

Bild vom Autor
# Einführung
Erinnern Sie sich noch daran, dass für die Erstellung einer Full-Stack-Anwendung teure Cloud-Credit, kostspielige API-Schlüssel und ein Crew von Ingenieuren erforderlich waren? Diese Zeiten sind offiziell vorbei. Bis 2026 können Entwickler eine produktionsreife Anwendung nur mit kostenlosen Instruments erstellen, bereitstellen und skalieren große Sprachmodelle (LLMs), die seine Intelligenz antreiben.
Die Landschaft hat sich dramatisch verändert. Open-Supply-Modelle fordern mittlerweile ihre kommerziellen Gegenstücke heraus. Kostenlose KI-Codierungsassistenten haben sich von einfachen Autovervollständigungstools zu vollständigen Coding-Agenten entwickelt, die ganze Funktionen entwerfen können. Und was vielleicht am wichtigsten ist: Sie können hochmoderne Modelle lokal oder über großzügige kostenlose Kontingente betreiben, ohne einen Cent auszugeben.
In diesem umfassenden Artikel werden wir eine reale Anwendung erstellen – eine Zusammenfassung von KI-Besprechungsnotizen. Benutzer laden Sprachaufzeichnungen hoch und unsere App transkribiert sie, extrahiert wichtige Punkte und Aktionselemente und zeigt alles in einem übersichtlichen Dashboard an – und das alles mit völlig kostenlosen Instruments.
Ganz gleich, ob Sie Scholar, Bootcamp-Absolvent oder erfahrener Entwickler sind, der eine Idee prototypisieren möchte, dieses Tutorial zeigt Ihnen, wie Sie die besten verfügbaren kostenlosen KI-Instruments nutzen können. Beginnen Sie damit, zu verstehen, warum kostenlose LLMs heute so intestine funktionieren.
# Verstehen, warum kostenlose große Sprachmodelle jetzt funktionieren
Noch vor zwei Jahren bedeutete die Entwicklung einer KI-gestützten App, dass man ein Funds für OpenAI-API-Credit einplanen oder teure GPU-Instanzen mieten musste. Die Wirtschaftslage hat sich grundlegend verändert.
Die Kluft zwischen kommerziellen und Open-Supply-LLMs ist nahezu verschwunden. Fashions mögen GLM-4.7-Flash von Zhipu AI zeigen, dass Open-Supply eine Leistung auf dem neuesten Stand der Technik erzielen und gleichzeitig völlig kostenlos genutzt werden kann. Ähnlich, LFM2-2.6B-Transkript wurde speziell für die Zusammenfassung von Besprechungen entwickelt und läuft vollständig auf dem Gerät mit Qualität auf Cloud-Ebene.
Für Sie bedeutet das, dass Sie nicht mehr an einen einzigen Anbieter gebunden sind. Wenn ein Modell für Ihren Anwendungsfall nicht funktioniert, können Sie zu einem anderen wechseln, ohne Ihre Infrastruktur zu ändern.
// Treten Sie der Self-Hosted-Bewegung bei
Es gibt eine wachsende Präferenz für lokale KI, die Modelle auf Ihrer eigenen {Hardware} ausführt, anstatt Daten an die Cloud zu senden. Dabei geht es nicht nur um die Kosten; es geht um Privatsphäre, Latenz und Kontrolle. Mit Werkzeugen wie Ollama Und LM Studiokönnen Sie leistungsstarke Modelle auf einem Laptop computer ausführen.
// Einführung des „Deliver Your Personal Key“-Modells
Es ist eine neue Kategorie von Instruments entstanden: Open-Supply-Anwendungen, die kostenlos sind, aber die Bereitstellung eigener API-Schlüssel erfordern. Das gibt Ihnen höchste Flexibilität. Sie können Googles verwenden Gemini-API (das täglich Hunderte von kostenlosen Anfragen bietet) oder vollständig lokale Modelle ohne laufende Kosten betreiben.
# Wählen Sie Ihren kostenlosen Stack für künstliche Intelligenz
Um die besten kostenlosen Optionen für jede Komponente unserer Anwendung aufzuschlüsseln, müssen Instruments ausgewählt werden, die Leistung und Benutzerfreundlichkeit in Einklang bringen.
