Eine visuelle Tour durch die größten Innovationen im Bereich Deep Studying und Pc Imaginative and prescient.
Vor CNNs bestand die Standardmethode zum Trainieren eines neuronalen Netzwerks zum Klassifizieren von Bildern darin, das Bild in eine Liste von Pixeln zu glätten und diese durch ein Feedforward-Neuralnetzwerk zu leiten, um die Klasse des Bilds auszugeben. Das Downside bei der Glättung des Bilds besteht darin, dass die wesentlichen räumlichen Informationen im Bild verworfen werden.
1989 führten Yann LeCun und sein Group Convolutional Neural Networks ein – das Rückgrat der Pc Imaginative and prescient-Forschung der letzten 15 Jahre! Im Gegensatz zu Feedforward-Netzwerken bewahren CNNs die 2D-Natur von Bildern und sind in der Lage, Informationen räumlich zu verarbeiten!
In diesem Artikel werden wir die Geschichte der CNNs speziell für Bildklassifizierungsaufgaben durchgehen – angefangen von den frühen Forschungsjahren in den 90er Jahren bis hin zur goldenen Ära Mitte der 2010er Jahre, als viele der genialsten Deep-Studying-Architekturen aller Zeiten konzipiert wurden. Abschließend diskutieren wir die neuesten Tendencies in der aktuellen CNN-Forschung, da sie mit Aufmerksamkeits- und Bildtransformatoren konkurrieren.
Besuche die YouTube-Video das alle Konzepte in diesem Artikel visuell mit Animationen erklärt. Sofern nicht anders angegeben, werden alle in diesem Artikel verwendeten Bilder und Illustrationen von mir selbst beim Erstellen der Videoversion erstellt.

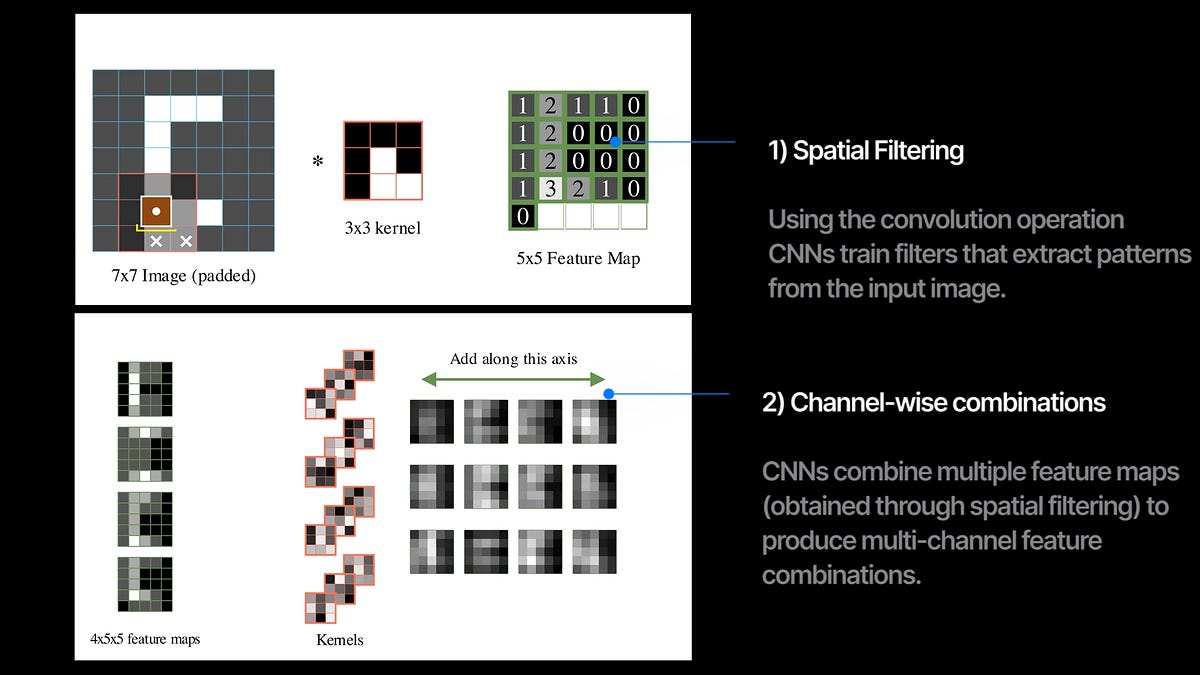
Das Herzstück eines CNN ist die Faltungsoperation. Wir scannen das Bild mit dem Filter und berechnen an jeder Überlappungsstelle das Skalarprodukt des Filters mit dem Bild. Diese resultierende Ausgabe wird als Function-Map bezeichnet und erfasst, wie stark und wo das Filtermuster im Bild vorhanden ist.

