

Einführung von LLMs – NLP und neuronale Netzwerke
Die Entwicklung großer Sprachmodelle geschah nicht über Nacht. Bemerkenswerterweise begann das erste Konzept von Sprachmodellen mit regelbasierten Systemen, die als Verarbeitung natürlicher Sprache bezeichnet wurden. Diese Systeme folgen vordefinierten Regeln, die Entscheidungen treffen und Schlussfolgerungen auf der Grundlage von Texteingaben ziehen. Diese Systeme basieren auf if-else-Anweisungen, die Schlüsselwortinformationen verarbeiten und vorgegebene Ausgaben generieren. Stellen Sie sich einen Entscheidungsbaum vor, bei dem die Ausgabe eine vorgegebene Antwort ist, wenn die Eingabe X, Y, Z oder nichts enthält. Beispiel: Wenn die Eingabe die Schlüsselwörter „Mutter“ enthält, wird „Wie geht es deiner Mutter?“ ausgegeben. Andernfalls wird „Können Sie das näher erläutern?“ ausgegeben.
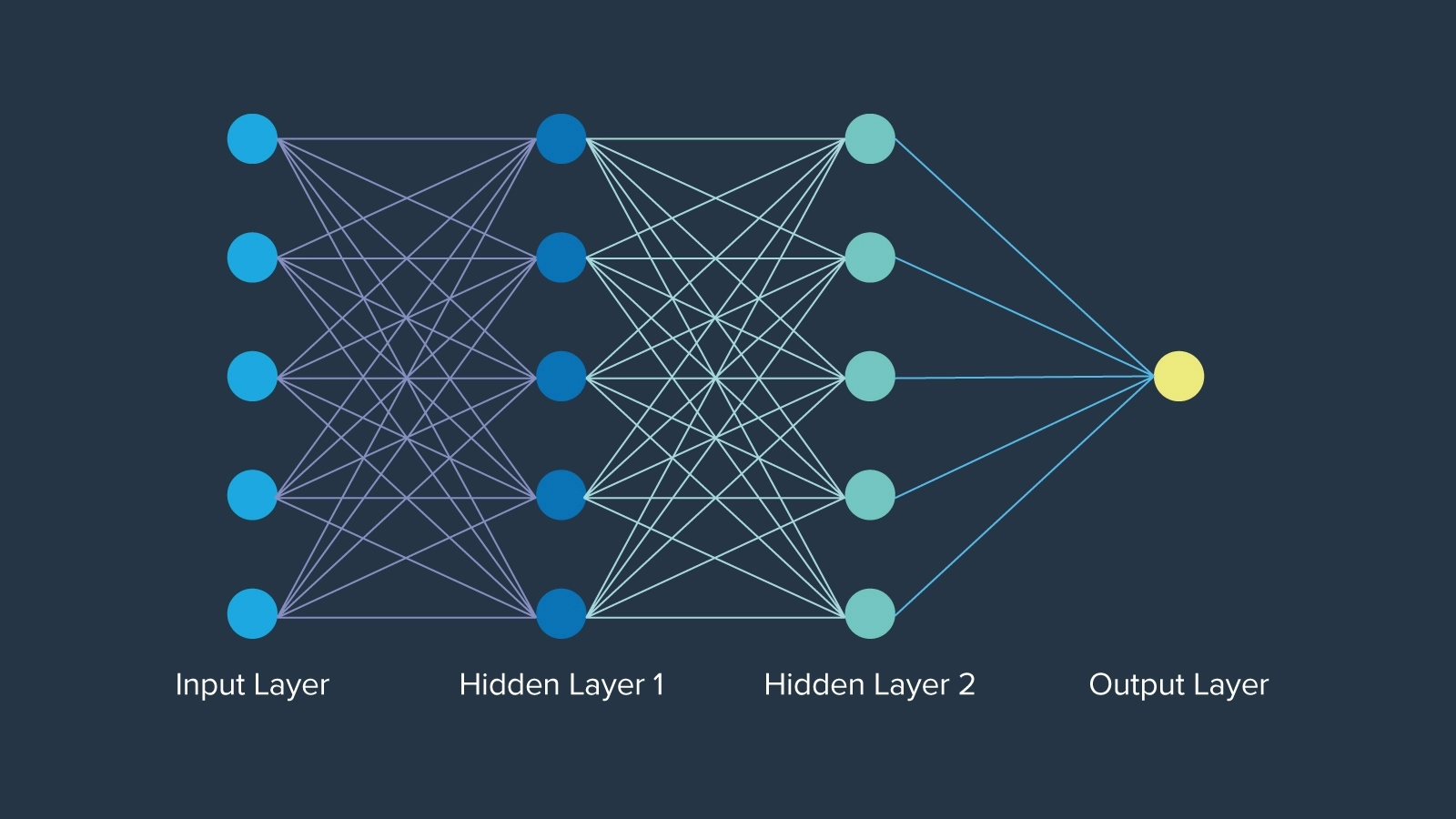
Der größte Fortschritt in der Anfangszeit waren neuronale Netzwerke, die 1943 erstmals von dem Mathematiker Warren McCulloch vorgestellt wurden. Inspiriert von den Neuronen der menschlichen Gehirnfunktion. Neuronale Netzwerke sind sogar schon rund 12 Jahre älter als der Begriff „künstliche Intelligenz“. Das Netzwerk der Neuronen in jeder Schicht ist auf eine bestimmte Weise organisiert, wobei jeder Knoten ein Gewicht hat, das seine Bedeutung im Netzwerk bestimmt. Letztendlich öffneten neuronale Netzwerke verschlossene Türen und schufen die Grundlage, auf der KI für immer aufgebaut sein wird.
Entwicklung von LLMs – Einbettungen, LSTM, Aufmerksamkeit und Transformatoren