// Transkriptionsebenen: Speech-to-Textual content
Für die Konvertierung von Audio in Textual content verfügen wir über hervorragende kostenlose Speech-to-Textual content-Instruments (STT).
| Werkzeug | Typ | Kostenloses Kontingent | Am besten für |
|---|---|---|---|
| OpenAI Whisper | Open-Supply-Modell | Unbegrenzt (selbst gehostet) | Genauigkeit, mehrere Sprachen |
| Whisper.cpp | Datenschutzorientierte Umsetzung | Unbegrenzt (Open-Supply) | Datenschutzrelevante Szenarien |
| Gemini-API | Cloud-API | 60 Anfragen/Minute | Schnelles Prototyping |
Für unser Projekt werden wir verwenden Flüsterndas Sie lokal oder über kostenlos gehostete Optionen ausführen können. Es unterstützt über 100 Sprachen und erstellt hochwertige Transkripte.
// Zusammenfassung und Analyse: Das große Sprachmodell
Hier haben Sie die größte Auswahl. Alle unten aufgeführten Optionen sind völlig kostenlos:
| Modell | Anbieter | Typ | Spezialisierung |
|---|---|---|---|
| GLM-4.7-Flash | Zhipu KI | Cloud (kostenlose API) | Allgemeiner Zweck, Codierung |
| LFM2-2.6B-Transkript | Flüssige KI | Lokal/auf dem Gerät | Zusammenfassung der Besprechung |
| Gemini 1.5 Flash | Cloud-API | Langer Kontext, kostenlose Stufe | |
| GPT-OSS-Schwalbe | Tokio Tech | Lokal/selbst gehostet | Japanisch/englisches Denken |
Für unsere Besprechungszusammenfassung, die LFM2-2.6B-Transkript Modell ist besonders interessant; Es wurde buchstäblich für genau diesen Anwendungsfall trainiert und läuft mit weniger als 3 GB RAM.
// Beschleunigte Entwicklung: Codierungsassistenten für künstliche Intelligenz
Bevor wir eine einzige Codezeile schreiben, denken Sie über die Instruments nach, die uns helfen, innerhalb der integrierten Entwicklungsumgebung (IDE) effizienter zu bauen:
| Werkzeug | Kostenloses Kontingent | Typ | Hauptmerkmal |
|---|---|---|---|
| Comate | Völlig kostenlos | VS Code-Erweiterung | SPEC-gesteuert, Multi-Agent |
| Codeium | Unbegrenzt kostenlos | IDE-Erweiterung | Über 70 Sprachen, schnelle Schlussfolgerung |
| Cline | Kostenlos (BYOK) | VS Code-Erweiterung | Autonome Dateibearbeitung |
| Weitermachen | Vollständig Open Supply | IDE-Erweiterung | Funktioniert mit jedem LLM |
| Bolt.diy | Selbst gehostet | Browser-IDE | Full-Stack-Generierung |
Unsere Empfehlung: Für dieses Projekt werden wir Codeium wegen seines unbegrenzten kostenlosen Kontingents und seiner Geschwindigkeit verwenden und Proceed als Backup behalten, wenn wir zwischen verschiedenen LLM-Anbietern wechseln müssen.
// Überprüfung des traditionellen kostenlosen Stacks
- Frontend: Reagieren (kostenlos und Open-Supply)
- Backend: FastAPI (Python, kostenlos)
- Datenbank: SQLite (dateibasiert, kein Server erforderlich)
- Einsatz: Vercel (großzügiges kostenloses Kontingent) + Machen (für Backend)
# Überprüfung des Projektplans
Definieren des Bewerbungsworkflows:
- Der Benutzer lädt eine Audiodatei hoch (Besprechungsaufzeichnung, Sprachnotiz, Vortrag).
