

Bild vom Autor | Canva
# Einführung
Datenanalyseprobleme sind nicht wirklich einzigartig. Doch „obwohl Ihre Probleme nicht einzigartig sind, bedeutet das nicht, dass sie verschwinden“, um Neil Younger zu paraphrasieren. Was wird sie verschwinden lassen? Die Erkenntnis, dass die meisten von ihnen unter der Oberfläche auf einer Handvoll wiederverwendbarer Muster basieren.
Ich zeige Ihnen diese Muster, damit Sie sie unabhängig von den Daten oder der Branche in Ihrer Arbeit oder Ihrem Vorstellungsgespräch wiederverwenden können. Daten sind immer genau das – Daten. Alle Muster werden dabei sein PostgreSQL Basierend auf den Codierungsinterviewfragen auf StrataScratch. Dann verknüpfe ich sie mit realen Geschäftssituationen.

# 1. Verknüpfungen + Filter: Die richtige Teilmenge finden
Frage: Filmdauer-Match von Amazon
Aufgabe: Entwicklung einer Funktion, die einzelne Filme aus der Inhaltsdatenbank von Amazon vorschlägt, die in die Dauer eines bestimmten Fluges passen.
Suchen Sie für Flug 101 nach Filmen, deren Laufzeit kleiner oder gleich der Flugdauer ist. Die Ausgabe sollte vorgeschlagene Filme für den Flug auflisten, einschließlich flight_id, movie_idUnd movie_duration.
Lösung:
SELECT fs.flight_id,
ec.movie_id,
ec.period AS movie_duration
FROM flight_schedule fs
JOIN entertainment_catalog ec ON ec.period <= fs.flight_duration
WHERE fs.flight_id = 101
ORDER BY ec.period;Ausgabe:
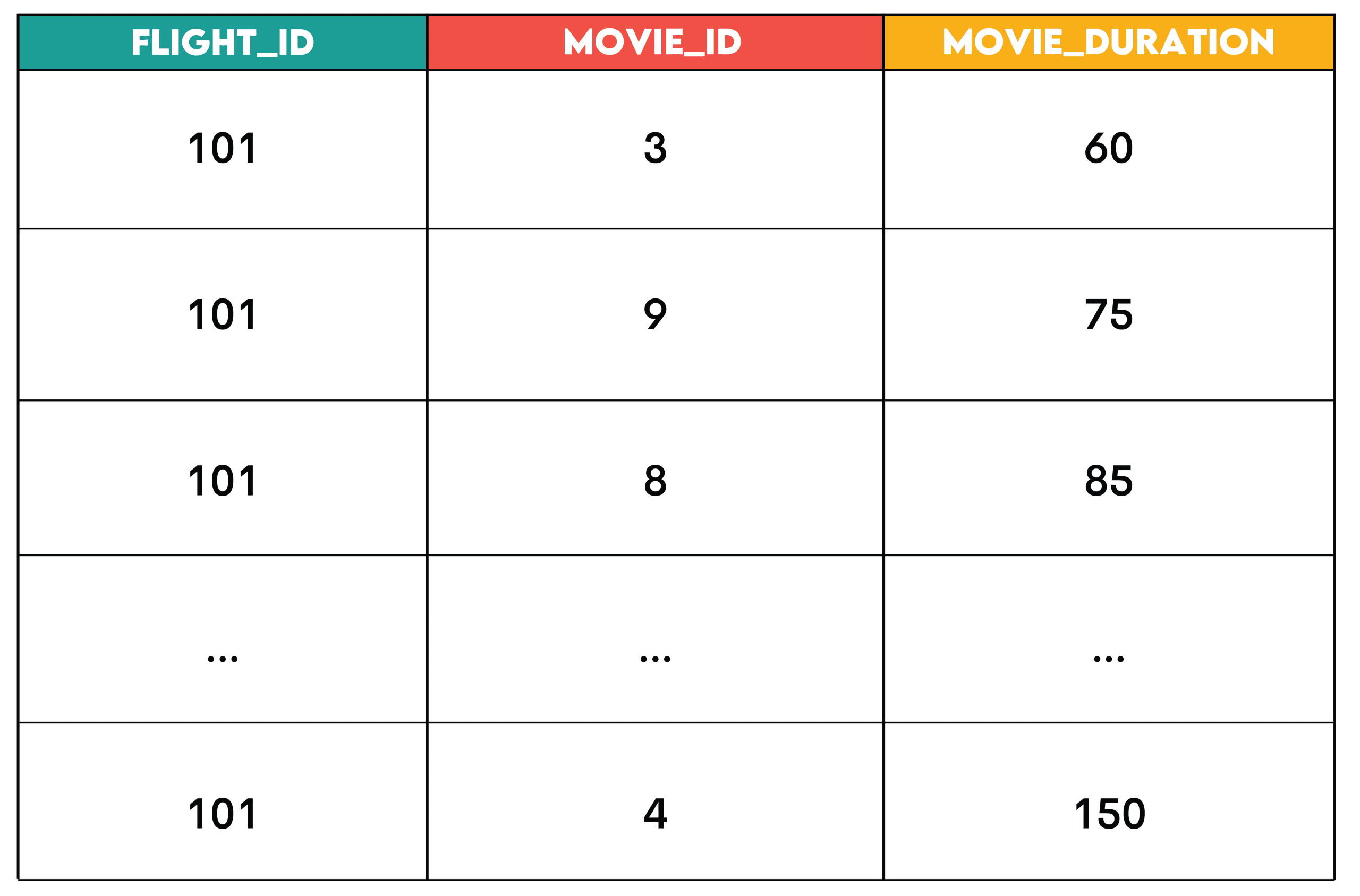
Muster: Der Be part of + Filter ist das Muster, bei dem Sie zwei Datensätze verbinden und Zeilen filtern (in WHERE vor der Aggregation oder in HAVING nach der Aggregation) basierend auf Bedingungen.
Das ist die Reihenfolge.

- Identifizieren Sie die Primärtabelle: Der Datensatz, der definiert, was Sie analysieren (
flight_schedule) - Ergänzende Daten hinzufügen: Die Datensätze, die Kontext oder Attribute hinzufügen (
entertainment_catalog) - Filter anwenden: Entfernen Sie die nicht benötigten Zeilen (
WHERE fs.flight_id = 101)
// Geschäftliche Nutzung
- HR: Erfassung der Mitarbeiter mit ihren Arbeitszeiten, um Überstunden zu erkennen
- Einzelhandel: Bestellungen mit Produktdetails verknüpfen, um die Leistung der Produktkategorie zu analysieren
- Streaming: Verknüpfen von Benutzern mit ihren Sitzungen, um aktive Zuschauer zu finden
# 2. Fensterfunktionen: Rangfolge und Reihenfolge
Frage: Prime-Beiträge professional Kanal von Meta
Aufgabe: Identifizieren Sie die Prime-3-Beiträge mit der höchsten Like-Anzahl für jeden Kanal. Weisen Sie jedem Beitrag basierend auf seiner Like-Anzahl einen Rang zu. So können Lücken im Rating entstehen, wenn Beiträge die gleiche Anzahl an Likes haben.
