

# Einführung
Pandas ist eine der beliebtesten Python-Bibliotheken für die Datenanalyse. Es bietet Ihnen einfache Werkzeuge zum Bereinigen, Umformen, Zusammenfassen und Untersuchen strukturierter Daten. Eine der nützlichsten Funktionen in Pandas ist GroupBy. Es hilft Ihnen bei der Beantwortung von Fragen, die eine Gruppierung von Zeilen nach einer oder mehreren Kategorien erfordern.
Wenn Sie beispielsweise mit Verkaufsdaten arbeiten, möchten Sie möglicherweise den Gesamtumsatz nach Area, den durchschnittlichen Bestellwert nach Produktkategorie oder die Anzahl der von jedem Vertriebsmitarbeiter bearbeiteten Bestellungen berechnen. Anstatt jede Kategorie einzeln manuell zu filtern, können Sie diese Berechnungen mit GroupBy auf saubere und effiziente Weise durchführen.
In diesem Tutorial werden wir praktische Beispiele für die Verwendung von Pandas GroupBy mit einem kleinen Verkaufsdatensatz durchgehen. Ich benutze Deepnote Als Codierungsumgebung werden einige Ausgaben als Pocket book-Screenshots direkt unter den Codeblöcken angezeigt.
# Erstellen eines Beispieldatensatzes
Bevor wir GroupBy verwenden, erstellen wir zunächst einen kleinen Datensatz zu Einzelhandelsumsätzen mit Spalten wie order_id, area, class, sales_rep, models, unit_price, low costUnd order_date. Anschließend konvertieren wir das Wörterbuch in Pandas DataFrame und erstellen Sie zwei neue Spalten: gross_sales Und net_sales.
knowledge = {
"order_id": (101, 102, 103, 104, 105, 106, 107, 108, 109, 110, 111, 112),
"area": ("North", "South", "North", "West", "South", "West", "North", "South", "West", "North", "South", "West"),
"class": ("Electronics", "Furnishings", "Electronics", "Furnishings", "Clothes", "Electronics",
"Clothes", "Furnishings", "Clothes", "Furnishings", "Electronics", "Clothes"),
"sales_rep": ("Ayesha", "Bilal", "Ayesha", "Chen", "Bilal", "Chen",
"Ayesha", "Bilal", "Chen", "Ayesha", "Bilal", "Chen"),
"models": (2, 1, 3, 2, 5, 4, 6, 2, 7, 1, 2, 8),
"unit_price": (500, 800, 450, 700, 60, 550, 55, 850, 65, 750, 520, 70),
"low cost": (0.05, 0.10, 0.00, 0.08, 0.00, 0.12, 0.05, 0.10, 0.00, 0.07, 0.03, 0.00),
"order_date": pd.to_datetime((
"2026-01-05", "2026-01-06", "2026-01-08", "2026-01-10",
"2026-01-12", "2026-01-15", "2026-02-02", "2026-02-05",
"2026-02-08", "2026-02-12", "2026-02-15", "2026-02-20"
))
}
df = pd.DataFrame(knowledge)
df("gross_sales") = df("models") * df("unit_price")
df("net_sales") = df("gross_sales") * (1 - df("low cost"))
dfDer gross_sales Die Spalte wird durch Multiplikation berechnet models von unit_pricewährend net_sales Passt diesen Wert nach Anwendung des Rabatts an. Dadurch erhalten wir einen sauberen Datensatz, den wir für alle GroupBy-Beispiele verwenden können.
