

Das Konzept der Diffusion
Rauschunterdrückungsdiffusionsmodelle werden trainiert, um Muster aus Rauschen herauszufiltern und ein gewünschtes Bild zu erzeugen. Der Trainingsprozess umfasst das Zeigen von Modellbeispielen von Bildern (oder anderen Daten) mit unterschiedlichen Rauschpegeln, die anhand eines Rauschplanungsalgorithmus bestimmt werden, um vorherzusagen, welche Teile der Daten Rauschen sind. Bei erfolgreichem Coaching kann das Rauschvorhersagemodell schrittweise ein realistisch aussehendes Bild aus reinem Rauschen aufbauen, indem es bei jedem Zeitschritt Rauschinkremente vom Bild abzieht.
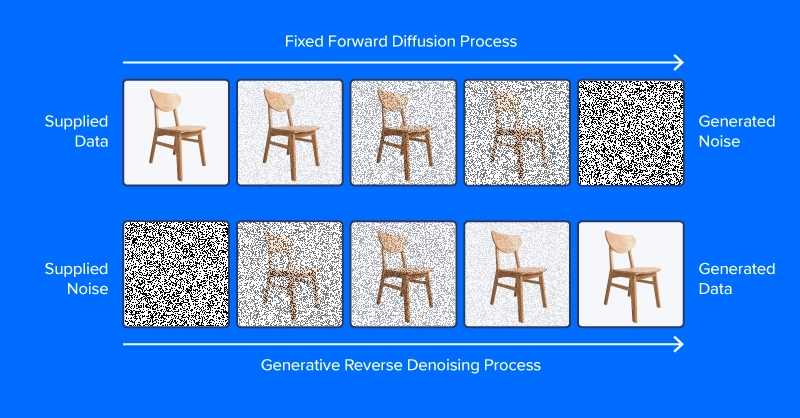
Anders als das Bild oben in diesem Abschnitt sagen moderne Diffusionsmodelle kein Rauschen aus einem Bild mit zusätzlichem Rauschen voraus, zumindest nicht direkt. Stattdessen sagen sie Rauschen in einer latenten Raumdarstellung des Bildes voraus. Der latente Raum stellt Bilder in einem komprimierten Satz numerischer Merkmale dar, der Ausgabe eines Kodierungsmoduls eines Variational Autoencoders oder VAE. Dieser Trick legte das „latente“ in latente Diffusionund reduzierte den Zeit- und Rechenaufwand für die Bilderzeugung erheblich. Wie die Autoren des Artikels berichten, beschleunigt latente Diffusion die Inferenz um mindestens das 2,7-Fache gegenüber direkter Diffusion und trainiert etwa dreimal schneller.
Wer mit latenter Diffusion arbeitet, spricht oft von der Verwendung eines „Diffusionsmodells“, aber tatsächlich umfasst der Diffusionsprozess mehrere Module. Wie im obigen Diagramm enthält eine Diffusionspipeline für Textual content-zu-Bild-Workflows normalerweise ein Texteinbettungsmodell (und seinen Tokenizer), ein Rauschprädiktions-/Diffusionsmodell und einen Bilddecoder. Ein weiterer wichtiger Teil der latenten Diffusion ist der Scheduler, der bestimmt, wie das Rauschen über eine Reihe von „Zeitschritten“ (eine Reihe iterativer Aktualisierungen, die das Rauschen schrittweise aus dem latenten Raum entfernen) skaliert und aktualisiert wird.
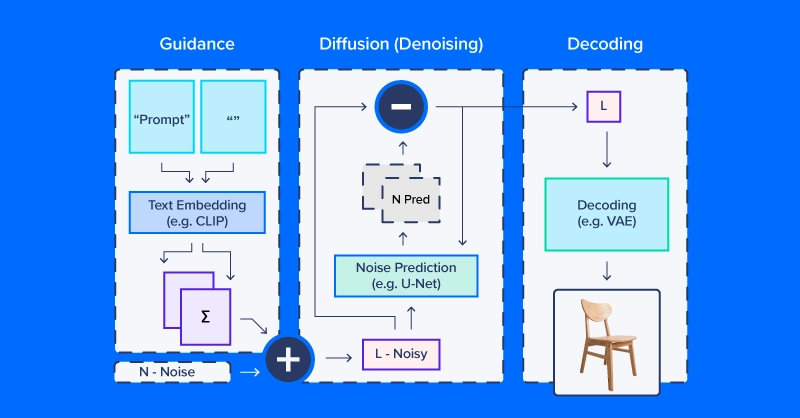
Beispiel für einen latenten Diffusionscode
Wir verwenden CompVis/latent-diffusion-v1-4 für die meisten unserer Beispiele. Die Texteinbettung übernimmt ein CLIPTextModel und CLIPTokenizer. Die Rauschvorhersage verwendet ein ‚U-Netz,‘ eine Artwork Bild-zu-Bild-Modell, das ursprünglich als Modell für Anwendungen in biomedizinischen Bildern (insbesondere Segmentierung) an Bedeutung gewann. Um Bilder aus entrauschten latenten Arrays zu erzeugen, verwendet die Pipeline einen Variational Autoencoder (VAE) zur Bilddekodierung, um diese Arrays in Bilder umzuwandeln.
