
Einführung
Das Verständnis der Bedeutung eines Wortes in einem Textual content ist entscheidend für die Analyse und Interpretation großer Datenmengen. Hier kommt die Time period Frequency-Inverse Doc Frequency (TF-IDF)-Technik in der natürlichen Sprachverarbeitung (Pure Language Processing, NLP) ins Spiel. Indem TF-IDF die Einschränkungen des traditionellen Bag-of-Phrases-Ansatzes überwindet, verbessert es die Textklassifizierung und stärkt die Fähigkeit von Modellen des maschinellen Lernens, Textinformationen effektiv zu verstehen und zu analysieren. Dieser Artikel zeigt Ihnen, wie Sie ein TF-IDF-Modell von Grund auf neu erstellen in Python und wie man es numerisch berechnet.
Überblick
- TF-IDF ist ein Schlüssel NLP-Technik das die Textklassifizierung verbessert, indem es Wörtern auf Grundlage ihrer Häufigkeit und Seltenheit eine Bedeutung zuweist.
- Wesentliche Begriffe, darunter Time period Frequency (TF), Doc Frequency (DF) und Inverse Doc Frequency (IDF), werden definiert.
- Der Artikel beschreibt detailliert die schrittweise numerische Berechnung der TF-IDF-Ergebnisse, beispielsweise anhand von Dokumenten.
- Eine praktische Anleitung zur Verwendung
TfidfVectorizervon scikit-learn zum Konvertieren von Textdokumenten in eine TF-IDF-Matrix. - Es wird in Suchmaschinen, bei der Textklassifizierung, beim Clustering und bei der Zusammenfassung verwendet, berücksichtigt jedoch weder die Wortreihenfolge noch den Kontext.

Terminologie: Wichtige Begriffe, die in TF-IDF verwendet werden
Bevor Sie sich in die Berechnungen und den Code vertiefen, müssen Sie die Schlüsselbegriffe verstehen:
- T: Begriff (Wort)
- D: Dokument (Wortgruppe)
- N: Anzahl der Corpus
- Korpus: der gesamte Dokumentensatz
Was ist Time period Frequency (TF)?
Die Häufigkeit, mit der ein Begriff in einem Dokument vorkommt, wird anhand der Begriffshäufigkeit (TF) gemessen. Die Gewichtung eines Begriffs in einem Dokument steht in direktem Zusammenhang mit seiner Häufigkeit. Die TF-Formel lautet:
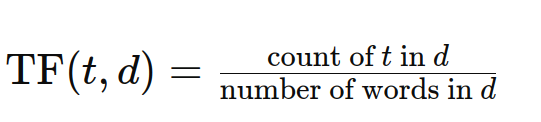
Was ist die Dokumenthäufigkeit (DF)?
Die Bedeutung eines Dokuments innerhalb eines Korpus wird anhand seiner Dokumenthäufigkeit (DF) gemessen. DF zählt die Anzahl der Dokumente, die die Phrase mindestens einmal enthalten, im Gegensatz zu TF, das die Vorkommen eines Begriffs in einem Dokument zählt. Die DF-Formel lautet:
DF
Was ist die Inverse Doc Frequency (IDF)?
Der Informationsgehalt eines Wortes wird anhand seiner inversen Dokumenthäufigkeit (IDF) gemessen. Bei der Berechnung der TF wird allen Begriffen das gleiche Gewicht zugewiesen, obwohl IDF dabei hilft, ungewöhnliche Begriffe hervorzuheben und häufige Begriffe (wie Stoppwörter) abzuwerten. Die IDF-Formel lautet:
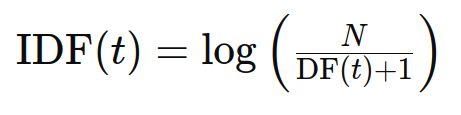
wobei N die Gesamtzahl der Dokumente und DF
Was ist TF-IDF?