- Das Backend empfängt die Datei und übergibt sie zur Transkription an Whisper
- Der transkribierte Textual content wird zur Zusammenfassung an ein LLM gesendet
- Das LLM extrahiert wichtige Diskussionspunkte, Aktionspunkte und Entscheidungen
- Die Ergebnisse werden in SQLite gespeichert
- Der Benutzer sieht ein übersichtliches Dashboard mit Transkript, Zusammenfassung und Aktionselementen
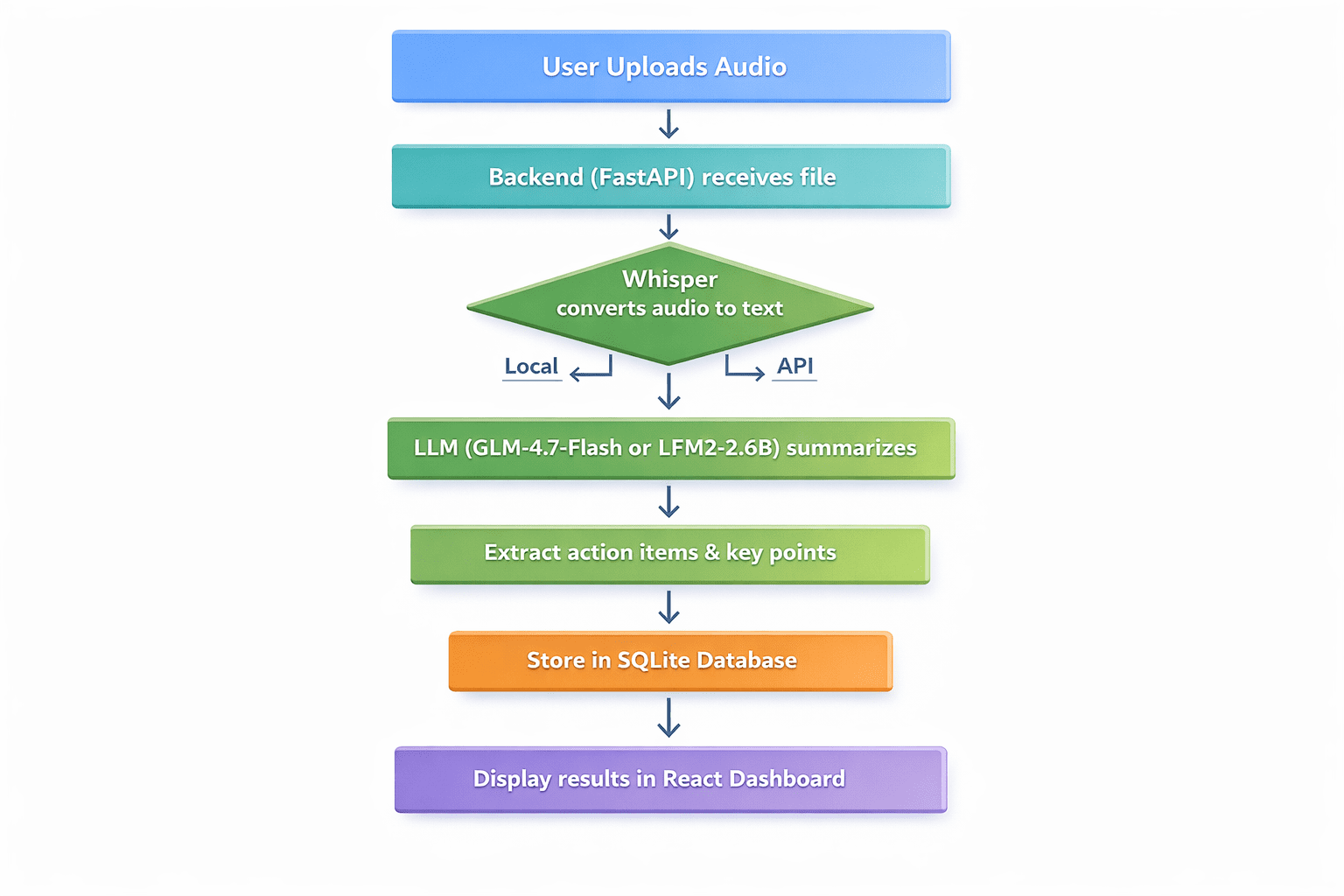
Professionelles Flussdiagramm mit sieben aufeinanderfolgenden Schritten | Bild vom Autor
// Voraussetzungen
- Python 3.9+ installiert
- Node.js und npm installiert
- Grundlegende Vertrautheit mit Python und React
- Ein Code-Editor (VS-Code empfohlen)
// Schritt 1: Einrichten des Backends mit FastAPI
Erstellen Sie zunächst unser Projektverzeichnis und richten Sie eine virtuelle Umgebung ein:
mkdir meeting-summarizer
cd meeting-summarizer
python -m venv venvAktivieren Sie die virtuelle Umgebung:
# On Home windows
venvScriptsactivate
# On Linux/macOS
supply venv/bin/activateInstallieren Sie die erforderlichen Pakete:
pip set up fastapi uvicorn python-multipart openai-whisper transformers torch openaiErstellen Sie nun die fundamental.py Datei für unsere FastAPI-Anwendung und fügen Sie diesen Code hinzu:
from fastapi import FastAPI, File, UploadFile, HTTPException
from fastapi.middleware.cors import CORSMiddleware
import whisper
import sqlite3
import json
import os
from datetime import datetime
app = FastAPI()
# Allow CORS for React frontend
app.add_middleware(
CORSMiddleware,
allow_origins=("http://localhost:3000"),
allow_methods=("*"),
allow_headers=("*"),
)
# Initialize Whisper mannequin - utilizing "tiny" for quicker CPU processing
print("Loading Whisper mannequin (tiny)...")
mannequin = whisper.load_model("tiny")
print("Whisper mannequin loaded!")
