
Einführung
LlamaIndex ist ein beliebtes Framework zum Erstellen LL.M. Anwendungen. Um eine robuste Anwendung zu erstellen, müssen wir wissen, wie man die eingebetteten Token zählt, bevor man sie erstellt, sicherstellen, dass es keine Duplikate im Vektorspeicher gibt, Quelldaten für die generierte Antwort erhält und vieles mehr. In diesem Artikel werden die Schritte zum Erstellen einer robusten Anwendung mit LlamaIndex erläutert.
Lernziele
- Verstehen Sie die wesentlichen Komponenten und Funktionen des LlamaIndex-Frameworks zum Erstellen robuster LLM-Anwendungen.
- Erfahren Sie, wie Sie eine effiziente Aufnahmepipeline zum Transformieren, Analysieren und Speichern von Dokumenten erstellen und ausführen.
- Erlernen Sie das Initialisieren, Speichern und Laden von Dokumenten und Vektorspeichern, um die dauerhafte Datenspeicherung effektiv zu verwalten.
- Erlernen Sie das Erstellen von Indizes und die Verwendung benutzerdefinierter Eingabeaufforderungen, um effiziente Abfragen und kontinuierliche Interaktionen mit Chat-Engines zu ermöglichen.

Voraussetzungen
Hier sind einige Voraussetzungen zum Erstellen einer Anwendung mit LlamaIndex.
Verwenden Sie die .env-Datei, um den OpenAI-Schlüssel zu speichern und ihn aus der Datei zu laden
import os
from dotenv import load_dotenv
load_dotenv('/.env') # present path of the .env file
OPENAI_API_KEY = os.environ('OPENAI_API_KEY')Wir werden Paul Grahams Essay als Beispieldokument verwenden. Es kann hier heruntergeladen werden: https://github.com/run-llama/llama_index/blob/principal/docs/docs/examples/information/paul_graham/paul_graham_essay.txt
So erstellen Sie eine Anwendung mit LlamaIndex
Laden der Daten
Der erste Schritt beim Erstellen einer Anwendung mit LlamaIndex besteht darin, die Daten zu laden.
from llama_index.core import SimpleDirectoryReader
paperwork = SimpleDirectoryReader(input_files=("./information/paul_graham_essay.txt"),
filename_as_id=True).load_data(show_progress=True)
# 'paperwork' is an inventory, which comprises the recordsdata we have now loadedSchauen wir uns die Schlüssel des Dokumentobjekts an
paperwork(0).to_dict().keys()
# output
"""
dict_keys(('id_', 'embedding', 'metadata', 'excluded_embed_metadata_keys',
'excluded_llm_metadata_keys', 'relationships', 'textual content', 'start_char_idx',
'end_char_idx', 'text_template', 'metadata_template', 'metadata_seperator',
'class_name'))
"""Wir können die Werte dieser Schlüssel wie bei einem Wörterbuch ändern. Sehen wir uns ein Beispiel mit Metadaten an.
Wenn wir weitere Informationen zum Dokument hinzufügen möchten, können wir diese wie folgt den Dokumentmetadaten hinzufügen. Diese Metadaten-Tags können zum Filtern der Dokumente verwendet werden.
paperwork(0).metadata.replace({'creator': 'paul_graham'})
paperwork(0).metadata
# output
"""
{'file_path': 'information/paul_graham_essay.txt',
'file_name': 'paul_graham_essay.txt',
'file_type': 'textual content/plain',
'file_size': 75042,
'creation_date': '2024-04-16',
'last_modified_date': '2024-04-15',
'creator': 'paul_graham'}
"""Aufnahmepipeline
Mit der Aufnahmepipeline können wir alle Datentransformationen durchführen, z. B. das Dokument in Knoten zerlegen, Metadaten für die Knoten extrahieren, Einbettungen erstellen, die Daten im Dokumentspeicher speichern und die Einbettungen und den Textual content der Knoten im Vektorspeicher speichern. Auf diese Weise können wir alles, was zum Bereitstellen der Daten für die Indizierung erforderlich ist, an einem Ort aufbewahren.
Noch wichtiger ist, dass durch die Verwendung des Doc Retailer und des Vector Retailer sichergestellt wird, dass keine doppelten Einbettungen erstellt werden, wenn wir den Doc Retailer und den Vector Retailer speichern und laden und die Aufnahmepipeline für dieselben Dokumente ausführen.