Wir beginnen mit dem Erstellen unserer Model dieser Pipeline aus HuggingFace-Komponenten.
# native setup
virtualenv diff_env –python=python3.8
supply diff_env/bin/activate
pip set up diffusers transformers huggingface-hub
pip set up torch --index-url https://obtain.pytorch.org/whl/cu118Überprüfen Sie unbedingt pytorch.org um sicherzustellen, dass Sie die richtige Model für Ihr System haben, wenn Sie lokal arbeiten. Unsere Importe sind relativ unkompliziert und der folgende Codeausschnitt reicht für alle folgenden Demos aus.
import os
import numpy as np
import torch
from diffusers import StableDiffusionPipeline, AutoPipelineForImage2Image
from diffusers.pipelines.pipeline_utils import numpy_to_pil
from transformers import CLIPTokenizer, CLIPTextModel
from diffusers import AutoencoderKL, UNet2DConditionModel,
PNDMScheduler, LMSDiscreteScheduler
from PIL import Picture
import matplotlib.pyplot as pltNun zu den Particulars. Beginnen Sie mit der Definition der Bild- und Diffusionsparameter und einer Eingabeaufforderung.
immediate = (" ")
# picture settings
top, width = 512, 512
# diffusion settings
number_inference_steps = 64
guidance_scale = 9.0
batch_size = 1Initialisieren Sie Ihren Pseudozufallszahlengenerator mit einem Startwert Ihrer Wahl, um Ihre Ergebnisse zu reproduzieren.
def seed_all(seed):
torch.manual_seed(seed)
np.random.seed(seed)
seed_all(193)Jetzt können wir das Texteinbettungsmodell, den Autoencoder, ein U-Web und den Zeitschrittplaner initialisieren.
tokenizer = CLIPTokenizer.from_pretrained("openai/clip-vit-large-patch14")
text_encoder = CLIPTextModel.from_pretrained("openai/clip-vit-large-patch14")
vae = AutoencoderKL.from_pretrained("CompVis/stable-diffusion-v1-4",
subfolder="vae")
unet = UNet2DConditionModel.from_pretrained("CompVis/stable-diffusion-v1-4",
subfolder="unet")
scheduler = PNDMScheduler()
scheduler.set_timesteps(number_inference_steps)
my_device = torch.gadget("cuda") if torch.cuda.is_available() else torch.gadget("cpu")
vae = vae.to(my_device)
text_encoder = text_encoder.to(my_device)
unet = unet.to(my_device)Um die Texteingabe als Einbettung zu kodieren, muss zunächst die Zeichenfolge tokenisiert werden. Bei der Tokenisierung werden Zeichen durch ganzzahlige Codes ersetzt, die einem Vokabular semantischer Einheiten entsprechen, z. B. durch Bytepaarkodierung (BPE). Unsere Pipeline bettet neben der Textaufforderung für unser Bild eine Null-Eingabeaufforderung (kein Textual content) ein. Dies gleicht den Diffusionsprozess zwischen der bereitgestellten Beschreibung und natürlich wirkenden Bildern im Allgemeinen aus. Später in diesem Artikel erfahren Sie, wie Sie die relative Gewichtung dieser Komponenten ändern können.
