

Bild vom Autor
# Einführung
Unter Net-Crawling versteht man den Prozess des automatischen Besuchs von Webseiten, dem Verfolgen von Hyperlinks und dem strukturierten Sammeln von Inhalten einer Web site. Es wird häufig zum Sammeln großer Informationsmengen aus Dokumentationsseiten, Artikeln, Wissensdatenbanken und anderen Webressourcen verwendet.
Das Crawlen einer gesamten Web site und das anschließende Konvertieren dieser Inhalte in ein Format, das ein KI-Agent tatsächlich verwenden kann, ist nicht so einfach, wie es sich anhört. Dokumentationsseiten enthalten häufig verschachtelte Seiten, wiederholte Navigationslinks, Standardinhalte und inkonsistente Seitenstrukturen. Darüber hinaus müssen die extrahierten Inhalte auf eine Weise bereinigt, organisiert und gespeichert werden, die für nachgelagerte KI-Workflows wie Abruf-, Frage-Antwort- oder agentenbasierte Systeme nützlich ist.
In diesem Leitfaden erfahren Sie, warum Sie es verwenden sollten Olostep anstatt Scrapy oder Selenrichten Sie alles ein, was für das Net-Crawling-Projekt benötigt wird, schreiben Sie ein einfaches Crawling-Skript zum Scrapen einer Dokumentationswebsite und erstellen Sie schließlich ein Frontend mit Gradio damit jeder einen Hyperlink und andere Argumente zum Crawlen von Web site-Seiten bereitstellen kann.
# Wählen Sie Olostep gegenüber Scrapy oder Selenium
Scrapy ist leistungsstark, aber es ist als vollständiges Scraping-Framework aufgebaut. Das ist nützlich, wenn Sie umfassende Kontrolle wünschen, bedeutet aber auch mehr Einrichtungs- und Engineering-Aufwand.
Selenium ist besser für die Browserautomatisierung bekannt. Es ist nützlich für die Interaktion mit JavaScript-lastigen Seiten, ist jedoch nicht wirklich als eigenständiger Dokumentations-Crawling-Workflow konzipiert.
Mit Olostep ist der Pitch viel direkter: Suchen, Crawlen, Scrapen und Strukturieren von Webdaten über eine Anwendungsprogrammierschnittstelle (API), mit Unterstützung für LLM-freundliche Ausgaben wie AbschlagTextual content, HTML und strukturiert JSON. Das bedeutet, dass Sie Teile für die Erkennung, Extraktion, Formatierung und nachgelagerte KI-Verwendung nicht auf die gleiche Weise manuell zusammenfügen müssen.
Bei Dokumentationsseiten kann dies einen viel schnelleren Weg von der URL zu nutzbarem Inhalt ermöglichen, da Sie weniger Zeit damit verbringen, den Crawling-Stack selbst zu erstellen, und mehr Zeit mit der Arbeit mit den Inhalten verbringen, die Sie tatsächlich benötigen.
# Installieren der Pakete und Festlegen des API-Schlüssels
Installieren Sie zunächst die Python Pakete, die in diesem Projekt verwendet werden. Das offizielle Olostep Software program Improvement Equipment (SDK) erfordert Python 3.11 oder höher.
pip set up olostep python-dotenv tqdmDiese Pakete übernehmen die Hauptteile des Workflows:
olostepverbindet Ihr Skript mit der Olostep-APIpython-dotenvlädt Ihren API-Schlüssel aus einer .env-DateitqdmFügt einen Fortschrittsbalken hinzu, damit Sie gespeicherte Seiten verfolgen können
Erstellen Sie als Nächstes ein kostenloses Olostep-Konto, öffnen Sie das Dashboard und generieren Sie einen API-Schlüssel auf der Seite „API-Schlüssel“. Die offiziellen Dokumente und Integrationen von Olostep verweisen Benutzer auf das Dashboard für die Einrichtung von API-Schlüsseln.
