
Haben Sie Schwierigkeiten, KI-Systeme zuverlässig und konsistent zu machen? Viele Groups stehen vor dem gleichen Downside. Ein leistungsstarker LLM liefert großartige Ergebnisse, aber ein günstigeres Modell versagt bei derselben Aufgabe oft. Dies erschwert die Skalierung von Produktionssystemen. Harness Engineering bietet eine Lösung. Anstatt das Modell zu ändern, bauen Sie ein System darauf auf. Sie verwenden Eingabeaufforderungen, Instruments, Middleware und Auswertungen, um das Modell zu zuverlässigen Ausgaben zu führen. In diesem Artikel habe ich mithilfe von einen zuverlässigen KI-Codierungsagenten erstellt Die DeepAgents von LangChain Und LangSmith. Wir testen seine Leistung auch mit Customary Maßstäbe.
Was ist Harness Engineering?
Der Schwerpunkt des Harness Engineering liegt auf dem Aufbau eines strukturierten Programs rund um ein LLM, um die Zuverlässigkeit zu verbessern. Anstatt die Modelle zu ändern, steuern Sie die Umgebungen, in denen sie funktionieren. Ein Harness umfasst eine Systemeingabeaufforderung, Instruments oder APIs, einen Testaufbau und Middleware, die das Verhalten des Modells steuert. Das Ziel besteht darin, den Aufgabenerfolg zu verbessern und die Kosten zu verwalten und dabei dasselbe zugrunde liegende Modell zu verwenden.
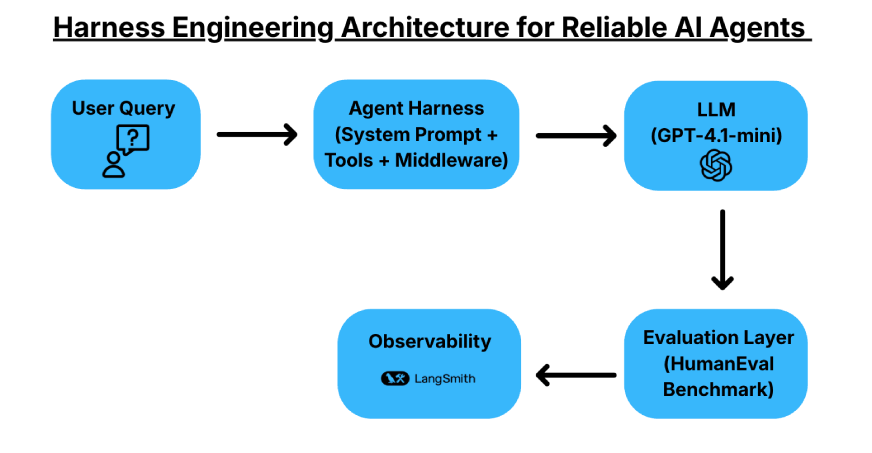
Für diesen Artikel verwenden wir die DeepAgents-Bibliothek von LangChain. DeepAgents fungiert als Agenten-Harness mit integrierten Funktionen wie Aufgabenplanung, einem speicherinternen virtuellen Dateisystem und Subagenten-Spawning. Diese Funktionen tragen dazu bei, den Arbeitsablauf des Agenten zu strukturieren und zuverlässiger zu machen.
Lesen Sie auch: Ein Leitfaden zu LangGraph und LangSmith zum Erstellen von KI-Agenten
Auswertung und Metriken
HumanEval ist ein Benchmark, der 164 handgefertigte Python-Probleme zur Bewertung der funktionalen Korrektheit umfasst. Wir werden diese Daten verwenden, um die KI-Agenten zu testen, die wir erstellen werden.
- Go@1 (Erfolg beim ersten Schuss): Der Prozentsatz der Probleme, die das Modell in einem einzigen Versuch korrekt gelöst hat. Dies ist der Goldstandard für Produktionssysteme, bei denen Benutzer auf einmal eine korrekte Antwort erwarten.