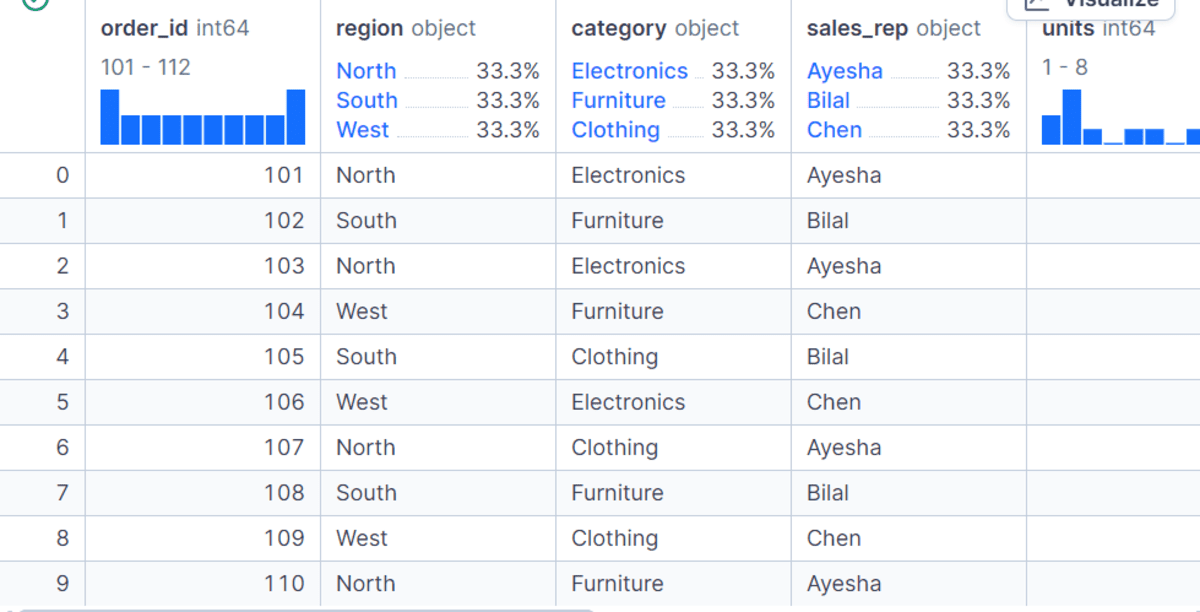
# Verwenden der grundlegenden GroupBy-Syntax
Der grundlegendste GroupBy-Vorgang folgt einem einfachen Muster: Wählen Sie eine Gruppierungsspalte aus, wählen Sie die Wertespalte aus und wenden Sie eine Aggregationsfunktion an. In diesem Beispiel gruppieren wir die Daten nach area und berechne die Summe net_sales für jede Area.
df.groupby("area")("net_sales").sum()Das Ergebnis zeigt, dass Nord, Süd und West jeweils ihren eigenen Gesamtverkaufswert haben. Dies ist der einfachste und häufigste Anwendungsfall für GroupBy beim Zusammenfassen von Daten.
area
North 3311.0
South 3558.8
West 4239.0
Title: net_sales, dtype: float64# Verwenden von GroupBy mit as_index=False
Standardmäßig verwendet Pandas die gruppierte Spalte als Index in der Ausgabe. Während dies in manchen Fällen nützlich ist, ist es oft einfacher, mit einem normalen zu arbeiten DataFrame wobei die gruppierte Spalte eine reguläre Spalte bleibt. Das ist wo as_index=False ist nützlich.
df.groupby("area", as_index=False)("net_sales").sum()In diesem Beispiel berechnen wir erneut den Gesamtnettoumsatz nach Area, das Ergebnis wird jedoch bereinigt zurückgegeben DataFramewas einfacher zu exportieren, zusammenzuführen oder in Berichten zu verwenden ist.

# Anwenden mehrerer Aggregationen auf eine Spalte
GroupBy ist nicht auf eine einzelne Berechnung beschränkt. Mit können Sie mehrere Aggregationsfunktionen auf dieselbe Spalte anwenden agg().
In diesem Beispiel berechnen wir die Summe, den Mittelwert, das Minimal, das Most und die Anzahl von net_sales für jede Area.
Dies gibt uns einen schnellen statistischen Überblick über die regionale Vertriebsleistung und hilft uns, nicht nur den Gesamtumsatz, sondern auch die durchschnittliche Bestellgröße und das Bestellvolumen zu vergleichen.
df.groupby("area")("net_sales").agg(("sum", "imply", "min", "max", "rely"))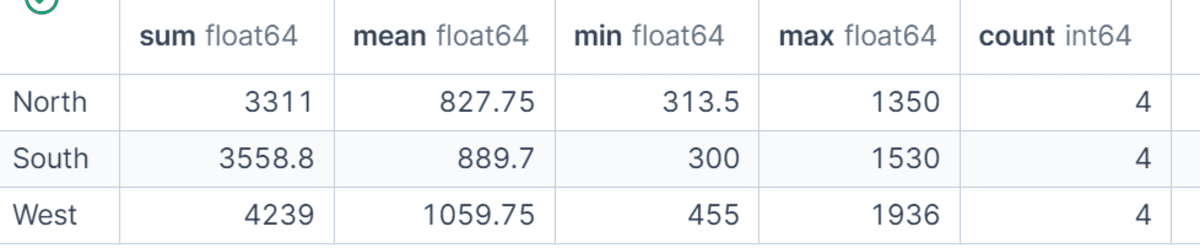
# Benannte Aggregationen verwenden
Benannte Aggregationen erleichtern das Lesen und Verwenden von GroupBy-Ausgaben. Anstatt generische Spaltennamen zurückzugeben, z sum oder implywir definieren unsere eigenen Namen wie total_sales, average_order_value, total_unitsUnd number_of_orders.