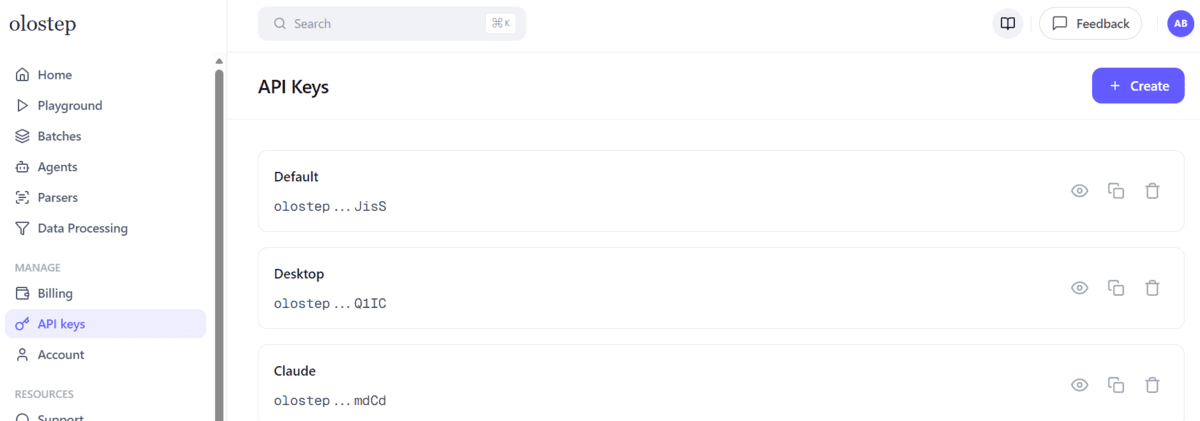
Erstellen Sie dann eine .env-Datei in Ihrem Projektordner:
OLOSTEP_API_KEY=your_real_api_key_hereDadurch bleibt Ihr API-Schlüssel von Ihrem Python-Code getrennt, was eine sauberere und sicherere Möglichkeit zur Verwaltung von Anmeldeinformationen darstellt.
# Erstellen des Crawler-Skripts
In diesem Teil des Projekts erstellen wir das Python-Skript, das eine Dokumentationswebsite crawlt, jede Seite im Markdown-Format extrahiert, den Inhalt bereinigt und ihn lokal als einzelne Dateien speichert. Wir erstellen den Projektordner, fügen eine Python-Datei hinzu und schreiben dann den Code Schritt für Schritt, damit er leicht zu befolgen und zu testen ist.
Erstellen Sie zunächst einen Projektordner für Ihren Crawler. Erstellen Sie in diesem Ordner eine neue Python-Datei mit dem Namen crawl_docs_with_olostep.py.
Jetzt fügen wir den Code Abschnitt für Abschnitt zu dieser Datei hinzu. Dies macht es einfacher zu verstehen, was die einzelnen Teile des Skripts tun und wie der gesamte Crawler zusammenarbeitet.
// Definieren der Crawl-Einstellungen
Beginnen Sie mit dem Importieren der erforderlichen Bibliotheken. Definieren Sie dann die wichtigsten Crawling-Einstellungen, wie Begin-URL, Crawling-Tiefe, Seitenlimit, Einschluss- und Ausschlussregeln und den Ausgabeordner, in dem die Markdown-Dateien gespeichert werden. Diese Werte steuern, wie viel von der Dokumentationsseite gecrawlt wird und wo die Ergebnisse gespeichert werden.
