# Einführung
Agentencodierungssitzungen sind teuer. Eine einzelne Claude Code-Sitzung – Dateien lesen, Code schreiben, Assessments ausführen, Iteration – kann 10–50-mal mehr Token verbrennen als eine einfache Chat-Konversation. Im Maßstab summiert sich das schnell. Fügen Sie Ratenbegrenzungen hinzu, die einen lang laufenden Workflow mitten in der Sitzung unterbrechen können, und die Abhängigkeit von einer API eines Drittanbieters, die die Preise ändern, strengere Richtlinien durchsetzen oder jederzeit ausfallen kann, und die Argumente für lokale Inferenz werden klar.
Lokale Modelle im Jahr 2026 sind intestine genug. Für die Aufgaben, die Claude Code täglich erledigt – Code-Vervollständigung, Refactoring, Debugging, Codebasis-Erklärung – deckt ein sorgfältig ausgewähltes quantisiertes Modell, das lokal ausgeführt wird, die überwiegende Mehrheit der realen Anwendungsfälle zu null Kosten professional Token und ohne Ratenbeschränkungen ab. Dieser Artikel behandelt drei Inferenz-Backends (Ollama, LM StudioUnd lama.cpp), die genauen Umgebungsvariablen und Konfigurationsdateien, um sie jeweils mit Claude Code zu verbinden, eine kuratierte Tabelle mit Modellen, die es wert sind, ausgeführt zu werden, und die Fehlerbehebungskorrekturen für die Probleme, auf die Sie tatsächlich stoßen.
# Wie Claude Code eine Verbindung zu jedem lokalen Modell herstellt
Der Mechanismus ist einfacher, als es die meisten Anleitungen vermuten lassen. Claude Code sendet Anfragen im Anthropic Messages API-Format. Standardmäßig gehen diese Anfragen an die Server von Anthropic. Einstellung ANTHROPIC_BASE_URL leitet sie an jeden Server weiter, der dasselbe Format spricht, das jetzt nativ Ollama, LM Studio und llama.cpp enthält.
Laut der offiziellen Dokumentation zu Umgebungsvariablen von Claude Code sind für dieses Setup folgende Variablen wichtig:
ANTHROPIC_BASE_URL: Leitet alle API-Aufrufe von den Anthropic-Servern an die von Ihnen festgelegte URL um. Stellen Sie dies auf die Adresse Ihres lokalen Inferenzservers ein.ANTHROPIC_API_KEY: der im Anforderungsheader gesendete API-Schlüssel. Lokale Server ignorieren normalerweise die Authentifizierung, daher wird diese normalerweise auf eine Platzhalterzeichenfolge wie „lokal“ oder „Ollama.“ANTHROPIC_AUTH_TOKEN: ein alternativer Authentifizierungsheader. Einige lokale Server prüfen dies anstelle des API-Schlüssels. Legen Sie den gleichen Platzhalter fest.
ANTHROPIC_DEFAULT_SONNET_MODEL, ANTHROPIC_DEFAULT_HAIKU_MODELUnd ANTHROPIC_DEFAULT_OPUS_MODEL: Claude Code fordert intern je nach Aufgabe unterschiedliche Modellebenen an. Diese drei Variablen ordnen jede Ebene dem Namen Ihres lokalen Modells zu. Ohne sie sendet Claude Code Anfragen für claude-sonnet-4-20250514 an Ihren lokalen Server, der die Anfrage ablehnt, da lokal kein solches Modell vorhanden ist.
Im Januar 2026 fügte Ollama native Unterstützung für die Anthropic Messages API hinzu. Dies warfare die technische Änderung, die diesen Workflow ohne Übersetzungs-Proxys praktisch machte. LM Studio hat einen nativen hinzugefügt /v1/messages Endpunkt in Model 0.4.1. llama.cpp verfügt schon länger über direkte Anthropic-API-Unterstützung. Alle drei sprechen jetzt das native Protokoll von Claude Code.