Dies ist besonders hilfreich, wenn Sie Analysen für Dashboards, Berichte oder Tutorials vorbereiten, da die Namen der Ausgabespalten klar erklären, was die einzelnen Metriken darstellen.
region_summary = (
df.groupby("area", as_index=False)
.agg(
total_sales=("net_sales", "sum"),
average_order_value=("net_sales", "imply"),
total_units=("models", "sum"),
number_of_orders=("order_id", "rely")
)
)
region_summary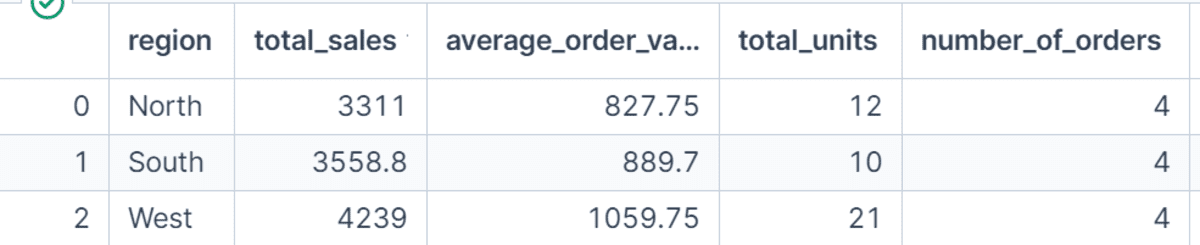
# Gruppierung nach mehreren Spalten
Sie können Daten auch nach mehr als einer Spalte gruppieren. In diesem Beispiel gruppieren wir nach beiden area Und class um den Gesamtnettoumsatz für jede Produktkategorie innerhalb jeder Area zu berechnen.
Dadurch erhalten wir eine detailliertere Ansicht der Daten im Vergleich zur Gruppierung allein nach Area. Die mehrspaltige Gruppierung ist nützlich, wenn Sie die Leistung in verschiedenen Dimensionen analysieren möchten, z. B. Area und Produkt, Abteilung und Mitarbeiter oder Monat und Kundensegment.
df.groupby(("area", "class"), as_index=False)("net_sales").sum()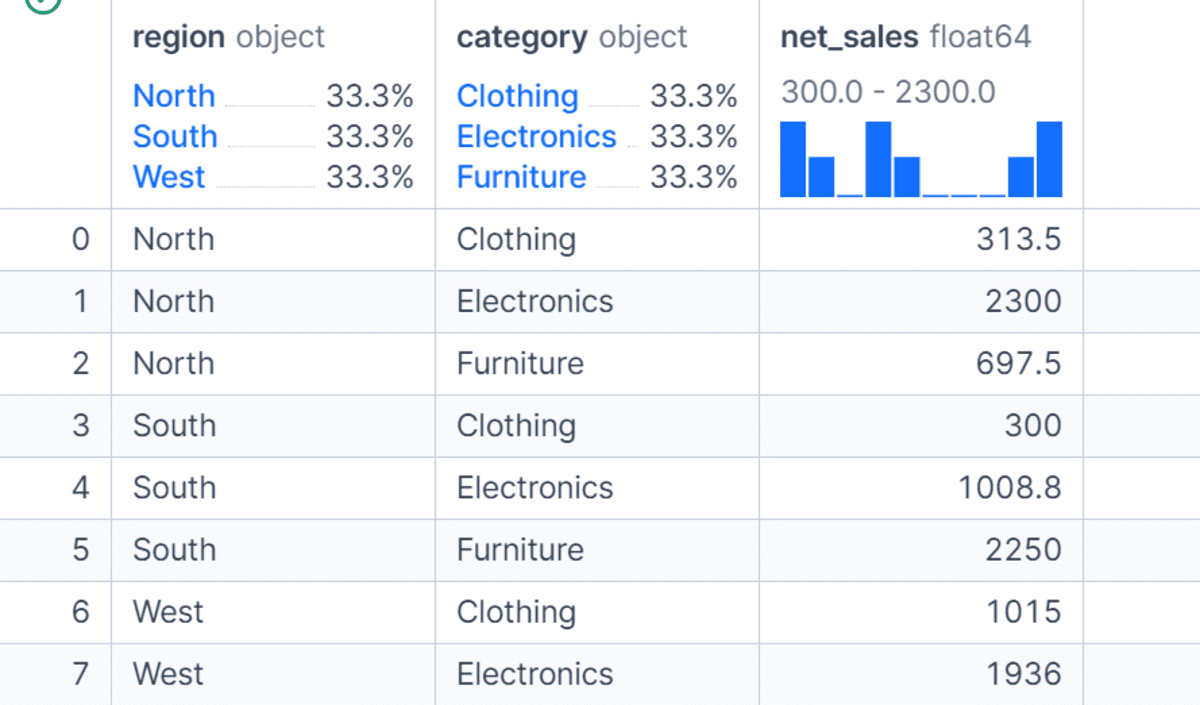
# Sortieren der GroupBy-Ergebnisse
Nach dem Gruppieren und Aggregieren von Daten möchten Sie häufig die Ergebnisse sortieren, um die höchsten oder niedrigsten Werte zu finden.
In diesem Beispiel berechnen wir den Gesamtumsatz nach Produktkategorie und sortieren die Ergebnisse dann in absteigender Reihenfolge.
