
Am 3. Juni 2026 stellte Google Gemma 4 12B Unified vor, ein multimodales Open-Supply-Modell, das Textual content, Bilder, Audio und Video innerhalb einer einzigen Architektur verstehen soll. Es vereint a 256K Kontextfenster mit einem effizienten, Laptop computer-freundlichen Design, das auf Agenten-Workflows und lokale Bereitstellung ausgerichtet ist.
Die Veröffentlichung wirft auch interessante Fragen zur umfassenderen KI-Strategie von Google auf, insbesondere zur Kluft zwischen den Modellen, die in öffentlichen APIs hervorgehoben werden, und denen, die durch Open-Supply-Instruments allgemein verfügbar gemacht werden. In diesem Artikel untersuchen wir die Architektur und Funktionen von Gemma 4 12B Unified und was seine Veröffentlichung für Entwickler bedeutet.
Was ist Gemma 4 12B?
Gemma 4 12B Unified ist Google DeepMinds mittelgroßes Open-Supply-Modell in der Gemma 4-Familie. Google beschreibt es als ein dichtes multimodales Modell, das entwickelt wurde, um agentische multimodale Intelligenz direkt auf Laptops zu bringen. Es schließt die Lücke zwischen dem kleineren Edge-Modell Gemma 4 E4B und dem größeren Gemma 4 26B A4B Combination-of-Consultants-Modell.
Die öffentliche Modellkarte listet Gemma 4-Modelle in fünf Größen auf: E2B, E4B, 12B Unified, 26B A4B und 31B. Gemma 4 12B Unified verfügt über 11,95B Parameter, 48 Ebenen, 1024-Token-Schiebefensteraufmerksamkeit, ein 256K-Kontextfenster, ein 262K-Vokabular und Unterstützung für Textual content-, Bild- und Audioeingaben.
Hauptmerkmale
Gemma 4 12B unterstützt:
- Textgenerierung und Chat
- Langkontextschlussfolgerung mit bis zu 256.000 Token
- Codierung, Code-Vervollständigung und Code-Korrektur
- Funktionsaufruf für Agenten-Workflows
- Videoverständnis durch Verarbeitung von Movies als Frames
- Audio-Spracherkennung und Übersetzung von Sprache in übersetzten Textual content
- Mehrsprachige Nutzung mit sofort einsatzbereiter Unterstützung für mehr als 35 Sprachen und Vorschulung für mehr als 140 Sprachen
Google hebt im Gemma 4 12B-Entwicklerhandbuch auch automatische Spracherkennung, Diarisierung, Videoverständnis, Codierung und Agentic Reasoning hervor.
Warum brauchte Google ein mittelgroßes einheitliches Modell?
Die ursprüngliche Gemma 4-Familie wurde am 31. März 2026 mit den Varianten E2B, E4B, 31B und 26B A4B veröffentlicht. Google veröffentlichte dann am 16. April 2026 Gemma 4 MTP Drafter, gefolgt von Gemma 4 12B Unified am 3. Juni 2026. Damit ist die 12B-Model eine Folgeerweiterung der Familie und nicht die ursprüngliche Gemma 4-Veröffentlichung.
Das Launch schließt eine praktische Bereitstellungslücke. E2B und E4B sind für Anwendungsfälle der Edge- und Mobilklasse konzipiert, während 26B A4B und 31B auf Excessive-Finish-Workstations und Server abzielen. Gemma 4 12B ist als Laptop computer-fähiges Modell positioniert, das stärkere Argumentation und multimodale Fähigkeiten als die Edge-Modelle bietet und gleichzeitig weniger Speicher verbraucht als das größere 26B MoE-Modell.