Laptop können die Bedeutung von Wörtern, die in einem Satz zusammenstehen, nicht auf die gleiche Weise erfassen wie Menschen. Um das Computerverständnis für die semantische Analyse zu verbessern, muss zunächst eine Worteinbettungstechnik angewendet werden, die es Modellen ermöglicht, die Beziehungen zwischen benachbarten Wörtern zu erfassen, was zu einer verbesserten Leistung bei verschiedenen NLP-Aufgaben führt. Es muss jedoch eine Methode geben, um Worteinbettungen im Speicher zu speichern.
Langzeit-Kurzzeitgedächtnis (LSTM) und Gated Recurrent Models (GRUs) waren große Fortschritte innerhalb neuronaler Netzwerke, da sie sequentielle Daten effektiver verarbeiten konnten als herkömmliche neuronale Netzwerke. Obwohl LSTMs nicht mehr verwendet werden, ebneten diese Modelle den Weg für komplexere Aufgaben zum Verstehen und Generieren von Sprachen, die schließlich zum Transformer-Modell führten.
Der moderne LLM – Achtung, Transformatoren und LLM-Varianten
Die Einführung des Aufmerksamkeitsmechanismus struggle ein Wendepunkt, da er es Modellen ermöglichte, sich bei der Erstellung von Vorhersagen auf verschiedene Teile einer Eingabesequenz zu konzentrieren. Transformer-Modelle, die 2017 mit dem wegweisenden Papier „Consideration is All You Want“ eingeführt wurden, nutzten den Aufmerksamkeitsmechanismus, um ganze Sequenzen gleichzeitig zu verarbeiten, was sowohl die Effizienz als auch die Leistung erheblich verbesserte. Die acht Google-Wissenschaftler waren sich nicht darüber im Klaren, welche Auswirkungen ihr Papier auf die Entwicklung der heutigen KI haben würde.
Im Anschluss an das Paper wurde Googles BERT (2018) entwickelt und als Grundlage für alle NLP-Aufgaben angepriesen. Es diente als Open-Supply-Modell, das in zahlreichen Projekten verwendet wurde und es der KI-Group ermöglichte, Projekte zu entwickeln und zu wachsen. Sein Expertise für kontextuelles Verständnis, seine vortrainierte Natur und die Möglichkeit zur Feinabstimmung sowie die Demonstration von Transformer-Modellen ebneten den Weg für größere Modelle.