Dadurch lässt sich leicht erkennen, welche Kategorie den meisten Umsatz generiert hat. Das Sortieren gruppierter Ergebnisse ist ein einfacher, aber wirkungsvoller Schritt, um Rohzusammenfassungen in nützliche Erkenntnisse umzuwandeln.
category_sales = (
df.groupby("class", as_index=False)
.agg(total_sales=("net_sales", "sum"))
.sort_values("total_sales", ascending=False)
)
category_sales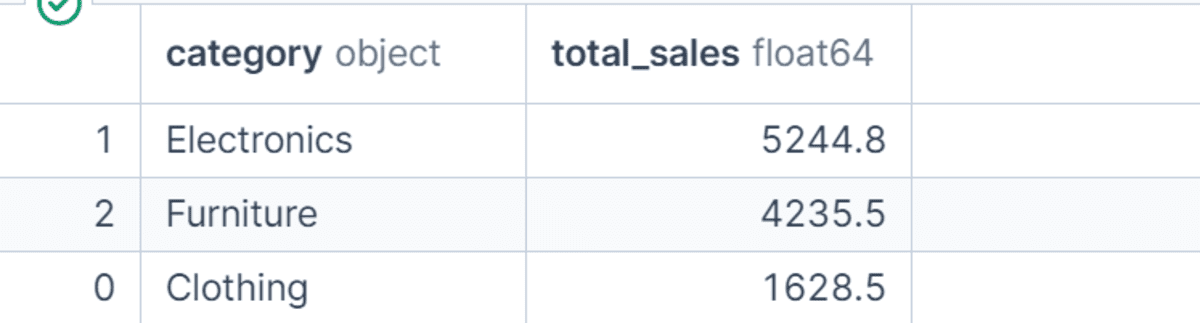
# Anzahl vs. Größe verstehen
Pandas bietet beides rely() Und measurement()aber sie sind nicht genau gleich. Der measurement() Die Methode zählt die Gesamtzahl der Zeilen in jeder Gruppe, einschließlich der Zeilen mit fehlenden Werten. Der rely() Die Methode zählt nur nicht fehlende Werte in einer ausgewählten Spalte.
In diesem Beispiel fügen wir absichtlich einen fehlenden Wert hinzu sales_rep Spalte. Die Ausgabe zeigt das measurement() zählt immer noch vier Zeilen für jede Area, während rely() gibt drei für Norden zurück, weil eins sales_rep Wert fehlt.
import numpy as np
df_missing = df.copy()
df_missing.loc(2, "sales_rep") = np.nan
print("Utilizing measurement():")
show(df_missing.groupby("area").measurement())
print("Utilizing rely() on sales_rep:")
show(df_missing.groupby("area")("sales_rep").rely())Ausgabe:
Utilizing measurement():
area
North 4
South 4
West 4
dtype: int64
Utilizing rely() on sales_rep:
area
North 3
South 4
West 4
Title: sales_rep, dtype: int64# Benutzen remodel() für Funktionen auf Gruppenebene
Der remodel() Die Methode ist nützlich, wenn Sie einen Wert auf Gruppenebene berechnen und ihn wieder zum Unique hinzufügen möchten DataFrame.