Die Ausgabe sollte den Kanalnamen, die Beitrags-ID, das Erstellungsdatum des Beitrags und die Anzahl der Likes für jeden Beitrag anzeigen.
Lösung:
WITH ranked_posts AS
(SELECT post_id,
channel_id,
created_at,
likes,
RANK() OVER (PARTITION BY channel_id ORDER BY likes DESC) AS post_rank
FROM posts
WHERE likes > 0)
SELECT c.channel_name,
r.post_id,
r.created_at,
r.likes
FROM ranked_posts AS r
JOIN channels AS c ON r.channel_id = c.channel_id
WHERE r.post_rank <= 3;Ausgabe:
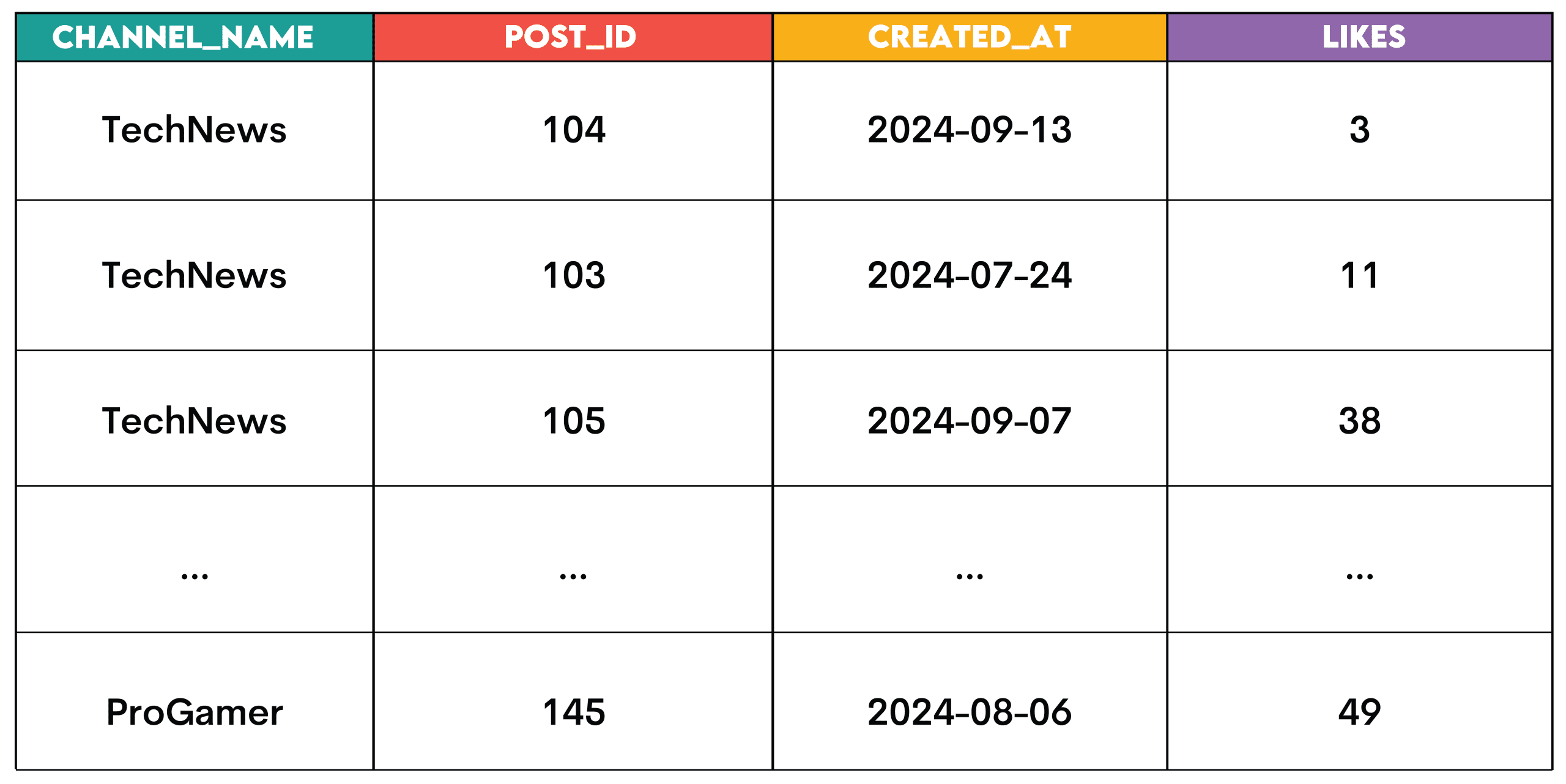
Muster: Dies sind die Fensterfunktionen, die für das Rating verwendet werden.
RANK(): Rating mit LückenDENSE_RANK(): Rating ohne LückenROW_NUMBER(): Einzigartige Reihenfolge ohne Bindungen
Befolgen Sie beim Rating dieses Muster.
