
Wenn Sie auch nur ein wenig von KI-Sprachmodellen besessen sind, sollten Sie sich Qwen3-TTS-Flash nicht entgehen lassen. Es handelt sich um das neue Flaggschiff-Textual content-to-Speech-System von Qwen, das für die Erzeugung natürlicher, ausdrucksstarker und menschenähnlicher Sprache in über 49 Lauten, 10 Sprachen und 9 chinesischen Dialekten entwickelt wurde. Dieses Modell richtet sich an Kreative, Entwickler, Pädagogen und alle, die Stimmen in Studioqualität wünschen, ohne Synchronsprecher einzustellen oder teure Instruments zu kaufen.
Und das Beste daran? Sie können es direkt über die Qwen-API verwenden.
In diesem Artikel erkläre ich, was das Modell besonders macht, warum diese Updates wichtig sind und wie Sie es nutzen können.
Was ist neu in Qwen3-TTS Flash?
Qwen3-TTS-Flash ist ein Flaggschiff-Textual content-to-Speech-Modell, das als Teil der Qwen3-Serie veröffentlicht wurde. Der Schwerpunkt liegt auf der natürlichen, ausdrucksstarken und mehrsprachigen Stimmerzeugung. Das Modell unterstützt die Synthese mehrerer Klangfarben, mehrerer Sprachen und mehrerer Dialekte, was bedeutet, dass Sie mit demselben Modell Sprache in verschiedenen Stilen, Akzenten und Sprachen erzeugen können.
Im Gegensatz zu älteren TTS-Systemen liest Qwen3-TTS-Flash nicht nur den Textual content. Es versteht Ton, Tempo, Emotionen, Persönlichkeit und Absicht. Die Ergebnisse klingen ruhig, dramatisch, unbeschwert, kindisch, gebieterisch, heat oder verspielt. Es reagiert sowohl auf den Inhalt des Textes als auch auf den gewünschten Stil.
Über 49 hochwertige Sounds
Das erste, was Qwen3-TTS-Flash auszeichnet, ist die Vielfalt der Stimmen. Das Modell unterstützt 49 ausdrucksstarke Klangfarben. Das sind keine einfachen Stimmen. Sie sind ausgereifte Charakterpersönlichkeiten mit emotionaler Bandbreite und Identität.
Sie erhalten sanfte Gesprächsstimmen, tiefe, reife Stimmen, kindliche Töne, Charaktere im Anime-Stil, herzliche Erzähler, strenge Lehrer, freundliche Begleiter und mehr. Dies macht es nützlich für Lern-Apps, Podcasts, Spielfiguren, Markenvideos, Storytelling und virtuelle Assistenten.
Einige Beispiele sind:
- Momo, der energisch und verspielt klingt
- Ono Anna, die freundlich und heat klingt
- Vivian, die einen stolzen, selbstbewussten Ton hat
- Eldric Sage, der älter und weiser klingt
- Bunny, der süß und ausdrucksstark klingt
- Elias, der streng und förmlich spricht
Jede Stimme trägt Persönlichkeit in sich. Sie können die Unterschiede in Einstellung, Alter und Energie spüren. Viele andere TTS-Modelle klingen, als würden sie dieselbe Basisstimme mit unterschiedlichen Filtern verwenden. Qwen3-TTS-Flash erstellt tatsächlich Charaktere.
Lesen Sie auch: Die 9 besten Open-Supply-Textual content-to-Speech-Modelle (TTS).
Echte mehrsprachige Sprachsynthese
Qwen3 TTS Flash funktioniert in 10 Hauptsprachen. Dazu gehören Chinesisch, Englisch, Deutsch, Italienisch, Portugiesisch, Spanisch, Japanisch, Koreanisch, Französisch und Russisch. Das Modell schneidet bei Genauigkeitstests intestine ab. Es erreicht eine niedrigere Wortfehlerrate als Systeme wie MiniMax, ElevenLabs und GPT 4o Audio Preview. Dies ist ein großer Vorteil für Groups, die globale Inhalte oder Produkte erstellen.
Dialekte
Dieses Modell beherrscht nicht nur Sprachen, es beherrscht auch Dialekte wunderbar.
Es unterstützt:
- Mandarin
- Kantonesisch
- Hokkien
- Sichuanesisch
- Shaanxi
- Wu
- Peking
- Tianjin
- Nanjing
Regionale Sprache wird mit korrektem Ton, Rhythmus, Kadenz, Umgangssprache und dem Charme nachgebildet, der bei generischen TTS-Modellen normalerweise verloren geht.