TF-IDF steht für Time period Frequency-Inverse Doc Frequency, ein statistisches Maß, mit dem die Wichtigkeit eines Wortes für ein Dokument in einer Sammlung oder einem Korpus bewertet wird. Es kombiniert die Wichtigkeit eines Begriffs in einem Dokument (TF) mit der Seltenheit des Begriffs im gesamten Korpus (IDF). Die Formel lautet:
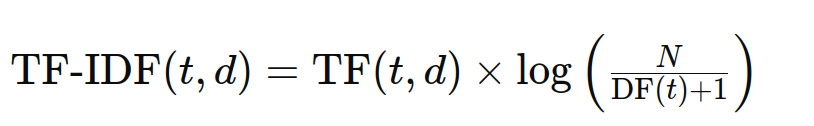
Numerische Berechnung von TF-IDF
Lassen Sie uns die numerische Berechnung von TF-IDF für die gegebenen Dokumente aufschlüsseln:
Unterlagen:
- „Der Himmel ist blau.“
- „Heute scheint die Sonne hell.“
- „Die Sonne am Himmel ist hell.“
- „Wir können die scheinende Sonne sehen, die helle Sonne.“
Schritt 1: Termfrequenz (TF) berechnen
Dokument 1: „Der Himmel ist blau.“
| Begriff | Zählen | TF |
| Die | 1 | 1/4 |
| Himmel | 1 | 1/4 |
| Ist | 1 | 1/4 |
| Blau | 1 | 1/4 |
Dokument 2: „Heute scheint die Sonne hell.“
| Begriff | Zählen | TF |
| Die | 1 | 1/5 |
| Sonne | 1 | 1/5 |
| Ist | 1 | 1/5 |
| hell | 1 | 1/5 |
| Heute | 1 | 1/5 |
Dokument 3: „Die Sonne am Himmel ist hell.“
| Begriff | Zählen | TF |
| Die | 2 | 2/7 |
| Sonne | 1 | 1/7 |
| In | 1 | 1/7 |
| Himmel | 1 | 1/7 |
| Ist | 1 | 1/7 |
| hell | 1 | 1/7 |
Dokument 4: „Wir können die scheinende Sonne sehen, die helle Sonne.“
| Begriff | Zählen | TF |
| Wir | 1 | 1/9 |
| dürfen | 1 | 1/9 |
| sehen | 1 | 1/9 |
| Die | 2 | 2/9 |
| leuchtenden | 1 | 1/9 |
| Sonne | 2 | 2/9 |
| hell | 1 | 1/9 |
Schritt 2: Inverse Dokumenthäufigkeit (IDF) berechnen
Mit N=4N = 4N=4:
| Begriff | Verteidigung | Israelische Verteidigungsstreitkräfte |
| Die | 4 | log(4/4+1)=log(0,8)≈−0,223 |
| Himmel | 2 | log(4/2+1)=log(1,333)≈0,287 |
| Ist | 3 | log(4/3+1)=log(1)=0 |
| Blau | 1 | log(4/1+1)=log(2)≈0,693 |
| Sonne | 3 | log(4/3+1)=log(1)=0 |
| hell | 3 | log(4/3+1)=log(1)=0 |
| Heute | 1 | log(4/1+1)=log(2)≈0,693 |
| In | 1 | log(4/1+1)=log(2)≈0,693 |
| Wir | 1 | log(4/1+1)=log(2)≈0,693 |
| dürfen | 1 | log(4/1+1)=log(2)≈0,693 |
| sehen | 1 | log(4/1+1)=log(2)≈0,693 |
| leuchtenden | 1 | log(4/1+1)=log(2)≈0,693 |
Schritt 3: TF-IDF berechnen
Berechnen wir nun die TF-IDF-Werte für jeden Begriff in jedem Dokument.
Dokument 1: „Der Himmel ist blau.“
| Begriff | TF | Israelische Verteidigungsstreitkräfte | TF-IDF |
| Die | 0,25 | -0,223 | 0,25 * -0,223 ≈-0,056 |
| Himmel | 0,25 | 0,287 | 0,25 * 0,287 ≈ 0,072 |
| Ist | 0,25 | 0 | 0,25 * 0 = 0 |
| Blau | 0,25 | 0,693 | 0,25 * 0,693 ≈ 0,173 |
Dokument 2: „Heute scheint die Sonne hell.“
| Begriff | TF | Israelische Verteidigungsstreitkräfte | TF-IDF |
| Die | 0,2 | -0,223 | 0,2 * -0,223 ≈ -0,045 |
| Sonne | 0,2 | 0 | 0,2 * 0 = 0 |
| Ist | 0,2 | 0 | 0,2 * 0 = 0 |
| hell | 0,2 | 0 | 0,2 * 0 = 0 |
| Heute | 0,2 | 0,693 | 0,2 * 0,693 ≈0,139 |
Dokument 3: „Die Sonne am Himmel ist hell.“
| Begriff | TF | Israelische Verteidigungsstreitkräfte | TF-IDF |
| Die | 0,285 | -0,223 | 0,285 * -0,223 ≈ -0,064 |
| Sonne | 0,142 | 0 | 0,142 * 0 = 0 |
| In | 0,142 | 0,693 | 0,142 * 0,693 ≈0,098 |
| Himmel | 0,142 | 0,287 | 0,142 * 0,287≈0,041 |
| Ist | 0,142 | 0 | 0,142 * 0 = 0 |
| hell | 0,142 | 0 | 0,142 * 0 = 0 |
Dokument 4: „Wir können die scheinende Sonne sehen, die helle Sonne.“
| Begriff | TF | Israelische Verteidigungsstreitkräfte | TF-IDF |
| Wir | 0,111 | 0,693 | 0,111 * 0,693 ≈0,077 |
| dürfen | 0,111 | 0,693 | 0,111 * 0,693 ≈0,077 |
| sehen | 0,111 | 0,693 | 0,111 * 0,693≈0,077 |
| Die | 0,222 | -0,223 | 0,222 * -0,223≈-0,049 |
| leuchtenden | 0,111 | 0,693 | 0,111 * 0,693 ≈0,077 |
| Sonne | 0,222 | 0 | 0,222 * 0 = 0 |
| hell | 0,111 | 0 | 0,111 * 0 = 0 |
TF-IDF-Implementierung in Python unter Verwendung eines integrierten Datensatzes
Nun wenden wir die TF-IDF-Berechnung an mit dem TfidfVektorisierer von scikit-learn mit einem integrierten Datensatz.