import os
import re
from pathlib import Path
from urllib.parse import urlparse
from dotenv import load_dotenv
from tqdm import tqdm
from olostep import Olostep
START_URL = "https://docs.olostep.com/"
MAX_PAGES = 10
MAX_DEPTH = 1
INCLUDE_URLS = (
"/**"
)
EXCLUDE_URLS = ()
OUTPUT_DIR = Path("olostep_docs_output")// Erstellen einer Hilfsfunktion zum Generieren sicherer Dateinamen
Jede gecrawlte Seite muss als eigene Markdown-Datei gespeichert werden. Dazu benötigen wir eine Hilfsfunktion, die eine URL in einen sauberen und dateisystemsicheren Dateinamen umwandelt. Dadurch werden Probleme mit Schrägstrichen, Symbolen und anderen Zeichen vermieden, die in Dateinamen nicht intestine funktionieren.
def slugify_url(url: str) -> str:
parsed = urlparse(url)
path = parsed.path.strip("https://www.kdnuggets.com/")
if not path:
path = "index"
filename = re.sub(r"(^a-zA-Z0-9/_-)+", "-", path)
filename = filename.exchange("https://www.kdnuggets.com/", "__").strip("-_")
return f"{filename or 'web page'}.md"// Erstellen einer Hilfsfunktion zum Speichern von Markdown-Dateien
Fügen Sie als Nächstes Hilfsfunktionen hinzu, um den extrahierten Inhalt zu verarbeiten, bevor Sie ihn speichern.
Die erste Funktion bereinigt den Markdown, indem sie zusätzlichen Schnittstellentext, wiederholte Leerzeilen und unerwünschte Seitenelemente wie Suggestions-Eingabeaufforderungen entfernt. Dies trägt dazu bei, dass sich die gespeicherten Dateien auf den eigentlichen Dokumentationsinhalt konzentrieren.
def clean_markdown(markdown: str) -> str:
textual content = markdown.exchange("rn", "n").strip()
textual content = re.sub(r"(s*u200b?s*)(#.*?)", "", textual content, flags=re.DOTALL)
traces = (line.rstrip() for line in textual content.splitlines())
start_index = 0
for index in vary(len(traces) - 1):
title = traces(index).strip()
underline = traces(index + 1).strip()
if title and underline and set(underline) == {"="}:
start_index = index
break
else:
for index, line in enumerate(traces):
if line.lstrip().startswith("# "):
start_index = index
break
traces = traces(start_index:)
for index, line in enumerate(traces):
if line.strip() == "Was this web page useful?":
traces = traces(:index)
break
cleaned_lines: record(str) = ()
for line in traces:
stripped = line.strip()
if stripped in {"Copy web page", "YesNo", "⌘I"}:
proceed
if not stripped and cleaned_lines and never cleaned_lines(-1):
proceed
cleaned_lines.append(line)
return "n".be a part of(cleaned_lines).strip()Die zweite Funktion speichert den bereinigten Markdown im Ausgabeordner und fügt die Quell-URL oben in die Datei ein. Es gibt auch eine kleine Hilfsfunktion, um alte Markdown-Dateien zu löschen, bevor ein neues Crawl-Ergebnis gespeichert wird.
def save_markdown(output_dir: Path, url: str, markdown: str) -> None:
output_dir.mkdir(mother and father=True, exist_ok=True)
filepath = output_dir / slugify_url(url)
content material = f"""---
source_url: {url}
---
{markdown}
"""
filepath.write_text(content material, encoding="utf-8")Es gibt auch eine kleine Hilfsfunktion, um alte Markdown-Dateien zu löschen, bevor ein neues Crawl-Ergebnis gespeichert wird.
def clear_output_dir(output_dir: Path) -> None:
if not output_dir.exists():
return
for filepath in output_dir.glob("*.md"):
filepath.unlink()// Erstellen der Haupt-Crawler-Logik
Dies ist der Hauptteil des Skripts. Es lädt den API-Schlüssel aus der .env-Datei, erstellt den Olostep-Consumer, startet den Crawl, wartet auf dessen Abschluss, ruft jede gecrawlte Seite als Markdown ab, bereinigt den Inhalt und speichert ihn lokal.