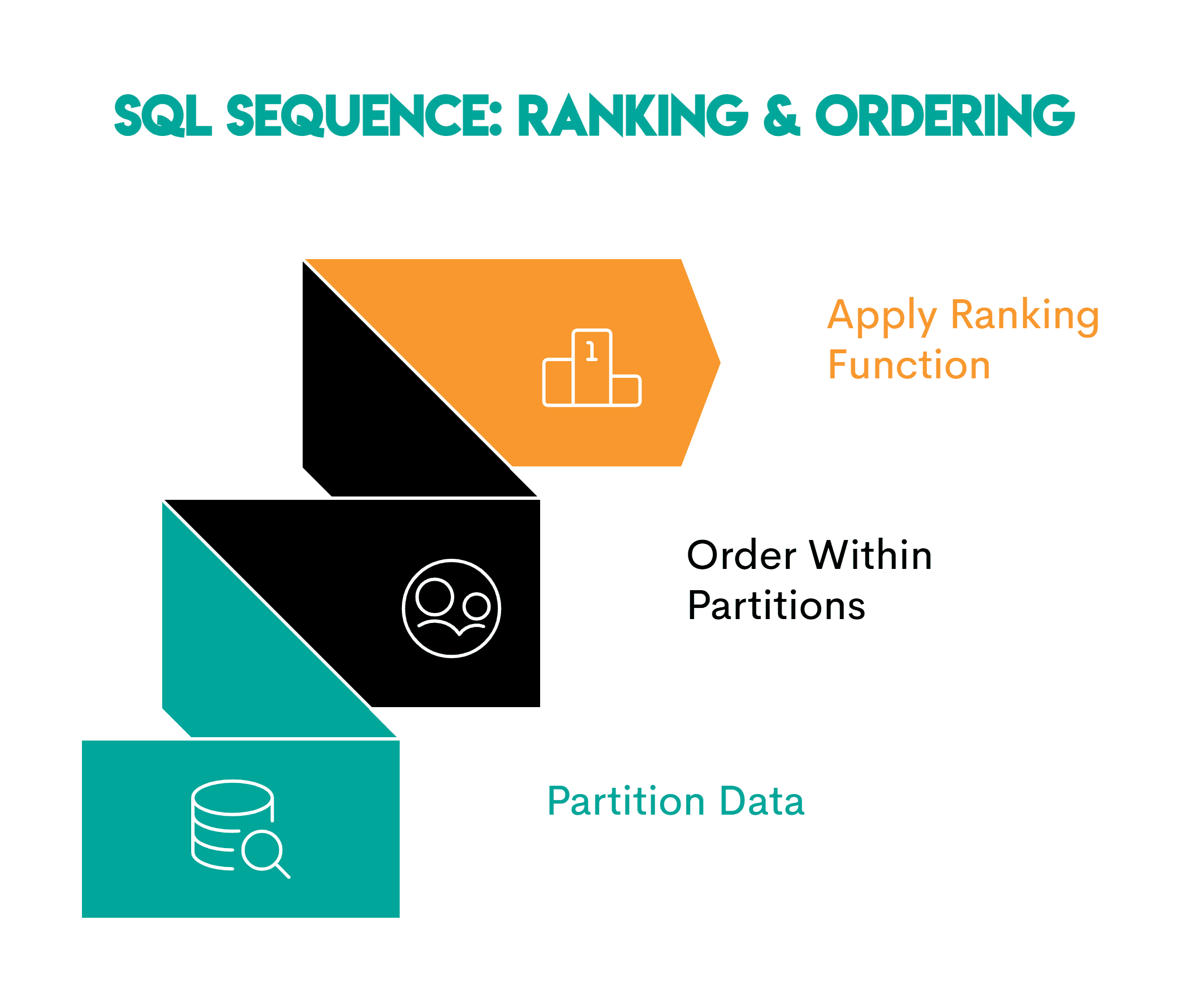
- Partitionieren Sie die Daten: Definieren Sie die logische Gruppe, die Sie analysieren (
PARTITION BY channel_id) - Reihenfolge innerhalb jeder Partition: Geben Sie die Rangfolge oder die zeitliche Reihenfolge an (
ORDER BY likes DESC) - Wenden Sie die Rating-Fensterfunktion an –
RANK(),DENSE_RANK()oderROW_NUMBER() OVER()je nach Aufgabe
// Geschäftliche Nutzung
Dieses Muster wird verwendet, um Prime-Performer zu identifizieren, zum Beispiel:
- Vertrieb: Prime-Vertriebsmitarbeiter professional Area
- Bildung: Einstufung der Schüler nach Testergebnissen innerhalb jeder Klasse
- Logistik: Rangfolge der Lieferfahrer nach abgeschlossenen Lieferungen innerhalb jeder Area
# 3. Aggregation + Gruppierung: Das Roll-Up-Muster
Frage: Bestellungen am selben Tag bei Walmart
Aufgabe: Finden Sie Benutzer, die am selben Tag eine Sitzung gestartet und eine Bestellung aufgegeben haben. Berechnen Sie die Gesamtzahl der an diesem Tag aufgegebenen Bestellungen und den Gesamtbestellwert für diesen Tag.
Lösung:
SELECT s.user_id,
s.session_date,
COUNT(o.order_id) AS total_orders,
SUM(o.order_value) AS total_order_value
FROM
(SELECT DISTINCT user_id,
session_date
FROM periods) s
JOIN order_summary o ON s.user_id = o.user_id
AND s.session_date = o.order_date
GROUP BY s.user_id, s.session_date;Ausgabe:
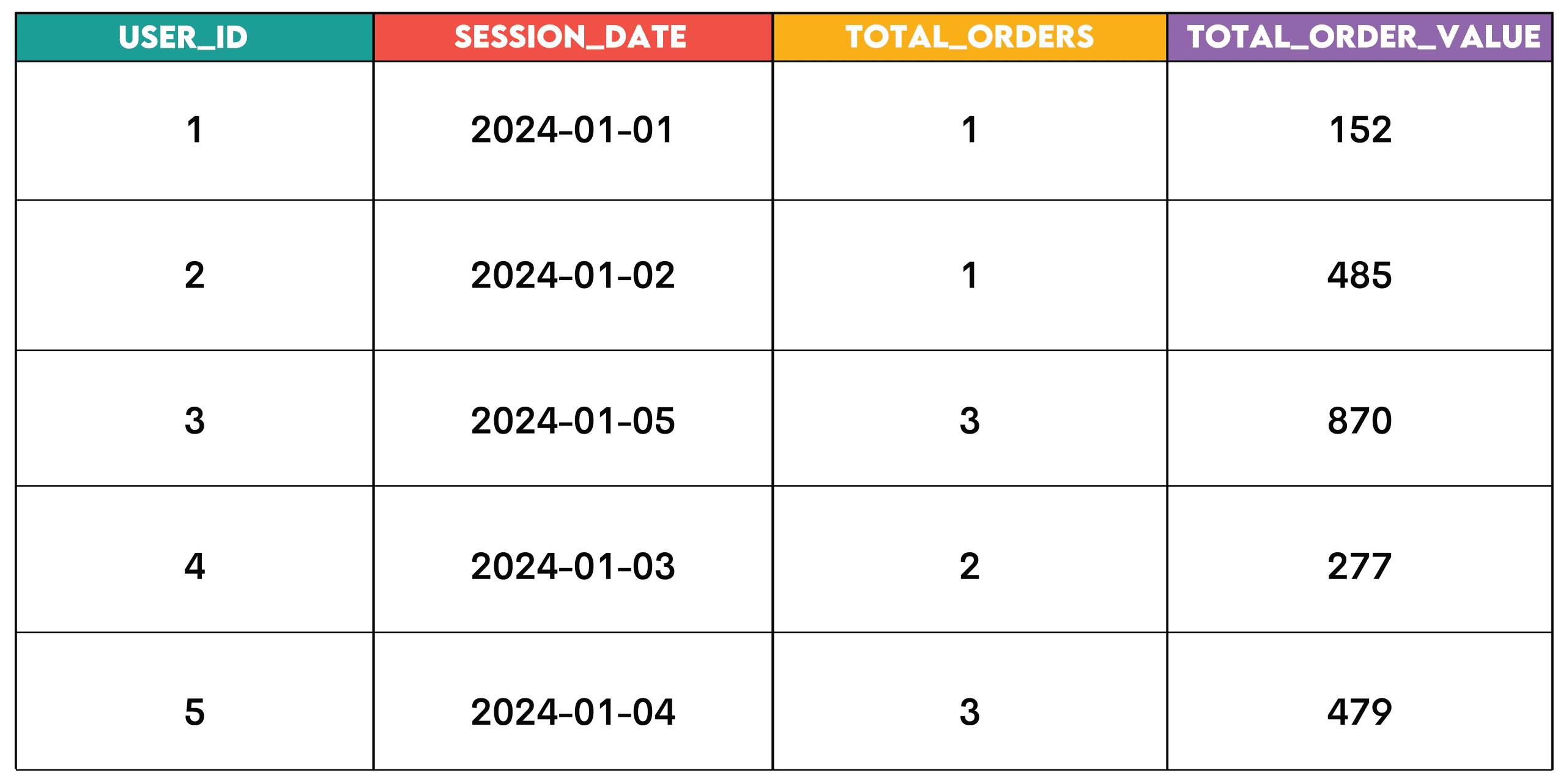
Muster: Dieses Muster dient zum Zusammenfassen von Daten, z. B. über Benutzer, Daten, Produkte oder andere analytische Dimensionen hinweg.