Bessere Kontrolle der Sprechgeschwindigkeit
Frühere TTS-Modelle hatten oft Probleme mit der Prosodie, was dazu führte, dass sich die Stimmen mechanisch oder zu flach anfühlten. Qwen3-TTS-Flash macht einen großen Schritt nach vorne, indem es dies deutlich verbessert. Anstatt Textual content in einem einheitlichen Rhythmus zu lesen, passt das Modell Ton und Tempo je nach Bedeutung an. Pausen entstehen ganz natürlich in Momenten, in denen ein menschlicher Sprecher innehalten würde. Emotionale Abschnitte werden subtil betont und das Modell ändert die Geschwindigkeit je nach Stimmung des Satzes.
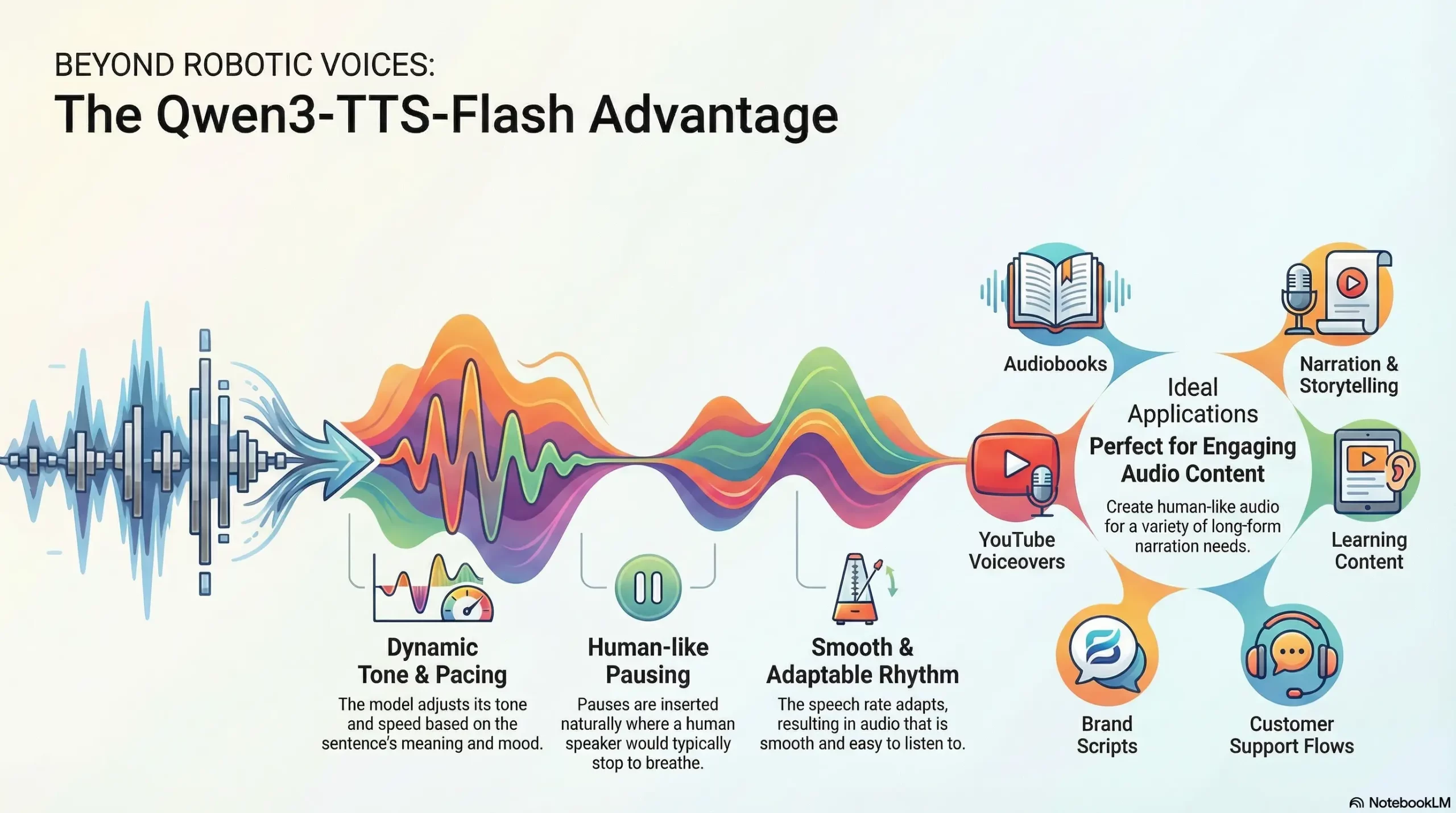
Der Rhythmus fühlt sich natürlich an. Die Sprechgeschwindigkeit passt sich an. Die Ausgabe ist flüssig und leicht anzuhören.