Schritt 1: Installieren Sie die erforderlichen Bibliotheken
Stellen Sie sicher, dass Sie scikit-learn installiert haben:
pip set up scikit-learnSchritt 2: Bibliotheken importieren
import pandas as pd
from sklearn.datasets import fetch_20newsgroups
from sklearn.feature_extraction.textual content import TfidfVectorizerSchritt 3: Laden Sie den Datensatz
Holen Sie sich den Datensatz der 20 Newsgroups:
newsgroups = fetch_20newsgroups(subset="practice")Schritt 4: Initialisieren TfidfVektorisierer
vectorizer = TfidfVectorizer(stop_words="english", max_features=1000)Schritt 5: Anpassen und Transformieren der Dokumente
Konvertieren Sie die Textdokumente in eine TF-IDF-Matrix:
tfidf_matrix = vectorizer.fit_transform(newsgroups.knowledge)Schritt 6: Die TF-IDF-Matrix anzeigen
Konvertieren Sie die Matrix zur besseren Lesbarkeit in einen DataFrame:
df_tfidf = pd.DataFrame(tfidf_matrix.toarray(), columns=vectorizer.get_feature_names_out())
df_tfidf.head()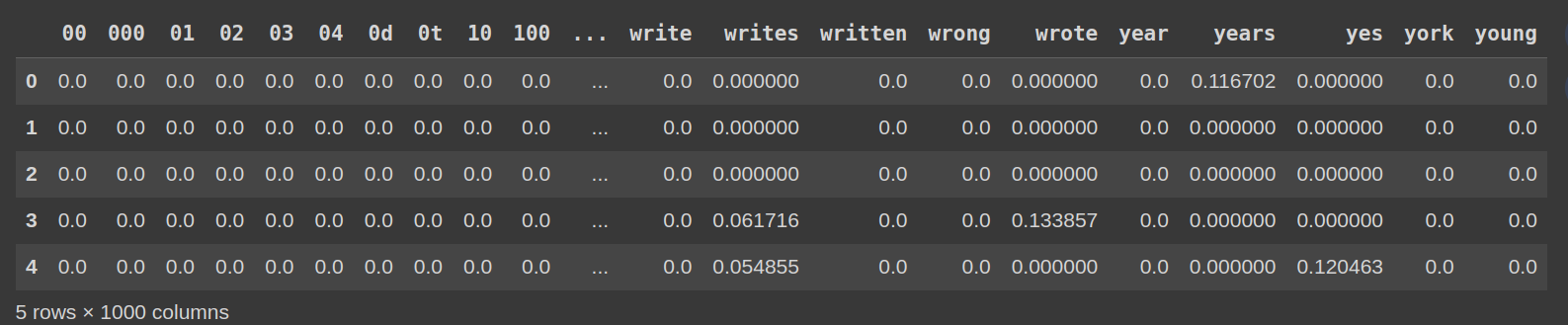
Abschluss
Mithilfe des 20 Newsgroups-Datensatzes und TfidfVectorizer können Sie eine große Sammlung von Textdokumenten in eine TF-IDF-Matrix konvertieren. Diese Matrix stellt die Wichtigkeit jedes Begriffs in jedem Dokument numerisch dar und erleichtert so verschiedene NLP Aufgaben wie Textklassifizierung, Clustering und erweiterte Textanalyse. Der TfidfVectorizer von scikit-learn bietet eine effiziente und unkomplizierte Möglichkeit, diese Transformation durchzuführen.
Häufig gestellte Fragen
Antwort: A: Die Verwendung des IDF-Logs hilft dabei, die Auswirkungen extrem häufiger Wörter zu verringern und zu verhindern, dass die IDF-Werte explodieren, insbesondere in großen Korpora. Dadurch wird sichergestellt, dass die IDF-Werte überschaubar bleiben und die Auswirkungen von Wörtern, die in Dokumenten sehr häufig vorkommen, werden reduziert.
Antwort: Ja, TF-IDF kann für große Datensätze verwendet werden. Allerdings sind eine effiziente Implementierung und ausreichende Rechenressourcen erforderlich, um die damit verbundenen großen Matrixberechnungen zu bewältigen.
Antwort: Die Beschränkung von TF-IDF besteht darin, dass es die Wortreihenfolge oder den Kontext nicht berücksichtigt, jeden Begriff unabhängig behandelt und daher möglicherweise die nuancierten Bedeutungen von Ausdrücken oder die Beziehung zwischen Wörtern übersieht.
Antwort: TF-IDF wird in verschiedenen Anwendungen verwendet, darunter:
1. Suchmaschinen bewerten Dokumente nach Relevanz für eine Abfrage
2. Textklassifizierung zur Identifizierung der wichtigsten Wörter für die Kategorisierung von Dokumenten
3. Clustering zur Gruppierung ähnlicher Dokumente anhand von Schlüsselbegriffen
4. Textzusammenfassung, um wichtige Sätze aus einem Dokument zu extrahieren