Dieser Abschnitt verknüpft alles miteinander und verwandelt die einzelnen Hilfsfunktionen in einen funktionierenden Dokumentations-Crawler.
def important() -> None:
load_dotenv()
api_key = os.getenv("OLOSTEP_API_KEY")
if not api_key:
elevate RuntimeError("Lacking OLOSTEP_API_KEY in your .env file.")
shopper = Olostep(api_key=api_key)
crawl = shopper.crawls.create(
start_url=START_URL,
max_pages=MAX_PAGES,
max_depth=MAX_DEPTH,
include_urls=INCLUDE_URLS,
exclude_urls=EXCLUDE_URLS,
include_external=False,
include_subdomain=False,
follow_robots_txt=True,
)
print(f"Began crawl: {crawl.id}")
crawl.wait_till_done(check_every_n_secs=5)
pages = record(crawl.pages())
clear_output_dir(OUTPUT_DIR)
for web page in tqdm(pages, desc="Saving pages"):
attempt:
content material = web page.retrieve(("markdown"))
markdown = getattr(content material, "markdown_content", None)
if markdown:
save_markdown(OUTPUT_DIR, web page.url, clean_markdown(markdown))
besides Exception as exc:
print(f"Didn't retrieve {web page.url}: {exc}")
print(f"Executed. Information saved in: {OUTPUT_DIR.resolve()}")
if __name__ == "__main__":
important()Notiz: Das vollständige Skript finden Sie hier: kingabzpro/web-crawl-olostepein Webcrawler und eine Starter-Webanwendung, die mit Olostep erstellt wurde.
// Testen des Net-Crawling-Skripts
Sobald das Skript fertig ist, führen Sie es auf Ihrem Terminal aus:
python crawl_docs_with_olostep.pyWährend das Skript ausgeführt wird, werden Sie sehen, wie der Crawler die Seiten verarbeitet und sie einzeln als Markdown-Dateien in Ihrem Ausgabeordner speichert.

Öffnen Sie nach Abschluss des Crawls die gespeicherten Dateien, um den extrahierten Inhalt zu überprüfen. Sie sollten saubere, lesbare Markdown-Versionen der Dokumentationsseiten sehen.
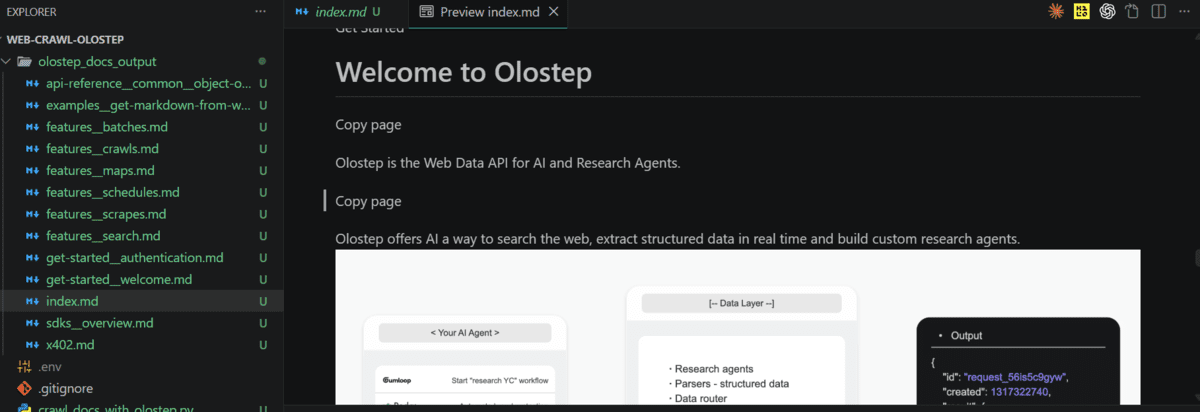
An diesem Punkt können Ihre Dokumentationsinhalte in KI-Workflows wie Such-, Abruf- oder agentenbasierten Systemen verwendet werden.