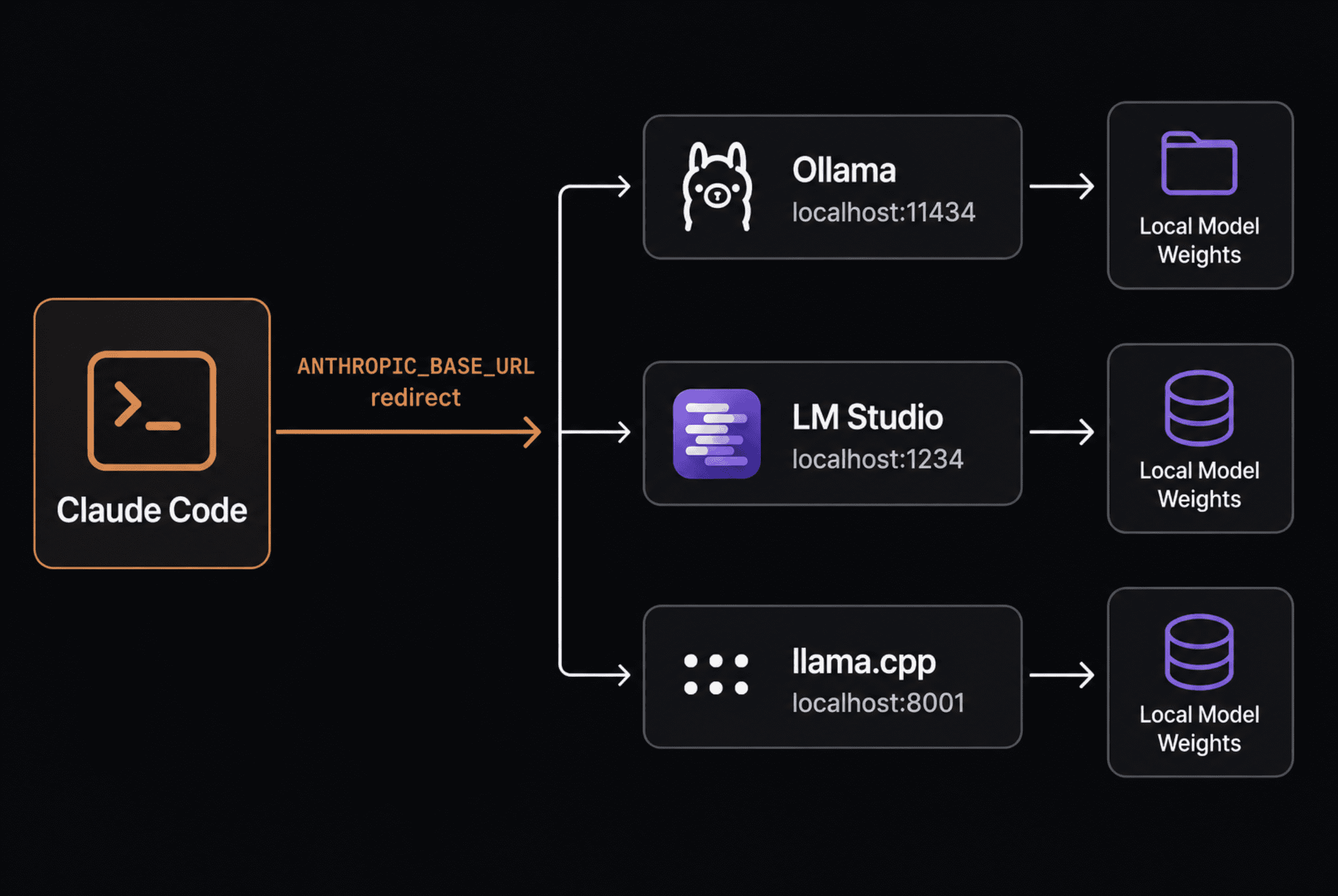
Ein übersichtliches Architekturdiagramm, das Claude Code, Ollama, LM Studio und llama.cpp | zeigt Bild vom Autor
# Backend 1: Ollama
Ollama ist der richtige Ausgangspunkt. Es verwaltet die gesamte Komplexität der Modellverwaltung – Herunterladen von Gewichtungen, Quantisierung, GPU- und CPU-Zuweisung und Bereitstellung – über eine einfache Befehlszeilenschnittstelle (CLI). Ein Befehl zum Installieren, ein Befehl zum Abrufen eines Modells, ein paar Umgebungsvariablen zum Konfigurieren. Es wird nach der Set up als Hintergrunddienst ausgeführt, sodass kein manueller Serverstart erforderlich ist.