Hier ist die Reihenfolge.

- Identifizieren Sie die Gruppierungsdimension: Die Spalte, nach der Sie gruppieren möchten (
user_idUndsession_date) - Gruppieren Sie die Daten: Verwenden
GROUP BYauf die ausgewählte(n) Dimension(en), um die Daten zu gruppieren - Aggregieren Sie die Metriken: Fassen Sie die Werte für jede Gruppe mithilfe der Aggregatfunktionen zusammen
- Aggregierte Ergebnisse filtern (elective): Verwenden
HAVINGabhängig vom Gesamtwert nur bestimmte Gruppen zu behalten
// Geschäftliche Nutzung
- E-Commerce: Bestellungen und Umsatz professional Kunde und Tag
- SaaS: Anmeldungen professional Benutzer und Woche
- Finanzen: Transaktionen professional Konto und Quartal
# 4. Pivotieren: Zeilen in Spalten umwandeln
Frage: Höchste Zahlung der Stadt San Francisco
Aufgabe: Erstellen Sie eine Pivot-Tabelle, die die höchste Zahlung für jeden Mitarbeiter in jedem Jahr anzeigt, sortiert nach Mitarbeiternamen in aufsteigender Reihenfolge. Die Tabelle sollte die Jahre 2011, 2012, 2013 und 2014 anzeigen.
Lösung:
SELECT employeename,
MAX(pay_2011) AS pay_2011,
MAX(pay_2012) AS pay_2012,
MAX(pay_2013) AS pay_2013,
MAX(pay_2014) AS pay_2014
FROM
(SELECT employeename,
CASE
WHEN yr = 2011
THEN totalpay
ELSE 0
END AS pay_2011,
CASE
WHEN yr = 2012
THEN totalpay
ELSE 0
END AS pay_2012,
CASE
WHEN yr = 2013
THEN totalpay
ELSE 0
END AS pay_2013,
CASE
WHEN yr = 2014
THEN totalpay
ELSE 0
END AS pay_2014
FROM sf_public_salaries) pmt
GROUP BY employeename
ORDER BY employeename;Ausgabe:
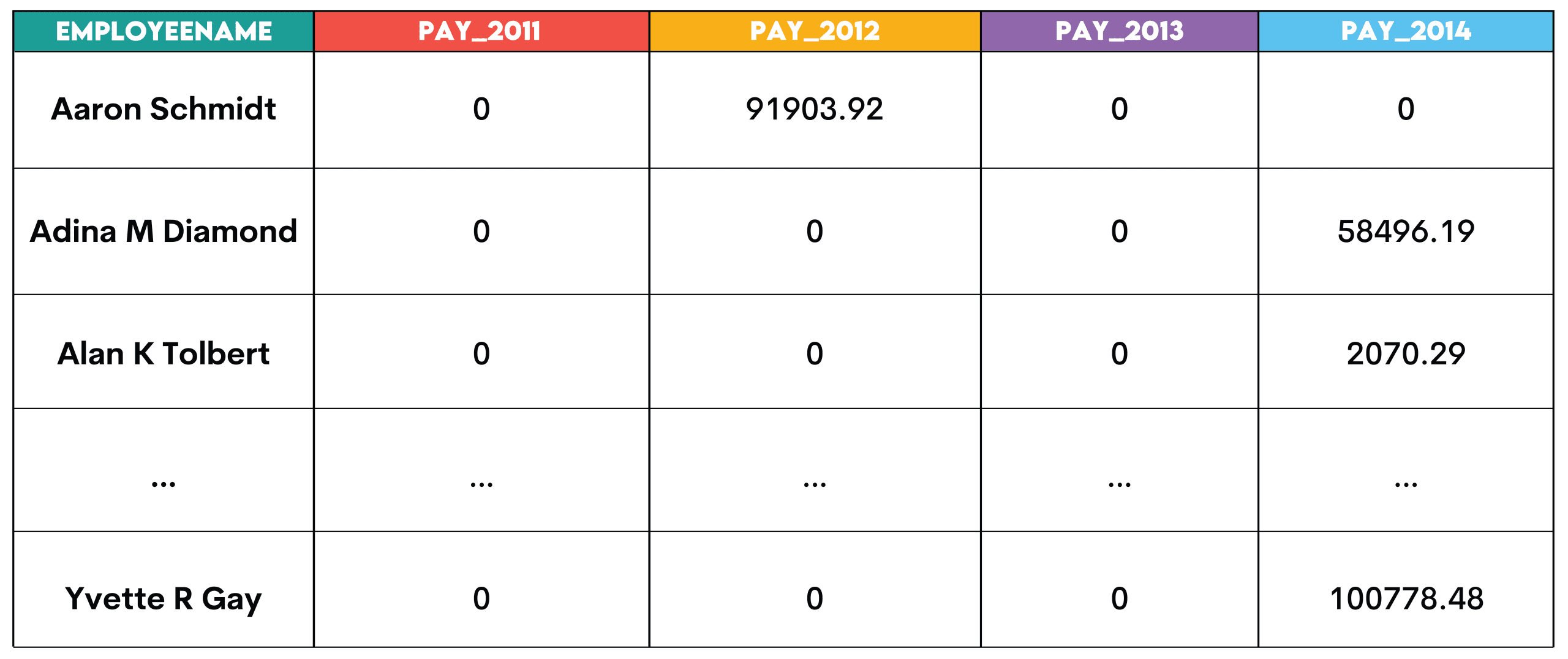
Muster: Durch das Pivotieren werden Zeilenwerte in Spalten umgewandelt. Dies ist nützlich, wenn Sie Metriken über Jahre, Kategorien oder Segmente hinweg vergleichen.