# Erstellen der Olostep Net Crawling-Webanwendung
In diesem Teil des Projekts erstellen wir eine einfache Webanwendung auf Foundation des Crawler-Skripts. Anstatt die Python-Datei jedes Mal bearbeiten zu müssen, bietet Ihnen diese Anwendung eine einfachere Möglichkeit, eine Dokumentations-URL einzugeben, Crawling-Einstellungen auszuwählen, den Crawl auszuführen und eine Vorschau der gespeicherten Markdown-Dateien an einem Ort anzuzeigen.
Der Frontend-Code für diese Anwendung ist verfügbar unter app.py im Repository: web-crawl-olostep/app.py.
Diese Anwendung macht ein paar nützliche Dinge:
- Hier können Sie eine Begin-URL für den Crawl eingeben
- Hier können Sie die maximale Anzahl der zu crawlenden Seiten festlegen
- Ermöglicht Ihnen die Steuerung der Kriechtiefe
- Ermöglicht das Hinzufügen von Einschluss- und Ausschluss-URL-Mustern
- Führt den Backend-Crawler direkt über die Schnittstelle aus
- Speichert die gecrawlten Seiten basierend auf der URL in einem Ordner
- Zeigt alle gespeicherten Markdown-Dateien in einem Dropdown an
- Zeigt eine Vorschau jeder Markdown-Datei direkt in der Anwendung an
- Ermöglicht das Löschen früherer Crawl-Ergebnisse mit einer Schaltfläche
Um die Anwendung zu starten, führen Sie Folgendes aus:
Danach startet Gradio einen lokalen Webserver und stellt einen Hyperlink wie diesen bereit:
* Operating on native URL: http://127.0.0.1:7860
* To create a public hyperlink, set `share=True` in `launch()`.Sobald die Anwendung ausgeführt wird, öffnen Sie die lokale URL in Ihrem Browser. In unserem Beispiel haben wir der Anwendung die gegeben URL der Claude Code-Dokumentation und bat darum, 50 Seiten mit einer Tiefe von 5 zu crawlen.
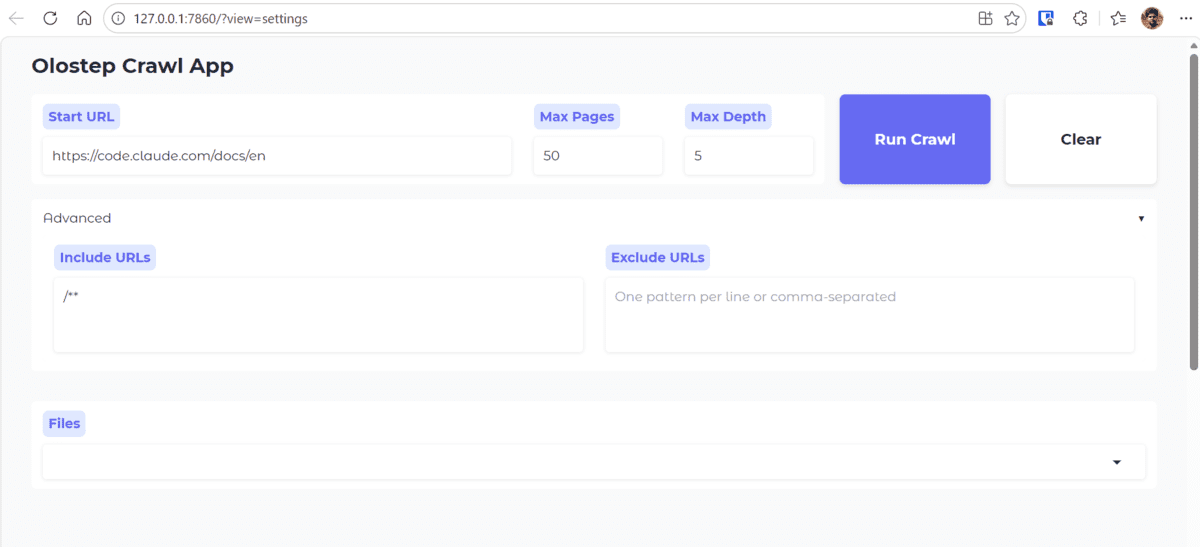
Wenn Sie klicken Führen Sie Crawl ausübergibt die Anwendung Ihre Einstellungen an den Backend-Crawler und startet den Crawl. Im Terminal können Sie den Fortschritt verfolgen, während die Seiten einzeln gecrawlt und gespeichert werden.

