
Einführung
In der künstlichen Intelligenz hat sich das Verständnis der zugrunde liegenden Funktionsweise von Sprachmodellen als wichtig und schwierig erwiesen. Google hat bei der Lösung dieses Issues einen bedeutenden Schritt nach vorne gemacht, indem es Gemma Scope veröffentlicht hat, ein umfassendes Paket von Instruments, das Forschern dabei hilft, einen Blick in die „Black Field“ der KI-Sprachmodelle zu werfen. Dieser Artikel befasst sich mit Gemma Scope, seiner Bedeutung und wie es das Feld der mechanistischen Interpretierbarkeit verändern soll.

Überblick
- Die mechanistische Interpretierbarkeit hilft Forschern zu verstehen, wie KI-Modelle aus Daten lernen und ohne menschliches Eingreifen Entscheidungen treffen.
- Gemma Scope bietet eine Reihe von Instruments, darunter Sparse Autoencoder, die Forschern dabei helfen, die interne Funktionsweise von KI-Sprachmodellen wie Gemma 2 9B und Gemma 2 2B zu analysieren und zu verstehen.
- Gemma Scope zerlegt Modellaktivierungen mithilfe von Sparse Autoencodern in unterschiedliche Merkmale und bietet Einblicke in die Artwork und Weise, wie Sprachmodelle Textual content verarbeiten und generieren.
- Die Implementierung von Gemma Scope umfasst das Laden des Gemma 2-Modells, das Durchlaufen von Texteingaben und die Verwendung von Sparse-Autoencodern zum Analysieren von Aktivierungen, wie in den bereitgestellten Codebeispielen gezeigt.
- Gemma Scope treibt die KI-Forschung voran, indem es Werkzeuge für ein tieferes Verständnis, eine Verbesserung des Modelldesigns, die Behandlung von Sicherheitsbedenken und die Skalierung von Interpretierbarkeitstechniken auf größere Modelle anbietet.
- Zukünftige Forschungen zur mechanistischen Interpretierbarkeit sollten sich auf die Automatisierung der Merkmalsinterpretation, die Gewährleistung der Skalierbarkeit, die Verallgemeinerung von Erkenntnissen über Modelle hinweg und die Berücksichtigung ethischer Überlegungen bei der KI-Entwicklung konzentrieren.
Was ist Gemma Scope?
Gemma Scope ist eine Sammlung von Hunderten öffentlich verfügbarer, offener Sparse Autoencoder (SAEs) für Googles leichte offene Modellfamilie Gemma 2 9B und Gemma 2 2B. Diese Technologien dienen Akademikern als „Mikroskop“ und ermöglichen ihnen, die internen Prozesse von Sprachmodellen zu analysieren und Einblicke in deren Funktionsweise und Entscheidungsfindung zu gewinnen.
Die Bedeutung mechanistischer Interpretierbarkeit
Um die Bedeutung von Gemma Scope zu verstehen, müssen Sie zunächst das Konzept der mechanischen Interpretierbarkeit verstehen. Wenn Forscher KI-Sprachmodelle entwerfen, erstellen sie Systeme, die ohne menschliches Eingreifen aus großen Datenmengen lernen können. Daher sind die inneren Abläufe dieser Modelle häufig unbekannt, selbst ihren Autoren.
Die mechanistische Interpretierbarkeit ist ein Forschungsthema, das sich dem Verständnis dieser grundlegenden Vorgänge widmet. Durch ihr Studium können Forscher tiefere Kenntnisse über die Funktionsweise von Sprachmodellen gewinnen.
- Schaffen Sie widerstandsfähigere Systeme.
- Verbessern Sie die Vorsichtsmaßnahmen gegen Modellhalluzinationen.
- Schützen Sie sich vor den Gefahren autonomer KI-Agenten, wie etwa Unehrlichkeit oder Manipulation.
Wie funktioniert Gemma Scope?
