
Die KI-Spracherzeugung hat ein großes Drawback. Es funktioniert wie ein Roboter, der ein Skript Satz für Satz liest, ohne Gefühle oder Emotionen. Es magazine klug sein, aber es ist weniger wichtig, wenn damit kein menschliches Gefühl verbunden ist. Die Artwork und Weise, wie die KI ihre Stimme erzeugt, macht es schwierig, das Gefühl zu haben, dass Sie ein substanzielles Gespräch führen.
Das hat sich alles geändert mit Google DeepMind Veröffentlichung des Gemini 3.1 Flash TTS am 15. April 2026. Dieses TTS ist nicht nur ein fortschrittlicher Sprachsynthesizer, sondern fungiert jetzt auch als KI-Sprachdirektor!
Mit dieser Technologie können Sie ein Synchronsprecherstudio ohne echte Ausrüstung erstellen, indem Sie einfach einen API-Aufruf verwenden oder in Google Studio. Schauen wir uns nun die neuen Funktionen dieser Technologie an, was sie für Sie bedeutet und vor allem drei reale Projekte, die Sie damit erstellen und sofort nutzen können!
Was macht Gemini 3.1 Flash TTS anders?
In früheren Versionen von AI TTS struggle die einzige Choice für Sie die einfache Sprach- und Geschwindigkeitssteuerung. Der Gemini 3.1 Flash TTS ist eine deutliche Verbesserung gegenüber früheren Generationen und bietet eine Vielzahl neuer Funktionen.

Zu den neuen Funktionen von Gemini 3.1 Flash TTS gehören:
- Audio-Tags: Fügen Sie Ihrem Transkript „Regieanweisungen“ in natürlicher Sprache hinzu. Wenn Sie dem Modell beispielsweise sagen, es solle aufgeregt klingen, ein Geheimnis flüstern oder eine Pause einlegen, bevor es fortfährt, führt dies dazu, dass das Modell die gewünschte Leistung erbringt.
- Szenenanweisungen: Definieren Sie den Umgebungs- und Erzählkontext für das gesamte Drehbuch und stellen Sie sicher, dass die Charaktere für mehrere aufeinanderfolgende Dialogstücke automatisch ihre Charaktere behalten.
- Charakterprofile: Erstellen Sie einzigartige, aktuelle Audioprofile für jeden Charakter. Wenden Sie die Notizen Ihres Regisseurs an, um die Wiedergabe des Audioprofils jedes Charakters in Bezug auf Tempo, Ton und Akzent festzulegen.
- Inline-Pivot-Tags: Sprecher können schnell von „Regular“ zu „Panik“ wechseln, ohne dass ein separater API-Aufruf erforderlich ist, selbst wenn sie sich mitten in einem Dialog befinden.
- Exportierbare Einstellungen: Sobald die Stimme konfiguriert wurde, exportieren Sie die genaue Konfiguration zur sofortigen Verwendung in den Gemini-API-Code.
Jede mit Gemini 3.1 erstellte Audiodatei ist mit „SynthID“ eingebettet, einer unsichtbaren Audiosignatur, die von Google DeepMind entwickelt wurde, um die Verwendung synthetischer Audiodateien zu verfolgen. Es bietet im Grunde eine Methode zur Erkennung synthetischer Audiodaten aus traditionell produzierten Audiodateien.
Erste Schritte mit Gemini 3.1 Flash TTS
Das Gemini 3.1 Flash TTS verfügt derzeit über drei verfügbare, zugängliche Plattformen:
- Entwicklerbenutzer können über die API von Gemini und das Google AI Studio eine Vorschau anzeigen
- Unternehmensbenutzer können über Vertex AI eine Vorschau anzeigen
- Google Vids steht nur Workspace-Nutzern zur Verfügung
Für die beiden folgenden Beispiele, die die API-Technologie nutzen, fordern Sie bitte unbedingt ein kostenloses an Gemini-API-Schlüssel zur Nutzung durch den Besuch von aistudio.google.com. Für den Zugriff auf das dritte Beispiel ist lediglich ein Webbrowser erforderlich.
