Klimamodelle sind eine Schlüsseltechnologie zur Vorhersage der Auswirkungen des Klimawandels. Durch Simulationen des Erdklimas können Wissenschaftler und politische Entscheidungsträger Bedingungen wie den Anstieg des Meeresspiegels, Überschwemmungen und steigende Temperaturen abschätzen und Entscheidungen über angemessene Reaktionen treffen. Aktuelle Klimamodelle haben jedoch Schwierigkeiten, diese Informationen schnell oder kostengünstig genug bereitzustellen, um auf kleineren Skalen, wie etwa der Größe einer Stadt, nützlich zu sein.
Nun, Autoren einer neuer Open-Entry-Artikel veröffentlicht im Zeitschrift für Fortschritte in der Modellierung von Erdsystemen haben eine Methode gefunden, mit der sich die Vorteile aktueller Klimamodelle durch maschinelles Lernen nutzen lassen, während gleichzeitig der für deren Ausführung erforderliche Rechenaufwand reduziert wird.
„Es stellt die traditionelle Weisheit auf den Kopf“, sagt Sai Ravela, ein leitender Forschungswissenschaftler in der Abteilung für Erd-, Atmosphären- und Planetenwissenschaften (EAPS) des MIT, der das Papier zusammen mit der EAPS-Postdoktorandin Anamitra Saha verfasst hat.
Traditionelle Weisheit
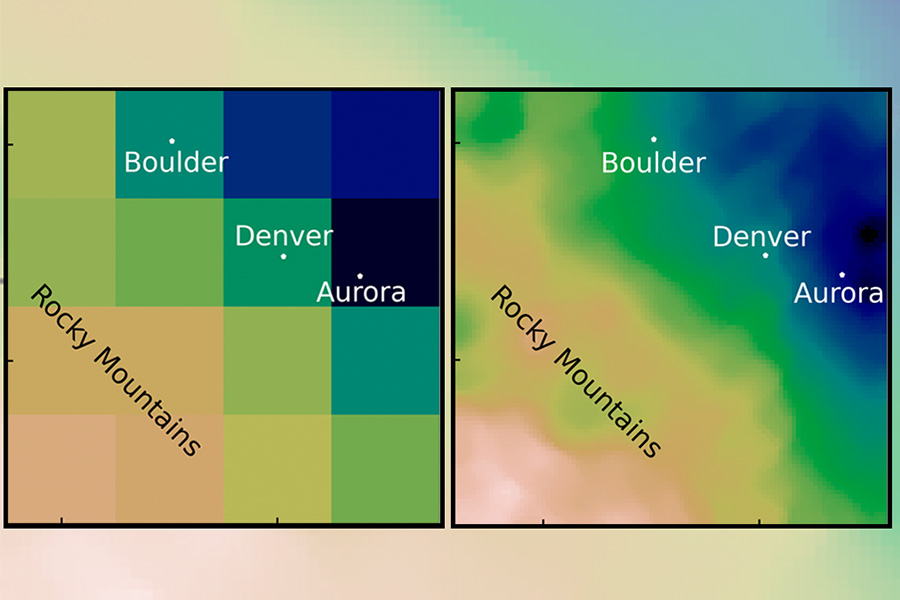
In der Klimamodellierung ist Downscaling der Prozess, bei dem ein globales Klimamodell mit grober Auflösung verwendet wird, um feinere Particulars über kleinere Regionen zu erzeugen. Stellen Sie sich ein digitales Bild vor: Ein globales Modell ist ein großes Bild der Welt mit einer geringen Anzahl von Pixeln. Um es herunterzuskalieren, zoomen Sie nur auf den Teil des Fotos, den Sie betrachten möchten – zum Beispiel Boston. Aber weil das Originalbild eine niedrige Auflösung hatte, ist die neue Model unscharf; sie bietet nicht genug Particulars, um besonders nützlich zu sein.
„Wenn man von einer groben zu einer feinen Auflösung übergeht, muss man irgendwie Informationen hinzufügen“, erklärt Saha. Beim Downscaling wird versucht, diese Informationen wieder hinzuzufügen, indem die fehlenden Pixel ergänzt werden. „Das Hinzufügen von Informationen kann auf zwei Arten erfolgen: Entweder kann es aus der Theorie kommen, oder es kann aus Daten stammen.“
Beim herkömmlichen Downscaling werden häufig physikalische Modelle verwendet (wie etwa der Prozess des Aufsteigens, Abkühlens und Kondensierens von Luft oder die Landschaft eines Gebiets) und mit statistischen Daten aus historischen Beobachtungen ergänzt. Diese Methode ist jedoch sehr rechenintensiv: Sie erfordert viel Zeit und Rechenleistung und ist zudem teuer.