Gemma Scope verwendet Sparse-Autoencoder, um die Aktivierungen eines Modells bei der Verarbeitung von Texteingaben zu interpretieren. Hier ist eine einfache Erklärung des Prozesses:
- Textual content Eingabe: Wenn Sie einem Sprachmodell eine Abfrage stellen, konvertiert es Ihren Textual content in eine Reihe von „Aktivierungen“.
- Aktivierungszuordnung: Diese Aktivierungen stellen Wortassoziationen dar, wodurch das Modell Verbindungen herstellen und Antworten liefern kann.
- Funktionserkennung: Während das Modell Textual content verarbeitet, stellen Aktivierungen auf verschiedenen Ebenen des neuronalen Netzwerks zunehmend komplexere Konzepte dar, die als „Options“ bezeichnet werden.
- Sparse-Autoencoder-Analyse: Die spärlichen Autoencoder von Gemma Scope unterteilen jede Aktivierung in begrenzte Merkmale, die die wahren zugrunde liegenden Eigenschaften des Sprachmodells offenlegen können.
Lesen Sie auch: Wie verwende ich Gemma LLM?
Gemma Scope – Technische Particulars und Implementierung
Lassen Sie uns in die technischen Particulars der Implementierung von Gemma Scope eintauchen und die Schlüsselkonzepte anhand von Codebeispielen veranschaulichen:
Laden des Modells
Zuerst müssen wir das Gemma 2-Modell laden:
from transformers import AutoModelForCausalLM, BitsAndBytesConfig, AutoTokenizer
from huggingface_hub import hf_hub_download, notebook_login
import numpy as np
import torchWir laden Gemma 2 2B, das kleinste Modell, für das Gemma Scope funktioniert. Wir laden das Basismodell und nicht das Konversationsmodell, da dort unsere SAEs gelehrt werden. Die SAEs scheinen auf diese Modelle übertragbar zu sein.
Um die Modellgewichte zu erhalten, müssen Sie sie zuerst mit Huggingface authentifizieren.
notebook_login()
torch.set_grad_enabled(False) # keep away from blowing up mem
mannequin = AutoModelForCausalLM.from_pretrained(
"google/gemma-2-2b",
device_map='auto',
)
tokenizer = AutoTokenizer.from_pretrained("google/gemma-2-2b")Ausführen des Modells

Nachdem wir das Modell geladen haben, versuchen wir es auszuführen! Wir geben ihm die Eingabeaufforderung
„Nur ein Tropfen auf dem heißen Stein. Eine Wetteränderung. Ich habe gebetet, dass du und ich zusammenkommen. Es ist, als würde ich in der Wüste nach Regen betteln.“ und drucken Sie die generierte Ausgabe
from IPython.show import show, Markdown
immediate = "Only a drop within the ocean A change within the climate,I used to be praying that you just and me would possibly find yourself collectively. Its like wiching for the rain as I stand within the desert."
# Use the tokenizer to transform it to tokens. Observe that this implicitly provides a particular "Starting of Sequence" or <bos> token to the beginning
inputs = tokenizer.encode(immediate, return_tensors="pt", add_special_tokens=True).to("cuda")
show(Markdown(f"**Encoded inputs:**n```n{inputs}n```"))
# Cross it in to the mannequin and generate textual content
outputs = mannequin.generate(input_ids=inputs, max_new_tokens=50)
generated_text = tokenizer.decode(outputs(0))
show(Markdown(f"**Generated textual content:**nn{generated_text}"))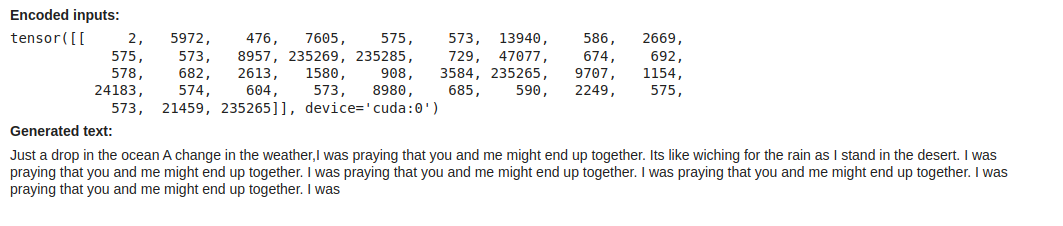
Wir haben additionally Gemma 2 geladen und können daraus Samples erstellen, um sinnvolle Ergebnisse zu erhalten.
