

# Einführung
Die zeilenweise Iteration ist einer der häufigsten Leistungsengpässe in Pandas Code. Bei kleinen Datensätzen bleibt es unbemerkt, aber für Verarbeitung großer Datenmengendas wird wirkungsvoll.
Pandas ist darauf gebaut NumPydas mit kompiliertem C-Code Operationen für ganze Arrays auf einmal ausführt. Das Durchlaufen von Zeilen in Python umgeht dies vollständig und erzwingt jede Operation zurück in den Python-Interpreter – eine Zeile nach der anderen.
Dieser Artikel behandelt 7 Alternativen zu Schleifen in Pandas, von denen jede für eine andere Artwork der Transformation geeignet ist. Am Ende haben Sie eine klare Vorstellung davon, zu welchem Werkzeug Sie je nach Artwork des Issues greifen müssen.
Sie können das Colab-Notizbuch auf GitHub herunterladen.
# Einrichten des Beispieldatensatzes
In diesem Artikel verwenden wir einen realistischen E-Commerce-Auftragsdatensatz:
import pandas as pd
import numpy as np
np.random.seed(42)
n = 100_000
classes = ('Electronics', 'Clothes', 'Dwelling & Kitchen', 'Sports activities', 'Books')
areas = ('North', 'South', 'East', 'West')
df = pd.DataFrame({
'order_id': vary(1, n + 1),
'customer_age': np.random.randint(18, 70, n),
'product_category': np.random.alternative(classes, n),
'area': np.random.alternative(areas, n),
'worth': np.spherical(np.random.uniform(5.0, 500.0, n), 2),
'amount': np.random.randint(1, 10, n),
'days_to_ship': np.random.randint(1, 14, n),
})
show(df.head())Ausgabe:
Wir haben jetzt einen Datensatz mit 100.000 Zeilen, mit dem wir arbeiten können.
# 1. Verwendung vektorisierter Operationen für die Arithmetik
Für jede Arithmetik oder jeden Vergleich in einer Spalte: vektorisierte Operationen sollte Ihr erster Instinkt sein.
Was wir tun wollen: Berechnen Sie den Gesamtumsatz professional Bestellung.
df('income') = df('worth') * df('amount')
show(df(('worth', 'amount', 'income')).head())Ausgabe:
# 2. Anwenden einer Funktion für bedingte Logik
Wenn Ihre Transformation eine Logik beinhaltet, die nicht als einfache Arithmetik ausgedrückt werden kann, .apply() ermöglicht es Ihnen, eine Funktion über eine Spalte oder Zeile zu übergeben.
Was wir tun wollen: Weisen Sie ein Versandprioritätsetikett basierend auf den Versandtagen zu.
def shipping_label(days):
if days <= 2:
return 'Categorical'
elif days <= 5:
return 'Customary'
else:
return 'Financial system'
df('shipping_tier') = df('days_to_ship').apply(shipping_label)
show(df(('days_to_ship', 'shipping_tier')).head())Ausgabe:
Benutzen .apply() ist sauber, lesbar und viel einfacher zu debuggen als eine Schleife. Verwenden Sie es, wenn Ihre Logik bedingt ist und np.the place() oder np.choose() fühlt sich zu verschachtelt an.
# 3. Verwendung np.the place() für binäre Bedingungen
Wenn Sie eine binäre Bedingung haben – ein Ergebnis, wenn wahr, ein anderes, wenn falsch – np.the place() ist die saubere und schnelle Wahl.
Was wir tun wollen: Markieren Sie Bestellungen, bei denen der Kunde Anspruch auf einen Senior-Rabatt hat.
df('senior_discount') = np.the place(df('customer_age') >= 60, True, False)
show(df(('customer_age', 'senior_discount')).head())Ausgabe:
np.the place() ist vollständig vektorisiert und deutlich schneller als .apply() für einfache wahre oder falsche Bedingungen. Betrachten Sie es als einen vektorisierten ternären Operator.
# 4. Auswahl über mehrere Bedingungen hinweg mit np.choose()
Wenn Sie mehr als zwei Bedingungen haben, np.choose() ermöglicht es Ihnen, eine Liste von Bedingungen und entsprechenden Werten zu definieren, ohne dass verschachtelte if/elif-Ketten erforderlich sind.
