Eine einfache Anleitung zur Verallgemeinerung von NLP-Aufgaben auf Pc Imaginative and prescient
Quick alle Aufgaben der natürlichen Sprachverarbeitung, von Sprachmodellierung und maskierter Wortvorhersage bis hin zu Übersetzung und Fragen-Antworten, wurden mit der Einführung der Transformer-Architektur im Jahr 2017 revolutioniert. Es dauerte nicht länger als 2–3 Jahre, bis Transformer auch bei Pc Imaginative and prescient-Aufgaben brillierten. In dieser Geschichte untersuchen wir zwei grundlegende Architekturen, die Transformern den Durchbruch in die Welt der Pc Imaginative and prescient ermöglichten.
Inhaltsverzeichnis
· Der Imaginative and prescient Transformer
∘ Schlüsselidee
∘ Betrieb
∘ Hybride Architektur
∘ Verlust der Struktur
∘ Ergebnisse
∘ Selbstüberwachtes Lernen durch Maskierung
· Maskierter Autoencoder Imaginative and prescient Transformer
∘ Schlüsselidee
∘ Die Architektur
∘ Schlussbemerkung und Beispiel

Schlüsselidee
Der Imaginative and prescient Transformer dient lediglich zur Verallgemeinerung der Standardtransformator Architektur zur Verarbeitung und zum Lernen von Bildeingaben. Es gibt eine Schlüsselidee zur Architektur, die die Autoren clear genug hervorgehoben haben:
„Inspiriert von den Erfolgen bei der Skalierung von Transformer in NLP experimentieren wir mit der Anwendung eines Commonplace-Transformers direkt auf Bilder, mit möglichst wenigen Änderungen.“
Betrieb
Es ist gültig, „möglichst wenige Änderungen“ im wahrsten Sinne des Wortes, denn sie nehmen praktisch keine Änderungen vor. Was sie tatsächlich ändern, ist die Eingabestruktur:
- In NLP nimmt der Transformator-Encoder eine Folge von One-Scorching-Vektoren (oder gleichwertige Token-Indizes), die den eingegebenen Satz/Absatz darstellen und gibt eine Folge von kontextuellen Einbettungsvektoren zurück, die für weitere Aufgaben (z. B. Klassifizierung) verwendet werden könnten
- Um den Lebenslauf zu verallgemeinern, nimmt der Imaginative and prescient Transformer eine Sequenz von Patch-Vektoren die repräsentieren die Eingabebild und gibt eine Folge von kontextuellen Einbettungsvektoren zurück, die für weitere Aufgaben (z. B. Klassifizierung) verwendet werden könnten
Nehmen wir insbesondere an, dass die Eingabebilder die Dimensionen (n,n,3) haben, um diese als Eingabe an den Transformator zu übergeben. Der Imaginative and prescient-Transformator macht Folgendes:
- Teilt es in k² Patches für ein gewisses okay auf (z. B. okay = 3), wie in der Abbildung oben.
- Jetzt ist jeder Patch (n/okay,n/okay,3). Der nächste Schritt besteht darin, jeden Patch in einen Vektor umzuwandeln.
Der Patch-Vektor hat die Dimension 3*(n/okay)*(n/okay). Wenn das Bild beispielsweise (900,900,3) ist und wir okay=3 verwenden, hat ein Patch-Vektor die Dimension 300*300*3, der die Pixelwerte im abgeflachten Patch darstellt. In dem Artikel verwenden die Autoren okay=16. Daher der Title des Artikels „Ein Bild sagt mehr als 16×16 Worte: Transformer für die Bilderkennung im großen Maßstab“. Anstatt einen One-Scorching-Vektor einzugeben, der das Wort darstellt, stellen sie einen Vektorpixel dar, der einen Patch des Bildes darstellt.