Laden wir jetzt eine unserer SAE-Dateien.
GemmaScope hat quick vierhundert SAEs, aber vorerst laden wir lediglich eines in den Reststrom am Ende der Ebene 20.
Laden der Parameter des Modells und Verschieben auf die GPU:
params = np.load(path_to_params)
pt_params = {ok: torch.from_numpy(v).cuda() for ok, v in params.gadgets()}Implementierung des Sparse-Auto-Encoders (SAE):
Aus pädagogischen Gründen definieren wir nun den Vorwärtsdurchgang der SAE.
Gemma Scope ist eine Sammlung von JumpReLU SAEs, ähnlich einem typischen zweischichtigen (eine versteckte Schicht) neuronalen Netzwerk, aber mit einer JumpReLU-Aktivierungsfunktion: ein ReLU mit einem diskontinuierlichen Sprung.
import torch.nn as nn
class JumpReLUSAE(nn.Module):
def __init__(self, d_model, d_sae):
# Observe that we initialise these to zeros as a result of we're loading in pre-trained weights.
# If you wish to prepare your individual SAEs then we advocate utilizing blah
tremendous().__init__()
self.W_enc = nn.Parameter(torch.zeros(d_model, d_sae))
self.W_dec = nn.Parameter(torch.zeros(d_sae, d_model))
self.threshold = nn.Parameter(torch.zeros(d_sae))
self.b_enc = nn.Parameter(torch.zeros(d_sae))
self.b_dec = nn.Parameter(torch.zeros(d_model))
def encode(self, input_acts):
pre_acts = input_acts @ self.W_enc + self.b_enc
masks = (pre_acts > self.threshold)
acts = masks * torch.nn.practical.relu(pre_acts)
return acts
def decode(self, acts):
return acts @ self.W_dec + self.b_dec
def ahead(self, acts):
acts = self.encode(acts)
recon = self.decode(acts)
return recon
sae = JumpReLUSAE(params('W_enc').form(0), params('W_enc').form(1))
sae.load_state_dict(pt_params)Lassen Sie uns zunächst einige Modellaktivierungen auf der SAE-Zielsite ausführen. Wir beginnen damit, zu demonstrieren, wie dies „manuell“ mithilfe von Pytorch-Hooks durchgeführt wird. Es ist zu beachten, dass dies keine besonders gute Vorgehensweise ist und es wahrscheinlich praktischer ist, eine Bibliothek wie TransformerLens zu verwenden, um das Einfügen des SAE in den Vorwärtsdurchlauf eines Modells zu handhaben. Es kann jedoch zur Veranschaulichung hilfreich sein, zu sehen, wie es gemacht wird.
Wir können Aktivierungen an einem Ort sammeln, indem wir einen Hook registrieren. Um dies lokal zu halten, können wir es in eine Funktion einbinden, die einen Hook registriert, das Modell ausführt, während die Zwischenaktivierung aufgezeichnet wird, und dann den Hook entfernt.
def gather_residual_activations(mannequin, target_layer, inputs):
target_act = None
def gather_target_act_hook(mod, inputs, outputs):
nonlocal target_act # ensure we are able to modify the target_act from the outer scope
target_act = outputs(0)
return outputs
deal with = mannequin.mannequin.layers(target_layer).register_forward_hook(gather_target_act_hook)
_ = mannequin.ahead(inputs)
deal with.take away()
return target_act
target_act = gather_residual_activations(mannequin, 20, inputs)
sae.cuda()
sae_acts = sae.encode(target_act.to(torch.float32))
recon = sae.decode(sae_acts)Lassen Sie uns noch einmal überprüfen, ob das Modell sinnvoll aussieht, indem wir prüfen, ob wir einen beträchtlichen Teil der Varianz erklären:
1 - torch.imply((recon(:, 1:) - target_act(:, 1:).to(torch.float32)) **2) / (target_act(:, 1:).to(torch.float32).var())
Das scheint wahrscheinlich in Ordnung zu sein. Dieser SAE hat angeblich einen L0 von ungefähr 70, additionally überprüfen wir das auch.