Voraussetzungen
- macOS, Linux oder Home windows (WSL2 unter Home windows empfohlen)
- Mindestens 16 GB RAM für den praktischen Einsatz (32 GB empfohlen)
- GPU mit 8+ GB VRAM für GPU-Inferenz oder nur CPU mit ausreichend RAM
- Ollama v0.14.0 oder höher ist für die Anthropic Messages API-Unterstützung erforderlich
Ollama installieren:
# macOS and Linux -- one command set up
curl -fsSL https://ollama.com/set up.sh | sh
# Confirm the model -- should be 0.14.0+ for Claude Code compatibility
ollama model
# Anticipated: ollama model is 0.14.x or increased
# Home windows: obtain the installer from https://ollama.com
# Native Home windows help has improved considerably in current releasesNach der Set up startet Ollama automatisch als Hintergrunddienst auf dem Port 11434. Sie können überprüfen, ob es ausgeführt wird:
# Examine the Ollama server is dwell
curl http://localhost:11434
# Anticipated response:
# Ollama is operatingZiehen Sie ein Codierungsmodell:
# GLM-4.7-Flash -- really helpful place to begin
# Sturdy device calling, 128K context, matches on 8 GB VRAM
# Apache 2.0 license
ollama pull glm-4.7-flash:newest
# Qwen3-Coder -- robust code technology and instruction following
# Requires 20+ GB VRAM for the complete mannequin
ollama pull qwen3-coder
# Devstral-Small -- particularly designed for agentic coding workflows
# Group-tested for Claude Code compatibility
# 24B, requires 16+ GB VRAM
ollama pull devstral-small-2:24b
# Confirm the mannequin is downloaded and prepared
ollama record
# Exhibits all pulled fashions with their sizes and modification dates// Konfigurieren von Claude Code für die Verwendung von Ollama
Possibility 1: Shell-Export (nur aktuelle Terminalsitzung)
# Redirect Claude Code to your native Ollama server
export ANTHROPIC_BASE_URL="http://localhost:11434"
# Native servers don't require actual authentication
# Set these to any non-empty string -- Ollama ignores the worth
export ANTHROPIC_API_KEY="ollama"
export ANTHROPIC_AUTH_TOKEN="ollama"
# Map Claude Code's mannequin tier requests to your native mannequin identify
# Claude Code internally requests sonnet/haiku/opus -- these variables
# translate these tier names to no matter mannequin you've pulled regionally
export ANTHROPIC_DEFAULT_SONNET_MODEL="glm-4.7-flash:newest"
export ANTHROPIC_DEFAULT_HAIKU_MODEL="glm-4.7-flash:newest"
export ANTHROPIC_DEFAULT_OPUS_MODEL="glm-4.7-flash:newest"
# Launch Claude Code -- it would now use Ollama as an alternative of the Anthropic API
claudePossibility 2: ~/.claude/settings.json (everlasting, gilt für alle Sitzungen)
Dieser Ansatz überdauert Terminal-Neustarts und gilt jedes Mal, wenn Sie Claude Code starten. Claude Code liest Umgebungsvariablen aus settings.json beim Begin, damit sie wirksam werden, egal wie claude wurde ins Leben gerufen.
Erstellen oder bearbeiten ~/.claude/settings.json:
{
"env": {
"ANTHROPIC_BASE_URL": "http://localhost:11434",
"ANTHROPIC_API_KEY": "ollama",
"ANTHROPIC_AUTH_TOKEN": "ollama",
"ANTHROPIC_DEFAULT_SONNET_MODEL": "glm-4.7-flash:newest",
"ANTHROPIC_DEFAULT_HAIKU_MODEL": "glm-4.7-flash:newest",
"ANTHROPIC_DEFAULT_OPUS_MODEL": "glm-4.7-flash:newest"
}
}Possibility 3: .env Datei im Projektverzeichnis (Projektüberschreibung)
Wenn Sie möchten, dass ein bestimmtes Projekt ein anderes Modell verwendet und gleichzeitig Ihre globalen Einstellungen auf der Anthropic API beibehalten:
# .env in your undertaking root -- loaded routinely by Claude Code
ANTHROPIC_BASE_URL=http://localhost:11434
ANTHROPIC_API_KEY=ollama
ANTHROPIC_AUTH_TOKEN=ollama
ANTHROPIC_DEFAULT_SONNET_MODEL=qwen3-coder
ANTHROPIC_DEFAULT_HAIKU_MODEL=qwen3-coder
ANTHROPIC_DEFAULT_OPUS_MODEL=qwen3-coderÜberprüfen Sie die Verbindung:
# Launch Claude Code with a easy check
claude
# Inside Claude Code, run a fundamental immediate:
# > What mannequin are you operating?
# An area mannequin ought to reply with out making any Anthropic API calls.
# To verify no exterior calls are being made, run with verbose logging:
claude --verbose
# Search for traces exhibiting requests going to localhost:11434
# relatively than api.anthropic.comVollständiger Arbeitsablauf von Grund auf:
curl -fsSL https://ollama.com/set up.sh | sh # 1. Set up Ollama
ollama pull glm-4.7-flash:newest # 2. Pull mannequin (~4 GB)
export ANTHROPIC_BASE_URL="http://localhost:11434" # 3. Redirect Claude Code
export ANTHROPIC_API_KEY="ollama" # 4. Set placeholder auth
export ANTHROPIC_AUTH_TOKEN="ollama"
export ANTHROPIC_DEFAULT_SONNET_MODEL="glm-4.7-flash:newest"
export ANTHROPIC_DEFAULT_HAIKU_MODEL="glm-4.7-flash:newest"
export ANTHROPIC_DEFAULT_OPUS_MODEL="glm-4.7-flash:newest"
claude # 5. Launch# Backend 2: LM Studio
LM Studio ist die richtige Wahl, wenn Sie eine grafische Oberfläche zum Durchsuchen und Verwalten von Modellen wünschen, anstatt vollständig im Terminal zu arbeiten. Seit Model 0.4.1 ist eine native Anthropic-kompatible Model enthalten /v1/messages Endpunkt – derselbe Pfad, den Claude Code erwartet – daher ist keine Übersetzungsebene oder Proxy erforderlich.
Voraussetzungen:
- macOS, Home windows oder Linux
- GPU mit 6+ GB VRAM empfohlen (nur CPU ist möglich, aber langsam)
- Laden Sie es von lmstudio.ai herunter oder verwenden Sie das CLI-Installationsprogramm für Headless-Server
Installieren und konfigurieren Sie LM Studio:
# On a server or VM and not using a GUI -- CLI installer
curl -fsSL https://releases.lmstudio.ai/cli/set up.sh | bash
# Or obtain the desktop app from https://lmstudio.ai for GUI useSchritte zur GUI-Einrichtung:
- Öffnen Sie LM Studio und suchen Sie nach einem Codierungsmodell (suchen Sie nach „qwen coder“ oder „devstral“).
- Laden Sie das Modell herunter. LM Studio übernimmt die Quantisierungsauswahl automatisch.
- Gehe zum Lokaler Server Registerkarte (die
<>Image in der linken Seitenleiste). - Legen Sie die Kontextgröße fest. LM Studio empfiehlt, mit mindestens 25.000 Token zu beginnen und diese für bessere Ergebnisse zu erhöhen.
- Klicken Starten Sie den Server.
- Notieren Sie sich den Port (Commonplace: 1234) und kopieren Sie den Modellnamen genau wie gezeigt.
Hinweis: Kopieren Sie die Modellkennung genau. LM Studio zeigt genau die Zeichenfolge an, an die Sie übergeben müssen
ANTHROPIC_DEFAULT_SONNET_MODEL. Eine Nichtübereinstimmung ist hier der häufigste Fehlermodus.
