
Von der Eingabeaufforderung bis zum Bild ist Steady Diffusion eine Pipeline mit vielen Komponenten und Parametern. Wenn alle diese Komponenten zusammenarbeiten, entsteht die Ausgabe. Wenn sich eine Komponente anders verhält, ändert sich die Ausgabe. Daher kann eine schlechte Einstellung Ihr Bild leicht ruinieren. In diesem Beitrag sehen Sie:
- Wie sich die verschiedenen Komponenten der Steady Diffusion-Pipeline auf Ihre Ausgabe auswirken
- So finden Sie die beste Konfiguration, um ein qualitativ hochwertiges Bild zu erzeugen
Lass uns anfangen.

So nutzen Sie stabile Diffusion effektiv.
Foto von Kam Idris. Einige Rechte vorbehalten.
Überblick
Dieser Beitrag besteht aus drei Teilen; sie sind:
- Bedeutung eines Modells
- Auswahl eines Samplers und Schedulers
- Größe und die CFG-Skala
Bedeutung eines Modells
Wenn es eine Komponente in der Pipeline gibt, die den größten Einfluss hat, muss es das Modell sein. In der Net-Benutzeroberfläche wird er „Checkpoint“ genannt, benannt nach der Artwork und Weise, wie wir das Modell gespeichert haben, als wir ein Deep-Studying-Modell trainiert haben.
Die Net-Benutzeroberfläche unterstützt mehrere Steady Diffusion-Modellarchitekturen. Die heute am weitesten verbreitete Architektur ist die Model 1.5 (SD 1.5). Tatsächlich teilen alle Versionen 1.x eine ähnliche Architektur (jedes Modell verfügt über 860 Millionen Parameter), werden jedoch mit unterschiedlichen Strategien trainiert oder verfeinert.
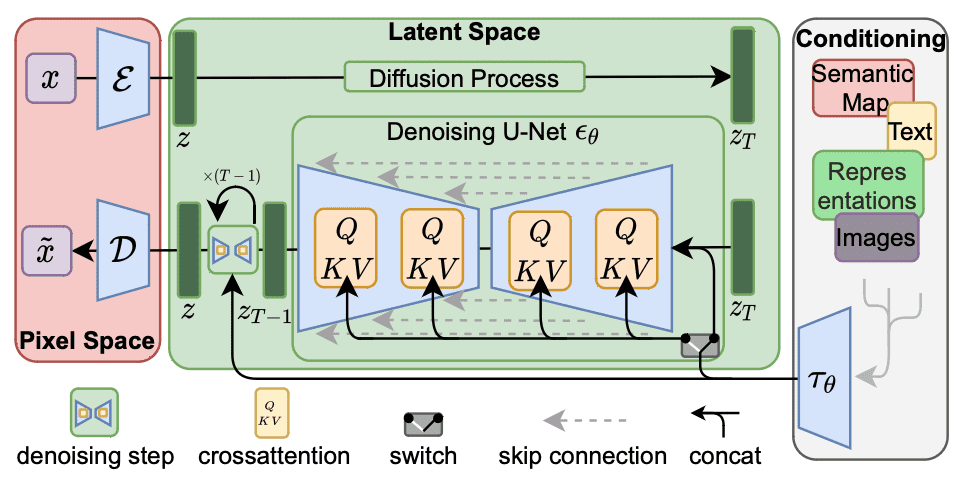
Architektur der stabilen Diffusion 1.x. Abbildung von Rombach et al. (2022)
Es gibt auch Steady Diffusion 2.0 (SD 2.0) und die aktualisierte Model 2.1. Dabei handelt es sich nicht um eine „Revision“ der Model 1.5, sondern um ein von Grund auf trainiertes Modell. Es verwendet einen anderen Textual content-Encoder (OpenCLIP anstatt CLIP); Daher würden sie Schlüsselwörter anders verstehen. Ein auffälliger Unterschied besteht darin, dass OpenCLIP weniger Namen von Prominenten und Künstlern kennt. Daher ist die Eingabeaufforderung von Steady Diffusion 1.5 in 2.1 möglicherweise veraltet. Da der Encoder unterschiedlich ist, sind SD2.x und SD1.x inkompatibel, obwohl sie eine ähnliche Architektur haben.
Als nächstes kommt der Steady Diffusion XL (SDXL). Während Model 1.5 eine native Auflösung von 512×512 hat und Model 2.0 diese auf 768×768 erhöhte, liegt SDXL bei 1024×1024. Es wird nicht empfohlen, eine wesentlich andere Größe als die native Auflösung zu verwenden. SDXL ist eine andere Architektur mit einer viel größeren 6,6-B-Parameter-Pipeline. Vor allem bestehen die Modelle aus zwei Teilen: dem Basismodell und dem Refiner-Modell. Sie werden paarweise geliefert, aber Sie können eines davon gegen ein kompatibles Gegenstück austauschen oder bei Bedarf auf den Refiner verzichten. Der verwendete Textencoder kombiniert CLIP und OpenCLIP. Daher sollte es Ihre Eingabeaufforderung besser verstehen als jede ältere Architektur. Die Ausführung von SDXL ist langsamer und erfordert viel mehr Speicher, aber normalerweise in besserer Qualität.