Ein bisschen von beidem
In ihrem neuen Artikel haben Saha und Ravela einen Weg gefunden, die Daten auf andere Weise hinzuzufügen. Sie haben eine Technik des maschinellen Lernens verwendet, die als Adversarial Studying bezeichnet wird. Dabei kommen zwei Maschinen zum Einsatz: Eine generiert Daten, die in unser Foto einfließen. Die andere Maschine beurteilt die Probe, indem sie sie mit tatsächlichen Daten vergleicht. Wenn sie das Bild für gefälscht hält, muss die erste Maschine es erneut versuchen, bis sie die zweite Maschine überzeugt hat. Das Endziel des Prozesses ist die Erstellung von Daten mit Superauflösung.
Der Einsatz von maschinellen Lerntechniken wie Adversarial Studying ist in der Klimamodellierung keine neue Idee. Derzeit hapert es jedoch daran, dass große Mengen grundlegender physikalischer Gesetze wie Erhaltungssätze nicht verarbeitet werden können. Die Forscher fanden heraus, dass es ausreichte, die physikalischen Grundlagen zu vereinfachen und sie mit Statistiken aus den historischen Daten zu ergänzen, um die gewünschten Ergebnisse zu erzielen.
„Wenn man das maschinelle Lernen mit einigen Informationen aus der Statistik und vereinfachter Physik ergänzt, ist es plötzlich magisch“, sagt Ravela. Er und Saha begannen mit der Schätzung extremer Niederschlagsmengen, indem sie komplexere physikalische Gleichungen entfernten und sich auf Wasserdampf und Landtopographie konzentrierten. Dann erstellten sie allgemeine Niederschlagsmuster für das bergige Denver und das flache Chicago und wendeten historische Berechnungen an, um die Ergebnisse zu korrigieren. „So erhalten wir Excessive, genau wie die Physik, zu einem viel geringeren Preis. Und wir erhalten ähnliche Geschwindigkeiten wie die Statistik, aber mit einer viel höheren Auflösung.“
Ein weiterer unerwarteter Vorteil der Ergebnisse conflict, dass nur so wenige Trainingsdaten benötigt wurden. „Die Tatsache, dass nur ein bisschen Physik und ein bisschen Statistik ausreichten, um die Leistung des ML-Modells (Maschinelles Lernen) zu verbessern … conflict eigentlich nicht von Anfang an offensichtlich“, sagt Saha. Das Coaching dauert nur wenige Stunden und kann innerhalb von Minuten Ergebnisse liefern – eine Verbesserung gegenüber den Monaten, die andere Modelle zum Ausführen benötigen.
Risiken schnell quantifizieren
Die Fähigkeit, die Modelle schnell und häufig auszuführen, ist eine wichtige Voraussetzung für Interessengruppen wie Versicherungsunternehmen und lokale politische Entscheidungsträger. Ravela nennt das Beispiel Bangladesch: Wenn man sieht, wie sich excessive Wetterereignisse auf das Land auswirken, kann man unter Berücksichtigung einer sehr großen Bandbreite von Bedingungen und Unsicherheiten so schnell wie möglich Entscheidungen darüber treffen, welche Nutzpflanzen angebaut werden sollten oder wohin die Bevölkerung auswandern sollte.
„Wir können nicht Monate oder Jahre warten, um dieses Risiko quantifizieren zu können“, sagt er. „Man muss weit in die Zukunft blicken und eine große Anzahl an Unsicherheiten berücksichtigen, um sagen zu können, was eine gute Entscheidung sein könnte.“
Während das aktuelle Modell nur excessive Niederschläge berücksichtigt, ist der nächste Schritt des Projekts, es auf die Untersuchung anderer kritischer Ereignisse wie tropische Stürme, Winde und Temperaturen zu trainieren. Mit einem robusteren Modell hofft Ravela, es im Rahmen eines Local weather Grand Challenges-Projekt.
„Wir sind sowohl von der Methodik, die wir entwickelt haben, als auch von den potenziellen Anwendungen, die sie ermöglichen könnte, sehr begeistert“, sagt er.