Hier ist die Reihenfolge.
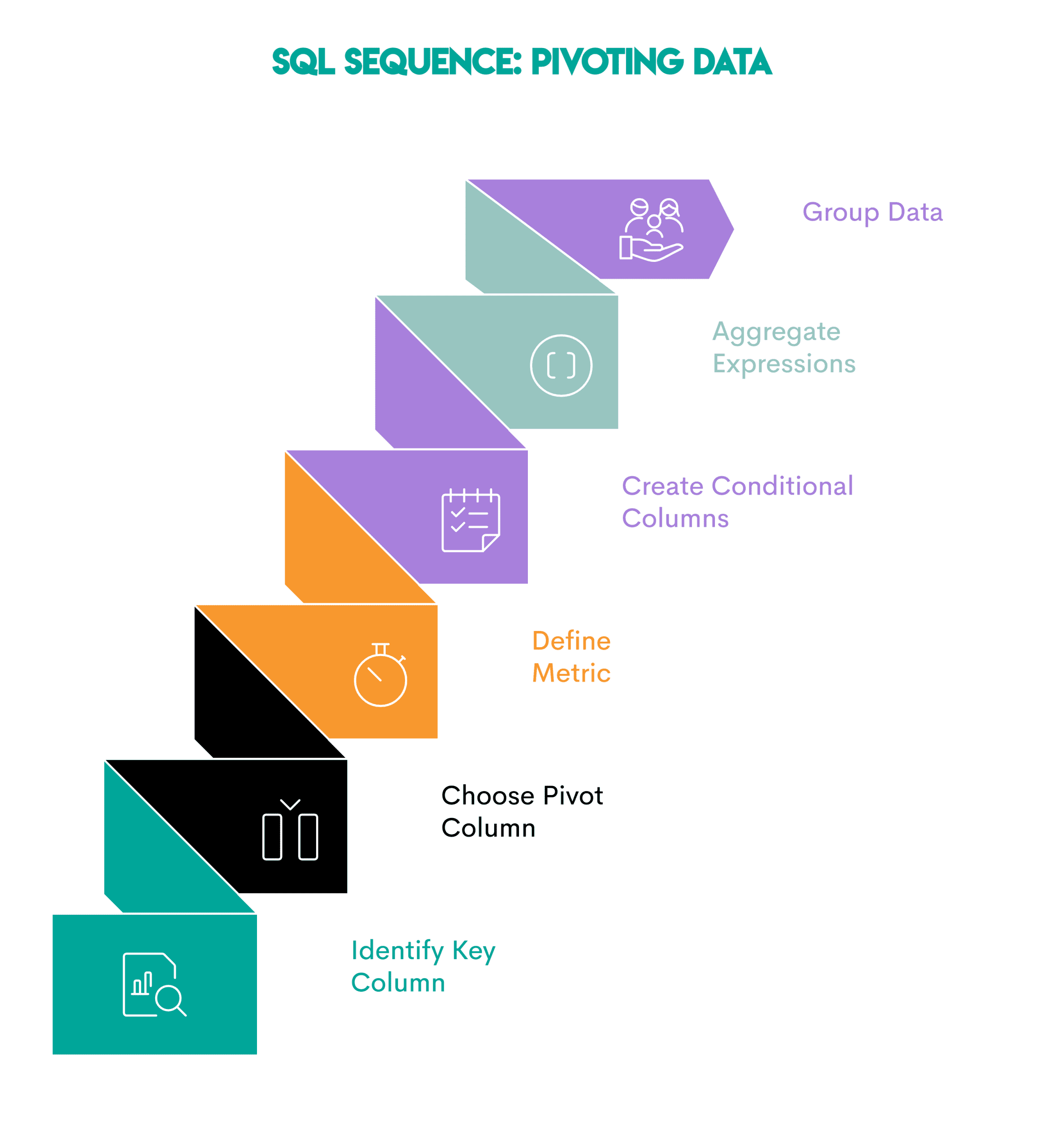
- Identifizieren Sie die Schlüsselspalte: Die Spalte, die Sie als Zeilen anzeigen möchten (
employeename) - Wählen Sie die Pivot-Spalte: Das Feld, dessen eindeutige Werte zu neuen Spalten werden (
yr) - Definieren Sie die Metrik: Bestimmen Sie die Metrik, die Sie berechnen und aggregieren möchten (
totalpay) - Bedingte Spalten erstellen: Verwenden
CASE WHEN(oderPIVOTsofern unterstützt), um jeder Spalte basierend auf der Pivot-Spalte Werte zuzuweisen - Bedingte Ausdrücke in der äußeren Abfrage aggregieren: Aggregieren Sie jede Pivot-Spalte
- Gruppieren Sie die Daten: Verwenden
GROUP BYin der Schlüsselspalte, um die Ausgabe zu gruppieren
// Geschäftliche Nutzung
- Finanzen: Vergleich der Einnahmen professional Quartal nebeneinander
- HR: Gehälter über Jahre hinweg vergleichen
- Einzelhandel: Vergleich der monatlichen Verkaufssummen
# 5. Kumulative Kennzahlen: Wachstum, Bindung und Fortschritt
Frage: Einnahmen im Laufe der Zeit von Amazon
Aufgabe: Berechnen Sie den gleitenden 3-Monats-Durchschnitt des Gesamtumsatzes aus Einkäufen. Die Retouren – dargestellt durch unfavourable Einkaufswerte – sollten nicht in die Berechnung einbezogen werden.
Die Ausgabe sollte Jahr-Monat (JJJJ-MM) und den gleitenden Durchschnitt anzeigen, sortiert vom frühesten zum neuesten Monat.