App 1: Erstellen Sie mit der Gemini-API einen emotionalen Hörbuch-Erzähler
In unserem realen Check des Gemini 3.1 Flash TTS werden wir ein Python-Programm erstellen, um mithilfe von Audio-Tags reine Textgeschichten in Hörbücher mit deutlichen emotionalen Klängen umzuwandeln. Auf diese Weise können Audio-Tags die Qualität des TTS-Audios im Hörbuchprozess drastisch verbessern. Hörbuch-TTS hat im Allgemeinen einen monotonen Ton; Wenn Sie jedoch die Emotionen über die Audio-Tags professional Szene steuern, sollte es einen spürbaren Unterschied in der Audioausgabe geben.
Anweisungen:
1. Installieren Sie das Gemini Python SDK:
pip set up google-generativeai2. Erstellen Sie eine Datei mit dem Namen audiobook.py und fügen Sie den folgenden Code ein:
import google.generativeai as genai
import base64
genai.configure(api_key="YOUR_API_KEY")
story = """
(calm, sluggish, hushed narrator voice)
The outdated home had been empty for thirty years.
(constructing stress, slight tremor in voice)
As she pushed open the door, the floorboards groaned beneath her.
(sharp, alarmed, fast-paced)
Then she noticed it. A shadow. Shifting towards her.
(relieved exhale, heat and tender)
It was simply the cat. An outdated tabby, blinking up at her in the dead of night.
"""
consumer = genai.Consumer()
response = consumer.fashions.generate_content(
mannequin="gemini-3.1-flash-tts-preview",
contents=story,
config={
"response_modalities": ("AUDIO"),
"speech_config": {
"voice_config": {
"prebuilt_voice_config": {"voice_name": "Kore"}
}
}
}
)
audio_data = response.candidates(0).content material.elements(0).inline_data.information
wav_bytes = base64.b64decode(audio_data)
with open("audiobook_output.wav", "wb") as f:
f.write(wav_bytes)
print("Saved: audiobook_output.wav") 3. Ersetzen Sie den Platzhalter „YOUR_API_KEY“ durch Ihren eigenen API-SCHLÜSSEL und führen Sie das Programm aus
python audiobook.py4. Öffnen Sie die Audiodatei unter audiobook_output.wav und hören Sie sie sich an
Die in Klammern angegebenen Regieanweisungen geben an, wie der Erzähler jedes Kapitel eines Hörbuchs emotional interpretieren soll. Wenn der Erzähler beispielsweise jedes Kapitel liest, wechselt er von einem ruhigen Flüstern zu Verwirrung und Panik, gefolgt von einer ruhigen Erleichterung in einer fortlaufenden Audioaufnahme.
Ausgabe:
Verbessern Sie es weiter: Suchen Sie ein beliebiges Kapitel auf der Web site von Mission Gutenberg und verwenden Sie es im Hörbuch. Anschließend durchlaufen Sie den Absatz in einem Kapitel. Sie können die Stimmung für jeden Absatz auch mit den Stimmungs-Audio-Tags markieren, um Ihre eigenen Hörbücher zu erstellen. Mit dieser Methode sollten Sie in der Lage sein, sofort und ohne großen Aufwand im Studio ein ausdrucksstarkes Hörbuch zu erstellen.
App 2: Podcast-Generator für mehrere Charaktere mithilfe der Gemini-API
In diesem Testfall verwenden wir die Multi-Speaker/Host-Funktion von Gemini 3.1 Flash Textual content-to-Speech. Dazu erstellen wir ein Podcast-Skript mit zwei Stimmen (zwei getrennten Geschwindigkeiten, Tönen und Einstellungen) aus einem einzigen API-Aufruf innerhalb derselben Audiodatei.