Claude-Code konfigurieren:
# Set the bottom URL to LM Studio's native server
export ANTHROPIC_BASE_URL="http://localhost:1234"
export ANTHROPIC_API_KEY="lm-studio"
export ANTHROPIC_AUTH_TOKEN="lm-studio"
# Change the mannequin identify with what LM Studio exhibits to your loaded mannequin
# Copy it precisely -- together with any model suffix or quantization tag
export ANTHROPIC_DEFAULT_SONNET_MODEL="qwen2.5-coder-32b-instruct"
export ANTHROPIC_DEFAULT_HAIKU_MODEL="qwen2.5-coder-32b-instruct"
export ANTHROPIC_DEFAULT_OPUS_MODEL="qwen2.5-coder-32b-instruct"Oder beharrlich drin ~/.claude/settings.json:
{
"env": {
"ANTHROPIC_BASE_URL": "http://localhost:1234",
"ANTHROPIC_API_KEY": "lm-studio",
"ANTHROPIC_AUTH_TOKEN": "lm-studio",
"ANTHROPIC_DEFAULT_SONNET_MODEL": "qwen2.5-coder-32b-instruct",
"ANTHROPIC_DEFAULT_HAIKU_MODEL": "qwen2.5-coder-32b-instruct",
"ANTHROPIC_DEFAULT_OPUS_MODEL": "qwen2.5-coder-32b-instruct"
}
}So führen Sie aus:
# 1. Begin the LM Studio server from the GUI (Native Server tab > Begin Server)
# 2. Set atmosphere variables
export ANTHROPIC_BASE_URL="http://localhost:1234"
export ANTHROPIC_API_KEY="lm-studio"
export ANTHROPIC_AUTH_TOKEN="lm-studio"
export ANTHROPIC_DEFAULT_SONNET_MODEL="your-model-name-here"
export ANTHROPIC_DEFAULT_HAIKU_MODEL="your-model-name-here"
export ANTHROPIC_DEFAULT_OPUS_MODEL="your-model-name-here"
# 3. Launch
claude# Backend 3: llama.cpp
lama.cpp ist die richtige Wahl, wenn Sie direkte Kontrolle über Inferenzparameter benötigen – Quantisierungstyp, KV-Cache-Konfiguration, Stapelgröße, Thread-Anzahl – oder wenn Sie auf einem Server laufen und den geringsten Overhead wünschen. Es verfügt über native Anthropic Messages API-Unterstützung, sodass kein Proxy oder keine Übersetzungsschicht erforderlich ist.
Voraussetzungen:
- Eine Modelldatei im GGUF-Format (Obtain von Hugging Face; Suche nach „GGUF“-Versionen eines beliebigen Modells)
- CUDA-fähige GPU für GPU-Inferenz oder nur CPU für langsamere Inferenz
- CMake und ein C++-Compiler für Quellcode-Builds (unter Linux/CUDA wird der Quellcode empfohlen)
Installieren Sie llama.cpp:
# macOS -- Homebrew is easiest
brew set up llama.cpp
# Linux with CUDA -- construct from supply for greatest GPU efficiency
git clone https://github.com/ggml-org/llama.cpp
cd llama.cpp
cmake -B construct -DGGML_CUDA=ON # Allow CUDA acceleration
cmake --build construct --config Launch # Construct
# Binaries in ./construct/bin/
# Linux CPU-only construct
cmake -B construct
cmake --build construct --config Launch
# Home windows -- pre-built binaries out there at:
# https://github.com/ggml-org/llama.cpp/releases
# Obtain the CUDA or CPU variant matching your {hardware}Laden Sie ein GGUF-Modell herunter:
# Set up the Hugging Face CLI if you happen to wouldn't have it
pip set up huggingface-hub
# Obtain GLM-4.7-Flash in Q4_K_XL quantization (~4.5 GB)
# This quantization provides a very good dimension/high quality steadiness for coding
huggingface-cli obtain unsloth/GLM-4.7-Flash-GGUF
GLM-4.7-Flash-UD-Q4_K_XL.gguf
--local-dir ./fashions/
# Or obtain Qwen3-Coder in This autumn quantization (~15 GB for 32B)
huggingface-cli obtain Qwen/Qwen3-Coder-32B-Instruct-GGUF
qwen3-coder-32b-instruct-q4_k_m.gguf
--local-dir ./fashions/Starten Sie den llama.cpp-Server:
# Begin llama-server with Anthropic API help and a 128K context window
llama-server
--model ./fashions/GLM-4.7-Flash-UD-Q4_K_XL.gguf
--alias "glm-4.7-flash" # This identify goes in ANTHROPIC_DEFAULT_SONNET_MODEL
--port 8001
--ctx-size 131072 # 128K context -- vital for giant codebases
--flash-attn # Reminiscence-efficient consideration, improves velocity
--n-gpu-layers 99 # Offload all layers to GPU; take away for CPU-only
# For CPU-only inference (no GPU):
llama-server
--model ./fashions/GLM-4.7-Flash-UD-Q4_K_XL.gguf
--alias "glm-4.7-flash"
--port 8001
--ctx-size 32768 # Scale back context dimension on CPU to maintain reminiscence manageable
--threads 8 # Match your CPU core dependWichtige Flags erklärt:
--alias: Die Modellnamenzeichenfolge, die Claude Code in Anfragen sendet. SatzANTHROPIC_DEFAULT_SONNET_MODELum genau dazu zu passen.--ctx-size: Kontextfenster in Tokens. 131072 = 128K. Größer ist besser für die Codebasisanalyse, verbraucht aber mehr VRAM. Reduzieren Sie die Zahl, wenn Fehler wegen unzureichendem Arbeitsspeicher auftreten.--flash-attn: Flash Consideration reduziert den VRAM-Spitzenwert, indem die Aufmerksamkeit in kleineren Blöcken verarbeitet wird. Aktivieren Sie es, wann immer Ihr Construct es unterstützt.--n-gpu-layers 99: Verlagert alle Transformatorschichten auf die GPU. Der Server verwendet automatisch weniger Schichten, wenn der VRAM knapp ist.