Neben BERT veröffentlichte OpenAI GPT-1, die erste Iteration ihres Transformer-Modells. GPT-1 (2018) begann mit 117 Millionen Parametern, gefolgt von GPT-2 (2019) mit einem gewaltigen Sprung auf 1,5 Milliarden Parameter, und die Entwicklung ging mit GPT-3 (2020) weiter, das 175 Milliarden Parameter umfasst. OpenAIs bahnbrechender Chatbot ChatGPT, der auf GPT-3 basiert, wurde zwei Jahre später am 30. November 2022 veröffentlicht, was einen großen Hype auslöste und den Zugang zu leistungsstarken KI-Modellen wirklich demokratisierte. Erfahren Sie mehr über die Unterschied zwischen BERT und GPT-3.
Welche technologischen Fortschritte bestimmen die Zukunft des LLM?
Fortschritte bei der {Hardware}, Verbesserungen bei Algorithmen und Methoden sowie die Integration von Multimodalität tragen alle zur Weiterentwicklung großer Sprachmodelle bei. Da die Branche neue Wege findet, LLMs effektiv zu nutzen, wird sich die weitere Weiterentwicklung an jede Anwendung anpassen und schließlich die Computerlandschaft völlig verändern.
Fortschritte bei der {Hardware}
Die einfachste und direkteste Methode zur Verbesserung von LLMs ist die Verbesserung der eigentlichen {Hardware}, auf der das Modell läuft. Die Entwicklung spezialisierter {Hardware} wie Grafikprozessoren (GPUs) Das Coaching und die Inferenz großer Sprachmodelle wurden erheblich beschleunigt. GPUs mit ihren parallelen Verarbeitungsfunktionen sind für die Verarbeitung der riesigen Datenmengen und komplexen Berechnungen, die LLMs erfordern, unverzichtbar geworden.
OpenAI verwendet NVIDIA-GPUs für seine GPT-Modelle und struggle einer der ersten NVIDIA DGX-Kunden. Ihre Beziehung erstreckte sich vom Aufkommen der KI bis zur Weiterführung der KI, als der CEO die erste NVIDIA DGX-1, aber auch die neueste NVIDIA DGX H200 persönlich übergab. Diese GPUs verfügen über riesige Speichermengen und Parallel Computing für Coaching, Bereitstellung und Inferenzleistung.
Verbesserungen bei Algorithmen und Architekturen
Die Transformer-Architektur ist dafür bekannt, dass sie bereits LLMs unterstützt. Die Einführung dieser Architektur struggle ausschlaggebend für die Weiterentwicklung von LLMs in ihrer heutigen Kind. Ihre Fähigkeit, ganze Sequenzen gleichzeitig statt sequenziell zu verarbeiten, hat die Effizienz und Leistung des Modells dramatisch verbessert.
Dennoch bleibt von der Transformer-Architektur und ihrer Fähigkeit, große Sprachmodelle weiterzuentwickeln, noch viel zu erwarten.
- Kontinuierliche Verfeinerungen des Transformer-Modells, einschließlich besserer Aufmerksamkeitsmechanismen und Optimierungstechniken, werden zu genaueren und schnelleren Modellen führen.
- Die Forschung an neuartigen Architekturen, wie etwa Sparse Transformers und effizienten Aufmerksamkeitsmechanismen, zielt darauf ab, den Rechenleistungsbedarf zu senken und gleichzeitig die Leistung beizubehalten oder zu steigern.
Integration multimodaler Eingaben
Die Zukunft von LLMs liegt in ihrer Fähigkeit, multimodale Eingaben zu verarbeiten und Textual content, Bilder, Audio und möglicherweise andere Datenformen zu integrieren, um reichhaltigere und kontextbezogenere Modelle zu erstellen. Multimodale Modelle wie CLIP und DALL-E von OpenAI haben das Potenzial der Kombination visueller und textlicher Informationen gezeigt und Anwendungen in der Bildgenerierung, Beschriftung und mehr ermöglicht.