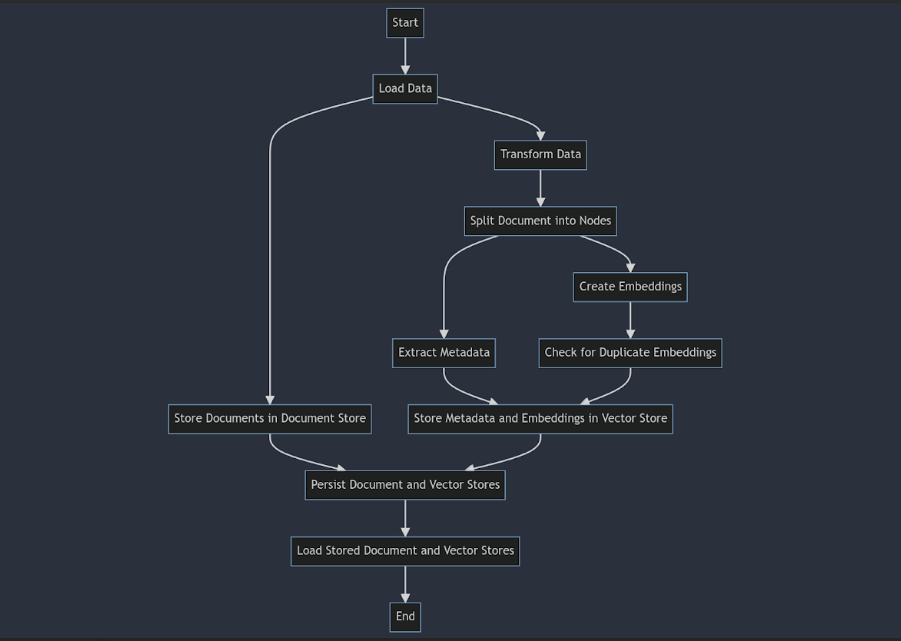
Token-Zählung
Der nächste Schritt beim Erstellen einer Anwendung mit LlamaIndex ist das Zählen der Token.
import the dependencies
import nest_asyncio
nest_asyncio.apply()
import tiktoken
from llama_index.core.callbacks import CallbackManager, TokenCountingHandler
from llama_index.core import MockEmbedding
from llama_index.core.llms import MockLLM
from llama_index.core.node_parser import SentenceSplitter,HierarchicalNodeParser
from llama_index.core.ingestion import IngestionPipeline
from llama_index.core.extractors import TitleExtractor, SummaryExtractorInitialisieren des Token-Zählers
token_counter = TokenCountingHandler(
tokenizer=tiktoken.encoding_for_model("gpt-3.5-turbo").encode,
verbose=True
)Jetzt können wir mit dem Aufbau einer Ingestion-Pipeline mit MockEmbedding und MockLLM fortfahren.
mock_pipeline = IngestionPipeline(
transformations = (SentenceSplitter(chunk_size=512, chunk_overlap=64),
TitleExtractor(llm=MockLLM(callback_manager=CallbackManager((token_counter)))),
MockEmbedding(embed_dim=1536, callback_manager=CallbackManager((token_counter)))))
nodes = mock_pipeline.run(paperwork=paperwork, show_progress=True, num_workers=-1)Der obige Code wendet einen Satzteiler auf die Dokumente an, um Knoten zu erstellen, und verwendet dann Mock-Embedding- und LLM-Modelle zur Metadatenextraktion und Embedding-Erstellung.
Dann können wir die Token-Anzahl überprüfen
# this returns the rely of embedding tokens
token_counter.total_embedding_token_count
# this returns the rely of llm tokens
token_counter.total_llm_token_count
# token counter is cumulative. Once we wish to set the token counts to zero, we are able to use this
token_counter.reset_counts()Wir können verschiedene Knotenparser und Metadatenextraktoren ausprobieren, um zu ermitteln, wie viele Token benötigt werden.