immediate = immediate * batch_size
tokens = tokenizer(immediate, padding="max_length",
max_length=tokenizer.model_max_length, truncation=True,
return_tensors="pt")
empty_tokens = tokenizer(("") * batch_size, padding="max_length",
max_length=tokenizer.model_max_length, truncation=True,
return_tensors="pt")
with torch.no_grad():
text_embeddings = text_encoder(tokens.input_ids.to(my_device))(0)
max_length = tokens.input_ids.form(-1)
notext_embeddings = text_encoder(empty_tokens.input_ids.to(my_device))(0)
text_embeddings = torch.cat((notext_embeddings, text_embeddings))Wir initialisieren den latenten Raum als zufälliges normales Rauschen und skalieren ihn entsprechend unserem Diffusionszeitschrittplaner.
latents = torch.randn(batch_size, unet.config.in_channels,
top//8, width//8)
latents = (latents * scheduler.init_noise_sigma).to(my_device)Alles ist startklar und wir können in die Diffusionsschleife selbst eintauchen. Wir können die Bilder verfolgen, indem wir in regelmäßigen Abständen Proben entnehmen, damit wir sehen können, wie das Rauschen allmählich abnimmt.
pictures = ()
display_every = number_inference_steps // 8
# diffusion loop
for step_idx, timestep in enumerate(scheduler.timesteps):
with torch.no_grad():
# concatenate latents, to run null/textual content immediate in parallel.
model_in = torch.cat((latents) * 2)
model_in = scheduler.scale_model_input(model_in,
timestep).to(my_device)
predicted_noise = unet(model_in, timestep,
encoder_hidden_states=text_embeddings).pattern
# pnu - empty immediate unconditioned noise prediction
# pnc - textual content immediate conditioned noise prediction
pnu, pnc = predicted_noise.chunk(2)
# weight noise predictions based on steering scale
predicted_noise = pnu + guidance_scale * (pnc - pnu)
# replace the latents
latents = scheduler.step(predicted_noise,
timestep, latents).prev_sample
# Periodically log pictures and print progress throughout diffusion
if step_idx % display_every == 0
or step_idx + 1 == len(scheduler.timesteps):
picture = vae.decode(latents / 0.18215).pattern(0)
picture = ((picture / 2.) + 0.5).cpu().permute(1,2,0).numpy()
picture = np.clip(picture, 0, 1.0)
pictures.lengthen(numpy_to_pil(picture))
print(f"step {step_idx}/{number_inference_steps}: {timestep:.4f}")Am Ende des Diffusionsprozesses haben wir ein ordentliches Rendering dessen, was Sie erzeugen wollten. Als Nächstes werden wir zusätzliche Techniken für eine bessere Kontrolle durchgehen. Da wir unsere Diffusionspipeline bereits erstellt haben, können wir für den Relaxation unserer Beispiele die optimierte Diffusionspipeline von HuggingFace verwenden.
Steuerung der Diffusionspipeline
Wir verwenden in diesem Abschnitt eine Reihe von Hilfsfunktionen:
def seed_all(seed):
torch.manual_seed(seed)
np.random.seed(seed)
def grid_show(pictures, rows=3):
number_images = len(pictures)
top, width = pictures(0).measurement
columns = int(np.ceil(number_images / rows))
grid = np.zeros((top*rows,width*columns,3))
for ii, picture in enumerate(pictures):
grid(ii//columns*top:ii//columns*top+top,
iipercentcolumns*width:iipercentcolumns*width+width) = picture
fig, ax = plt.subplots(1,1, figsize=(3*columns, 3*rows))
ax.imshow(grid / grid.max())
return grid, fig, ax
def callback_stash_latents(ii, tt, latents):
# tailored from fastai/diffusion-nbs/stable_diffusion.ipynb
latents = 1.0 / 0.18215 * latents
picture = pipe.vae.decode(latents).pattern(0)
picture = (picture / 2. + 0.5).cpu().permute(1,2,0).numpy()
picture = np.clip(picture, 0, 1.0)
pictures.lengthen(pipe.numpy_to_pil(picture))
my_seed = 193Wir beginnen mit der bekanntesten und einfachsten Anwendung von Diffusionsmodellen: der Bildgenerierung aus Textaufforderungen, bekannt als Textual content-zu-Bild-Generierung. Das Modell, das wir verwenden, wurde von der akademischen Labor, das das Papier zur latenten Diffusion veröffentlicht hat. Hugging Face koordiniert Arbeitsabläufe wie die latente Diffusion über die praktische Pipeline-API. Wir möchten definieren, welches Gerät und welcher Gleitkommawert berechnet werden soll, basierend darauf, ob wir eine GPU haben oder nicht.