Was wir tun wollen: Weisen Sie einen regionalen Steuersatz zu.
circumstances = (
df('area') == 'North',
df('area') == 'South',
df('area') == 'East',
df('area') == 'West',
)
tax_rates = (0.08, 0.06, 0.07, 0.09)
df('tax_rate') = np.choose(circumstances, tax_rates, default=0.07)
df('tax_amount') = df('worth') * df('tax_rate')
show(df(('area', 'worth', 'tax_rate', 'tax_amount')).head())Ausgabe:
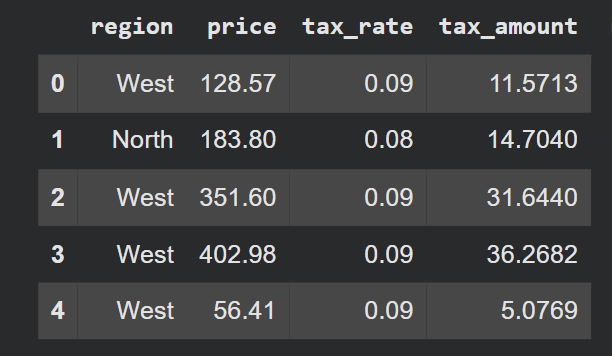
np.choose() wertet alle Bedingungen der Reihe nach aus und wählt die erste Übereinstimmung aus. Der default Der Parameter behandelt alles, was nicht übereinstimmt, was als Sicherheitsnetz nützlich ist.
# 5. Zuordnen von Werten mit einer Wörterbuchsuche
Wenn Sie Werte in einer Spalte übersetzen müssen – etwa Kategorienamen numerischen Codes zuordnen oder Schlüssel durch Beschriftungen ersetzen müssen – .map() mit einem Wörterbuch ist sauber und schnell.
Was wir tun wollen: Produktkategorien internen Abteilungscodes zuordnen.
category_codes = {
'Electronics': 'ELEC',
'Clothes': 'CLTH',
'Dwelling & Kitchen': 'HOME',
'Sports activities': 'SPRT',
'Books': 'BOOK',
}
df('dept_code') = df('product_category').map(category_codes)
show(df(('product_category', 'dept_code')).head())Ausgabe:
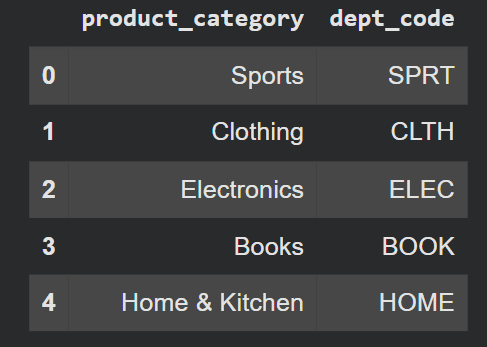
.map() funktioniert wie eine Nachschlagetabelle. Es ist eines der am wenigsten genutzten Werkzeuge bei Pandas – wir greifen oft danach .apply(lambda x: dict(x)) Wann .map(dict) macht das Gleiche schneller.
# 6. Manipulieren von Strings mit dem .str Zugriffsberechtigter
String-Manipulation Hier verwenden die Leute am häufigsten standardmäßig Schleifen oder .apply(). Der .str Zugriffsberechtigter ermöglicht es Ihnen, Zeichenfolgenoperationen über eine gesamte Spalte auszuführen, ohne dass beides erforderlich ist.
Was wir tun wollen: Extrahieren Sie das erste Wort aus dem product_category Spalte und wandeln Sie sie in Kleinbuchstaben um.
df('category_slug') = df('product_category').str.cut up().str(0).str.decrease()
show(df(('product_category', 'category_slug')).head())Ausgabe:
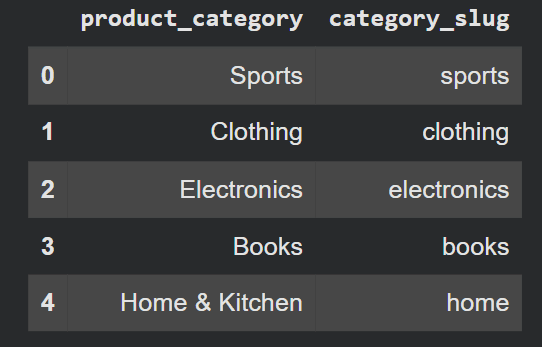
Sie können verketten .str Methoden genau wie normale Python-String-Methoden. Es unterstützt auch .str.comprises(), .str.substitute(), .str.extract() für Regex und mehr.