Die restlichen Operationen bleiben wie beim ursprünglichen Transformator-Encoder:
- Diese Patch-Vektoren passieren eine trainierbare Einbettungsschicht
- Jedem Vektor werden Positionseinbettungen hinzugefügt, um ein Gefühl räumlicher Informationen im Bild zu erhalten
- Die Ausgabe ist Anzahl Patches Encoderdarstellungen (eine für jeden Patch), die zur Klassifizierung auf Patch- oder Bildebene verwendet werden können
- Häufiger (und wie im Dokument) wird der entsprechenden Darstellung ein CLS-Token vorangestellt, das zur Vorhersage des gesamten Bildes verwendet wird (ähnlich wie bei BERT).
Wie wäre es mit dem Transformator-Decoder?
Denken Sie daran, dass es genau wie der Transformer-Encoder ist. Der Unterschied besteht darin, dass er maskierte Selbstaufmerksamkeit anstelle von Selbstaufmerksamkeit verwendet (aber die gleiche Eingabesignatur bleibt). In jedem Fall sollten Sie davon ausgehen, dass Sie eine Transformer-Architektur, die nur aus Decodern besteht, nur selten verwenden werden, da die einfache Vorhersage des nächsten Patches möglicherweise keine besonders interessante Aufgabe ist.
Hybride Architektur
Die Autoren erwähnen auch, dass es möglich ist, mit einer CNN-Function-Map statt mit dem Bild selbst zu beginnen, um eine Hybridarchitektur zu bilden (CNN speist die Ausgabe in den Imaginative and prescient Transformer ein). In diesem Fall betrachten wir die Eingabe als eine generische (n,n,p)-Function-Map und ein Patch-Vektor hat die Dimensionen (n/okay)*(n/okay)*p.
Verlust der Struktur
Es könnte Ihnen in den Sinn kommen, dass diese Architektur nicht so intestine sein sollte, weil sie das Bild als lineare Struktur behandelt, obwohl dies nicht der Fall ist. Der Autor versucht darzustellen, dass dies beabsichtigt ist, indem er erwähnt
„Die zweidimensionale Nachbarschaftsstruktur wird sehr sparsam eingesetzt … Positionseinbettungen enthalten zum Zeitpunkt der Initialisierung keine Informationen über die 2D-Positionen der Patches und alle räumlichen Beziehungen zwischen den Patches müssen von Grund auf neu erlernt werden.“
Wir werden im nächsten Artikel sehen, dass der Transformator dies lernen kann, wie seine gute Leistung in den Experimenten und, noch wichtiger, die Architektur beweisen.
Ergebnisse
Das wichtigste Fazit der Ergebnisse ist, dass Imaginative and prescient Transformers bei kleinen Datensätzen tendenziell nicht besser abschneiden als CNN-basierte Modelle, bei größeren Datensätzen jedoch an CNN-basierte Modelle herankommen oder diese übertreffen und in jedem Fall erheblich weniger Rechenleistung erfordern:

Hier sehen wir, dass für den JFT-300M-Datensatz (der 300 Millionen Bilder enthält) die auf dem Datensatz vortrainierten ViT-Modelle die auf ResNet basierenden Baselines übertreffen, während sie für das Vortraining wesentlich weniger Rechenressourcen benötigen. Wie man sehen kann, nutzte der größte von ihnen verwendete Imaginative and prescient Transformer (ViT-Large mit 632 Millionen Parametern und okay=16) etwa 25 % der Rechenleistung des auf ResNet basierenden Modells und übertraf es dennoch. Die Leistung verschlechtert sich nicht einmal so sehr, da ViT-Giant nur <6,8 % der Rechenleistung nutzt.
Mittlerweile legen auch andere Ergebnisse vor, bei denen ResNet eine deutlich bessere Leistung zeigte, wenn es auf ImageNet-1K trainiert wurde, das lediglich über 1,3 Millionen Bilder verfügt.