Diese Integrationen ermöglichen es LLMs, noch komplexere Aufgaben auszuführen, wie etwa das Erfassen des Kontexts sowohl aus Texten als auch aus visuellen Hinweisen, was sie letztendlich vielseitiger und leistungsfähiger macht.
Zukunft des LLM
Die Fortschritte sind nicht zum Stillstand gekommen und es werden noch mehr kommen, da die LLM-Entwickler planen, noch innovativere Techniken und Systeme in ihre Arbeit zu integrieren. Nicht jede Verbesserung bei LLMs erfordert anspruchsvollere Berechnungen oder ein tieferes konzeptionelles Verständnis. Eine wichtige Verbesserung ist die Entwicklung kleinerer, benutzerfreundlicherer Modelle.
Auch wenn diese Modelle möglicherweise nicht an die Effektivität von „Mammut-LLMs“ wie GPT-4 und LLaMA 3 heranreichen, ist es wichtig, sich daran zu erinnern, dass nicht alle Aufgaben huge und komplexe Berechnungen erfordern. Trotz ihrer Größe können fortschrittliche kleinere Modelle wie Mixtral 8x7B und Mistal 7B immer noch beeindruckende Leistungen erbringen. Hier sind einige Schlüsselbereiche und Technologien, die voraussichtlich die Entwicklung und Verbesserung von LLMs vorantreiben werden:
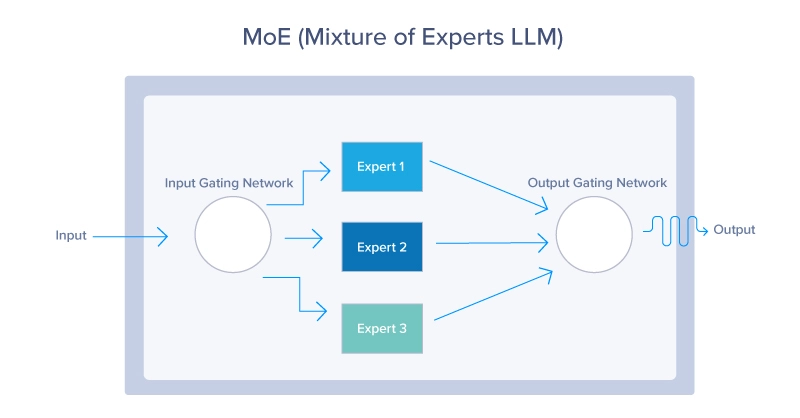
1. Experten-Combine (MoE)
MoE-Modelle Verwenden Sie einen dynamischen Routing-Mechanismus, um für jeden Enter nur eine Teilmenge der Modellparameter zu aktivieren. Dieser Ansatz ermöglicht eine effiziente Skalierung des Modells, indem die relevantesten „Experten“ basierend auf dem Inputkontext aktiviert werden, wie unten dargestellt. MoE-Modelle bieten eine Möglichkeit, LLMs zu skalieren, ohne dass die Rechenkosten proportional steigen. Indem zu einem bestimmten Zeitpunkt nur ein kleiner Teil des gesamten Modells genutzt wird, können diese Modelle weniger Ressourcen verbrauchen und dennoch eine hervorragende Leistung bieten.
