
Spekulative Dekodierung ist eine Technik zur Beschleunigung der Inferenz großer Sprachmodelle. Ein kleines, schnelles Entwurfsmodell schlägt mehrere Token vor. Das große Zielmodell verifiziert sie parallel. Wenn akzeptiert, erfolgt die Schlussfolgerung schneller. Bei einer Ablehnung greift das System ordnungsgemäß zurück.
Das EAGLE-Group, das vLLM-Group und das TorchSpec-Group haben die EAGLE-Serie mit EAGLE 1, EAGLE 2 und EAGLE 3 auf den Markt gebracht, die sich zu einer der am weitesten verbreiteten und praktisch eingesetzten Familien spekulativer Decodierungsalgorithmen sowohl in Forschungs- als auch in Produktionssystemen entwickelt hat. Heute erhält diese Familie mit der Einführung von ein gezieltes Zuverlässigkeits-Improve ADLER 3.1.
Was lief schief
Während die spekulative Dekodierung in kontrollierten Umgebungen eine gute Leistung erbringt, nimmt die Leistung bei unterschiedlichen Chat-Vorlagen, Eingaben mit langem Kontext oder Systemaufforderungen außerhalb der Verteilung häufig ab.
Das EAGLE-Group führte diese Fragilität auf ein Phänomen namens zurück Aufmerksamkeitsdrift Mit zunehmender Spekulationstiefe verlagert der Verfasser seine Aufmerksamkeit allmählich von den Sink-Tokens hin zu den selbst generierten Tokens.
Einfacher ausgedrückt: Der Drafter ist ein kleines Modell, das zukünftige Token vorhersagt. Wenn die Spekulation tiefer geht, beginnt sie, sich auf ihre eigenen früheren Ergebnisse statt auf den ursprünglichen Kontext zu konzentrieren. Dies verschlechtert die Akzeptanzlänge und die Ausgabestabilität.
Es wurden zwei zugrunde liegende Probleme identifiziert. Erstens wird die fusionierte Eingabedarstellung zunehmend unausgewogen, da verborgene Zustände höherer Ebenen die Drafter-Eingabe dominieren. Zweitens wächst die Größe des verborgenen Zustands aufgrund des nicht normalisierten Restpfads über Spekulationsschritte hinweg. Zusammengenommen führen diese Effekte dazu, dass der Drafter bei tieferen Spekulationstiefen immer weniger stabil wird.
Zwei architektonische Korrekturen in EAGLE 3.1
Um der Aufmerksamkeitsdrift entgegenzuwirken, verfügt EAGLE 3.1 über zwei wichtige Architekturverbesserungen: FC-Normalisierung nach jedem verborgenen Zielzustand und vor der FC-Schicht sowie die Einspeisung verborgener Submit-Norm-Zustände in den nächsten Decodierungsschritt.
Die FC-Normalisierung stabilisiert die verborgenen Zustände, die der Zeichner vom Zielmodell erhält. Ohne sie wächst die Größe des verborgenen Zustands über die Schritte hinweg, was den Zeichner zunehmend unzuverlässig macht. Durch die Anwendung der Normalisierung bei jedem Schritt bleiben die Eingaben begrenzt.
Durch das Submit-Norm-Design verhält sich die Methode eher wie ein rekursiver Aufruf des Drafters über die Decodierungsschritte hinweg, anstatt einfach zusätzliche Ebenen an das Zielmodell anzuhängen.