Interessanterweise ist es nicht erforderlich, zwei API-Aufrufe zu verbinden, und es ist hierfür keine Nachbearbeitung erforderlich. Geben Sie einfach eine einzige Eingabeaufforderung an, die zwei verschiedene Persönlichkeiten in eine einzige Audiodatei umwandelt.
Anweisungen:
1. Erstellen Sie ein Skript mit dem Namen „podcast_gen.py“.
import google.generativeai as genai
import base64
genai.configure(api_key="YOUR_API_KEY")
transcript = """
<scene>
Two tech journalists debate whether or not AI voice is overhyped.
Alex is skeptical and speaks shortly with a dry tone.
Jordan is enthusiastic, heat, and barely sooner when excited.
</scene>
<speaker identify="Alex" tempo="quick" tone="dry, skeptical">
Yearly somebody declares that is the AI voice breakthrough.
And yearly, the demos sound nice however actual adoption drags.
</speaker>
<speaker identify="Jordan" tempo="measured" tone="enthusiastic, heat">
However this time the numbers again it up. We're not speaking demos —
we're speaking manufacturing deployments delivery precise product.
</speaker>
<speaker identify="Alex" tone="sharp, sardonic">
Deployments of chatbots that also mispronounce "Worcestershire."
Unbelievable milestone.
</speaker>
<speaker identify="Jordan" tone="laughing, mild">
Okay, truthful. However the trajectory — you genuinely can't argue
with the place that is heading in twelve months.
</speaker>
"""
consumer = genai.Consumer()
response = consumer.fashions.generate_content(
mannequin="gemini-3.1-flash-tts-preview",
contents=transcript,
config={
"response_modalities": ("AUDIO"),
"speech_config": {
"multi_speaker_voice_config": {
"speaker_voice_configs": (
{
"speaker": "Alex",
"voice_config": {
"prebuilt_voice_config": {"voice_name": "Fenrir"}
}
},
{
"speaker": "Jordan",
"voice_config": {
"prebuilt_voice_config": {"voice_name": "Aoede"}
}
}
)
}
}
}
)
audio_data = response.candidates(0).content material.elements(0).inline_data.information
wav_bytes = base64.b64decode(audio_data)
with open("podcast.wav", "wb") as f:
f.write(wav_bytes)
print("Podcast saved: podcast.wav")2. Führen Sie es aus, indem Sie die unten gezeigten Befehle ausführen:
python podcast_gen.py3. Öffnen Sie die Datei „podcast.wav“ und hören Sie sich die beiden unterschiedlichen Stimmen an, die die beiden Persönlichkeiten repräsentieren (die Audioaufnahmen wurden ohne die Verwendung eines Aufnahmestudios erstellt).
Ausgabe:
Verbessern Sie es weiter: Um dies zu vertiefen, richten Sie ein Net-Scrape-Instrument auf einen beliebigen Artikel, den Sie in einer Nachrichtenquelle oder einem Reddit-Thread finden, erstellen Sie eine 10-zeilige Zusammenfassung, die diesen Artikel in ein Skript im Stil einer Zwei-Host-Debatte umwandelt, und senden Sie diese an Ihre Podcast_gen.py. Jetzt verfügen Sie über einen automatisierten „AI Day by day Information Podcast“, der täglich von Ihrer Crontab aus ausgeführt wird.
App 3: Regie eines Filmtrailer-Voice-Overs mit Google AI Studio
The Banana Break up und Liberty Bell arbeiten zusammen, um Ihnen einen atemberaubenden Filmtrailer-Voice-Over zu präsentieren. Sie erledigen alles über die Google AI Studio-Browserkonsole. Daher ist keine Codierung oder zusätzliche Einrichtung erforderlich. Sie werden sich bei diesem Projekt völlig kreativ fühlen, da Sie der Kreativdirektor für dieses Projekt werden.
Dies besteht aus drei Teilen, die wie folgt lauten:
Bereiten Sie das Modell vor
1. Besuchen Sie aistudio.google.com. Melden Sie sich dort mit Ihrem Google-Konto an. Für die kostenlose Nutzung des Dienstes benötigen Sie keine Kreditkarte.