# Database setup
def init_db():
conn = sqlite3.join('conferences.db')
c = conn.cursor()
c.execute('''CREATE TABLE IF NOT EXISTS conferences
(id INTEGER PRIMARY KEY AUTOINCREMENT,
filename TEXT,
transcript TEXT,
abstract TEXT,
action_items TEXT,
created_at TIMESTAMP)''')
conn.commit()
conn.shut()
init_db()
async def summarize_with_llm(transcript: str) -> dict:
"""Placeholder for LLM summarization logic"""
# This can be carried out in Step 2
return {"abstract": "Abstract pending...", "action_items": ()}
@app.publish("/add")
async def upload_audio(file: UploadFile = File(...)):
file_path = f"temp_{file.filename}"
with open(file_path, "wb") as buffer:
content material = await file.learn()
buffer.write(content material)
attempt:
# Step 1: Transcribe with Whisper
outcome = mannequin.transcribe(file_path, fp16=False)
transcript = outcome("textual content")
# Step 2: Summarize (To be stuffed in Step 2)
summary_result = await summarize_with_llm(transcript)
# Step 3: Save to database
conn = sqlite3.join('conferences.db')
c = conn.cursor()
c.execute(
"INSERT INTO conferences (filename, transcript, abstract, action_items, created_at) VALUES (?, ?, ?, ?, ?)",
(file.filename, transcript, summary_result("abstract"),
json.dumps(summary_result("action_items")), datetime.now())
)
conn.commit()
meeting_id = c.lastrowid
conn.shut()
os.take away(file_path)
return {
"id": meeting_id,
"transcript": transcript,
"abstract": summary_result("abstract"),
"action_items": summary_result("action_items")
}
besides Exception as e:
if os.path.exists(file_path):
os.take away(file_path)
elevate HTTPException(status_code=500, element=str(e))// Schritt 2: Integration des kostenlosen großen Sprachmodells
Lassen Sie uns nun das implementieren summarize_with_llm() Funktion. Wir zeigen zwei Ansätze:
Choice A: Verwendung der GLM-4.7-Flash-API (Cloud, kostenlos)
from openai import OpenAI
async def summarize_with_llm(transcript: str) -> dict:
shopper = OpenAI(api_key="YOUR_FREE_ZHIPU_KEY", base_url="https://open.bigmodel.cn/api/paas/v4/")
response = shopper.chat.completions.create(
mannequin="glm-4-flash",
messages=(
{"function": "system", "content material": "Summarize the next assembly transcript and extract motion gadgets in JSON format."},
{"function": "person", "content material": transcript}
),
response_format={"sort": "json_object"}
)
return json.masses(response.decisions(0).message.content material)Choice B: Verwendung des lokalen LFM2-2.6B-Transkripts (lokal, völlig kostenlos)
from transformers import AutoModelForCausalLM, AutoTokenizer
import torch
async def summarize_with_llm_local(transcript):
model_name = "LiquidAI/LFM2-2.6B-Transcript"
tokenizer = AutoTokenizer.from_pretrained(model_name)
mannequin = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype=torch.float16,
device_map="auto"
)
immediate = f"Analyze this transcript and supply a abstract and motion gadgets:nn{transcript}"
inputs = tokenizer(immediate, return_tensors="pt").to(mannequin.system)
with torch.no_grad():
outputs = mannequin.generate(**inputs, max_new_tokens=500)
return tokenizer.decode(outputs(0), skip_special_tokens=True)// Schritt 3: Erstellen des React-Frontends
Erstellen Sie ein einfaches React-Frontend, um mit unserer API zu interagieren. Erstellen Sie in einem neuen Terminal eine React-App:
npx create-react-app frontend
cd frontend
npm set up axiosErsetzen Sie den Inhalt von src/App.js mit:
import React, { useState } from 'react';
import axios from 'axios';
import './App.css';
perform App() {
const (file, setFile) = useState(null);
const (importing, setUploading) = useState(false);
const (outcome, setResult) = useState(null);
const (error, setError) = useState('');
const handleUpload = async () => {
if (!file) { setError('Please choose a file'); return; }
setUploading(true);
const formData = new FormData();
formData.append('file', file);
attempt {
const response = await axios.publish('http://localhost:8000/add', formData);