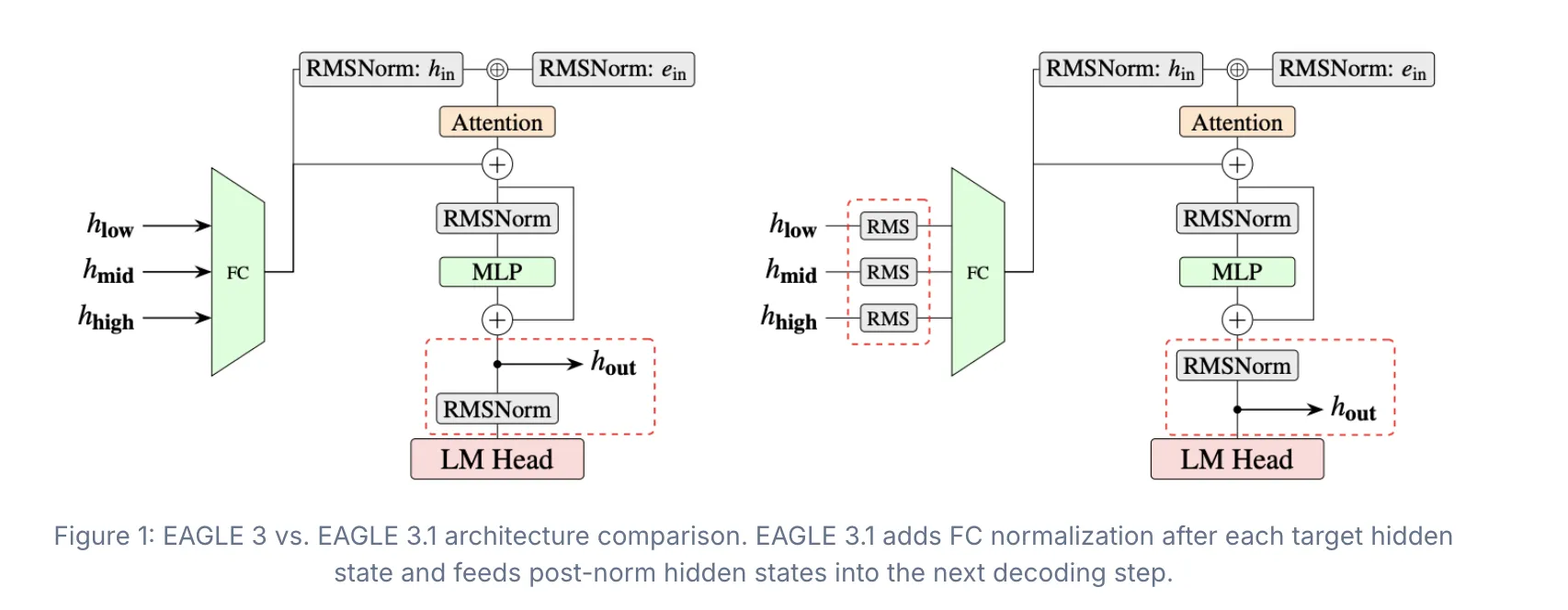
Was diese Fixes liefern
Im Vergleich zu EAGLE 3 zeigt EAGLE 3.1: eine kürzere Trainingszeit bis zur Inferenzzeit-Extrapolation, eine stärkere Robustheit über lange Kontexte, eine höhere Widerstandsfähigkeit gegenüber Variationen von Chat-Vorlagen und Systemaufforderungen sowie eine stabilere Akzeptanzlänge in verschiedenen Bereitstellungsumgebungen.
Bei Lengthy-Context-Workloads erreicht EAGLE 3.1 im Vergleich zu EAGLE 3 eine bis zu 2-mal längere Akzeptanzlänge.
Trainingsinfrastruktur: TorchSpec
TorchSpec bietet jetzt effiziente Trainingsunterstützung für EAGLE 3.1 und zukünftige spekulative Decodierungsalgorithmen. Durch die Reduzierung des Schulungsaufwands und die Vereinfachung der Experimentierabläufe trägt TorchSpec dazu bei, die Iteration und Erkundung für die Forschung und Bereitstellung spekulativer Dekodierung der nächsten Era zu beschleunigen.