In diesem Beispiel berechnen wir den Gesamtumsatz für jede Area und speichern ihn in einer neuen Spalte mit dem Namen region_total_sales.
Anschließend berechnen wir den Anteil jeder Bestellung am Gesamtumsatz ihrer Area. Im Gegensatz zu agg()wodurch die Daten auf eine Zeile professional Gruppe reduziert werden, remodel() Gibt Werte zurück, die an den ursprünglichen Zeilen ausgerichtet sind, was es für die Characteristic-Entwicklung sehr nützlich macht.
df("region_total_sales") = df.groupby("area")("net_sales").remodel("sum")
df("order_share_of_region") = df("net_sales") / df("region_total_sales")
df(("order_id", "area", "net_sales", "region_total_sales", "order_share_of_region"))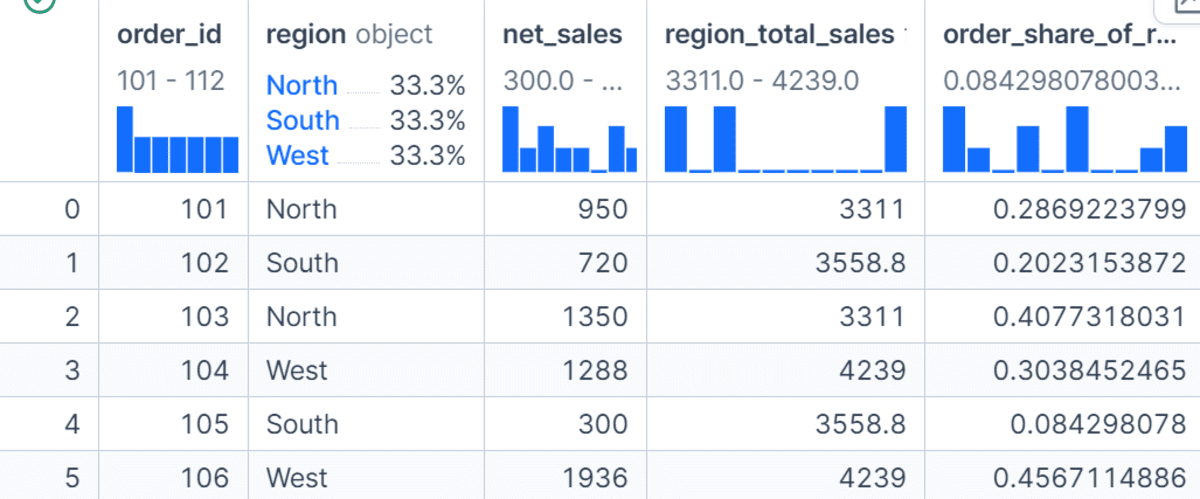
# Gruppen filtern mit filter()
Der filter() Mit der Methode können Sie ganze Gruppen basierend auf einer Bedingung behalten oder entfernen. In diesem Beispiel behalten wir nur die Regionen bei, in denen der Gesamtnettoumsatz mehr als 3.000 beträgt.
Anstatt eine Zusammenfassungszeile professional Gruppe zurückzugeben, filter() gibt die Originalzeilen der Gruppen zurück, die die Bedingung erfüllen. Dies ist nützlich, wenn Sie leistungsschwache Gruppen entfernen oder nur Gruppen behalten möchten, die eine Geschäftsregel erfüllen.