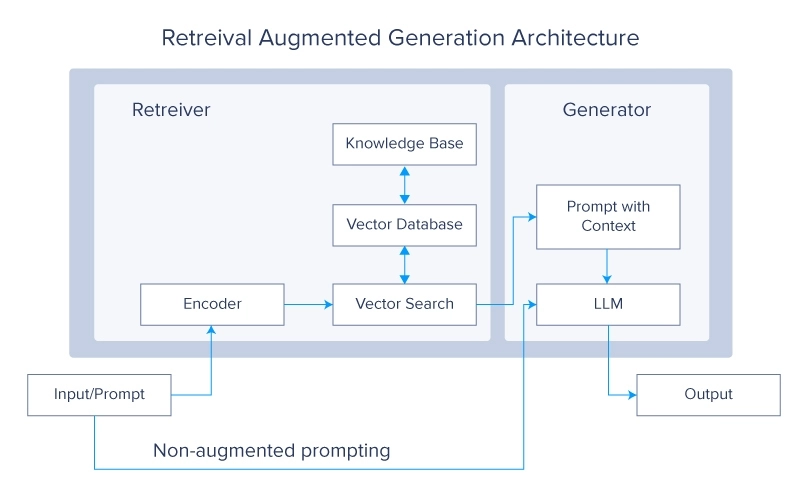
2. Retrieval-Augmented Era (RAG)-Systeme
Retrieval Augmented Era-Systeme sind derzeit ein sehr heißes Thema in der LLM-Group. Das Konzept stellt die Frage, warum Sie die LLMs mit mehr Daten trainieren sollten, wenn Sie sie einfach die gewünschten Daten aus einer externen Quelle abrufen lassen können. Diese Daten werden dann verwendet, um eine endgültige Antwort zu generieren.
RAG-Systeme verbessern LLMs, indem sie während des Generierungsprozesses relevante Informationen aus großen externen Datenbanken abrufen. Diese Integration ermöglicht es dem Modell, auf aktuelles und domänenspezifisches Wissen zuzugreifen und es zu integrieren, wodurch seine Genauigkeit und Relevanz verbessert wird. Durch die Kombination der generativen Fähigkeiten von LLMs mit der Präzision von Abrufsystemen entsteht ein leistungsstarkes Hybridmodell, das qualitativ hochwertige Antworten generieren und gleichzeitig durch externe Datenquellen informiert bleiben kann.
3. Meta-Lernen
Mithilfe von Meta-Studying-Ansätzen können LLMs das Lernen erlernen, sodass sie sich mit minimaler Schulung schnell an neue Aufgaben und Bereiche anpassen können.
Das Konzept des Meta-Lernens basiert auf mehreren Schlüsselkonzepten wie:
- Few-Shot-Studying: Dabei werden LLMs darauf trainiert, neue Aufgaben anhand von nur wenigen Beispielen zu verstehen und auszuführen, wodurch die für effektives Lernen erforderliche Datenmenge erheblich reduziert wird. Dies macht sie äußerst vielseitig und effizient im Umgang mit unterschiedlichen Szenarien.
- Selbstüberwachtes Lernen: LLMs verwenden große Mengen unmarkierter Daten, um Beschriftungen zu generieren und Darstellungen zu lernen. Diese Kind des Lernens ermöglicht es Modellen, ein umfassendes Verständnis der Sprachstruktur und Semantik zu entwickeln, das dann für bestimmte Anwendungen fein abgestimmt wird.
- Reinforcement Studying: Bei diesem Ansatz lernen LLMs, indem sie mit ihrer Umgebung interagieren und Suggestions in Kind von Belohnungen oder Strafen erhalten. Dies hilft den Modellen, ihre Aktionen zu optimieren und Entscheidungsprozesse im Laufe der Zeit zu verbessern.
Abschluss
LLMs sind Wunderwerke der modernen Technologie. Sie funktionieren komplex, sind riesig und ihre Weiterentwicklungen sind bahnbrechend. In diesem Artikel haben wir das Zukunftspotenzial dieser außergewöhnlichen Entwicklungen untersucht. Ausgehend von ihren Anfängen in der Welt der künstlichen Intelligenz haben wir uns auch mit wichtigen Innovationen wie neuronalen Netzwerken und Aufmerksamkeitsmechanismen befasst.
Anschließend haben wir eine Vielzahl von Strategien zur Verbesserung dieser Modelle untersucht, darunter Fortschritte bei der {Hardware}, Verfeinerungen ihrer internen Mechanismen und die Entwicklung neuer Architekturen. Wir hoffen, dass Sie inzwischen ein klareres und umfassenderes Verständnis von LLMs und ihrer vielversprechenden Entwicklung in naher Zukunft gewonnen haben.
Kevin Vu verwaltet Weblog von Exxact Corp und arbeitet mit vielen seiner talentierten Autoren zusammen, die über verschiedene Aspekte des Deep Studying schreiben.