2. Wählen Sie das Modell. Sobald Sie angemeldet sind, wählen Sie die Gemini-3 TTS-Vorschau aus. Der Titel wird in der rechten Seitenleiste unter „Ausführungseinstellungen“ angezeigt.
Stellen Sie die Szene ein
3. Erstellen Sie mithilfe des folgenden Textes eine Szene im bereitgestellten Textfeld oben im Google AI Playground, bevor Sie die männliche oder weibliche Stimme(n) auswählen:
Ein dunkles Kino. Der Bildschirm flackert. Das Publikum hält den Atem an.
Dadurch erhält das Modell einen Kontext, in dem der Charakter für alle Sprecher während der gesamten Produktion erhalten bleibt.
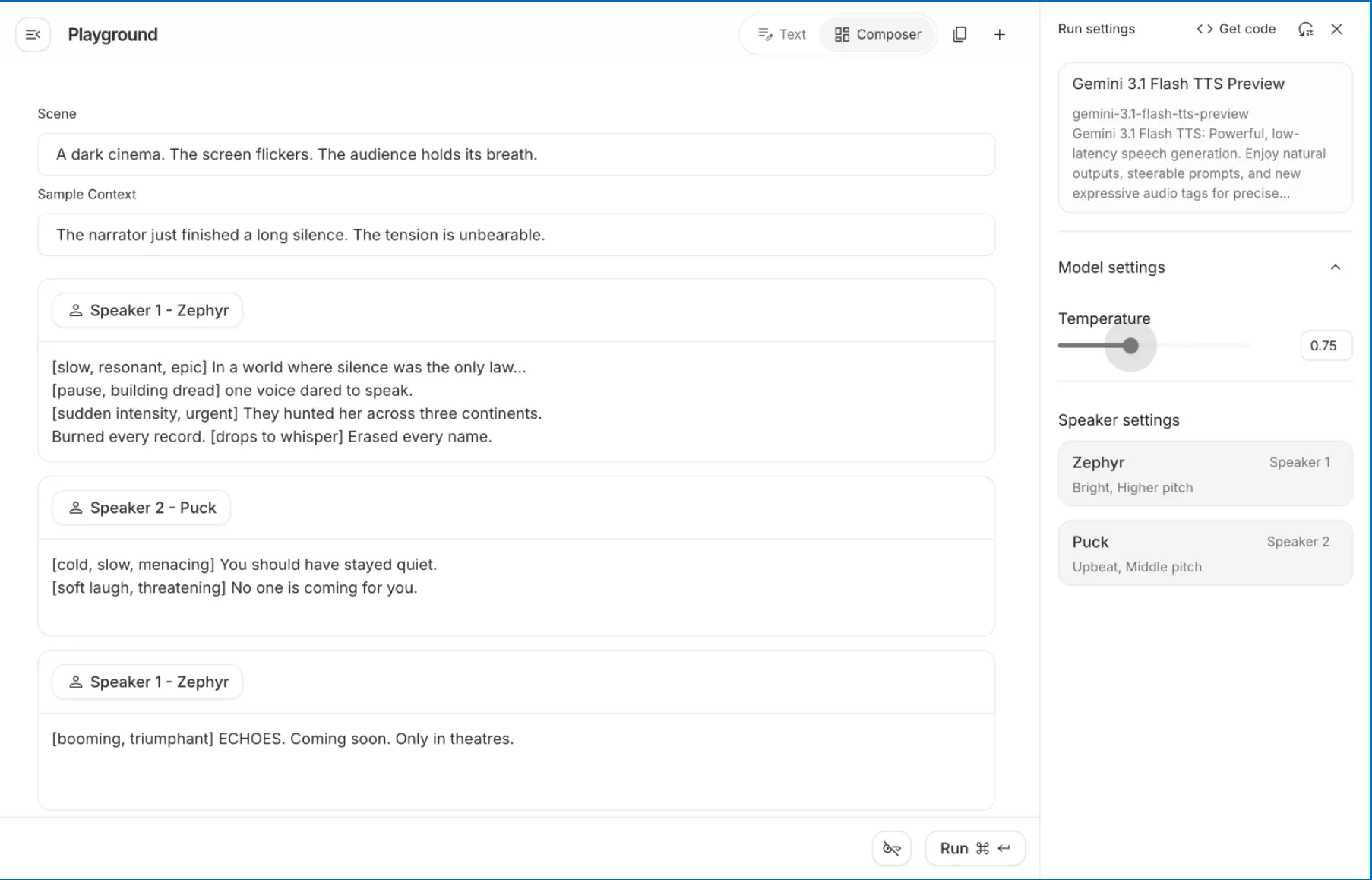
4. Erstellen Sie Ihren Beispielkontext. Geben Sie in diesem Bereich Folgendes ein: Der Erzähler hat gerade ein langes Schweigen beendet. Die körperliche Anspannung ist auf einem unglaublichen Niveau.