high_sales_regions = df.groupby("area").filter(lambda group: group("net_sales").sum() > 3000)
high_sales_regions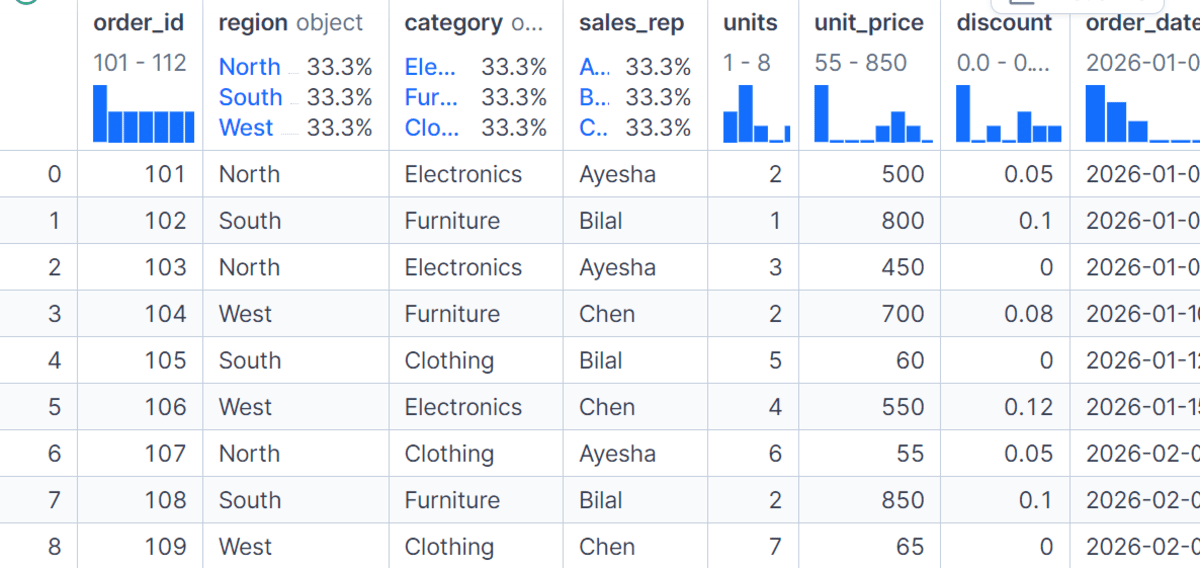
# Anwenden benutzerdefinierter Logik mit apply()
Der apply() Die Methode bietet Ihnen mehr Flexibilität, da Sie damit für jede Gruppe benutzerdefinierte Logik ausführen können.
In diesem Beispiel verwenden wir apply() mit nlargest() um die Prime-Reihenfolge nach Nettoumsatz in jeder Area zu finden. Dies ist nützlich, wenn integrierte Aggregationsfunktionen für Ihre Analyse nicht ausreichen.
Jedoch, apply() kann langsamer sein als integrierte Methoden wie sum(), imply(), agg()Und remodel()Daher ist es am besten, es nur zu verwenden, wenn Sie benutzerdefinierte gruppenweise Vorgänge benötigen.
top_order_by_region = (
df.groupby("area", group_keys=False)
.apply(lambda group: group.nlargest(1, "net_sales"))
)
top_order_by_region
# Gruppierung nach Datum
GroupBy ist auch für zeitbasierte Analysen sehr nützlich.
In diesem Beispiel extrahieren wir den Monat aus order_date Spalte und gruppieren Sie die Daten nach Monat.
Anschließend berechnen wir den Gesamtumsatz und die Gesamtbestellungen für jeden Monat. Dieser Ansatz ist hilfreich bei der Analyse von Developments im Zeitverlauf, z. B. monatlichen Verkäufen, wöchentlicher Benutzeraktivität oder jährlichem Umsatzwachstum.
df("month") = df("order_date").dt.to_period("M").astype(str)
monthly_sales = (
df.groupby("month", as_index=False)
.agg(total_sales=("net_sales", "sum"), total_orders=("order_id", "rely"))
)
monthly_sales
# Gruppieren nach Datum mit pd.Grouper
pd.Grouper Bietet eine sauberere Möglichkeit, Zeitreihendaten zu gruppieren, ohne manuell eine separate Monatsspalte zu erstellen.
In diesem Beispiel gruppieren wir die DataFrame von order_date Verwenden Sie eine monatliche Häufigkeit und berechnen Sie den Gesamtumsatz und die Gesamtbestellungen.
Dies ist besonders nützlich, wenn Sie mit realen Datensätzen arbeiten, die Zeitstempel enthalten, und Sie Daten nach Tag, Woche, Monat, Quartal oder Jahr zusammenfassen möchten.
monthly_sales_grouper = (
df.groupby(pd.Grouper(key="order_date", freq="M"))
.agg(total_sales=("net_sales", "sum"), total_orders=("order_id", "rely"))
.reset_index()
)
monthly_sales_grouper
# Erstellen einer Zusammenfassung im Pivot-Stil mit GroupBy
Sie können kombinieren groupby() mit unstack() um eine Übersichtstabelle im Pivot-Stil zu erstellen.