- Go@okay (Erfolg bei mehreren Stichproben): Die Wahrscheinlichkeit, dass mindestens eine von okay generierten Stichproben korrekt ist. Dies wird verwendet, um das Wissen oder die Erkundungskraft des Modells zu messen.
Erstellen eines Codierungsagenten mit Harness Engineering
Wir werden einen Codierungsagenten erstellen und ihn anhand der von uns definierten Benchmarks und Metriken bewerten. Der Agent wird mithilfe der DeepAgents-Bibliothek von LangChain implementiert und nutzt die Ideen des Harness Engineering zum Aufbau des KI-Programs.
Voraussetzungen (API-Schlüssel)
- Besuchen Sie die LangSmith Dashboard und klicken Sie auf die Schaltfläche „Beobachtbarkeit einrichten“. Dann sehen Sie diesen Bildschirm. Klicken Sie nun auf die Possibility „API-Schlüssel generieren“ und halten Sie den LangSmith-Schlüssel bereit.
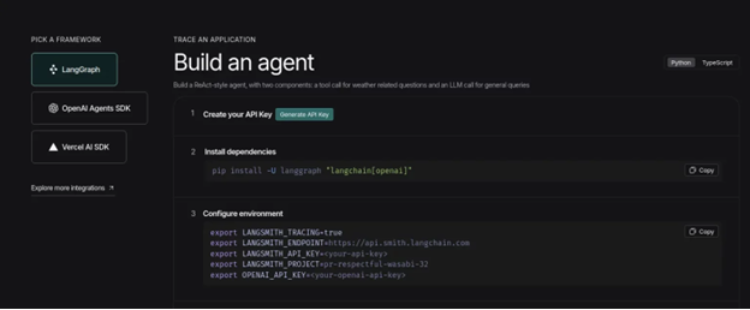
- Wir benötigen außerdem einen OpenAI-API-Schlüssel und verwenden das gpt-5-Modell als Gehirn des Programs. Den API-Schlüssel erhalten Sie bei diesen Hyperlink.
Installationen
!git clone https://github.com/openai/human-eval.git
!sed -i '/evaluate_functional_correctness/d' human-eval/setup.py
!pip set up -qU ./human-eval deepagents langchain-openai Initialisierungen
import os
from google.colab import userdata
os.environ('LANGCHAIN_TRACING_V2') = 'true'
os.environ('LANGSMITH_API_KEY') = userdata.get('LANGSMITH_API_KEY')
os.environ('LANGSMITH_PROJECT') = 'DeepAgent'
os.environ('OPENAI_API_KEY') = userdata.get('OPENAI_API_KEY')Definieren der Eingabeaufforderungen
from langsmith import Shopper
from langchain_core.prompts import ChatPromptTemplate
ls = Shopper()
PROMPTS = {
"coding-agent-1": (
"You're a Python coding assistant.n"
"Given a operate signature and docstring, full the implementation.n"
"Return ONLY the finished Python operate — no prose, no markdown fences."
),
"coding-agent-2": (
"You're a Python coding assistant with a self-verification self-discipline.n"
"Steps you MUST comply with:n"
"1. Learn the docstring and edge circumstances rigorously.n"
"2. Write the implementation.n"
"3. Mentally run the offered examples in opposition to your code.n"
"4. If any instance fails, rewrite and repeat step 3.n"
"Return ONLY the finished Python operate. No prose, no markdown fences."
),
"coding-agent-3": (
"You're an professional Python engineer. Assume step-by-step earlier than coding.n"
"nProcess:n"
"<suppose>n"
" - Restate what the operate should do in a single sentence.n"
" - Listing nook circumstances (empty inputs, negatives, giant values).n"
" - Select the best appropriate algorithm.n"
"</suppose>n"
"Then output the finished Python operate verbatim — no markdown, no rationalization."