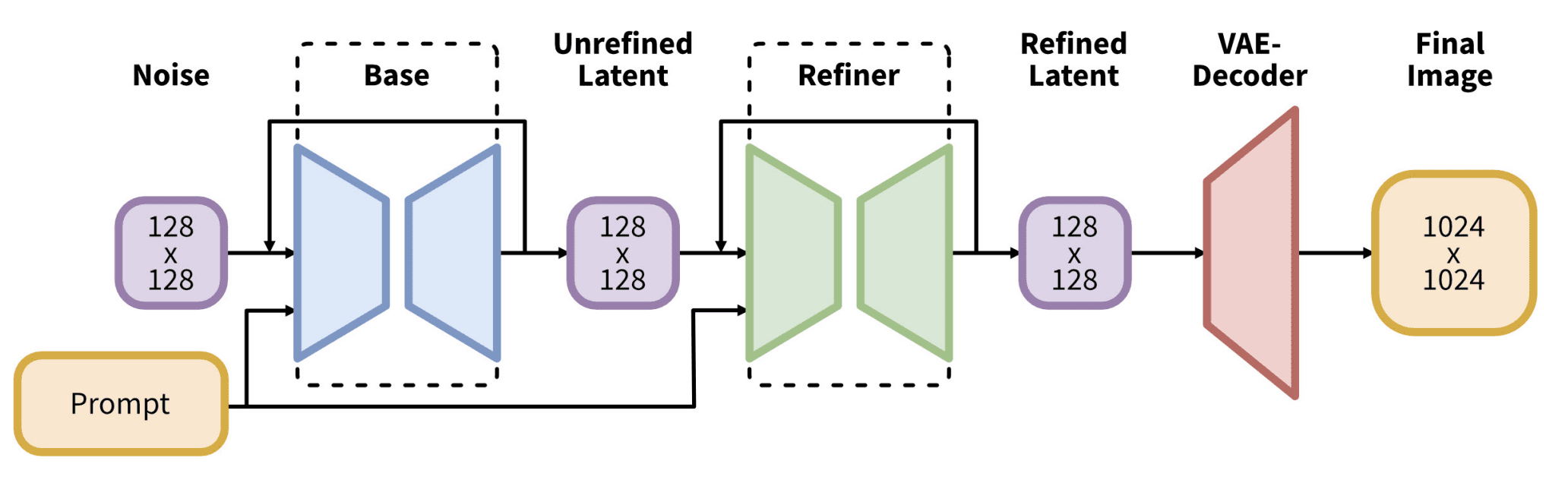
Architektur von SDXL. Abbildung von Podell et al. (2023)
Für Sie ist es wichtig, dass Sie Ihre Modelle in drei inkompatible Familien einteilen: SD1.5, SD2.x und SDXL. Sie verhalten sich bei Ihrer Eingabeaufforderung anders. Sie werden auch feststellen, dass SD1.5 und SD2.x für ein gutes Bild eine detrimental Eingabeaufforderung benötigen würden, diese ist jedoch bei SDXL weniger wichtig. Wenn Sie SD2.x-Modelle verwenden, werden Sie außerdem feststellen, dass Sie Ihren Refiner in der Net-Benutzeroberfläche auswählen können.

Bilder, die mit der Eingabeaufforderung „Ein Quick-Meals-Restaurant in der Wüste mit dem Namen „Sandy Burger““ generiert wurden, unter Verwendung von SD 1.5 mit verschiedenen zufälligen Startwerten. Beachten Sie, dass keiner von ihnen den Namen richtig geschrieben hat.

Bilder, die mit der Eingabeaufforderung „Ein Quick-Meals-Restaurant in der Wüste mit dem Namen „Sandy Burger““ generiert wurden, unter Verwendung von SD 2.0 mit verschiedenen zufälligen Startwerten. Beachten Sie, dass nicht alle den Namen richtig geschrieben haben.

Bilder, die mit der Eingabeaufforderung „Ein Quick-Meals-Restaurant in der Wüste mit dem Namen „Sandy Burger““ generiert wurden, unter Verwendung von SDXL mit verschiedenen zufälligen Startwerten. Beachten Sie, dass alle den Namen richtig geschrieben haben.