In einer Faltungsschicht trainieren wir mehrere Filter, die verschiedene Merkmalskarten aus dem Eingabebild extrahieren. Wenn wir mehrere Faltungsschichten mit einer gewissen Nichtlinearität nacheinander stapeln, erhalten wir ein Faltungsneuronales Netzwerk (CNN).
Jede Faltungsschicht führt additionally gleichzeitig zwei Dinge aus:
1. räumliche Filterung mit der Faltungsoperation zwischen Bildern und Kerneln und
2. Kombinieren der mehreren Eingangskanäle und geben Sie einen neuen Satz Kanäle aus.
90 Prozent der Forschung in CNNs zielten darauf ab, genau diese beiden Dinge zu modifizieren oder zu verbessern.

Das Papier von 1989
Dieses Papier von 1989 hat uns beigebracht, wie man nichtlineare CNNs von Grund auf mit Backpropagation trainiert. Sie geben 16×16 Graustufenbilder handgeschriebener Ziffern ein und durchlaufen zwei Faltungsschichten mit 12 Filtern der Größe 5×5. Die Filter bewegen sich während des Scannens auch mit einer Schrittweite von 2. Die Schrittweite-Faltung ist nützlich, um das Eingabebild herunterzusampeln. Nach den Konv-Schichten werden die Ausgabekarten abgeflacht und durch zwei vollständig verbundene Netzwerke geleitet, um die Wahrscheinlichkeiten für die 10 Ziffern auszugeben. Unter Verwendung des Softmax-Kreuzentropieverlusts wird das Netzwerk optimiert, um die richtigen Beschriftungen für die handgeschriebenen Ziffern vorherzusagen. Nach jeder Schicht wird auch die Tanh-Nichtlinearität verwendet – wodurch die gelernten Merkmalskarten komplexer und ausdrucksstärker werden. Mit nur 9760 Parametern battle dies ein sehr kleines Netzwerk im Vergleich zu den heutigen Netzwerken, die Hunderte Millionen Parameter enthalten.

Induktive Vorspannung
Induktive Voreingenommenheit ist ein Konzept des maschinellen Lernens, bei dem wir absichtlich bestimmte Regeln und Einschränkungen in den Lernprozess einführen, um unsere Modelle von Verallgemeinerungen wegzubringen und sie stärker in Richtung Lösungen zu bewegen, die unserem menschenähnlichen Verständnis entsprechen.
Wenn Menschen Bilder klassifizieren, führen wir auch eine räumliche Filterung durch nach gemeinsamen Mustern zu suchen, um mehrere Darstellungen zu bilden und dann Kombinieren Sie sie, um unsere Vorhersagen zu bilden. Die CNN-Architektur ist darauf ausgelegt, genau das nachzubilden. In Feedforward-Netzwerken wird jedes Pixel wie ein eigenes isoliertes Merkmal behandelt, da jedes Neuron in den Schichten mit allen Pixeln verbunden ist – in CNNs gibt es mehr Parameter-Sharing, da derselbe Filter das gesamte Bild scannt. Induktive Verzerrungen machen CNNs auch weniger datenhungrig, da sie aufgrund des Netzwerkdesigns lokale Mustererkennung kostenlos erhalten, aber Feedforward-Netzwerke müssen ihre Trainingszyklen damit verbringen, sie von Grund auf zu lernen.