Erstellen Sie Doc- und Vector-Shops
Der nächste Schritt beim Erstellen einer Anwendung mit LlamaIndex besteht darin, Doc- und Vektorspeicher zu erstellen.
from llama_index.embeddings.openai import OpenAIEmbedding
from llama_index.core.storage.docstore import SimpleDocumentStore
from llama_index.vector_stores.chroma import ChromaVectorStore
import chromadbJetzt können wir den Doc- und den Vektorspeicher initialisieren
doc_store = SimpleDocumentStore()
# point out the trail, the place vector retailer is saved
chroma_client = chromadb.PersistentClient(path="./chroma_db")
# we'll create a set if would not already exists
chroma_collection = chroma_client.get_or_create_collection("paul_essay")
vector_store = ChromaVectorStore(chroma_collection=chroma_collection)pipeline = IngestionPipeline(
transformations = (SentenceSplitter(chunk_size=512, chunk_overlap=128),
OpenAIEmbedding(model_name="text-embedding-3-small",
callback_manager=CallbackManager((token_counter)))),
docstore=doc_store,
vector_store=vector_store
)
nodes = pipeline.run(paperwork=paperwork, show_progress=True, num_workers=-1)Sobald wir die Pipeline ausführen, werden Einbettungen im Vektorspeicher für die Knoten gespeichert. Wir müssen auch den Doc-Speicher speichern.
doc_store.persist('./doc storage/doc_store.json')
# we are able to additionally verify the embedding token rely
token_counter.total_embedding_token_countJetzt können wir den Kernel neu starten, um die gespeicherten Shops zu laden.
Laden Sie die Doc- und Vector-Shops
Lassen Sie uns nun die erforderlichen Methoden wie oben erwähnt importieren.
# load the doc retailer
doc_store = SimpleDocumentStore.from_persist_path('./doc storage/doc_store.json')
# load the vector retailer
chroma_client = chromadb.PersistentClient(path="./chroma_db")
chroma_collection = chroma_client.get_or_create_collection("paul_essay")
vector_store = ChromaVectorStore(chroma_collection=chroma_collection)
Nun initialisieren Sie die obige Pipeline erneut und führen sie aus. Sie erstellt jedoch keine Einbettungen, da das System das Dokument bereits verarbeitet und gespeichert hat. Wir fügen additionally ein beliebiges neues Dokument einem Ordner hinzu, laden alle Dokumente und führen die Pipeline aus, wobei wir nur Einbettungen für das neue Dokument erstellen.
Wir können es mit dem folgenden überprüfen
# hash of the doc
paperwork(0).hash
# you will get the doc title from the doc_store
for i in doc_store.docs.keys():
print(i)
# hash of the doc within the doc retailer
doc_store.docs('information/paul_graham_essay.txt').hash
# When each of these hashes match, duplicate embeddings are usually not created. Schauen Sie in den Vector Retailer
Sehen wir uns an, was im Vektorspeicher gespeichert ist.
chroma_collection.get().keys()
# output
# dict_keys(('ids', 'embeddings', 'metadatas', 'paperwork', 'uris', 'information'))
chroma_collection.get()('metadatas')(0).keys()
# output
# dict_keys(('_node_content', '_node_type', 'creation_date', 'doc_id',
'document_id', 'file_name', 'file_path', 'file_size',
'file_type', 'last_modified_date', 'ref_doc_id'))
# this may return ids, metadatas, and paperwork of the nodes within the assortment
chroma_collection.get() Wie wissen wir, welcher Knoten welchem Dokument entspricht? Wir können uns die Metadaten node_content ansehen.