Wie greife ich auf das Qwen TTS-Modell zu?
Abhängig von Ihrem Arbeitsablauf können Sie auf zwei Arten auf Qwen3-TTS zugreifen:
Verwendung der Qwen-API
Dies ist die offizielle und zuverlässigste Methode.
Sie benötigen lediglich:
- Ein DashScope-API-Schlüssel von der Alibaba Cloud-Plattform
- Das DashScope Python SDK
Beispielcode:
import os
import requests
import dashscope
textual content = "Let me advocate a T shirt to everybody. This one is basically good wanting and the colour is stylish."
response = dashscope.MultiModalConversation.name(
mannequin="qwen3-tts-flash-2025-11-27",
api_key=os.getenv("DASHSCOPE_API_KEY"),
textual content=textual content,
voice="Ryan",
language_type="English",
stream=False
)
audio_url = response.output.audio.url
save_path = "audio.wav"
strive:
r = requests.get(audio_url)
r.raise_for_status()
with open(save_path, 'wb') as f:
f.write(r.content material)
print("Saved to", save_path)
besides Exception as e:
print("Error:", str(e))
Hugging Face verwenden (kostenlose Testversion)
Qwen bietet eine kostenlose Demo zu Hugging Face Areas an, in der Sie:
- Textual content einfügen
- Wählen Sie eine Stimme aus
- Hören Sie sich das generierte Audio an oder laden Sie es herunter
Diese Model eignet sich intestine zum Testen, aber die kostenpflichtige API bietet eine viel höhere Wiedergabetreue, eine stabilere Prosodie und eine schnellere Generierung. Klicken Sie hier, um es auszuprobieren!
Probieren wir es aus!
Um zu verstehen, wie sich Qwen3-TTS-Flash in realen Szenarien verhält, habe ich es mit drei verschiedenen Skripten und drei verschiedenen Stimmen getestet. Jede Aufgabe zielt auf einen einzigartigen Sprechstil ab: Werbung, Erzählung und professionelle Berufsberatung. Hier ist, was ich gefunden habe.
Aufgabe 1: Werbeskript (Stimme: Vivian, Sprache: Englisch)
Verwendetes Skript:
Hören Sie für eine Sekunde auf zu scrollen. Wenn Sie das hören, müssen Sie aufhören, für teure KI-Bootcamps zu bezahlen.
Analytics Vidhya hat eine riesige Bibliothek mit kostenlosen Kursen geöffnet, die Sie sehen müssen. Ich spreche von vollständigen Lehrplänen zu Python und SQL sowie von hochmodernen Technologien wie generativer KI, RAG-Systemen und KI-Agenten.
Warum es tun? Da es sich um praxisorientiertes Programmieren handelt, ist es absolut auf dem neuesten Stand, und ja – Sie erhalten kostenlose Zertifikate für Ihren Lebenslauf.
Dies ist Ihr Karriere-Cheat-Code. Gehen Sie jetzt zu Analytics Vidhya dot com und beginnen Sie noch heute mit dem Aufbau Ihrer Zukunft.
Ausgabe:
Meine Rezension
Vivians Timbre kam mit diesem Drehbuch im Promo-Stil hervorragend zurecht. Die Energie conflict klar, ohne übertrieben zu klingen. Das Modell behielt ein gleichmäßiges Tempo bei, betonte die richtigen Formulierungen und lieferte einen überzeugenden Name-to-Motion. Die Aussprache conflict klar und die Übergänge zwischen den Sätzen fühlten sich natürlich an. Diese Ausgabe ist stark genug für Marketingvideos, Instagram-Reels oder YouTube-Anzeigen, ohne dass eine zusätzliche Bearbeitung erforderlich ist.
Aufgabe 2: Narratives + reflektierendes Drehbuch (Stimme: Chelsie, Sprache: Englisch)
Verwendetes Skript:
Stellen Sie sich vor, Sie wachen in einer Welt auf, in der sich Ihr Zeitplan einfach von selbst verwaltet. Keine störenden Alarme mehr, nur ein sanfter Anstieg der Beleuchtung, um Ihren Tag zu beginnen.
In der modernen Zeit ist künstliche Intelligenz nicht nur ein Schlagwort; es ist in den Stoff unseres täglichen Lebens eingewebt. Von der Organisation komplexer Daten mit 5G-Geschwindigkeit bis hin zum Fahren autonomer Fahrzeuge ist Automatisierung der neue Commonplace.