Ein Merkmal von Steady Diffusion ist, dass die ursprünglichen Modelle weniger leistungsfähig, aber anpassungsfähig sind. Daher werden viele fein abgestimmte Modelle von Drittanbietern hergestellt. Am bedeutendsten sind die Modelle, die sich auf bestimmte Stile spezialisiert haben, wie zum Beispiel japanische Animes, westliche Zeichentrickfilme, 2,5D-Grafiken im Pixar-Stil oder fotorealistische Bilder.
Modelle finden Sie auf Civitai.com oder Hugging Face Hub. Eine Suche mit Schlüsselwörtern wie „fotorealistisch“ oder „2D“ und eine Sortierung nach Bewertung würden normalerweise helfen.
Auswahl eines Samplers und Schedulers
Die Bilddiffusion beginnt mit Rauschen und ersetzt das Rauschen strategisch durch Pixel, bis das endgültige Bild entsteht. Später stellte sich heraus, dass dieser Prozess als stochastische Differentialgleichung dargestellt werden kann. Die numerische Lösung der Gleichung ist möglich und es gibt verschiedene Algorithmen unterschiedlicher Genauigkeit.
Der am häufigsten verwendete Sampler ist Euler. Es ist traditionell, aber dennoch nützlich. Dann gibt es noch eine Familie von DPM-Samplern. Einige neue Sampler wie UniPC und LCM wurden kürzlich eingeführt. Jeder Sampler ist ein Algorithmus. Es soll für mehrere laufen Schritte, und in jedem Schritt werden unterschiedliche Parameter verwendet. Die Parameter werden über a eingestellt Planer, wie Karras oder exponentiell. Einige Sampler verfügen über einen alternativen „Ancestral“-Modus, der jedem Schritt Zufälligkeit hinzufügt. Dies ist nützlich, wenn Sie mehr kreative Leistung wünschen. Diese Sampler tragen meist den Zusatz „a“ im Namen, etwa „Euler a“ statt „Euler“. Die nicht angestammten Sampler konvergieren, dh sie hören nach bestimmten Schritten auf, die Ausgabe zu ändern. Ancestral-Sampler würden eine andere Ausgabe liefern, wenn Sie die Schrittgröße erhöhen.

Auswahl von Sampler, Scheduler, Schritten und anderen Parametern in der Steady Diffusion Net-Benutzeroberfläche
Als Benutzer können Sie davon ausgehen, dass Karras der Planer für alle Fälle ist. Der Zeitplaner und die Schrittgröße erfordern jedoch einige Experimente. Entweder Euler oder DPM++2M sollten ausgewählt werden, da sie Qualität und Geschwindigkeit am besten ausbalancieren. Sie können mit einer Schrittweite von etwa 20 bis 30 beginnen; Je mehr Schritte Sie wählen, desto besser ist die Ausgabequalität in Bezug auf Particulars und Genauigkeit, aber proportional langsamer.
Größe und CFG-Skala
Denken Sie daran, dass der Bilddiffusionsprozess mit einem verrauschten Bild beginnt und nach und nach Pixel platziert, die durch die Eingabeaufforderung bedingt sind. Wie stark sich die Konditionierung auf den Diffusionsprozess auswirken kann, wird durch den Parameter CFG-Skala (klassifikatorfreie Führungsskala) gesteuert.
Leider hängt der optimale Wert der CFG-Skala vom Modell ab. Einige Modelle funktionieren am besten mit einer CFG-Skala von 1 bis 2, während andere für 7 bis 9 optimiert sind. Der Standardwert in der Net-Benutzeroberfläche ist 7,5. Generell gilt jedoch: Je höher die CFG-Skala, desto stärker entspricht das Ausgabebild Ihrer Eingabeaufforderung.
Wenn Ihr CFG-Maßstab zu niedrig ist, entspricht das Ausgabebild möglicherweise nicht Ihren Erwartungen. Es gibt jedoch noch einen weiteren Grund, warum Sie nicht das erhalten, was Sie erwartet haben: Die Ausgabegröße. Wenn Sie beispielsweise nach einem Bild eines stehenden Mannes fragen, erhalten Sie möglicherweise stattdessen ein Kopffoto oder eine Halbkörperaufnahme, es sei denn, Sie stellen die Bildgröße auf eine deutlich größere Höhe als die Breite ein. Der Diffusionsprozess legt in den ersten Schritten die Bildkomposition fest. Es ist einfacher, einen stehenden Mann auf einer größeren Leinwand darzustellen.