),
}
for title, textual content in PROMPTS.objects():
immediate = ChatPromptTemplate.from_messages(
(("system", textual content), ("human", "{enter}"))
)
ls.push_prompt(title, object=immediate)
print(f"pushed: {title}")Ausgabe:
pushed: coding-agent-1
pushed: coding-agent-2
pushed: coding-agent-3
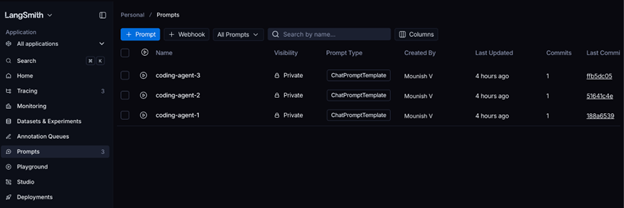
Wir haben die Eingabeaufforderungen definiert und an LangSmith weitergeleitet. Sie können dasselbe im Abschnitt „Eingabeaufforderungen“ im LangSmith-Dashboard überprüfen:
Definition unseres ersten Agenten
from deepagents import create_deep_agent
from langchain.chat_models import init_chat_model
PROMPT = "coding-agent-1"
pulled = ls.pull_prompt(PROMPT)
system_prompt = pulled.messages(0).immediate.template
print(f"Loaded immediate: {PROMPT}")
print(system_prompt(:120), "...")
mannequin = init_chat_model("openai:gpt-5-mini")
# Creating the DeepAgent
agent = create_deep_agent(
mannequin=mannequin,
system_prompt=system_prompt,
)
print("nAgent prepared")Der Agent sollte einsatzbereit sein. Er verwendet die zuvor definierte Eingabeaufforderung „coding-agent-1“.
Testen Sie den Agenten
# Obtain the HumanEval benchmark dataset (164 Python coding issues)
!wget -q https://github.com/openai/human-eval/uncooked/grasp/knowledge/HumanEval.jsonl.gz -O HumanEval.jsonl.gz
# Import required libraries
import gzip
import json
# Operate to learn the HumanEval dataset
def read_problems(path="HumanEval.jsonl.gz"):
issues = {}
attempt:
with gzip.open(path, "rt") as f:
for line in f:
p = json.masses(line)
issues(p("task_id")) = p
besides FileNotFoundError:
print("Dataset file not discovered.")
return issues
# Load all issues
issues = read_problems()
# Extract job IDs
task_ids = listing(issues.keys())
# Print whole variety of issues
print(f"Whole issues: {len(task_ids)}")
# Elective: examine the primary drawback
instance = issues(task_ids(0))
print("nExample Job ID:", instance("task_id"))
print("nPrompt:n", instance("immediate"))
print("nCanonical Resolution:n", instance("canonical_solution"))Gesamtprobleme: 164
Wir haben jetzt 164 Codierungsprobleme, die wir zum Testen des Programs verwenden können.
Code mit dem Agenten generieren
import re
def extract_code(textual content: str, immediate: str) -> str:
"""Return simply the finished operate, stripping any markdown wrapping."""
textual content = re.sub(r"```pythons*", "", textual content)
textual content = re.sub(r"```s*", "", textual content)
if textual content.strip().startswith("def "):
return textual content.strip()
return immediate + textual content
def resolve(drawback: dict) -> str:
consequence = agent.invoke(
{"messages": ({"position": "consumer", "content material": drawback("immediate")})},
config={
"metadata": {
"task_id": drawback("task_id"),
"prompt_name": PROMPT,
}
},
)
uncooked = consequence("messages")(-1).content material
return extract_code(uncooked, drawback("immediate"))
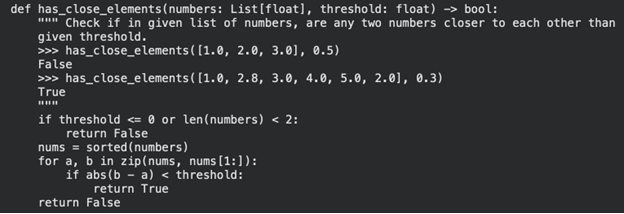
# Check the system on the primary drawback earlier than operating the total analysis
pattern = issues(task_ids(0))
code = resolve(pattern)
print(code)Ausgabe:
Großartig! Wir haben ein funktionierendes System. Testen wir es jetzt an 5 Codierungsproblemen!