ids = chroma_collection.get()('ids')
# this may print doc title for every node
for i in ids:
information = json.hundreds(chroma_collection.get(i)('metadatas')(0)('_node_content'))
print(information('relationships')('1')('node_id'))# this may embrace the embeddings of the node together with metadata and textual content
chroma_collection.get(ids=ids(0),embrace=('embeddings', 'metadatas', 'paperwork'))
# we are able to additionally filter the gathering
chroma_collection.get(ids=ids, the place={'file_size': {'$gt': 75040}},
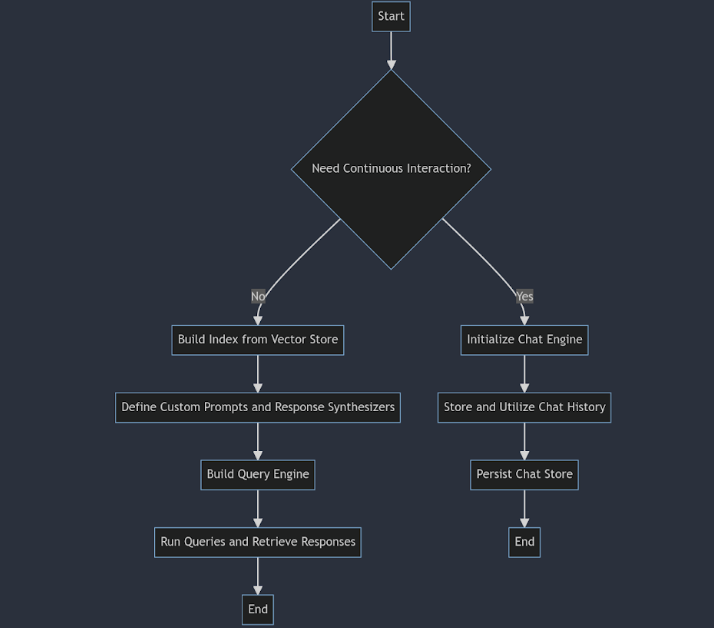
where_document={'$comprises': 'paul'}, embrace=('metadatas', 'paperwork'))Abfragen
from llama_index.llms.openai import OpenAI
from llama_index.core.retrievers import VectorIndexRetriever
from llama_index.core import get_response_synthesizer
from llama_index.core.response_synthesizers.kind import ResponseMode
from llama_index.core.query_engine import RetrieverQueryEngine
from llama_index.core.chat_engine import (ContextChatEngine,
CondenseQuestionChatEngine, CondensePlusContextChatEngine)
from llama_index.core.storage.chat_store import SimpleChatStore
from llama_index.core.reminiscence import ChatMemoryBuffer
from llama_index.core import PromptTemplate
from llama_index.core.chat_engine.sorts import ChatMode
from llama_index.core.llms import ChatMessage, MessageRole
from llama_index.core import ChatPromptTemplateJetzt können wir einen Index aus dem Vektorspeicher erstellen. Ein Index ist eine Datenstruktur, die das schnelle Abrufen des relevanten Kontexts für eine Benutzerabfrage erleichtert.
# outline the index
index = VectorStoreIndex.from_vector_store(vector_store=vector_store)
# outline a retriever
retriever = VectorIndexRetriever(index=index, similarity_top_k=3)Im obigen Code ruft der Retriever die drei ähnlichsten Knoten zu unserer Abfrage ab.
Wenn wir möchten, dass das LLM die Abfrage nur auf Grundlage des bereitgestellten Kontexts und sonst nichts beantwortet, können wir die benutzerdefinierten Eingabeaufforderungen entsprechend verwenden.
qa_prompt_str = (
"Context data is under.n"
"---------------------n"
"{context_str}n"
"---------------------n"
"Given the context data and never prior information, "
"reply the query: {query_str}n"
)
chat_text_qa_msgs = (
ChatMessage(function=MessageRole.SYSTEM,
content material=("Solely reply the query, if the query is answerable with the given context.
In any other case say that query cannot be answered utilizing the context"),
),
ChatMessage(function=MessageRole.USER, content material=qa_prompt_str))
text_qa_template = ChatPromptTemplate(chat_text_qa_msgs)Jetzt können wir den Antwortsynthesizer definieren, der den Kontext und die Abfragen an das LLM übergibt, um die Antwort zu erhalten. Wir können auch einen Token-Zähler als Callback-Supervisor hinzufügen, um die verwendeten Token zu verfolgen.
gpt_3_5 = OpenAI(mannequin="gpt-3.5-turbo")
response_synthesizer = get_response_synthesizer(llm = gpt_3_5, response_mode=ResponseMode.COMPACT,
text_qa_template=text_qa_template,
callback_manager=CallbackManager((token_counter)))Jetzt können wir den Retriever und den Response_Synthesizer als Abfrage-Engine kombinieren, die die Abfrage entgegennimmt.
query_engine = RetrieverQueryEngine(
retriever=retriever,
response_synthesizer=response_synthesizer)
# ask a question
Response = query_engine.question("who's paul graham?")