Basierend auf TorchSpec und vLLM hat das Forschungsteam außerdem ein EAGLE 3.1-Entwurfsmodell für Kimi K2.6 trainiert und als Open-Supply-Model bereitgestellt, verfügbar unter Umarmendes Gesicht. Das Modell dient als Beispiel für die Bereitstellung von EAGLE 3.1 mit TorchSpec-Schulung und vLLM-Serving-Unterstützung in einem realen Serving-Modell
vLLM-Integration: konfigurationsgesteuert und abwärtskompatibel
EAGLE 3.1 landet in vLLM als konfigurationsgesteuerte Erweiterung der bestehenden EAGLE 3-Implementierung. Die Integration umfasst die Unterstützung der FC-Normalisierung, Suggestions zu versteckten Zuständen nach der Norm und die Entfernung fest codierter Annahmen rund um versteckte Zielzustände.
Die Abwärtskompatibilität mit bestehenden EAGLE 3-Checkpoints bleibt vollständig erhalten. EAGLE 3.1-Entwurfsmodelle können direkt über denselben Codepfad für spekulative Dekodierung eingebunden werden.
vllm serve nvidia/Kimi-K2.6-NVFP4
--trust-remote-code
--tensor-parallel-size 4
--tool-call-parser kimi_k2
--enable-auto-tool-choice
--reasoning-parser kimi_k2
--attention-backend tokenspeed_mla
--speculative-config '{"mannequin":"lightseekorg/kimi-k2.6-eagle3.1-mla","technique":"eagle3","num_speculative_tokens":3}'
--language-model-onlyBenchmark-Ergebnisse für Kimi K2.6
Das Forschungsteam hat das Entwurfsmodell Kimi K2.6 EAGLE 3.1 auf Kimi-K2.6-NVFP4 mit vLLM (TP=4, GB200, nicht disagg) im SPEED-Bench-Codierungsdatensatz verglichen. EAGLE 3.1 bietet einen 2,03-fach höheren Ausgabedurchsatz professional Benutzer bei Parallelität 1. Die Beschleunigung bleibt sinnvoll, da die Parallelität skaliert: 1,71-fach bei C=4 und 1,66-fach bei C=16.
Der visuelle Erklärer von Marktechpost
Wichtige Erkenntnisse
- EAGLE 3.1-Korrekturen Aufmerksamkeitsdrift – eine neu identifizierte Instabilität, bei der der Verfasser den Fokus auf sinkende Token in tieferen Spekulationstiefen verliert.
- Zwei architektonische Änderungen – FC-Normalisierung Und Postnorm-Hidden-State-Suggestions – den Drafter über Spekulationsschritte hinweg stabilisieren.
- Bei Workloads mit langem Kontext liefert EAGLE 3.1 bis zu 2× längere Akzeptanzlänge im Vergleich zu EAGLE 3.
- Benchmarks zum Kimi-K2.6-NVFP4 zeigen 2,03-facher Ausgabedurchsatz professional Benutzer bei Parallelität 1, Abfall auf 1,66× bei C=16.
- EAGLE 3.1 ist Abwärtskompatibel mit EAGLE 3-Kontrollpunkten und ist bereits in vLLM foremost integriert und wird in v0.22.0 ausgeliefert.
Schauen Sie sich das an Technische Particulars. Sie können uns auch gerne weiter folgen Twitter und vergessen Sie nicht, bei uns mitzumachen 150.000+ ML SubReddit und Abonnieren Unser E-newsletter. Warten! Bist du im Telegram? Jetzt können Sie uns auch per Telegram kontaktieren.
Möchten Sie mit uns zusammenarbeiten, um Ihr GitHub-Repo ODER Ihre Hugging Face Web page ODER Produktveröffentlichung ODER Ihr Webinar usw. zu bewerben? Vernetzen Sie sich mit uns

Michal Sutter ist ein Knowledge-Science-Experte mit einem Grasp of Science in Knowledge Science von der Universität Padua. Mit einer soliden Grundlage in statistischer Analyse, maschinellem Lernen und Datentechnik ist Michal hervorragend darin, komplexe Datensätze in umsetzbare Erkenntnisse umzuwandeln.