Dies teilt dem Modell mit, welche Artwork von emotionalem Zustand vor der Verwendung der ersten Dialogzeile bestand.
Vollständige Sprecherprofile
5. Schließen Sie Sprecher 1 – Zephs (Erzähler-)Dialog ab. Im Panel sehen Sie, dass Zephyr als Lautsprecher 1 mit der Beschreibung „Hell, höhere Tonhöhe“ gekennzeichnet ist. Dies deutet darauf hin, dass er ein eindringlicher und fesselnder Erzähler sein soll, perfekt für einen epischen Geschichtenerzähler. Geben Sie im Dialogblock „Sprecher 1“ Folgendes ein:
(langsam, tief, dramatisch) In einer Welt, in der Stille als „Gesetz“ gilt (Pause, wachsende Angst), wagt eine Stimme zu sprechen. (plötzlich drängend, mit Intensität) Sie jagten sie rund um den Globus und zerstörten alles, was sie fanden. (verringert die Intensität) Mit allen Mitteln verschwunden.
Schließe Sprecher 2 – Pucks (Schurken-)Dialog ab. Sie werden sehen, dass Puck zuvor als „Upbeat, Center Pitch“ bezeichnet wurde; Sie können diese Energie jedoch mit einem Stimmungs-Tag überschreiben. Geben Sie im Dialogblock „Lautsprecher 2“ Folgendes ein:
(kalt, langsam, mit bedrohlicher Miene) Du hättest nie sprechen sollen. (leise lachend, drohend) Es kommt niemand sonst, um dir zu helfen.
Klicken Sie auf „+ Sprachblock hinzufügen“, um am Ende dieses Segments einen weiteren narrativen Abschluss für das Erzählsegment von Sprecher Zephyr hinzuzufügen, und geben Sie Folgendes ein:
(dröhnende, heroische Stimme) Echos. Kommt bald. Nur im Kino.
Ausgabe:
Benchmarks: Wie schlägt sich das eigentlich?
An diesem Punkt können wir eine ganz andere Seite der Geschichte sehen. Obwohl Google nicht sagt, dass sie besser sind als alle anderen, haben sie ihr Gemini 3.1 Flash TTS (Textual content to Speech) dem gründlichsten unabhängigen TTS-Benchmark unterzogen, der jemals erstellt wurde.