Selbstüberwachtes Lernen durch Maskierung
Die Autoren führten eine vorläufige Untersuchung zur Vorhersage maskierter Patches zur Selbstüberwachung durch und ahmten dabei die in BERT verwendete Aufgabe der maskierten Sprachmodellierung nach (d. h. Patches ausblenden und versuchen, sie vorherzusagen).
„Wir verwenden das Ziel der maskierten Patch-Vorhersage für vorläufige Selbstüberwachungsexperimente. Dazu beschädigen wir 50 % der Patch-Einbettungen, indem wir ihre Einbettungen entweder durch eine lernbare (Masken-)Einbettung (80 %), eine zufällige andere Patch-Einbettung (10 %) ersetzen oder sie einfach so lassen, wie sie sind (10 %).“
Mit selbstüberwachtem Vortraining erreicht ihr kleineres ViT-Base/16-Modell eine Genauigkeit von 79,9 % auf ImageNet, eine deutliche Verbesserung von 2 % gegenüber dem Coaching von Grund auf. Aber immer noch 4 % hinter dem überwachten Vortraining.

Schlüsselidee
Wie wir aus dem Artikel zum Imaginative and prescient Transformer erfahren haben, waren die Vorteile des Vortrainings durch Maskieren von Patches in den Eingabebildern nicht so signifikant wie bei gewöhnlicher NLP, wo maskiertes Vortraining bei einigen Feinabstimmungsaufgaben zu hochmodernen Ergebnissen führen kann.
In diesem Dokument wird eine Imaginative and prescient-Transformer-Architektur mit einem Encoder und einem Decoder vorgeschlagen, die bei Vortraining mit Maskierung zu erheblichen Verbesserungen gegenüber dem Basismodell des Imaginative and prescient Transformer führt (bis zu 6 % Verbesserung im Vergleich zum überwachten Coaching eines Imaginative and prescient Transformer in Basisgröße).

Dies ist ein Beispiel (Eingabe, Ausgabe, echte Beschriftungen). Es handelt sich insofern um einen Autoencoder, als er versucht hat, die Eingabe zu rekonstruieren und gleichzeitig die fehlenden Patches auszufüllen.
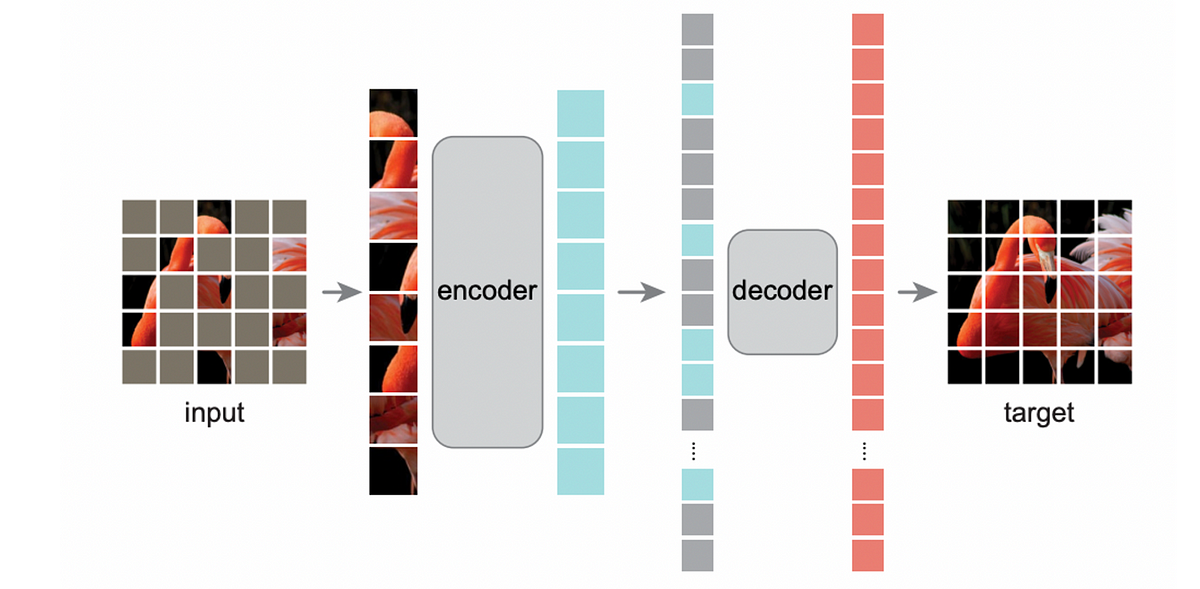
Die Architektur
Ihre Encoder ist einfach der normale Imaginative and prescient-Transformer-Encoder, den wir zuvor erklärt haben. Beim Coaching und bei der Inferenz werden nur die „beobachteten“ Patches verwendet.