if (1):
#Run CompVis/stable-diffusion-v1-4 on GPU
pipe_name = "CompVis/stable-diffusion-v1-4"
my_dtype = torch.float16
my_device = torch.gadget("cuda")
my_variant = "fp16"
pipe = StableDiffusionPipeline.from_pretrained(pipe_name,
safety_checker=None, variant=my_variant,
torch_dtype=my_dtype).to(my_device)
else:
#Run CompVis/stable-diffusion-v1-4 on CPU
pipe_name = "CompVis/stable-diffusion-v1-4"
my_dtype = torch.float32
my_device = torch.gadget("cpu")
pipe = StableDiffusionPipeline.from_pretrained(pipe_name,
torch_dtype=my_dtype).to(my_device)Orientierungsskala
Wenn Sie eine sehr ungewöhnliche Texteingabeaufforderung verwenden (die sich stark von denen im Datensatz unterscheidet), kann es passieren, dass Sie in einem weniger frequentierten Teil des latenten Raums landen. Die Einbettung der Nulleingabeaufforderung sorgt für einen Ausgleich und die Kombination der beiden gemäß Guidance_Scale ermöglicht es Ihnen, die Spezifität Ihrer Eingabeaufforderung gegen allgemeine Bildmerkmale abzuwägen.
guidance_images = ()
for steering in (0.25, 0.5, 1.0, 2.0, 4.0, 6.0, 8.0, 10.0, 20.0):
seed_all(my_seed)
my_output = pipe(my_prompt, num_inference_steps=50,
num_images_per_prompt=1, guidance_scale=steering)
guidance_images.append(my_output.pictures(0))
for ii, img in enumerate(my_output.pictures):
img.save(f"prompt_{my_seed}_g{int(steering*2)}_{ii}.jpg")
temp = grid_show(guidance_images, rows=3)
plt.savefig("prompt_guidance.jpg")
plt.present()Da wir die Eingabeaufforderung mithilfe der 9 Leitkoeffizienten generiert haben, können Sie die Eingabeaufforderung grafisch darstellen und die Entwicklung der Diffusion verfolgen. Der Standardleitkoeffizient beträgt 0,75, daher wäre das 7. Bild die Standardbildausgabe.
Damaging Eingabeaufforderungen
Manchmal „will“ die latente Diffusion wirklich ein Bild erzeugen, das nicht Ihren Absichten entspricht. In diesen Szenarien können Sie einen negativen Immediate verwenden, um den Diffusionsprozess von unerwünschten Ergebnissen wegzudrängen. Wir könnten zum Beispiel einen negativen Immediate verwenden, um die Diffusionsergebnisse unserer Mars-Astronauten etwas weniger menschlich zu gestalten.
my_prompt = " "
my_negative_prompt = " "
output_x = pipe(my_prompt, num_inference_steps=50, num_images_per_prompt=9,
negative_prompt=my_negative_prompt)
temp = grid_show(output_x)
plt.present()Sie sollten Ausgaben erhalten, die Ihrer Eingabeaufforderung folgen, und gleichzeitig die Ausgabe der in Ihrer negativen Eingabeaufforderung beschriebenen Dinge vermeiden.
Bildvariation
Die Generierung von Textual content zu Bild von Grund auf ist nicht die einzige Anwendung für Diffusionspipelines. Tatsächlich eignet sich Diffusion intestine zur Bildmodifikation, ausgehend von einem Ausgangsbild. Wir verwenden eine etwas andere Pipeline und ein vorab trainiertes Modell, das auf Bild-zu-Bild-Diffusion abgestimmt ist.
pipe_img2img = AutoPipelineForImage2Image.from_pretrained(
"runwayml/stable-diffusion-v1-5", safety_checker=None,
torch_dtype=my_dtype, use_safetensors=True).to(my_device)Eine Anwendung dieses Ansatzes besteht darin, Variationen zu einem Thema zu erzeugen. Ein Konzeptkünstler könnte diese Technik verwenden, um schnell verschiedene Ideen für die Illustration eines Exoplaneten auf der Grundlage der neuesten Forschung zu iterieren.
Wir laden zunächst das Konzept eines gemeinfreien Künstlers für Planet 1e im TRAPPIST-System herunter (Quelle: NASA/JPL-Caltech).