Wichtigste Änderungen gegenüber früheren Gemma 4-Modellen
| Bereich | Frühere Gemma 4-Modelle | Gemma 4 12B Unified |
| Modellgröße | E2B, E4B, 26B A4B, 31B zunächst | Fügt eine mittelgroße 12B-Dichteoption hinzu |
| Multimodales Design | Andere Modelle verwenden je nach Größe spezielle Bild- und Audio-Encoder | Encoderfreie Projektion von Bild und Audio in das LLM |
| Audio | E2B und E4B verfügten über natives Audio; 31B und 26B A4B führen keine Audiounterstützung auf | Erstes mittelgroßes Gemma 4-Modell mit nativem Audio |
| Kontext | 128K für E2B/E4B, 256K für größere Modelle | 256K |
| Bereitstellungsziel | Edge-Modelle für Mobilgeräte, größere Modelle für Workstations und Server | Lokale multimodale Agenten mit Laptop computer-First-Ansatz |
| Feinabstimmung | Separate Encoder können die Komplexität erhöhen | Die einheitliche Token-Schleife kann in einem Durchgang optimiert werden |
| Benchmarks | E4B ist leichter, 26B A4B ist stärker | 12B liegt in den meisten offiziellen Wertungen dazwischen |
Architekturübersicht
1. Einheitliches, geberfreies Design
Die wichtigste technische Änderung in Gemma 4 12B ist seine geberfreie multimodale Architektur. Herkömmliche multimodale Modelle verwenden häufig separate Encoder für Bild- und Audioeingaben, bevor Darstellungen an das Sprachmodell übergeben werden. Laut Google entfernt Gemma 4 12B diese separaten multimodalen Encoder und projiziert Rohbild-Patches und Audiowellenformen direkt in den LLM-Einbettungsraum. (weblog.google)
2. Sehverarbeitung
Für die Bildverarbeitung heißt es im Entwicklerhandbuch, dass Gemma 4 12B den in anderen mittelgroßen Gemma 4-Modellen verwendeten mehrschichtigen Bildcodierer durch einen Bildverarbeitungseinbetter mit 35 Millionen Parametern ersetzt. Rohe 48×48-Pixel-Patches werden mit einer einzigen Matrixmultiplikation in die verborgene LLM-Dimension projiziert, und räumliche Informationen werden durch faktorisierte Koordinatensuchmatrizen angehängt.
3. Audioverarbeitung
Für Audio entfernt Gemma 4 12B den separaten konformerbasierten Audio-Encoder, der in kleineren Gemma 4-Varianten verwendet wird. Es schneidet rohes 16-kHz-Audio in 40-ms-Frames und projiziert diese Frames linear in den LLM-Eingaberaum.
4. Decoder und Aufmerksamkeit
Auf der Modellkarte heißt es, dass Gemma 4 einen hybriden Aufmerksamkeitsmechanismus verwendet, der die Aufmerksamkeit des lokalen Schiebefensters mit der vollständigen globalen Aufmerksamkeit verschachtelt, wobei die letzte Ebene immer world ist. Es verwendet außerdem einheitliche Schlüssel und Werte in globalen Ebenen und Proportional RoPE für Effizienz im langen Kontext.
5. MTP-Drafter für geringere Latenz
Gemma 4 12B ist „Draft-ready“, was bedeutet, dass es Multi-Token-Prediction-Drafter für die spekulative Dekodierung unterstützt. In der MTP-Dokumentation von Google wird erklärt, dass ein kleineres Entwurfsmodell mehrere zukünftige Token vorhersagt, während das Zielmodell sie parallel überprüft, wodurch die Decodierungsgeschwindigkeit verbessert wird, ohne die endgültige verifizierte Ausgabequalität zu verändern.
Verfügbarkeit und Zugriff
Gemma 4 12B ist als offene Gewichte in vortrainierten und unter Anleitung abgestimmten Varianten erhältlich Umarmendes Gesicht Und Kaggle. Im Startbeitrag von Google werden außerdem LM Studio, Ollama, Google AI Edge Gallery, Google AI Edge Eloquent, LiteRT-LM, Hugging Face Transformers, llama.cpp, MLX, SGLang, vLLM und Unsloth als unterstützte Ökosystempfade aufgeführt.