Lösung:
SELECT t.month,
AVG(t.monthly_revenue) OVER (ORDER BY t.month ROWS BETWEEN 2 PRECEDING AND CURRENT ROW) AS avg_revenue
FROM
(SELECT to_char(created_at::date, 'YYYY-MM') AS month,
SUM(purchase_amt) AS monthly_revenue
FROM amazon_purchases
WHERE purchase_amt > 0
GROUP BY to_char(created_at::date, 'YYYY-MM')
ORDER BY to_char(created_at::date, 'YYYY-MM')
) t
ORDER BY t.month ASC;Ausgabe:
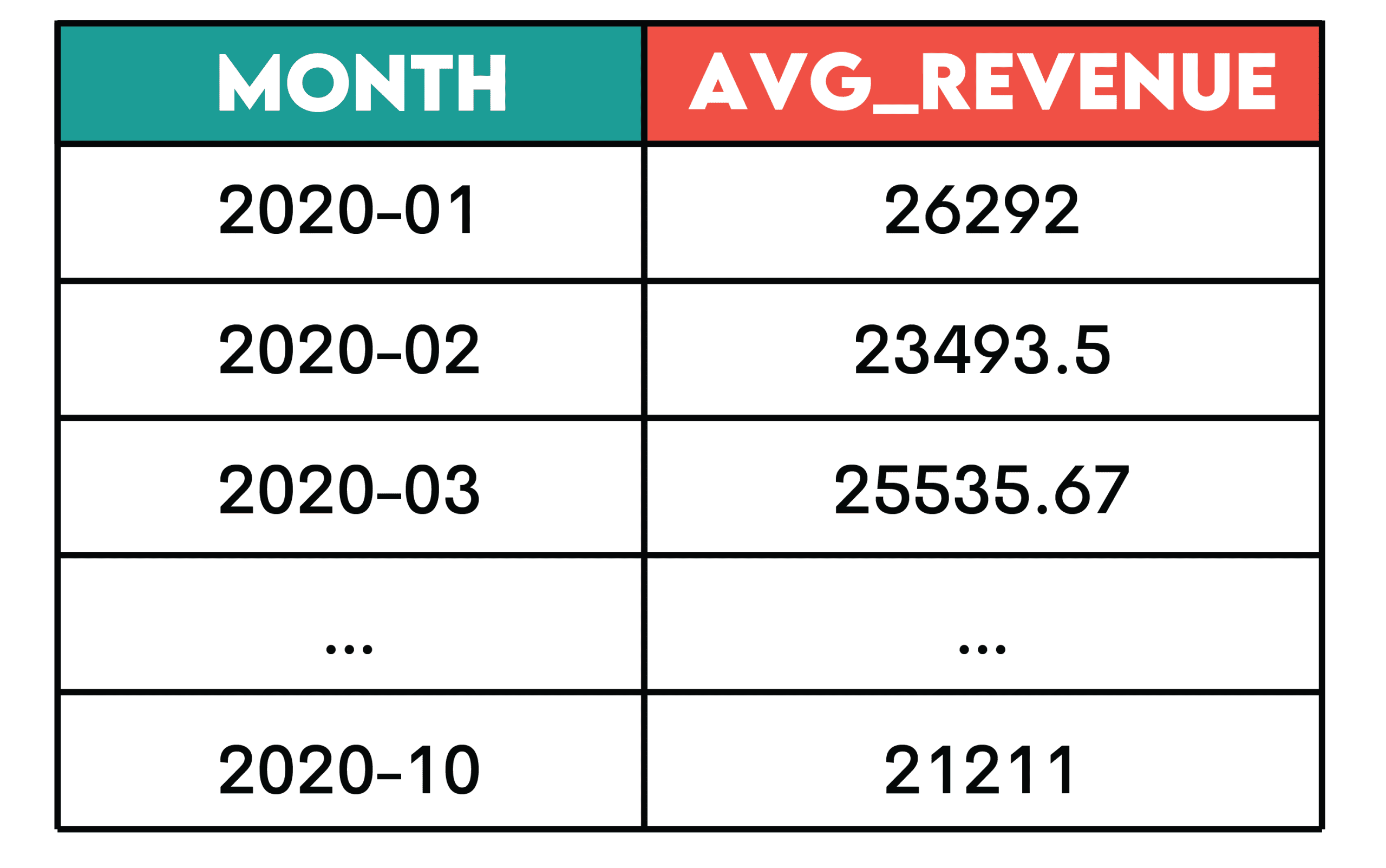
Muster: Kumulative Metriken (z. B. laufende Summe, gleitender Durchschnitt oder laufende Anzahl) werden verwendet, um Tendencies zu verstehen, anstatt einzelne Zeiträume separat anzuzeigen.
Hier ist die Reihenfolge.

- Vorabaggregation (elective) nach Zeitraum: Fassen Sie die Analysedaten zu Gesamtsummen professional erforderlichem Zeitraum zusammen (in der Unterabfrage angezeigt).
- Wenden Sie die Aggregatfunktion an: Verwenden Sie eine Aggregatfunktion für die Spalte, die Sie in der Hauptabfrage aggregieren möchten
- Verwandeln Sie die Aggregatfunktion in eine Fensterfunktion: Verwenden Sie die
OVER()Klausel - Ordnen Sie die Zeiträume: Sortieren Sie die Daten innerhalb einer Partition chronologisch, damit die kumulative Berechnung korrekt angewendet wird (
ORDER BY t.month) - Definieren Sie den Fensterrahmen: Definieren Sie die Anzahl der vorherigen oder folgenden Perioden, die in die kumulative Berechnung einbezogen werden sollen (
ROWS BETWEEN 2 PRECEDING AND CURRENT ROW)
// Geschäftliche Nutzung
- E-Commerce: Laufender Gesamtumsatz
- SaaS: Kumulierte aktive Benutzer
- Produktanalyse: Kohortenretentionskurven
- Finanzen: Nachlaufende Durchschnittswerte
- Vorgänge: Laufende Summe der Assist-Tickets
# 6. Trichteranalyse: Sequenzielles Verhalten verfolgen
Frage: Penetrationsanalyse von Spotify
Aufgabe: Wir müssen die Anforderungen überarbeiten. Die neue Aufgabe besteht darin, zu messen, wie Benutzer die Interaktionsphasen auf Spotify durchlaufen. Hier sind die Phasen des Engagements:
- Aktiv – Der Benutzer hatte mindestens eine Sitzung
- Engagiert – Der Benutzer hatte mehr als 5 Sitzungen
- Hauptbenutzer: Der Benutzer hatte in den letzten 30 Tagen mehr als 5 Sitzungen und mindestens 10 Hörstunden
Berechnen Sie für jedes Land, wie viele Benutzer jede Stufe erreichen und wie hoch die Gesamtkonversionsrate von der ersten Aktivität bis zum Energy-Consumer-Standing ist.