(sae_acts > 1).sum(-1)
Es gibt einen Haken: Unsere SAEs werden nicht auf dem BOS-Token trainiert, da wir festgestellt haben, dass es dazu neigt, ein großer Ausreißer zu sein und das Coaching fehlschlagen zu lassen. Wenn wir sie additionally auffordern, etwas zu tun, neigen sie dazu, Kauderwelsch zu sagen, und wir müssen aufpassen, dass das nicht aus Versehen passiert! Wie oben gezeigt, ist das BOS-Token in Bezug auf L0 ein großer Ausreißer!
Schauen wir uns die aktivierendsten Aspekte in diesem Eingabetext an jeder Token-Place an.
values, inds = sae_acts.max(-1)
inds
Wir stellen additionally fest, dass eines der Beispiele für die maximale Aktivierung zu diesem Thema bei Begriffen ausgelöst wird, die mit Zeitreisen in Verbindung stehen!
Lassen Sie uns die Funktionen mithilfe des Neuropedia-Dashboards interaktiver visualisieren.
from IPython.show import IFrame
html_template = "https://neuronpedia.org/{}/{}/{}?embed=true&embedexplanation=true&embedplots=true&embedtest=true&top=300"
def get_dashboard_html(sae_release = "gemma-2-2b", sae_id="20-gemmascope-res-16k", feature_idx=0):
return html_template.format(sae_release, sae_id, feature_idx)
html = get_dashboard_html(sae_release = "gemma-2-2b", sae_id="20-gemmascope-res-16k", feature_idx=10004)
IFrame(html, width=1200, top=600)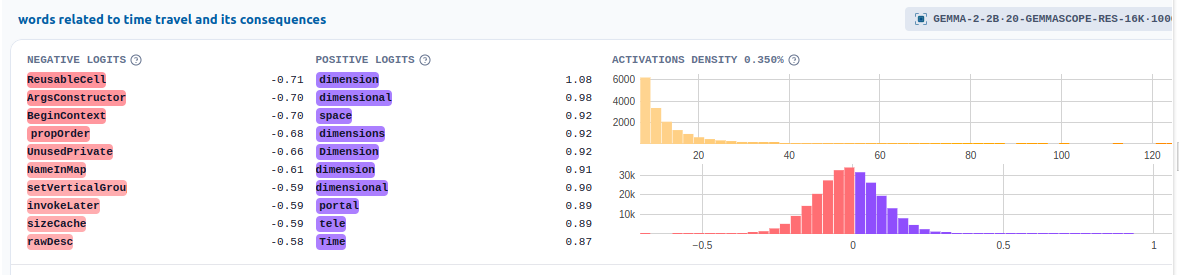
Lesen Sie auch: Google Gemma, das Open-Supply-LLM-Kraftpaket
Ein reales Fallbeispiel
Erwägen Sie die Untersuchung und Bewertung neuerer Artikel, um den praktischen Nutzen von Gemma Scope zu demonstrieren. Dieses Beispiel zeigt Gemma 2 grundlegende Methoden zum Umgang mit unterschiedlichen Nachrichteninhalten.
Einrichtung und Implementierung
Zuerst bereiten wir unsere Umgebung vor, indem wir die erforderlichen Bibliotheken importieren und das Gemma 2 2B-Modell und seinen Tokenizer laden.