Praktisch: Führen Sie Gemma 4 12B mit Ollama aus
- Laden Sie Ollama herunter von https://ollama.com/obtain/
- Installieren Sie es in Ihrem System und geben Sie ollama in das Terminal ein, um die Set up zu überprüfen:
- Fügen Sie es in ein neues Terminalfenster ein
ollama run gemma4:12bund drücken Sie die Eingabetaste
Dies wird heruntergeladen gemma4 12b auf Ihrem PC und Sie können direkt damit interagieren
Praktisch: Bildverständnis
Testen wir Gemma4 12B auf Bildverständnis, für das dieses Modell bekannt ist.
Wir werden Ollama hier verwenden, aber nicht im Terminal, sondern über Code
Um dies zu verwenden, installieren Sie die ollama python sdk:
!pip set up ollama
import ollama
# Outline the mannequin ID
MODEL_ID = "gemma4:12b" # Guarantee this matches your native Ollama mannequin title
# Fingers-on: Picture Understanding
# Word: Google recommends inserting picture content material earlier than textual content in multimodal prompts.
# For native recordsdata, cross the trail string. For URLs, obtain the picture first.
image_messages = (
{
"function": "person",
"content material": "Extract the important thing tendencies from this desk.",
"pictures": ("financia_table.png"),
}
)
image_response = ollama.chat(mannequin=MODEL_ID, messages=image_messages)
print(image_response("message")("content material"))Ausgabe:
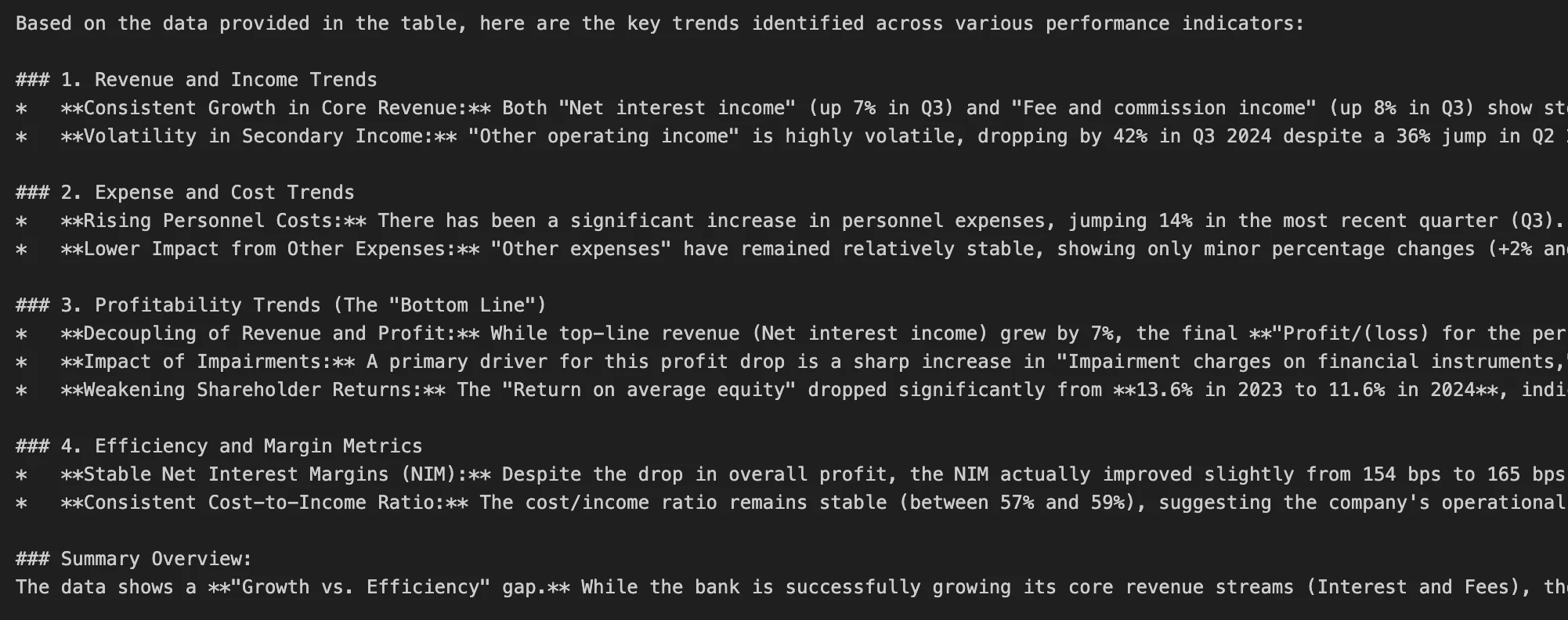
Wir können sehen, dass Gemma4 12B das Bild erfolgreich analysieren kann. Google empfiehlt, in multimodalen Eingabeaufforderungen Bildinhalte vor Textual content zu platzieren.