import pandas as pd
# Calculate move@1 and common latency
handed = sum(r("handed") for r in outcomes)
pass_at_1 = handed / len(outcomes)
avg_latency = sum(r("latency_s") for r in outcomes) / len(outcomes)
print(f"Outcomes : move@1 = {pass_at_1:.2%} ({handed}/{len(outcomes)})")
print(f"Avg latency = {avg_latency:.1f}s")
# Convert outcomes to DataFrame for simpler inspection
df = pd.DataFrame(outcomes)
print(df(("task_id", "handed", "latency_s")).to_string(index=False))
# Print failed duties for debugging
print("n── Failures ──")
for _, row in df(~df("handed")).iterrows():
print(f"n{'─'*60}")
print(f"TASK: {row('task_id')}")
print(row("code")(:400)) # Present first 400 chars of codeAusgabe:
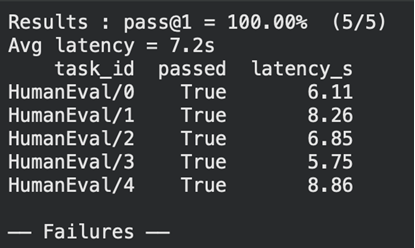
Großartig! Wir haben die Assessments erfolgreich durchgeführt und können auch die Latenz jedes einzelnen Assessments sehen. Öffnen wir LangSmith, um die Token-Nutzung, die Kosten und andere Particulars anzuzeigen.
Öffnen Sie LangSmith -> Gehen Sie zum Abschnitt „Tracing“ -> Öffnen Sie das DeepAgent-Projekt:
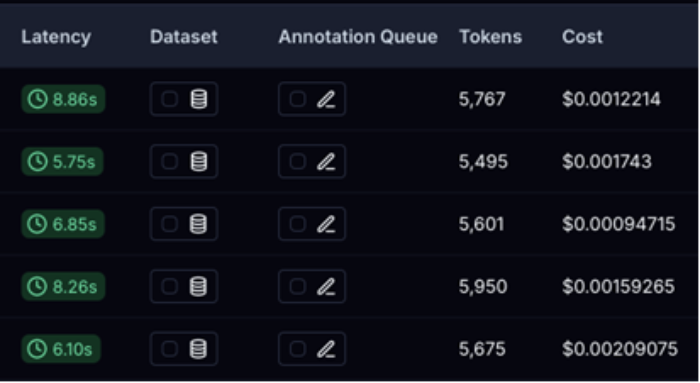
Dies wird nützlich sein, um unsere Ergebnisse mit dem neuen Agenten zu vergleichen, den wir erstellen werden.