Nach Abschluss des Crawls enthält der Ausgabeordner die gespeicherten Markdown-Dateien. In diesem Beispiel würden Sie sehen, dass 50 Dateien hinzugefügt wurden.
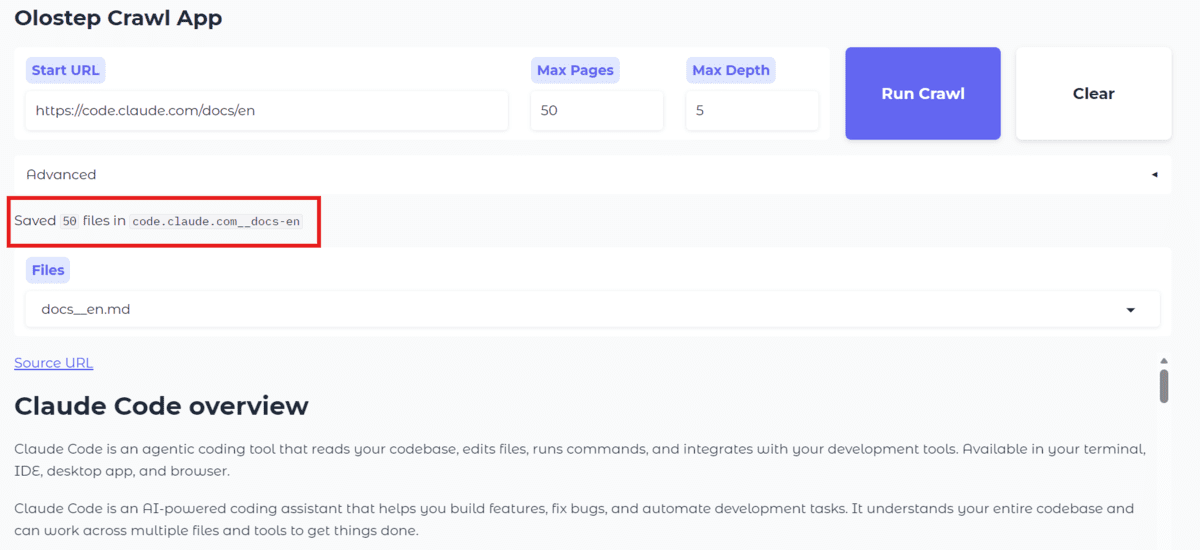
Das Dropdown-Menü in der Anwendung wird dann automatisch aktualisiert, sodass Sie jede gespeicherte Datei öffnen und direkt in der Weboberfläche eine Vorschau als ordnungsgemäß formatiertes Markdown anzeigen können.