In diesem Beispiel gruppieren wir die Daten nach area Und classberechnen Sie den Gesamtnettoumsatz und formen Sie das Ergebnis dann um, sodass Kategorien zu Spalten werden. Dadurch lässt sich die Ausgabe leichter über Regionen und Kategorien hinweg vergleichen. Dies ist eine großartige Technik, wenn Sie eine kompakte Tabelle für Berichte oder schnelle Analysen benötigen.
region_category_table = (
df.groupby(("area", "class"))("net_sales")
.sum()
.unstack(fill_value=0)
)
region_category_table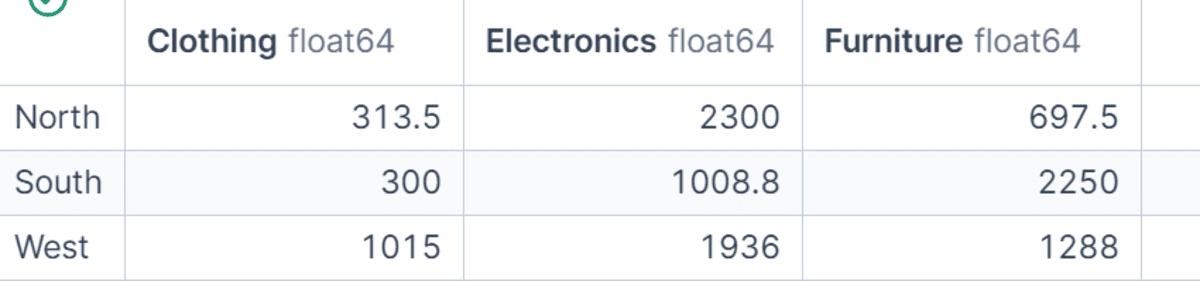
# Abschluss
Pandas GroupBy ist eines der leistungsstärksten Instruments zur Datenanalyse in Python. Es hilft Ihnen, Daten zusammenzufassen, Gruppen zu vergleichen, neue Funktionen zu erstellen, Ergebnisse zu filtern und benutzerdefinierte Berechnungen anzuwenden, ohne unnötige manuelle Logik schreiben zu müssen.
Während ich an diesem Tutorial arbeitete, wurde mir klar, wie viel Tiefe in GroupBy steckt. Selbst nachdem ich jahrelang mit Daten gearbeitet hatte, lernte ich neue und bessere Wege, um häufige Probleme zu lösen. Funktionen wie pd.Grouperbenutzerdefinierte Aggregationsfunktionen und remodel() zeichneten sich dadurch aus, dass sie viele Aufgaben schneller, sauberer und einfacher zu warten machen.
Aus diesem Grund ist es auch wichtig, die nativen Instruments zu verstehen. Es ist verlockend, sich auf Vibe-Coding oder schnelle benutzerdefinierte Lösungen zu verlassen, aber diese können oft zu langsamerem und komplizierterem Code führen. Wenn Sie wissen, was Pandas bereits bietet, können Sie Lösungen schreiben, die effizienter, wiederverwendbarer und praktischer für die Datenanalyse in der realen Welt sind.
In diesem Tutorial haben wir die nützlichsten GroupBy-Vorgänge behandelt, einschließlich grundlegender Aggregation, benannter Aggregation, mehrspaltiger Gruppierung, Sortierung, rely() vs measurement(), remodel(), filter(), apply()Datumsgruppierung und Zusammenfassungen im Pivot-Stil. Sobald Sie diese Muster verstanden haben, können Sie GroupBy verwenden, um viele Fragen zur realen Datenanalyse schnell und sicher zu beantworten.
Abid Ali Awan (@1abidaliawan) ist ein zertifizierter Datenwissenschaftler, der gerne Modelle für maschinelles Lernen erstellt. Derzeit konzentriert er sich auf die Erstellung von Inhalten und das Schreiben technischer Blogs zu maschinellem Lernen und Datenwissenschaftstechnologien. Abid verfügt über einen Grasp-Abschluss in Technologiemanagement und einen Bachelor-Abschluss in Telekommunikationstechnik. Seine Imaginative and prescient ist es, ein KI-Produkt mithilfe eines graphischen neuronalen Netzwerks für Schüler mit psychischen Erkrankungen zu entwickeln.