Definieren eines neuen Agenten
from deepagents import create_deep_agent
from langchain.brokers.middleware import ModelCallLimitMiddleware
from langchain.chat_models import init_chat_model
SYSTEM_PROMPT = "coding-agent-3"
pulled = ls.pull_prompt(SYSTEM_PROMPT)
system_prompt = pulled.messages(0).immediate.template
# Construct the agent
base_model = init_chat_model("openai:gpt-5-mini")
new_agent = create_deep_agent(
mannequin=base_model,
system_prompt=system_prompt,
middleware=(
# Restrict mannequin calls to 2 per invocation
ModelCallLimitMiddleware(
run_limit=2,
exit_behavior="finish",
),
),
)
def resolve(drawback: dict) -> str:
consequence = new_agent.invoke(
{"messages": ({"position": "consumer", "content material": drawback("immediate")})},
config={
"metadata": {
"task_id": drawback("task_id"),
"prompt_name": SYSTEM_PROMPT,
}
},
)
uncooked = consequence("messages")(-1).content material
return extract_code(uncooked, drawback("immediate"))Testen des neuen Agenten
import time
from human_eval.execution import check_correctness
N_PROBLEMS = 5
TIMEOUT = 5 # seconds per check case
outcomes = ()
for task_id in task_ids(:N_PROBLEMS):
drawback = issues(task_id)
t0 = time.time()
# Resolve the issue utilizing the agent
code = resolve(drawback)
latency = time.time() - t0
# Examine correctness of the generated code
consequence = check_correctness(drawback, code, timeout=TIMEOUT)
outcomes.append({
"task_id": task_id,
"handed": consequence("handed"),
"latency_s": spherical(latency, 2),
"code": code,
})
standing = "PASS" if consequence("handed") else "FAIL"
print(f"{standing} {task_id:30s} {latency:.1f}s")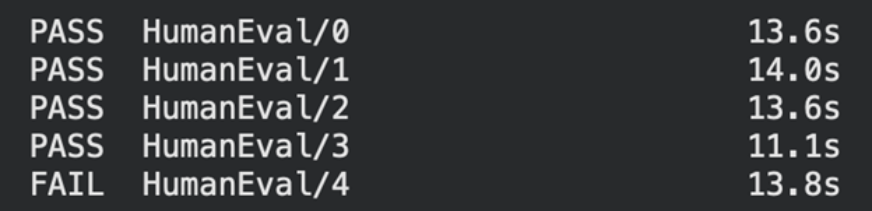
Wir können sehen, dass unser Immediate-3 vier Probleme bestanden hat, aber ein Codierungsproblem nicht lösen konnte.
Abschluss
Bedeutet das, dass unser Immediate-1 besser warfare? Die Antwort ist nicht so einfach: Wir müssen Go@1-Assessments mehrmals ausführen, um die Konsistenz des Agenten zu testen, und zwar mit einer Testgröße, die viel größer als 5 ist. Dies hilft uns, die durchschnittliche Latenz, die Kosten und den wichtigsten Faktor zu ermitteln: die Aufgabenzuverlässigkeit. Auch das Finden und Anschließen der richtigen Middleware kann dazu beitragen, dass das System unseren Anforderungen entspricht. Es sind Middlewares vorhanden, um die Fähigkeiten des Agenten zu erweitern und die Anzahl der Modellaufrufe, Toolaufrufe und vieles mehr zu steuern. Es ist wichtig, den Agenten zu bewerten, und LangSmith kann sicherlich bei der Rückverfolgbarkeit helfen, die Eingabeaufforderungen speichern und auch Fehler (falls vorhanden) des Agenten anzeigen. Es ist wichtig zu beachten, dass sich Immediate Engineering zwar auf das konzentriert EingangHarness Engineering konzentriert sich auf die Umfeld Und Einschränkungen.
Häufig gestellte Fragen
A. Middleware ist Software program, die als Brücke zwischen Komponenten fungiert, die Kommunikation ermöglicht und die Fähigkeiten eines Agenten erweitert.
A. Zu den beliebten Alternativen für die LLM-Verfolgung und -Überwachung gehören Langfuse, Arize Phoenix usw.
A. Zu den Branchen-Benchmarks gehören SWE-Bench und BigCodeBench zur Messung der Codierungsleistung in der Praxis.
Leidenschaftlich für Technologie und Innovation, Absolvent des Vellore Institute of Expertise. Derzeit arbeite ich als Knowledge Science Trainee mit Schwerpunkt auf Knowledge Science. Großes Interesse an Deep Studying und generativer KI, begierig darauf, modernste Techniken zu erforschen, um komplexe Probleme zu lösen und wirkungsvolle Lösungen zu schaffen.
Melden Sie sich an, um weiterzulesen und von Experten kuratierte Inhalte zu genießen.