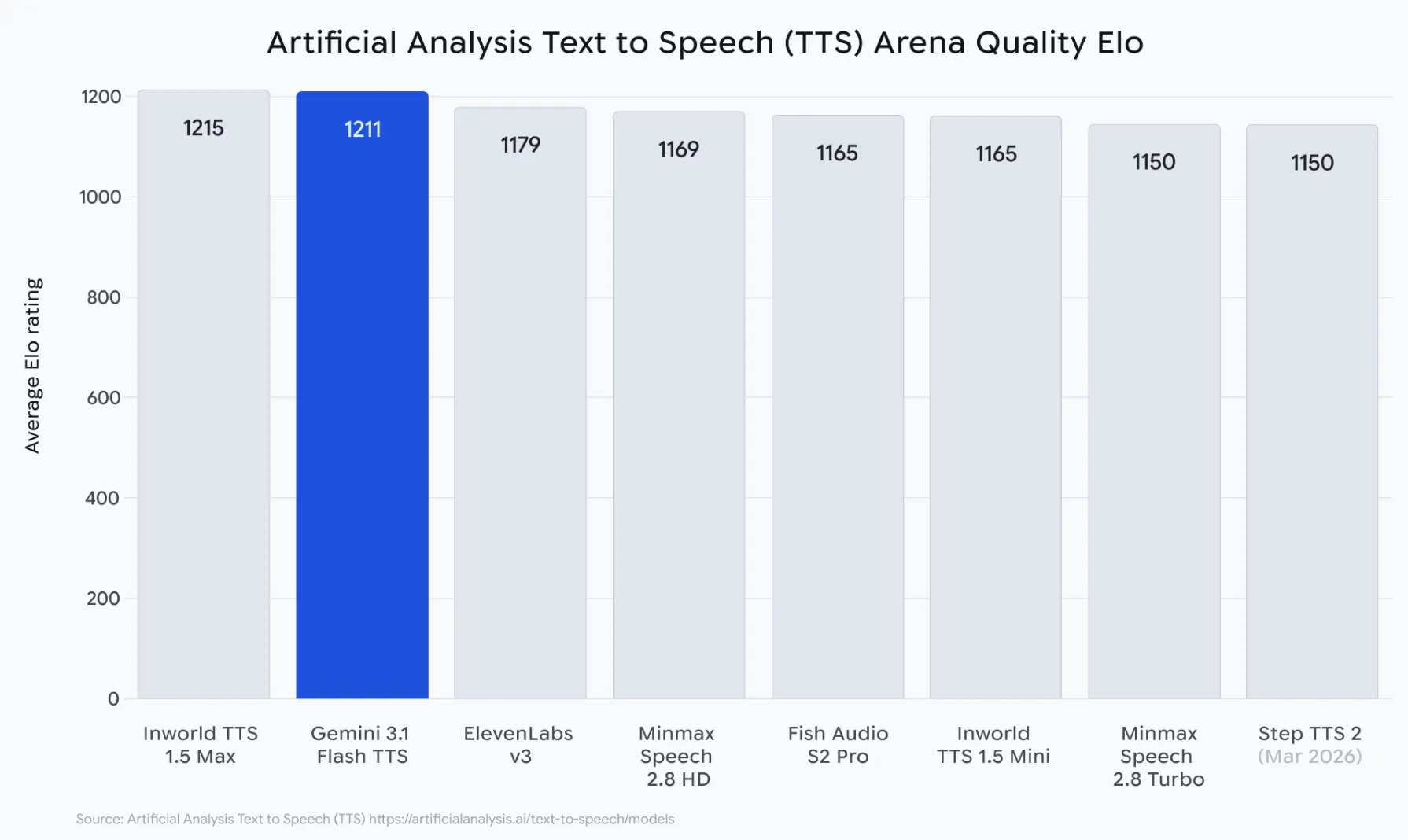
Die Synthetic Evaluation TTS Area führt Tausende anonymer blinder menschlicher Präferenztests für synthetische Sprache durch. Bei diesen Checks hören sich Menschen zwei TTS-Stimmen an und wählen diejenige aus, die ihrer Meinung nach am natürlichsten klingt, ohne zu wissen, welches Modell welche Stimme erzeugt hat. Es erfolgt keine Auswahl der vom Unternehmen selbst erstellten Samples oder Partituren. Dies ist der ultimative Beweis dafür, wie viele Menschen es vorziehen würden, jede Stimme auf dem Markt zu nutzen. Hier sind einige Ergebnisse des Gemini 3.1 Flash TTS-Roboters:
- 1.211 Elo-Rating beim Begin – der höchste Elo-Rating für alle öffentlich verfügbaren TTS-Engines
- „Attraktivste Veränderung“-Platzierung – das einzige TTS in der TTS-Geschichte mit hoher Natürlichkeit und niedrigen Kosten professional Zeichen
- Mehr als 70 Sprachen getestet – alle haben den natürlich klingenden Stil, das Tempo und die Akzentkontrolle beibehalten
- Produziert drei oder mehr verschiedene Lautsprecher in einer einzigen kohärenten Ausgabe – nicht aus aneinandergereihten Clips
- in der Ausgabe jeder Stimme mit SynthID als Wasserzeichen versehen; Kein anderes Modell auf der Bestenliste verfügt über Wasserzeichen mit SynthID.