Lösung:
WITH base AS (
SELECT nation,
user_id,
periods,
listening_hours,
last_active_date
FROM penetration_analysis
),
stage_1 AS (
SELECT DISTINCT user_id, nation
FROM base
WHERE periods > 0
),
stage_2 AS (
SELECT DISTINCT user_id, nation
FROM base
WHERE periods >= 5
),
stage_3 AS (
SELECT DISTINCT user_id, nation
FROM base
WHERE periods >= 5 AND listening_hours >= 10
)
SELECT nation,
COUNT(DISTINCT s1.user_id) AS users_started,
COUNT(DISTINCT s2.user_id) AS engaged_5_sessions,
COUNT(DISTINCT s3.user_id) AS power_users,
ROUND(100.0 * COUNT(DISTINCT s3.user_id) / NULLIF(COUNT(DISTINCT s1.user_id), 0), 2
) AS conversion_rate
FROM stage_1 s1
LEFT JOIN stage_2 s2 USING (user_id, nation)
LEFT JOIN stage_3 s3 USING (user_id, nation)
GROUP BY nation;Ausgabe:

Muster: Die Trichteranalyse zeigt, wie Benutzer eine Reihe geordneter Phasen durchlaufen. Da die Analyse vom Abschluss der vorangehenden Analyse abhängt, konzentriert sie sich auf Konvertierung und Drop-off.
Hier ist die Reihenfolge.
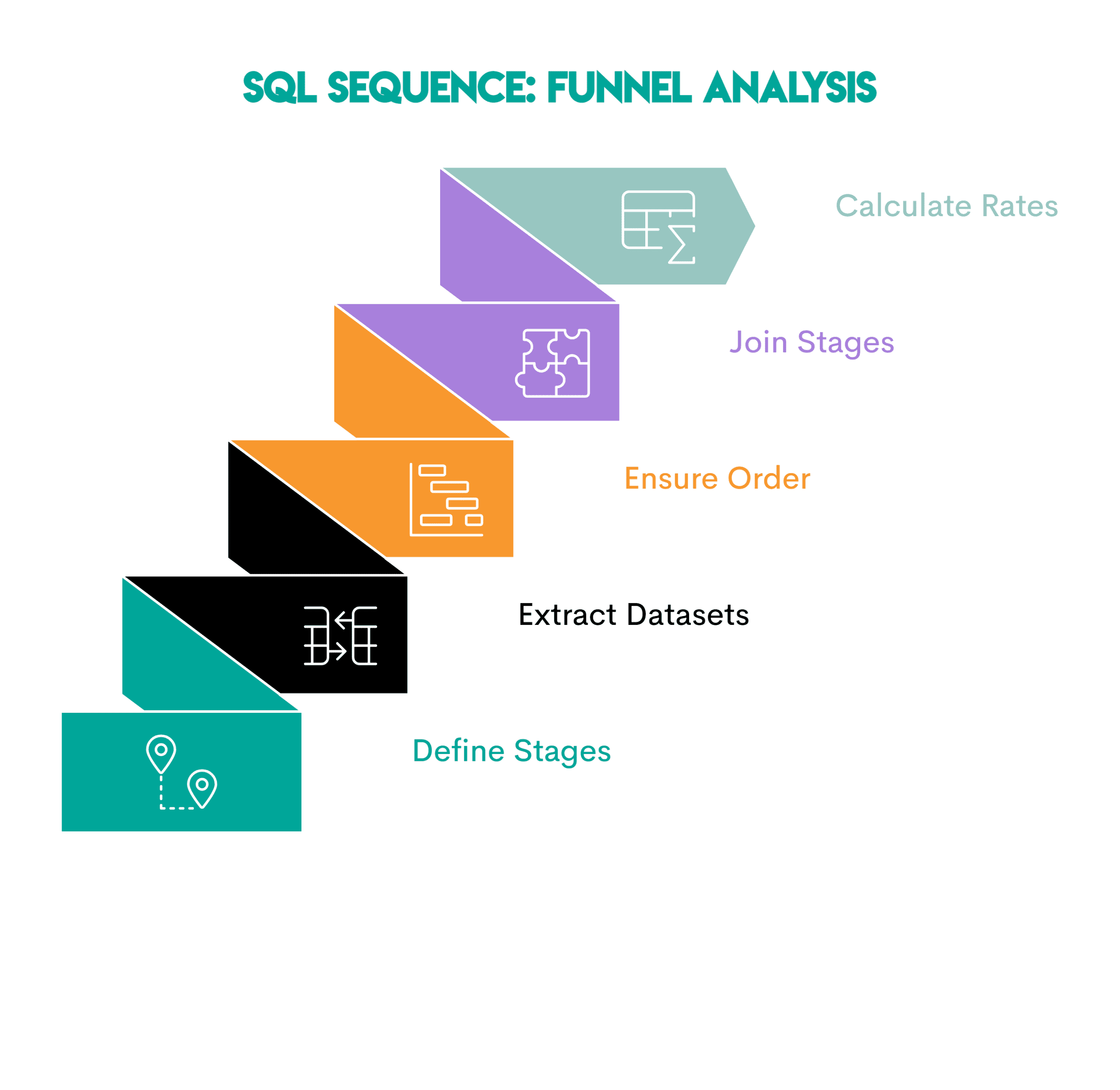
- Definieren Sie die Phasen: Identifizieren Sie jeden Schritt, den ein Benutzer ausführen muss
- Extrahieren Sie einen Datensatz professional Stufe: Schreiben Sie für jede Stufe einen gemeinsamen Tabellenausdruck (CTE) oder eine Unterabfrage, die nur die qualifizierten Benutzer enthält
- Stellen Sie die Phasenreihenfolge sicher: Filtern Sie bei Bedarf nach Zeitstempeln oder Sequenzregeln, sodass spätere Phasen nach früheren auftreten
- Den Phasen beitreten: Die Phasendatensätze mit verbinden
LEFT JOINum zu sehen, wie viele Benutzer jeden Schritt erreichen - Zählen Sie die Benutzer und berechnen Sie die Konversionsraten: Vergleichen Sie die Anzahl der Benutzer in jeder Section
// Geschäftliche Nutzung
- E-Commerce: Besuchen Sie -> In den Warenkorb -> Kaufen
- SaaS: Anmelden -> Aktivieren -> Behalten
- Streaming: Einmal anhören -> Regelmäßig teilnehmen -> Energy-Consumer werden
# 7. Zeitbasierter Vergleich: Periodenbezogene Kennzahlen
Frage: Tägliche Verstöße gegen die Stadt San Francisco
Aufgabe: Bestimmen Sie die Veränderung der Anzahl der täglichen Verstöße, indem Sie die Differenz zwischen der Anzahl der aktuellen und früheren Verstöße nach Inspektionsdatum berechnen.