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
from huggingface_hub import hf_hub_download
import numpy as np
# Load Gemma 2 2B mannequin and tokenizer
mannequin = AutoModelForCausalLM.from_pretrained("google/gemma-2-2b", device_map='auto')
tokenizer = AutoTokenizer.from_pretrained("google/gemma-2-2b")Als Nächstes implementieren wir den JumpReLU Sparse Autoencoder (SAE) und laden vortrainierte Parameter:
# Outline JumpReLU SAE
class JumpReLUSAE(torch.nn.Module):
def __init__(self, d_model, d_sae):
tremendous().__init__()
self.W_enc = torch.nn.Parameter(torch.zeros(d_model, d_sae))
self.W_dec = torch.nn.Parameter(torch.zeros(d_sae, d_model))
self.threshold = torch.nn.Parameter(torch.zeros(d_sae))
self.b_enc = torch.nn.Parameter(torch.zeros(d_sae))
self.b_dec = torch.nn.Parameter(torch.zeros(d_model))
def encode(self, input_acts):
pre_acts = input_acts @ self.W_enc + self.b_enc
masks = (pre_acts > self.threshold)
acts = masks * torch.nn.practical.relu(pre_acts)
return acts
def decode(self, acts):
return acts @ self.W_dec + self.b_dec
# Load pre-trained SAE parameters
path_to_params = hf_hub_download(
repo_id="google/gemma-scope-2b-pt-res",
filename="layer_20/width_16k/average_l0_71/params.npz",
)
params = np.load(path_to_params)
pt_params = {ok: torch.from_numpy(v).cuda() for ok, v in params.gadgets()}
# Initialize and cargo SAE
sae = JumpReLUSAE(params('W_enc').form(0), params('W_enc').form(1))
sae.load_state_dict(pt_params)
sae.cuda()
# Perform to collect activations
def gather_residual_activations(mannequin, target_layer, inputs):
target_act = None
def gather_target_act_hook(mod, inputs, outputs):
nonlocal target_act
target_act = outputs(0)
deal with = mannequin.mannequin.layers(target_layer).register_forward_hook(gather_target_act_hook)
_ = mannequin(inputs)
deal with.take away()
return target_actAnalysefunktion
Wir erstellen eine Funktion zur Analyse von Überschriften mit Gemma Scope:
# Analyze headline with Gemma Scope
def analyze_headline(headline, top_k=5):
inputs = tokenizer.encode(headline, return_tensors="pt", add_special_tokens=True).to("cuda")
# Collect activations
target_act = gather_residual_activations(mannequin, 20, inputs)
# Apply SAE
sae_acts = sae.encode(target_act.to(torch.float32))
# Get prime activated options
values, indices = torch.topk(sae_acts.sum(dim=1), ok=top_k)
return indices(0).tolist()Beispielüberschriften
Für unsere Analyse verwenden wir eine Reihe unterschiedlicher Schlagzeilen:
# Pattern information headlines
headlines = (
"World temperatures attain document excessive in 2024",
"Tech large unveils revolutionary quantum pc",
"Historic peace treaty signed in Center East",
"Breakthrough in renewable vitality storage introduced",
"Main cybersecurity assault impacts thousands and thousands worldwide"
)Characteristic-Kategorisierung
Um unsere Analyse verständlicher zu machen, kategorisieren wir die aktivierten Funktionen in allgemeine Themenbereiche:
# Predefined function classes (for demonstration functions)
feature_categories = {
1000: "Local weather and Setting",
2000: "Expertise and Innovation",
3000: "World Politics",
4000: "Vitality and Sustainability",
5000: "Cybersecurity and Digital Threats"
}
def categorize_feature(feature_id):
category_id = (feature_id // 1000) * 1000
return feature_categories.get(category_id, "Uncategorized")Ergebnisse und Interpretation
Lassen Sie uns nun jede Überschrift analysieren und die Ergebnisse interpretieren:
# Analyze headlines
for headline in headlines:
print(f"nHeadline: {headline}")
top_features = analyze_headline(headline)
print("High activated function classes:")
for function in top_features:
class = categorize_feature(function)
print(f"- Characteristic {function}: {class}")
print(f"For detailed function interpretation, go to: https://neuronpedia.org/gemma-2-2b/20-gemmascope-res-16k/{top_features(0)}")
# Generate a abstract report
print("n--- Abstract Report ---")
print("This evaluation demonstrates how Gemma Scope can be utilized to grasp the underlying ideas")
print("that the mannequin prompts when processing various kinds of information headlines.")