Inzwischen Decoder ist auch einfach der normale Imaginative and prescient-Transformer-Encoder, aber er benötigt:
- Maskierte Token-Vektoren für die fehlenden Patches
- Encoder-Ausgabevektoren für die bekannten Patches
Für ein Bild ( ( A, B, X), (C, X, X), (X, D, E)), bei dem X einen fehlenden Patch bezeichnet, verwendet der Decoder die Sequenz der Patch-Vektoren (Enc(A), Enc(B), Vec(X), Vec(X), Vec(X), Enc(D), Enc(E)). Enc gibt den Encoder-Ausgabevektor für den Patch-Vektor zurück und X ist ein Vektor zur Darstellung des fehlenden Tokens.
Der letzte Schicht im Decoder gibt es eine lineare Schicht, die die Kontexteinbettungen (erzeugt durch den Imaginative and prescient Transformer Encoder im Decoder) auf einen Vektor mit der Länge gleich der Patchgröße abbildet. Die Verlustfunktion ist der mittlere quadratische Fehler, der die Differenz zwischen dem ursprünglichen Patchvektor und dem von dieser Schicht vorhergesagten quadriert. In der Verlustfunktion betrachten wir nur die Decodervorhersagen aufgrund maskierter Token und ignorieren diejenigen, die den aktuellen entsprechen (d. h. Dec(A), Dec(B), Dec(C) usw.).
Schlussbemerkung und Beispiel
Es magazine überraschend sein, dass die Autoren vorschlagen, etwa 75 % der Patches in den Bildern zu maskieren; BERT würde nur etwa 15 % der Wörter maskieren. Sie begründen dies folgendermaßen:
Bilder sind natürliche Signale mit starker räumlicher Redundanz – z. B. kann ein fehlender Patch aus benachbarten Patches wiederhergestellt werden, ohne dass Teile, Objekte und Szenen auf hohem Niveau verstanden werden. Um diesen Unterschied zu überwinden und das Erlernen nützlicher Funktionen zu fördern, maskieren wir einen sehr hohen Anteil zufälliger Patches.
Möchten Sie es selbst ausprobieren? Schauen Sie sich das an Demo-Notizbuch von NielsRogge.
Das ist alles für diese Geschichte. Wir haben uns auf eine Reise begeben, um zu verstehen, wie grundlegende Transformatormodelle auf die Welt der Computervision verallgemeinert werden können. Ich hoffe, Sie fanden es klar, aufschlussreich und Ihre Zeit wert.
Verweise:
(1) Dosovitskiy, A. et al. (2021) Ein Bild sagt mehr als 16 x 16 Worte: Transformatoren für die Bilderkennung im großen Maßstab, arXiv.org. Verfügbar um: https://arxiv.org/abs/2010.11929 (Zugriff: 28. Juni 2024).
(2) Er, Ok. et al. (2021) Maskierte Autoencoder sind skalierbare Imaginative and prescient-Lerner, arXiv.org. Verfügbar um: https://arxiv.org/abs/2111.06377 (Zugriff: 28. Juni 2024).