Zeigen Sie das Inspektionsdatum und die Veränderung der Anzahl der täglichen Verstöße an, geordnet von der frühesten bis zur letzten Inspektion.
Lösung:
SELECT inspection_date::DATE,
COUNT(violation_id) - LAG(COUNT(violation_id)) OVER(ORDER BY inspection_date::DATE) AS diff
FROM sf_restaurant_health_violations
GROUP BY 1
ORDER BY 1;Ausgabe:
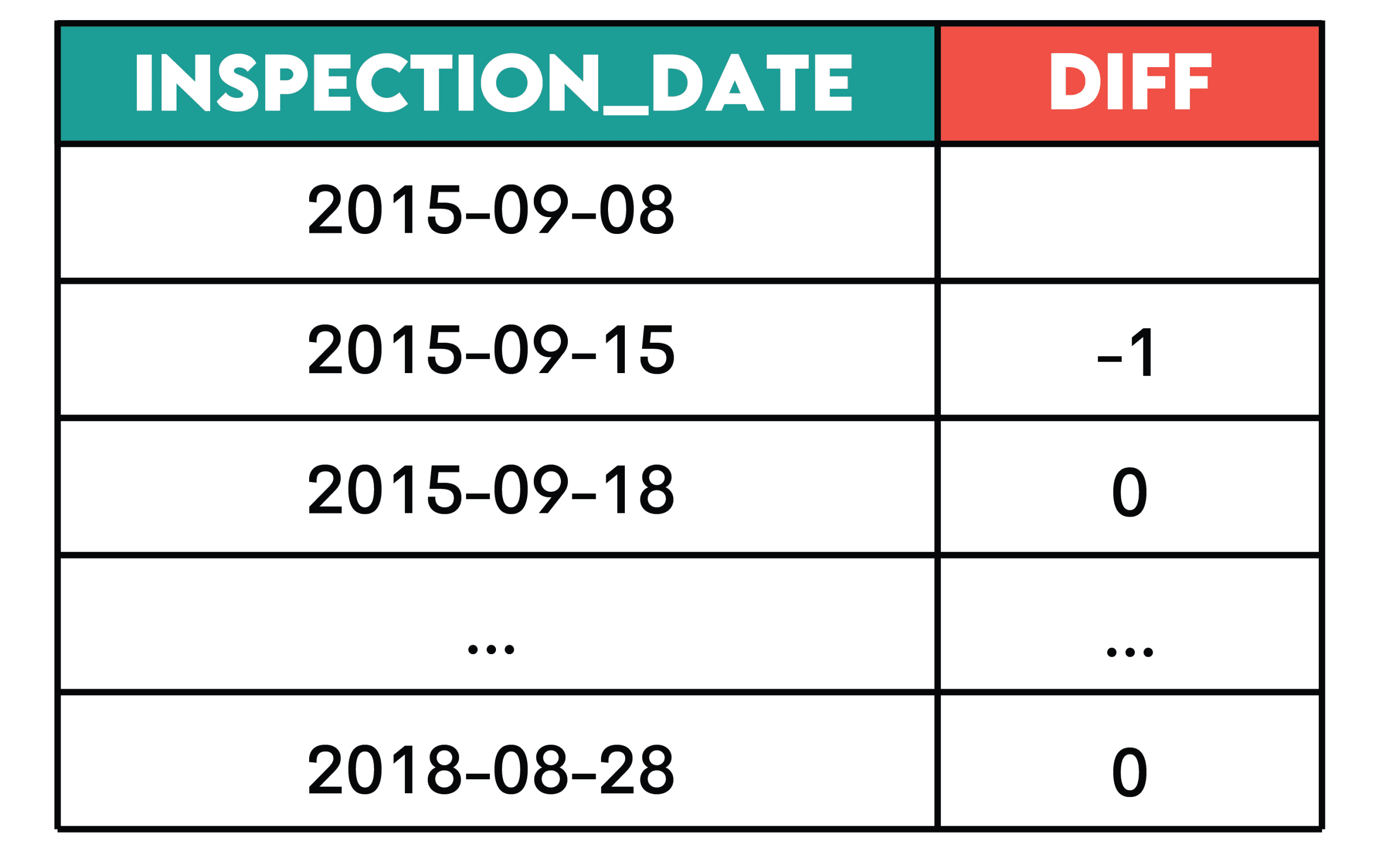
Muster: Dieses Muster ist nützlich, wenn Sie sehen möchten, wie sich eine Metrik im Laufe der Zeit ändert.
Hier ist die Reihenfolge.
- Daten aggregieren: Fassen Sie die Ereignisse in Zeiträumen zusammen (tägliche/wöchentliche/monatliche Summen).
- Wenden Sie eine Fensterfunktion an: Verwenden
LAG()oderLEAD()um auf die Werte der vorherigen oder folgenden Periode zuzugreifen - Ordnen Sie die Zeiträume: Verwenden Sie die
ORDER BYKlausel inOVER()um die Daten chronologisch zu sortieren, damit Vergleiche korrekt sind - Berechnen Sie die Differenz: Subtrahieren Sie den vorherigen Wert vom aktuellen Wert, um die Differenz zu erhalten
// Geschäftliche Nutzung
- Produkt: Tägliche Änderungen bei aktiven Benutzern
- Operationen: Tägliche Änderungen im Supportvolumen
- Finanzen: Umsatzdeltas im Monatsvergleich
# Zusammenfassung
Verinnerlichen Sie diese sieben Muster und beobachten Sie, wie sich die Datenanalyseprobleme vor Ihren Augen auflösen. Ich bin sicher, dass sie in vielen Geschäftssituationen und Vorstellungsgesprächen hilfreich sein werden.
Nate Rosidi ist Datenwissenschaftler und in der Produktstrategie tätig. Er ist außerdem außerordentlicher Professor für Analytik und Gründer von StrataScratch, einer Plattform, die Datenwissenschaftlern hilft, sich mit echten Interviewfragen von Prime-Unternehmen auf ihre Interviews vorzubereiten. Nate schreibt über die neuesten Tendencies auf dem Karrieremarkt, gibt Ratschläge zu Vorstellungsgesprächen, stellt Knowledge-Science-Projekte vor und behandelt alles rund um SQL.