setResult(response.information);
} catch (err) err.message));
lastly { setUploading(false); }
};
return (
<div className="App">
<header className="App-header"><h1>AI Assembly Summarizer</h1></header>
<fundamental className="container">
<div className="upload-section">
<enter sort="file" onChange={(e) => setFile(e.goal.information(0))} disabled={importing} />
<button onClick={handleUpload} disabled= importing>
{importing ? 'Processing...' : 'Analyze'}
</button>
{error && <p className="error">{error}</p>}
</div>
{outcome && (
<div className="outcomes">
<h4>Abstract</h4><p>{outcome.abstract}</p>
<h4>Motion Gadgets</h4>
<ul>{outcome.action_items.map((it, i) => <li key={i}>{it}</li>)}</ul>
</div>
)}
</fundamental>
</div>
);
}
export default App;// Schritt 4: Ausführen der Anwendung
- Starten Sie das Backend: Führen Sie im Hauptverzeichnis bei aktiver virtueller Umgebung Folgendes aus
uvicorn fundamental:app --reload - Starten Sie das Frontend: Führen Sie in einem neuen Terminal im Frontend-Verzeichnis Folgendes aus
npm begin - Offen http://localhost:3000 in Ihrem Browser und laden Sie eine Take a look at-Audiodatei hoch
Dashboard-Oberfläche mit zusammenfassenden Ergebnissen | Bild vom Autor
# Kostenlose Bereitstellung der Anwendung
Sobald Ihre App lokal funktioniert, ist es an der Zeit, sie weltweit bereitzustellen – immer noch kostenlos. Machen bietet ein großzügiges kostenloses Kontingent für Webdienste. Schieben Sie Ihren Code in ein GitHub-Repository, erstellen Sie einen neuen Webdienst auf Render und verwenden Sie diese Einstellungen:
- Umgebung: Python 3
- Construct-Befehl:
pip set up -r necessities.txt - Startbefehl:
uvicorn fundamental:app --host 0.0.0.0 --port $PORT
Erstellen Sie eine necessities.txt Datei:
fastapi
uvicorn
python-multipart
openai-whisper
transformers
torch
openaiNotiz: Whisper und Transformers benötigen viel Speicherplatz. Wenn Sie an die Grenzen des kostenlosen Kontingents stoßen, sollten Sie stattdessen die Verwendung einer Cloud-API für die Transkription in Betracht ziehen.
// Bereitstellen des Frontends auf Vercel
Vercel ist der einfachste Weg, React-Apps bereitzustellen:
- Installieren Sie die Vercel-CLI:
npm i -g vercel - Führen Sie in Ihrem Frontend-Verzeichnis Folgendes aus:
vercel - Aktualisieren Sie Ihre API-URL in
App.jsum auf Ihr Render-Backend zu verweisen
// Erkundung lokaler Bereitstellungsalternativen
Wenn Sie Cloud-Internet hosting vollständig vermeiden möchten, können Sie sowohl Frontend als auch Backend auf einem lokalen Server bereitstellen, indem Sie Instruments wie verwenden ngrok um Ihren lokalen Server vorübergehend verfügbar zu machen.
# Abschluss
Wir haben gerade eine produktionsreife KI-Anwendung mit ausschließlich kostenlosen Instruments erstellt. Fassen wir zusammen, was wir erreicht haben:
- Transkription: Verwendet Whisper von OpenAI (kostenlos, Open Supply)
- Zusammenfassung: Leveraged GLM-4.7-Flash oder LFM2-2.6B (beide völlig kostenlos)
- Backend: Mit FastAPI erstellt (kostenlos)
- Frontend: Erstellt mit React (kostenlos)
- Datenbank: Gebrauchtes SQLite (kostenlos)
- Bereitstellung: Bereitstellung auf Vercel und Render (kostenlose Stufen)
- Entwicklung: Beschleunigt mit kostenlosen KI-Codierungsassistenten wie Codeium
Die Landschaft für die kostenlose KI-Entwicklung warfare noch nie so vielversprechend. Open-Supply-Modelle konkurrieren mittlerweile mit kommerziellen Angeboten. Lokale KI-Instruments geben uns Privatsphäre und Kontrolle. Und großzügige kostenlose Stufen von Anbietern wie Google und Zhipu AI ermöglichen uns Prototypen ohne finanzielles Risiko.
Shittu Olumid ist ein Software program-Ingenieur und technischer Autor, der sich leidenschaftlich dafür einsetzt, modernste Technologien zu nutzen, um fesselnde Erzählungen zu erschaffen, mit einem scharfen Blick fürs Element und einem Gespür für die Vereinfachung komplexer Konzepte. Sie können Shittu auch auf finden Twitter.