Anschließend verwenden wir nach der Herunterskalierung zum Entfernen von Particulars eine Diffusionspipeline, um mehrere unterschiedliche Versionen des Exoplaneten TRAPPIST-1e zu erstellen.
url =
"https://add.wikimedia.org/wikipedia/commons/thumb/3/38/TRAPPIST-1e_artist_impression_2018.png/600px-TRAPPIST-1e_artist_impression_2018.png"
img_path = url.cut up("https://www.kdnuggets.com/")(-1)
if not (os.path.exists("600px-TRAPPIST-1e_artist_impression_2018.png")):
os.system(f"wget '{url}'")
init_image = Picture.open(img_path)
seed_all(my_seed)
trappist_prompt = "Artist's impression of TRAPPIST-1e"
"giant Earth-like water-world exoplanet with oceans,"
"NASA, artist idea, practical, detailed, intricate"
my_negative_prompt = "cartoon, sketch, orbiting moon"
my_output_trappist1e = pipe_img2img(immediate=trappist_prompt, num_images_per_prompt=9,
picture=init_image, negative_prompt=my_negative_prompt, guidance_scale=6.0)
grid_show(my_output_trappist1e.pictures)
plt.present()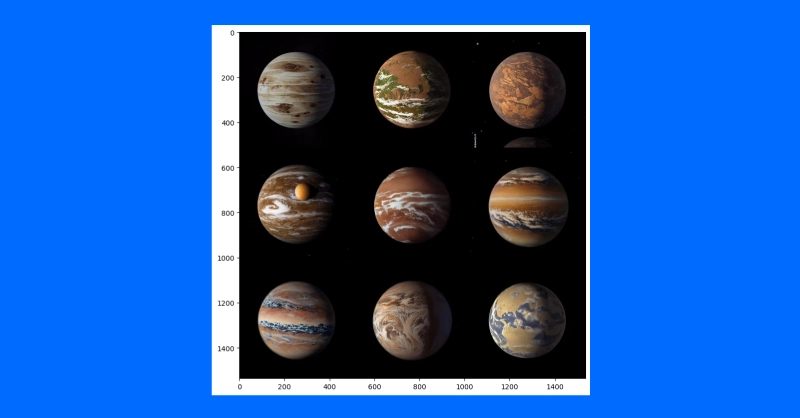
Indem wir dem Modell ein Beispielbild zuführen, können wir ähnliche Bilder erzeugen. Sie können auch eine textgesteuerte Bild-zu-Bild-Pipeline verwenden, um den Stil eines Bildes zu ändern, indem Sie die Anleitung erweitern, destructive Eingabeaufforderungen und mehr hinzufügen, wie z. B. „nicht realistisch“ oder „Aquarell“ oder „Papierskizze“. Ihre Vorgehensweise kann unterschiedlich sein und die Anpassung Ihrer Eingabeaufforderungen ist der einfachste Weg, das richtige Bild zu finden, das Sie erstellen möchten.
Schlussfolgerungen
Trotz des Diskurses über Diffusionssysteme und die Nachahmung von menschengemachter Kunst haben Diffusionsmodelle andere, wirkungsvollere Zwecke. Es hat gewesen angewendet Vorhersage der Proteinfaltung für Proteindesign und Arzneimittelentwicklung. Textual content-to-Video ist auch ein Aktive Fläche von Forschung und wird von mehreren Unternehmen angeboten (zB Stabilitäts-KI, Google). Diffusion ist auch ein neuer Ansatz für Textual content zu Sprache Anwendungen.
Es ist klar, dass der Diffusionsprozess eine zentrale Rolle bei der Entwicklung der KI und der Interaktion der Technologie mit der globalen menschlichen Umwelt spielt. Die Feinheiten des Urheberrechts, anderer Gesetze zum geistigen Eigentum und die Auswirkungen auf die menschliche Kunst und Wissenschaft sind sowohl positiv als auch negativ erkennbar. Was jedoch wirklich positiv ist, ist die beispiellose Fähigkeit der KI, Sprache zu verstehen und Bilder zu erzeugen. Es warfare AlexNet, das Laptop ein Bild analysieren und Textual content ausgeben ließ, und erst jetzt können Laptop Texteingaben analysieren und zusammenhängende Bilder ausgeben.
Unique. Mit Genehmigung erneut veröffentlicht.
Kevin Vu verwaltet Weblog von Exxact Corp und arbeitet mit vielen seiner talentierten Autoren zusammen, die über verschiedene Aspekte des Deep Studying schreiben.