit, noch größere und komplexere Bilder zu verarbeiten. Tatsächlich arbeiten wir an Nachfolgern von $x$T, die diese Grenzen noch weiter ausdehnen werden.
Abschließend
Eine vollständige Beschreibung dieser Arbeit finden Sie im Artikel über arXiv. Der Projektseite enthält einen Hyperlink zu unserem veröffentlichten Code und den Gewichten. Wenn Sie die Arbeit nützlich finden, zitieren Sie sie bitte wie folgt:
@article{xTLargeImageModeling,
title={xT: Nested Tokenization for Bigger Context in Massive Photographs},
writer={Gupta, Ritwik and Li, Shufan and Zhu, Tyler and Malik, Jitendra and Darrell, Trevor and Mangalam, Karttikeya},
journal={arXiv preprint arXiv:2403.01915},
yr={2024}
}