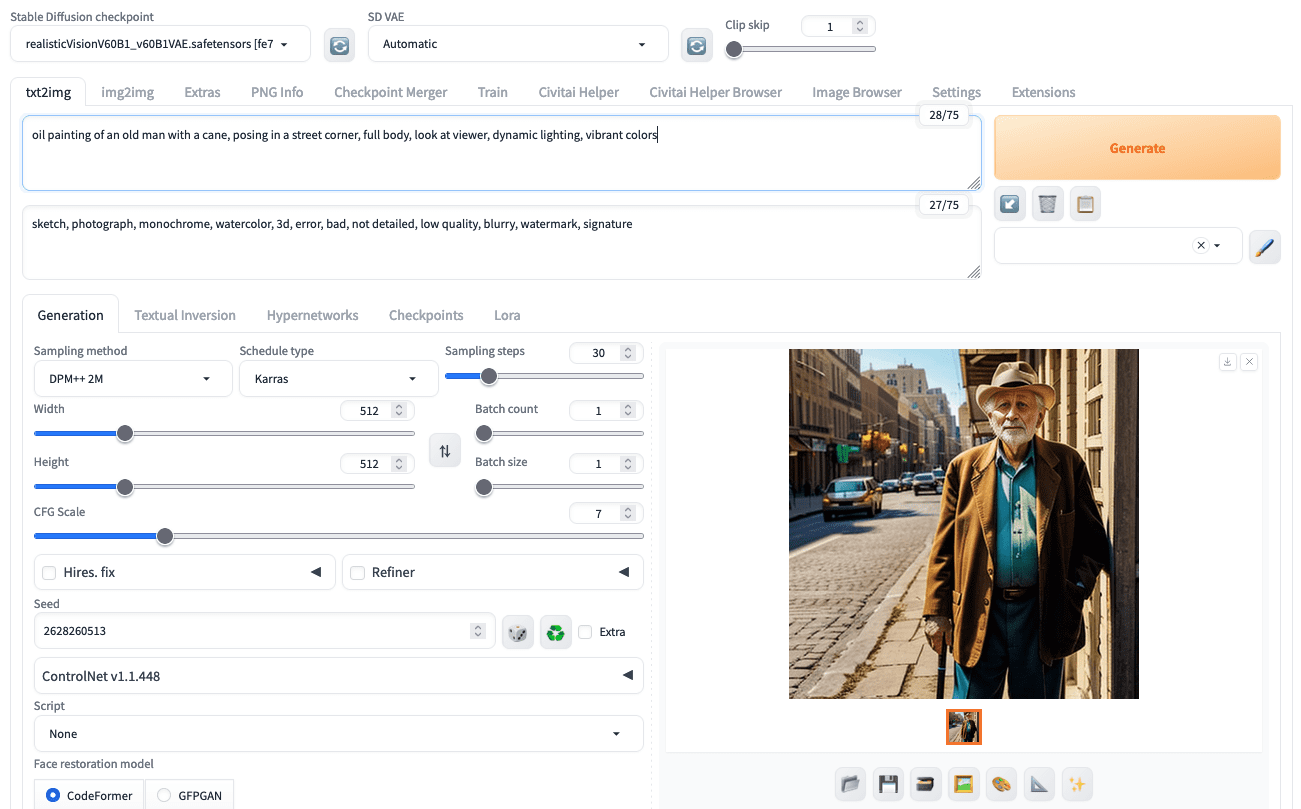
Erzeugen einer Halbkörperaufnahme, wenn eine quadratische Leinwand bereitgestellt wird.

Generieren einer Ganzkörperaufnahme mit derselben Eingabeaufforderung, demselben Startwert und nur der Änderung der Leinwandgröße.
Wenn Sie einem Objekt, das einen kleinen Teil des Bildes einnimmt, zu viele Particulars geben, werden diese Particulars ebenfalls ignoriert, da nicht genügend Pixel vorhanden sind, um diese Particulars darzustellen. Deshalb ist beispielsweise SDXL im Allgemeinen besser als SD 1,5, da Sie normalerweise eine größere Pixelgröße verwenden.
Abschließend sei noch darauf hingewiesen, dass die Generierung von Bildern mithilfe von Bilddiffusionsmodellen Zufälligkeit beinhaltet. Beginnen Sie immer mit einem Stapel mehrerer Bilder, um sicherzustellen, dass die schlechte Ausgabe nicht nur auf den zufälligen Startwert zurückzuführen ist.
Weitere Lektüre
In diesem Abschnitt finden Sie weitere Ressourcen zum Thema, wenn Sie tiefer gehen möchten.
Zusammenfassung
In diesem Beitrag haben Sie einige subtile Particulars kennengelernt, die sich auf die Bilderzeugung in Steady Diffusion auswirken. Konkret haben Sie gelernt:
- Der Unterschied zwischen verschiedenen Versionen von Steady Diffusion
- Wie sich der Scheduler und der Sampler auf den Bilddiffusionsprozess auswirken
- Wie sich die Leinwandgröße auf die Ausgabe auswirken kann