print("By analyzing the activated options, we are able to acquire insights into the mannequin's interpretation")
print("of varied information subjects and doubtlessly establish biases or focus areas in its coaching information.")
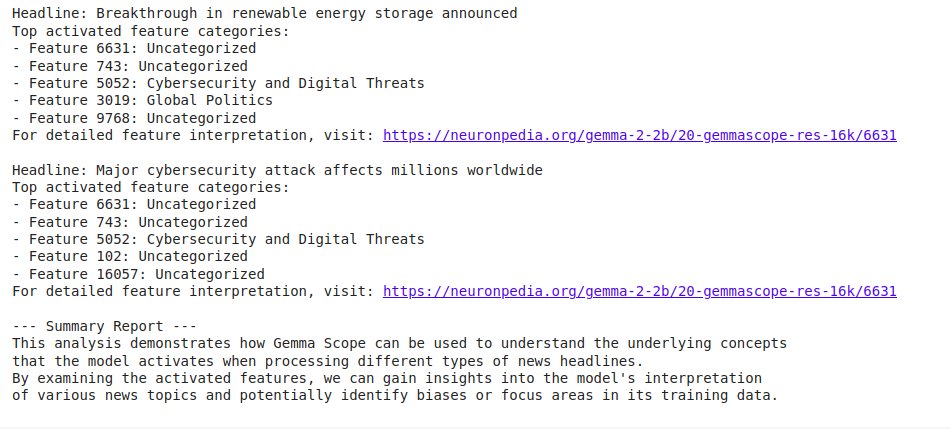
Diese Untersuchung gibt Aufschluss darüber, wie das Gemma 2-Modell verschiedene Nachrichtenthemen interpretiert. So können wir beispielsweise feststellen, dass Schlagzeilen zum Klimawandel häufig Options in der Kategorie „Klima und Umwelt“ aktivieren, während Tech-Information Options in der Kategorie „Technologie und Innovation“ aktivieren.
Lesen Sie auch: Gemma 2: Nachfolger der Google Gemma-Familie großer Sprachmodelle.
Gemma Scope: Auswirkungen auf die KI-Forschung und -Entwicklung
Gemma Scope ist eine wichtige Errungenschaft auf dem Gebiet der mechanistischen Interpretierbarkeit. Seine potenziellen Auswirkungen auf die KI-Forschung und -Entwicklung sind weitreichend:
- Besseres Verständnis des Modellverhaltens: Gemma Scope bietet Forschern einen umfassenden Einblick in die internen Prozesse eines Modells und ermöglicht ihnen so ein besseres Verständnis dafür, wie Sprachmodelle Entscheidungen treffen und reagieren.
- Verbessertes Modelldesign: Forscher, die die internen Vorgänge von Modellen besser verstehen, können effizientere und effektivere Sprachmodelle erstellen, was möglicherweise zu Durchbrüchen bei den Fähigkeiten der künstlichen Intelligenz führt.
- Reaktion auf Sicherheitsbedenken bezüglich KI: Die Fähigkeit von Gemma Scope, die Funktionsweise von Sprachmodellen aufzuzeigen, kann dabei helfen, potenzielle Gefahren für KI-Systeme wie Voreingenommenheit, Halluzinationen oder unerwartete Aktionen zu identifizieren und zu mindern.
- Förderung der Interpretierbarkeitsforschung: Google hofft, den Fortschritt auf diesem wichtigen Gebiet zu beschleunigen, indem es Gemma 2 als beste Modellfamilie für die offene mechanistische Interpretierbarkeitsforschung etabliert.