# 7. Gruppen aggregieren mit .groupby()
Ein gängiges Schleifenmuster ist die Iteration über Teilmengen von Daten, um Statistiken auf Gruppenebene zu berechnen. .groupby() erledigt dies nativ.
Was wir tun wollen: Berechnen Sie den Gesamtumsatz und die durchschnittliche Lieferzeit professional Produktkategorie.
abstract = (
df.groupby('product_category')
.agg(
total_revenue=('income', 'sum'),
avg_ship_days=('days_to_ship', 'imply'),
order_count=('order_id', 'depend')
)
.spherical(2)
.reset_index()
)
abstractAusgabe:
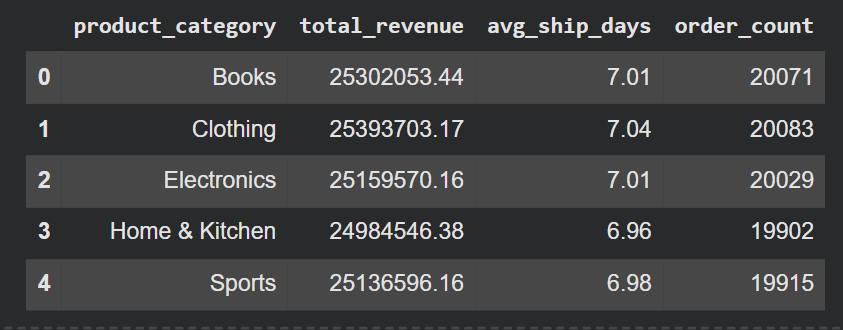
# Das richtige Werkzeug auswählen
Die meisten Transformationen, für die Sie eine Schleife schreiben würden, passen problemlos in eines dieser Muster:
| Operation / Methode | Anwendungsfall/Beschreibung |
|---|---|
| Arithmetik auf Spalten |
Führen Sie vektorisierte mathematische Operationen wie Addition, Subtraktion, Multiplikation und Division direkt in DataFrame-Spalten durch. |
Vektorisierte Operationen (*, +usw.) |
Wenden Sie elementweise Operationen effizient und ohne explizite Schleifen auf ganze Spalten an. |
| Einfache Wahr/Falsch-Bedingung |
Werten Sie boolesche Bedingungen aus, um bedingte Spalten zu filtern oder zu erstellen. |
np.the place() |
Wenden Sie bedingte (if-else) Logik vektorisiert auf Arrays und DataFrame-Spalten an. |
| Mehrere Bedingungen, mehrere Ergebnisse |
Behandeln Sie komplexe bedingte Logik mit mehreren Regeln und Ausgaben. |
np.choose() |
Wählen Sie Werte basierend auf mehreren Bedingungen aus und geben Sie entsprechende Ausgaben zurück. |
| Wertersetzung per Lookup |
Ersetzen Sie Werte mithilfe von Zuordnungswörterbüchern für schnelle Transformationen. |
.map(dict) |
Ordnen Sie Werte in einer Reihe mithilfe eines Wörterbuchs oder einer Funktion zur Ersetzung zu. |
.apply() |
Wenden Sie benutzerdefinierte Funktionen zeilen- oder spaltenweise an, um versatile Transformationen zu ermöglichen. |
| String-Manipulation |
Verwenden Sie vektorisierte String-Operationen über |
.groupby() + .agg() |
Gruppieren Sie Daten und berechnen Sie aggregierte Statistiken wie Summe, Mittelwert, Anzahl usw. |
Sobald Sie anfangen, in Spalten statt in Zeilen zu denken, werden Sie feststellen, dass sich die Pandas-API weniger wie eine Problemumgehung anfühlt, sondern eher wie die tatsächlich beabsichtigte Arbeitsweise.
Bala Priya C ist ein Entwickler und technischer Redakteur aus Indien. Sie arbeitet gerne an der Schnittstelle von Mathematik, Programmierung, Datenwissenschaft und Inhaltserstellung. Zu ihren Interessen- und Fachgebieten gehören DevOps, Datenwissenschaft und Verarbeitung natürlicher Sprache. Sie liebt es zu lesen, zu schreiben, zu programmieren und Kaffee zu trinken! Derzeit arbeitet sie daran, zu lernen und ihr Wissen mit der Entwickler-Group zu teilen, indem sie Tutorials, Anleitungen, Meinungsbeiträge und mehr verfasst. Bala erstellt außerdem ansprechende Ressourcenübersichten und Programmier-Tutorials.