Claude-Code konfigurieren:
export ANTHROPIC_BASE_URL="http://localhost:8001"
export ANTHROPIC_API_KEY="llama-cpp"
export ANTHROPIC_AUTH_TOKEN="llama-cpp"
# Should match the --alias you handed to llama-server precisely
export ANTHROPIC_DEFAULT_SONNET_MODEL="glm-4.7-flash"
export ANTHROPIC_DEFAULT_HAIKU_MODEL="glm-4.7-flash"
export ANTHROPIC_DEFAULT_OPUS_MODEL="glm-4.7-flash"So führen Sie aus:
# Terminal 1: begin the llama.cpp server
llama-server
--model ./fashions/GLM-4.7-Flash-UD-Q4_K_XL.gguf
--alias "glm-4.7-flash"
--port 8001
--ctx-size 131072
--flash-attn
--n-gpu-layers 99
# Terminal 2: configure and launch Claude Code
export ANTHROPIC_BASE_URL="http://localhost:8001"
export ANTHROPIC_API_KEY="llama-cpp"
export ANTHROPIC_AUTH_TOKEN="llama-cpp"
export ANTHROPIC_DEFAULT_SONNET_MODEL="glm-4.7-flash"
export ANTHROPIC_DEFAULT_HAIKU_MODEL="glm-4.7-flash"
export ANTHROPIC_DEFAULT_OPUS_MODEL="glm-4.7-flash"
claude# Das Komplette settings.json
Der Export von Umgebungsvariablen dauert nur so lange wie die Terminalsitzung. Für eine dauerhafte Konfiguration verwenden Sie ~/.claude/settings.json. Claude Code liest beim Begin Variablen aus dieser Datei, sodass sie unabhängig davon gelten, wie Claude gestartet wurde – vom Terminal, von einer VS Code-Aufgabe oder von einem Skript.
Hier ist eine produktionsbereite Model settings.json mit allen Variablen erklärt:
{
"env": {
"ANTHROPIC_BASE_URL": "http://localhost:11434",
"ANTHROPIC_API_KEY": "ollama",
"ANTHROPIC_AUTH_TOKEN": "ollama",
"ANTHROPIC_DEFAULT_SONNET_MODEL": "glm-4.7-flash:newest",
"ANTHROPIC_DEFAULT_HAIKU_MODEL": "glm-4.7-flash:newest",
"ANTHROPIC_DEFAULT_OPUS_MODEL": "glm-4.7-flash:newest",
"CLAUDE_CODE_DISABLE_EXPERIMENTAL_BETAS": "1"
}
}Warum CLAUDE_CODE_DISABLE_EXPERIMENTAL_BETAS: "1" Angelegenheiten:
Wenn Claude Code über Nicht-Anthropic-Backends verwendet wird, fügt Claude Code Anthropic-spezifische experimentelle Beta-Flags zu Anforderungsheadern hinzu – Flags, die Drittanbieter und lokale Server nicht erkennen. Dies verursacht Error: Sudden worth(s) for the anthropic-beta header auf den meisten lokalen Inferenzservern. Setzen Sie diese Variable auf "1" Entfernt diese Header, bevor die Anfrage gesendet wird, wodurch der Fehler behoben wird, ohne dass die Kernfunktionen von Claude Code beeinträchtigt werden.