# response textual content
Response.responseUm zu erfahren, welcher Textual content zur Generierung dieser Antwort verwendet wird, können wir den folgenden Code verwenden
for i, node in enumerate(Response.source_nodes):
print(f"textual content of the node {i}")
print(node.textual content)
print("------------------------------------n")Ebenso können wir verschiedene Abfrage-Engines ausprobieren.
Chatten
Wenn wir mit unseren Daten kommunizieren möchten, müssen wir die vorherigen Abfragen und die Antworten speichern, anstatt isolierte Abfragen zu stellen.
chat_store = SimpleChatStore()
chat_memory = ChatMemoryBuffer.from_defaults(token_limit=5000, chat_store=chat_store, llm=gpt_3_5)
system_prompt = "Reply the query solely based mostly on the context offered"
chat_engine = CondensePlusContextChatEngine(retriever=retriever,
llm=gpt_3_5, system_prompt=system_prompt, reminiscence=chat_memory)Im obigen Code haben wir chat_store initialisiert und das chat_memory-Objekt mit einem Token-Restrict von 5000 erstellt. Wir können auch eine system_prompt und andere Eingabeaufforderungen bereitstellen.
Dann können wir eine Chat-Engine erstellen, indem wir auch Retriever und Chat-Speicher einbinden.
Wir können die Antwort wie folgt erhalten
streaming_response = chat_engine.stream_chat("Who's Paul Graham?")
for token in streaming_response.response_gen:
print(token, finish="")Wir können den Chatverlauf mit dem angegebenen Code lesen
for i in chat_memory.chat_store.retailer('chat_history'):
print(i.function.title)
print(i.content material)Jetzt können wir den Chat-Retailer nach Bedarf speichern und wiederherstellen.
chat_store.persist(persist_path="chat_store.json")
chat_store = SimpleChatStore.from_persist_path(
persist_path="chat_store.json"
)Auf diese Weise können wir mit dem LlamaIndex-Framework robuste RAG-Anwendungen erstellen und verschiedene erweiterte Retriever und Re-Ranker ausprobieren.
Lesen Sie auch: Erstellen Sie eine RAG-Pipeline mit dem LLama-Index
Abschluss
Das LlamaIndex-Framework bietet eine umfassende Lösung zum Erstellen robuster LLM-Anwendungen und gewährleistet effiziente Datenverarbeitung, persistente Speicherung und erweiterte Abfragefunktionen. Es ist ein wertvolles Software für Entwickler, die mit großen Sprachmodellen arbeiten. Die wichtigsten Erkenntnisse aus diesem Leitfaden zu LlamaIndex sind:
- Das LlamaIndex-Framework ermöglicht robuste Datenaufnahme-Pipelines, sorgt für eine organisierte Dokumentanalyse, Metadatenextraktion und Einbettungserstellung und verhindert gleichzeitig Duplikate.
- Durch die effektive Verwaltung von Dokument- und Vektorspeichern gewährleistet LlamaIndex die Datenkonsistenz und ermöglicht das einfache Abrufen und Speichern von Dokumenteinbettungen und Metadaten.
- Das Framework unterstützt den Aufbau von Indizes und benutzerdefinierten Abfrage-Engines und ermöglicht so einen schnellen Kontextabruf für Benutzerabfragen und kontinuierliche Interaktionen über Chat-Engines.
Häufig gestellte Fragen
A. Das LlamaIndex-Framework ist für den Aufbau robuster LLM-Anwendungen konzipiert. Es bietet Instruments für die effiziente Aufnahme, Speicherung und Abfrage von Daten und gewährleistet so die organisierte und zuverlässige Handhabung großer Sprachmodelle.
A. LlamaIndex verhindert doppelte Einbettungen, indem es Dokument- und Vektorspeicher verwendet, um vorhandene Einbettungen zu überprüfen, bevor neue erstellt werden. So wird sichergestellt, dass jedes Dokument nur einmal verarbeitet wird.
A. LlamaIndex kann verschiedene Dokumenttypen verarbeiten, indem es sie in Knoten analysiert, Metadaten extrahiert und Einbettungen erstellt, wodurch es für verschiedene Datenquellen vielseitig einsetzbar ist.
A. LlamaIndex unterstützt kontinuierliche Interaktion durch Chat-Engines, die den Chat-Verlauf speichern und nutzen und so fortlaufende, kontextbezogene Gespräche mit den Daten ermöglichen.