Benchmarks und Vergleich
Die offizielle Modellkarte meldet die folgenden, an Anweisungen angepassten Benchmark-Ergebnisse:
| Benchmark | Gemma 4 31B | Gemma 4 26B A4B | Gemma 4 12B Unified | Gemma 4 E4B | Gemma 4 E2B | Gemma 3 27B |
| MMLU Professional | 85,2 % | 82,6 % | 77,2 % | 69,4 % | 60,0 % | 67,6 % |
| AIME 2026, keine Werkzeuge | 89,2 % | 88,3 % | 77,5 % | 42,5 % | 37,5 % | 20,8 % |
| LiveCodeBench v6 | 80,0 % | 77,1 % | 72,0 % | 52,0 % | 44,0 % | 29,1 % |
| Codeforces ELO | 2150 | 1718 | 1659 | 940 | 633 | 110 |
| GPQA-Diamant | 84,3 % | 82,3 % | 78,8 % | 58,6 % | 43,4 % | 42,4 % |
| MMMU Professional | 76,9 % | 73,8 % | 69,1 % | 52,6 % | 44,2 % | 49,7 % |
| MATH-Imaginative and prescient | 85,6 % | 82,4 % | 79,7 % | 59,5 % | 52,4 % | 46,0 % |
| FLEURS, niedriger ist besser | nicht verfügbar | nicht verfügbar | 0,069 | 0,08 | 0,09 | nicht verfügbar |
Gemma 4 12B sitzt zwischen E4B und 26B A4B bieten einen praktischen Mittelweg für lokale Argumentations-, Codierungs-, Visions- und Audio-Workloads.
Abschluss
Gemma 4 12B ist nicht nur ein inkrementelles Replace; Es ist Googles Plan, hochleistungsfähige multimodale, agentenbasierte KI direkt auf alltägliche Entwicklermaschinen zu bringen. Durch die Weiterleitung von Textual content, Bild und Audio in einen einzigen, codiererfreien Decoder-Transformator wird die Pipeline-Komplexität für lokale Sprach-, Codierungs- und Dokumenten-Workflows vollständig eliminiert.
Letztendlich bietet dieses Modell technischen Führungskräften den perfekten Mittelweg zwischen winzigen Edge-Modellen und massiver Cloud-Infrastruktur. Der kluge Ansatz ist klar: Stellen Sie es als leistungsstarkes lokales Open-Weight-Modell bereit, überprüfen Sie die API-Verfügbarkeit vor der Skalierung und verankern Sie Ihre Bereitstellung anhand messbarer Latenz-, Sicherheits- und Compliance-Anforderungen.
Harsh Mishra ist ein KI/ML-Ingenieur, der mehr Zeit damit verbringt, mit großen Sprachmodellen zu sprechen als mit echten Menschen. Leidenschaftlich für GenAI, NLP und die intelligentere Entwicklung von Maschinen (damit sie ihn noch nicht ersetzen). Wenn er nicht gerade Modelle optimiert, optimiert er wahrscheinlich seinen Kaffeekonsum. 🚀☕
Melden Sie sich an, um weiterzulesen und von Experten kuratierte Inhalte zu genießen.