Zwischen Backends wechseln:
Wenn Sie mit mehreren Backends arbeiten – Ollama für den täglichen Gebrauch, die Anthropic API für komplexe Aufgaben – besteht der sauberste Ansatz darin, separate Shell-Skripte zu verwalten, anstatt sie zu bearbeiten settings.json hin und her:
# use-local.sh -- change to Ollama
export ANTHROPIC_BASE_URL="http://localhost:11434"
export ANTHROPIC_API_KEY="ollama"
export ANTHROPIC_AUTH_TOKEN="ollama"
export ANTHROPIC_DEFAULT_SONNET_MODEL="glm-4.7-flash:newest"
export ANTHROPIC_DEFAULT_HAIKU_MODEL="glm-4.7-flash:newest"
export ANTHROPIC_DEFAULT_OPUS_MODEL="glm-4.7-flash:newest"
echo "Claude Code → native Ollama (glm-4.7-flash)"# use-anthropic.sh -- change again to the Anthropic API
unset ANTHROPIC_BASE_URL
unset ANTHROPIC_AUTH_TOKEN
unset ANTHROPIC_DEFAULT_SONNET_MODEL
unset ANTHROPIC_DEFAULT_HAIKU_MODEL
unset ANTHROPIC_DEFAULT_OPUS_MODEL
# ANTHROPIC_API_KEY ought to already be set to your actual key in your rc file
echo "Claude Code → Anthropic API"Geben Sie eines der beiden Skripte in Ihrer aktuellen Sitzung ein:
supply ./use-local.sh
claude
# Once you want the actual API for a fancy process:
supply ./use-anthropic.sh
claude# Beste lokale Fashions für Claude Code im Jahr 2026
Die {Hardware} ist die Hauptbeschränkung. Damit Claude Code mit lokalen Modellen tatsächlich für Codierungsaufgaben und nicht nur für eine Demo verwendet werden kann, sollten Sie 32 GB RAM anstreben – Apple Silicon Unified Reminiscence oder PC-RAM. 16 GB sind mit kleineren quantisierten Modellen und CPU-Auslastung machbar, aber die Generierungsgeschwindigkeit wird bei mehrstufigen Agentenaufgaben merklich langsamer sein.
| Modell | VRAM erforderlich | Kontext | Stärken | Lizenz | Befehl ziehen |
|---|---|---|---|---|---|
| glm-4.7-flash | 8 GB | 128K | Device-Aufruf, schnell, geringer VRAM | Apache 2.0 | ollama pull glm-4.7-flash |
| devstral-small-2:24b | 16 GB | 32K | Agentische Codierungsworkflows | Apache 2.0 | ollama pull devstral-small-2:24b |
| qwen3-coder | 20 GB | 128K | Codegenerierung, Anweisungen | Apache 2.0 | ollama pull qwen3-coder |
| qwen3.5:27b | 20 GB | 256K | Rundum stark, großer Kontext | Apache 2.0 | ollama pull qwen3.5:27b |
| gemma4:26b | 20 GB | 256K | Begründung, 77 % Codierungsbank | Gemma-Lizenz | ollama pull gemma4:26b |
# Beheben häufiger Probleme
- Verbindung wurde beim Starten von Claude Code abgelehnt: Der Inferenzserver läuft nicht. Dies ist das häufigste Downside und am einfachsten zu diagnostizieren.
# Examine if Ollama is operating curl http://localhost:11434 # Anticipated: "Ollama is operating" # Examine if LM Studio server is operating curl http://localhost:1234/v1/fashions # Ought to return a JSON record of loaded fashions # Examine if llama-server is operating curl http://localhost:8001/well being # Ought to return {"standing":"okay"} # If not operating -- begin the server first, then launch Claude Code ollama serve # Ollama # LM Studio: use the GUI Native Server tab # llama.cpp: run the llama-server command from the Backend 3 part - Modell nicht gefunden oder unbekannter Modellfehler: Der Modellname in Ihrem
ANTHROPIC_DEFAULT_SONNET_MODELstimmt nicht mit dem überein, was der Server weiß.# Record all fashions Ollama has out there ollama record # The mannequin identify in ANTHROPIC_DEFAULT_SONNET_MODEL should match EXACTLY # together with the tag -- "glm-4.7-flash:newest" not "glm-4.7-flash" # Confirm with a direct API name to substantiate what the server sees curl http://localhost:11434/v1/fashions - Toolaufrufe schlagen fehl oder geben Fehler zurück: Für Streaming-Device-Aufrufe, die Claude Code beim Ausführen von Funktionen oder Skripten verwendet, ist Ollama Model 0.14.3-rc1 oder höher erforderlich. Frühere Versionen der 0.14.x-Serie hatten eine unvollständige Unterstützung für Streaming-Device-Aufrufe.