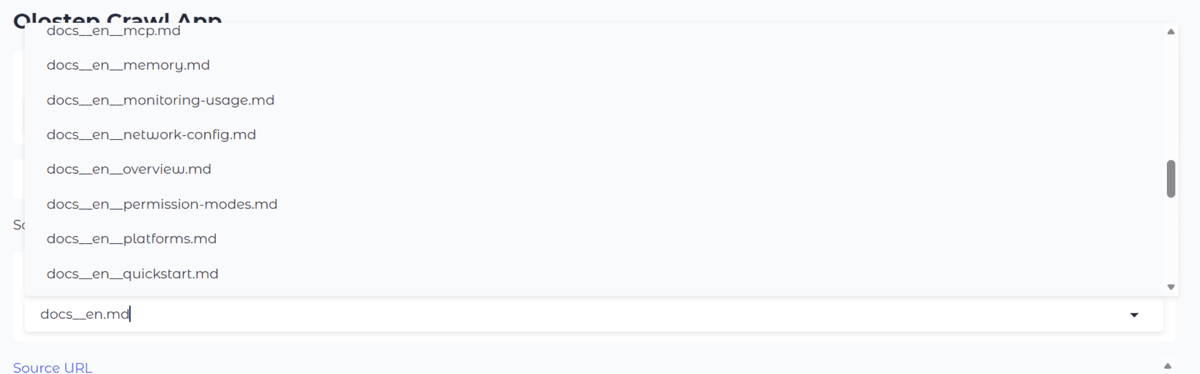
Dadurch ist der Crawler viel einfacher zu bedienen. Anstatt jedes Mal Werte im Code zu ändern, können Sie über eine einfache Benutzeroberfläche verschiedene Dokumentationsseiten und Crawling-Einstellungen testen. Dadurch lässt sich das Projekt auch einfacher mit anderen Personen teilen, die möglicherweise nicht direkt in Python arbeiten möchten.
# Letzter Imbiss
Beim Webcrawlen geht es nicht nur um das Sammeln von Seiten einer Web site. Die eigentliche Herausforderung besteht darin, diese Inhalte in saubere, strukturierte Dateien umzuwandeln, die ein KI-System tatsächlich verwenden kann. In diesem Projekt haben wir ein einfaches Python-Skript und eine Gradio-Anwendung verwendet, um diesen Prozess erheblich zu vereinfachen.
Ebenso wichtig ist, dass der Workflow schnell genug für den tatsächlichen Einsatz ist. In unserem Beispiel dauerte das Crawlen von 50 Seiten mit einer Tiefe von 5 nur etwa 50 Sekunden, was zeigt, dass Sie Dokumentationsdaten schnell vorbereiten können, ohne eine umfangreiche Pipeline aufzubauen.
Dieses Setup kann auch über einen einmaligen Crawl hinausgehen. Sie können die tägliche Ausführung mit cron oder dem Taskplaner planen und sogar nur die Seiten aktualisieren, die sich geändert haben. Dadurch bleibt Ihre Dokumentation aktuell und verbraucht nur eine geringe Anzahl an Credit.
Für Groups, die diese Artwork von Workflow benötigen, um wirtschaftlich sinnvoll zu sein, wurde Olostep speziell dafür entwickelt. Es ist deutlich günstiger als der Aufbau oder die Wartung einer internen Crawling-Lösung und mindestens 50 % günstiger als vergleichbare Alternativen auf dem Markt.
Mit zunehmender Nutzung sinken die Kosten professional Anfrage weiter, was es zu einer praktischen Wahl für größere Dokumentationspipelines macht. Diese Kombination aus Zuverlässigkeit, Skalierbarkeit und starker Einheitsökonomie ist der Grund, warum einige der am schnellsten wachsenden KI-nativen Startups auf Olostep vertrauen, um ihre Dateninfrastruktur zu betreiben.
Abid Ali Awan (@1abidaliawan) ist ein zertifizierter Datenwissenschaftler, der gerne Modelle für maschinelles Lernen erstellt. Derzeit konzentriert er sich auf die Erstellung von Inhalten und das Schreiben technischer Blogs zu maschinellem Lernen und Datenwissenschaftstechnologien. Abid verfügt über einen Grasp-Abschluss in Technologiemanagement und einen Bachelor-Abschluss in Telekommunikationstechnik. Seine Imaginative and prescient ist es, ein KI-Produkt mithilfe eines graphischen neuronalen Netzwerks für Schüler mit psychischen Erkrankungen zu entwickeln.