Gemini 3.1 Flash TTS-Vergleich mit Mitbewerbern
Die meisten hochwertigen TTS-Motoren sind nicht erschwinglich. Die meisten kostengünstigen TTS klingen wie TTS, die zu teuer sind. Gemini 3.1 Flash TTS ist das erste TTS, das sich souverän zwischen diesen Modellen positioniert. Hier sehen Sie, wie es im Vergleich zu den führenden KI-TTS-Modellen in Bezug auf wichtige Kriterien abschneidet:
| Besonderheit | Gemini 3.1 Flash TTS | ElevenLabs Multilingual v3 | OpenAI TTS HD | Azure Neural TTS |
|---|---|---|---|---|
| Elo-Rating (Künstliche Analyse) | 1.211 | ~1.150 (geschätzt) | ~1.090 (geschätzt) | ~1.020 (geschätzt) |
| Audio-Tags / Emotionskontrolle | Nativ, inline | Nur Sprachklonen | Keiner | Nur SSML-Tags |
| Dialog mit mehreren Sprechern | Nativer Einzelanruf | Erfordert Nähen | Erfordert Nähen | Beschränkt |
| Sprachunterstützung | Über 70 Sprachen | 32 Sprachen | 57 Sprachen | Über 140 Sprachen |
| Akzent + Tempokontrolle | Professional Sprecher, natürliche Sprache | Per Sprachklonen | NEIN | Nur SSML |
| Szenen-/Kontextrichtung | Ja | NEIN | NEIN | NEIN |
| KI-Sicherheitswasserzeichen | SynthID | NEIN | NEIN | NEIN |
| Als API-Code exportieren | Ein Klick in AI Studio | NEIN | NEIN | NEIN |
| Freier Platz / Spielplatz | Google AI Studio | Begrenzte Testversion | Spielplatz | Begrenzte Testversion |
| Am besten für | Kreative und ausdrucksstarke Apps | Projekte zum Klonen von Stimmen | Einfache, klare Erzählung | Unternehmensmaßstab |
Abschluss
KI-Sprachtechnologie gibt es schon seit langem und sie ist für viele Anwendungen „intestine genug“. Allerdings waren KI-Stimmen nicht „intestine genug“ für den Einsatz in Kontexten, in denen eine menschliche Stimme erforderlich ist, um Emotionen darzustellen oder dem Benutzer irgendeine Type kreativer Kontrolle zu bieten.
Gemini 3.1 Flash TTS ändert all das. Der reichhaltige Funktionsumfang macht es zum allerersten KI-basiertes Sprachmodell das wirklich mit einer aufgezeichneten menschlichen Stimme mithalten kann, insbesondere für den Einsatz in kreativen Anwendungen.
Die drei oben genannten Projekte sind nur Ihr Einstiegspunkt. Denken Sie an interaktive Fiktion mit verzweigten vertonten Erzählungen, an mehrsprachige Kundendienstmitarbeiter mit regionalen Akzenten oder sogar an KI-Lehrer, die so klingen, als würden sie sich darum kümmern. Mit Gemini 3.1 Flash TTS sind keine Grenzen gesetzt.
Melden Sie sich an, um weiterzulesen und von Experten kuratierte Inhalte zu genießen.