# Examine your Ollama model ollama model # If under 0.14.3, replace Ollama curl -fsSL https://ollama.com/set up.sh | sh anthropic-betaHeader-Fehler:Sie werden sehen:
Error: Sudden worth(s) for the anthropic-beta header. Dies geschieht, weil Claude Code Anthropic-spezifische experimentelle Beta-Flags hinzufügt, die lokale Server nicht erkennen. Beheben Sie das Downside, indem Sie dies zu Ihrem hinzufügensettings.jsonenv-Block:"CLAUDE_CODE_DISABLE_EXPERIMENTAL_BETAS": "1"- Zurück zur Anthropic API:
# Shell session -- unset the redirect variables unset ANTHROPIC_BASE_URL unset ANTHROPIC_AUTH_TOKEN unset ANTHROPIC_DEFAULT_SONNET_MODEL unset ANTHROPIC_DEFAULT_HAIKU_MODEL unset ANTHROPIC_DEFAULT_OPUS_MODEL # Then make certain your actual API secret's set echo $ANTHROPIC_API_KEY # Ought to present your sk-ant-... key, not a placeholder # In case you used settings.json -- take away or remark out the env block # and restart Claude Code - Langsame Generierungsgeschwindigkeit: Bei Agenten-Claude-Code-Aufgaben ist die Generierungsgeschwindigkeit wichtig, da jeder Device-Aufruf ein Roundtrip ist. Wenn die Geschwindigkeit nicht ausreicht:
- Wechseln Sie zu einem kleineren oder aggressiveren quantisierten Modell (Q4_K_M statt Q8).
- Aktivieren
--flash-attnin llama.cpp, falls nicht bereits festgelegt. - Kontextgröße reduzieren (
--ctx-size); Größere Kontexte lassen sich langsamer vorab ausfüllen. - Auf Ollama, fertig
OLLAMA_NUM_GPU_LAYERS=99in Ihrer Umgebung, um eine maximale GPU-Auslastung zu erzwingen.
# Abschluss
Was früher fragile Adapter und Hacks erforderte, ist heute ein fünfstufiger Prozess. Installieren Sie das Inferenz-Backend, ziehen Sie ein Modell, legen Sie drei Umgebungsvariablen fest und Claude Code leitet an Ihren lokalen Laptop statt an die API von Anthropic weiter. Sobald Sie das Modell heruntergeladen haben, dauert die Konfiguration weniger als fünf Minuten.
Das praktische Ergebnis ist ein Codierungsassistent, dessen Ausführung nach der Einrichtung keine Kosten verursacht, keine Ratenbeschränkungen hat, Ihren Code vollständig auf Ihrem Laptop behält und die überwiegende Mehrheit der realen Codierungsanwendungsfälle mit Qualitätsniveaus abdeckt, die vor einem Jahr in lokalen Modellen nicht verfügbar waren. Beginnen Sie mit Ollama und glm-4.7-flash – Es hat die geringsten Hardwareanforderungen, die konsistenteste Unterstützung für Toolaufrufe und den schnellsten Weg zu einem funktionierenden Setup. Sobald dies ausgeführt wird, skalieren Sie das Modell basierend auf Ihrer {Hardware} und dem Qualitätsniveau, das Sie tatsächlich benötigen.
Shittu Olumide ist ein Software program-Ingenieur und technischer Autor, der sich leidenschaftlich dafür einsetzt, modernste Technologien zu nutzen, um fesselnde Erzählungen zu erschaffen, mit einem scharfen Blick fürs Element und einem Gespür für die Vereinfachung komplexer Konzepte. Sie können Shittu auch auf finden Twitter.