- Skalierungstechniken für moderne Modelle: Mit Gemma Scope können Forscher Interpretierbarkeitstechniken, die für einfachere Modelle entwickelt wurden, auf größere, kompliziertere Systeme wie Gemma 2 9B anwenden.
- Komplexe Fähigkeiten verstehen: Forscher können jetzt die umfangreiche Toolbox von Gemma Scope nutzen, um fortgeschrittenere Funktionen von Sprachmodellen zu untersuchen, wie etwa das Denken in Gedankenketten.
- Anwendungen in der Praxis: Die Entdeckungen von Gemma Scope können echte Schwierigkeiten bei der Bereitstellung künstlicher Intelligenz lösen, etwa die Minimierung von Halluzinationen und die Verhinderung von Jailbreaks in größeren Modellen.
Herausforderungen und zukünftige Richtungen
Obwohl Gemma Scope einen enormen Fortschritt bei der Interpretierbarkeit von Sprachmodellen darstellt, gibt es noch verschiedene Hindernisse und Themen für künftige Forschung.
- Merkmalsinterpretation: Obwohl Gemma Scope Merkmale erkennen kann, ist für die Bewertung ihrer Bedeutung und Relevanz ein menschliches Eingreifen erforderlich. Die Entwicklung automatisierter Methoden zur Merkmalsinterpretation ist ein wichtiges Thema für zukünftige Forschung.
- Skalierbarkeit: Angesichts der zunehmenden Größe und Komplexität von Sprachmodellen ist es von entscheidender Bedeutung, sicherzustellen, dass Interpretierbarkeitstools wie Gemma Scope mithalten können.
- Verallgemeinernde Erkenntnisse: Die über Gemma Scope gewonnenen Erkenntnisse werden in andere Sprachmodelle und KI-Systeme übertragen, damit sie breiter anwendbar sind.
- Ethische Überlegungen: Da wir immer tiefere Einblicke in KI-Systeme erhalten, wird es zunehmend wichtiger, ethische Bedenken hinsichtlich Datenschutz, Voreingenommenheit und verantwortungsvoller KI-Entwicklung auszuräumen.
Abschluss
Gemma Scope ist ein großer Fortschritt auf dem Gebiet der maschinellen Interpretierbarkeit von Sprachmodellen. Google hat neue Wege für die Untersuchung, Verbesserung und den Schutz dieser zunehmend wichtigen Technologien eröffnet, indem es Akademikern leistungsstarke Instruments zur Untersuchung der Funktionsweise von KI-Systemen bietet.
Häufig gestellte Fragen
Antwort: Gemma Scope ist eine Sammlung offener Sparse Autoencoder (SAEs) für Googles leichtgewichtige offene Modellfamilie Gemma 2 9B und Gemma 2 2B, die es Forschern ermöglicht, die internen Prozesse von Sprachmodellen zu analysieren und Einblicke in ihre Funktionsweise zu gewinnen.
Antwort: Die mechanistische Interpretierbarkeit hilft Forschern, die grundlegende Funktionsweise von KI-Modellen zu verstehen. Sie ermöglicht die Entwicklung widerstandsfähigerer Systeme, verbessert den Schutz der Modelle gegen Halluzinationen und schützt vor Risiken wie Unehrlichkeit oder Manipulation durch autonome KI-Agenten.
Antwort: SAEs sind eine Artwork neuronales Netzwerk, das in Gemma Scope verwendet wird, um Aktivierungen in begrenzte Merkmale zu zerlegen und so die zugrunde liegenden Eigenschaften des Sprachmodells offenzulegen.
Antwort: Ja, die Implementierung umfasst das Laden des Gemma 2-Modells, das Ausführen mit spezifischer Texteingabe und das Analysieren von Aktivierungen mithilfe von Sparse Autoencodern. Der Artikel enthält Beispielcode für detaillierte Schritte.