Aber die wichtige Frage bleibt: Bringt uns diese Technologie näher zusammen oder treibt sie uns weiter auseinander? Es ist an der Zeit, die Artwork und Weise zu überdenken, wie wir uns im digitalen Zeitalter vernetzen. Willkommen zum nächsten Kapitel.
Ausgabe:
Meine Rezension:
Chelsie hat den nachdenklichen Ton wunderbar gemeistert. Die Stimme vermittelte emotionale Wärme, perfekt für Storytelling, Produktdemos oder Movies im Dokumentarfilmstil. Das Tempo wurde in den richtigen Momenten verlangsamt, was dem Drehbuch ein nachdenkliches und filmisches Gefühl verlieh. Die Pausen und Stressmuster klangen sehr menschlich, ohne Roboterartefakte. Dies ist best für Erzählungen oder das Erzählen von Markengeschichten.
Aufgabe 3: Karriereorientiertes Drehbuch (Stimme: Ryan, Sprache: Englisch)
Verwendetes Skript:
Generative KI ist nicht nur ein Schlagwort; Es ist der am schnellsten wachsende Karriereweg in der Technologiegeschichte.
Reden wir über Zahlen. Die Nachfrage nach GenAI-Ingenieuren ist explodiert, aber der Talentpool ist nahezu leer. Aus diesem Grund zahlen Unternehmen enorme Prämien – spezialisierte Stellen verdienen locker einhundertfünfzigtausend Greenback professional Jahr.
Vom Finanzwesen bis zum Gesundheitswesen ist jede Branche verzweifelt daran interessiert, LLMs und Agenten zu integrieren. Wenn Sie eine Karriere suchen, die zukunftssichere Sicherheit und Hebelwirkung bietet, dann ist dies das Richtige für Sie.
Der beste Zeitpunkt für einen Wechsel conflict gestern. Der zweitbeste Zeitpunkt ist jetzt. Beginnen Sie mit dem Bau.
Ausgabe:
Meine Rezension:
Ryans Stimme lieferte einen starken, professionellen Ton mit genau dem richtigen Maß an Autorität. Das Modell betonte effektiv berufsorientierte Formulierungen und sorgte gleichzeitig für eine reibungslose, sichere Übermittlung. Diese Ausgabe klingt wie etwas, das direkt aus einem modernen Tech-Erklärer oder einem LinkedIn-Lernmodul stammt. Keine spürbaren Verzerrungen oder Geschwindigkeitsprobleme, sodass es für Podcast-Intros, Berufsberatungsvideos oder Tech-Werbung geeignet ist.
Leistung und praktischer Wert
Das Modell ist schnell, ausdrucksstark und zuverlässig. Es erzeugt eine natürliche Sprache mit starker Klarheit. Es unterstützt lange Texte und funktioniert intestine in Anwendungen. Aufgrund der geringen Wortfehlerrate eignet es sich für professionelle Audio-Anwendungsfälle.
Da es über eine API erfolgt, können Entwickler es integrieren in:
- Cell Apps
- Internet-Apps
- Lernplattformen
- Spiele
- Chatbots
- Kundensupportströme
- Sprachagenten
- Videoskripte
Es ist eines der wenigen TTS-Modelle, das Maßstab, Ausdruck, mehrsprachige Ausgabe und Charakterstimmen in einem einzigen Paket vereint.
Lesen Sie auch:
Abschluss
Qwen3-TTS-Flash ist eines der leistungsfähigsten mehrsprachigen TTS-Systeme, die derzeit verfügbar sind. Mit seiner riesigen Klangfarbenbibliothek, der natürlichen Prosodie, der starken Dialektunterstützung und der schnellen Generierung ist es sowohl für den täglichen Einsatz als auch für den Einsatz in großen Unternehmen konzipiert. Egal, ob Sie ein Video kommentieren, einen Voicebot erstellen oder Charakterdialoge erstellen, dieses Modell ist leistungsstark, flexibel und über die API äußerst einfach zu verwenden.
Hallo, ich bin Nitika, eine technisch versierte Content material-Erstellerin und Vermarkterin. Kreativität und das Lernen neuer Dinge sind für mich selbstverständlich. Ich habe Erfahrung in der Erstellung ergebnisorientierter Content material-Strategien. Ich kenne mich intestine mit Website positioning-Administration, Key phrase-Operationen, Internet-Content material-Schreiben, Kommunikation, Content material-Strategie, Redaktion und Schreiben aus.
Melden Sie sich an, um weiterzulesen und von Experten kuratierte Inhalte zu genießen.