

Bild vom Autor
Ich bin der festen Überzeugung, dass man ein überzeugendes Portfolio braucht, um im Bereich künstliche Intelligenz eingestellt zu werden. Das heißt, man muss den Personalverantwortlichen zeigen, dass man KI-Modelle und -Anwendungen erstellen kann, die reale Probleme lösen.
In diesem Weblog überprüfen wir 7 KI-Portfolioprojekte, die Ihren Lebenslauf aufwerten werden. Diese Projekte werden mit Tutorials, Quellcode und anderen unterstützenden Materialien geliefert, die Ihnen beim Erstellen geeigneter KI-Anwendungen helfen.
1. Erstellen und implementieren Sie Ihre Machine-Studying-Anwendung in 5 Minuten
Projektlink: Erstellen Sie mit Hugging Face und Gradio in 5 Minuten einen KI-Chatbot
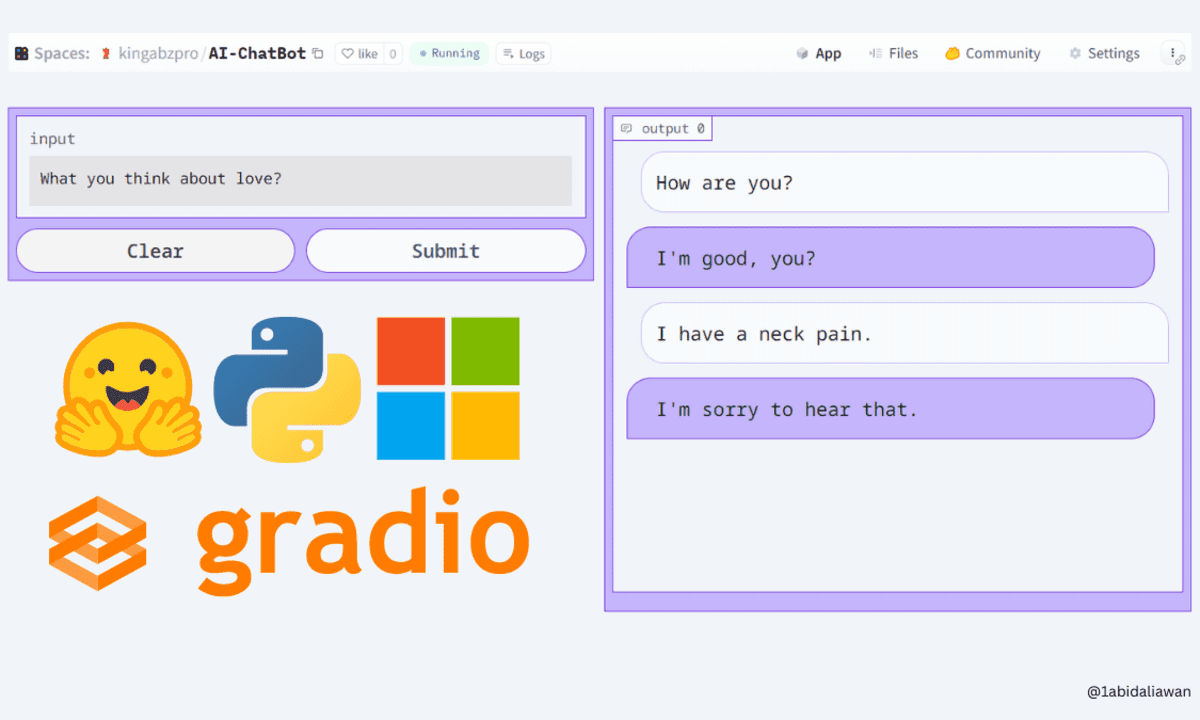
Screenshot aus dem Projekt
In diesem Projekt erstellen Sie eine Chatbot-Anwendung und stellen sie in Hugging Face-Bereichen bereit. Es ist ein anfängerfreundliches KI-Projekt, das nur minimale Kenntnisse von Sprachmodellen und Python erfordert. Zunächst lernen Sie verschiedene Komponenten der Gradio-Python-Bibliothek kennen, um eine Chatbot-Anwendung zu erstellen, und verwenden dann das Hugging Face-Ökosystem, um das Modell zu laden und bereitzustellen.
So einfach ist das.
2. Erstellen Sie KI-Projekte mit DuckDB: SQL Question Engine
Projektlink: DuckDB-Tutorial: Erstellen von KI-Projekten
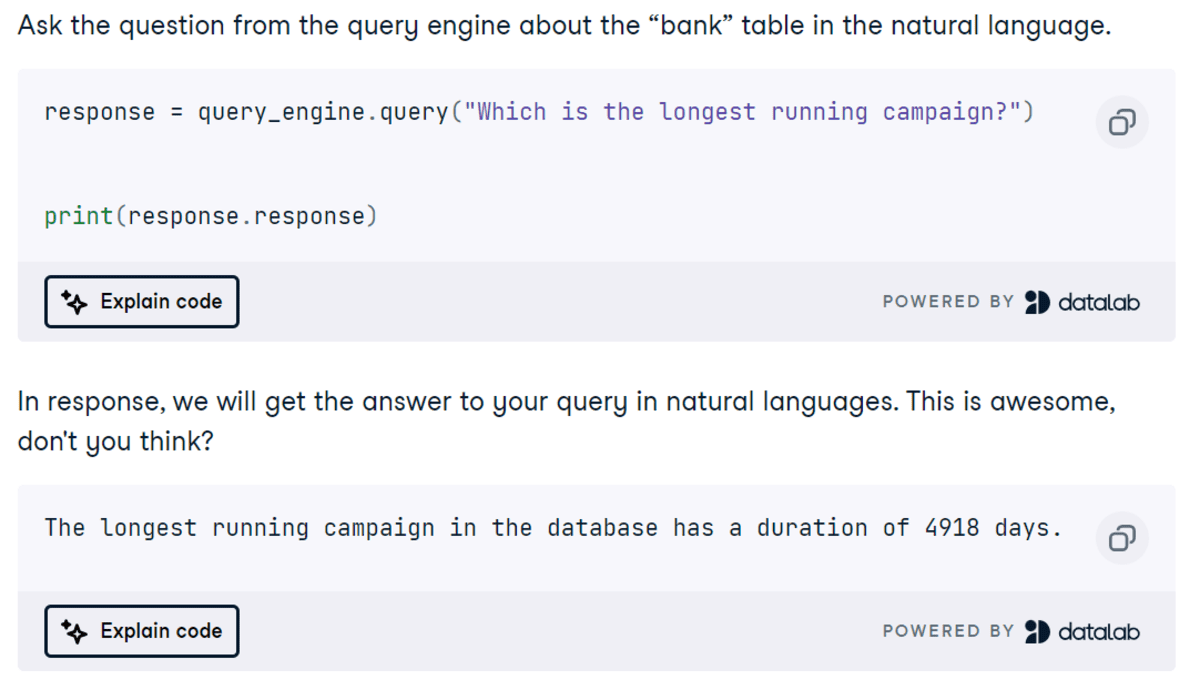
Screenshot aus dem Projekt
In diesem Projekt lernen Sie, DuckDB als Vektordatenbank für eine RAG-Anwendung und auch als SQL-Abfrage-Engine mithilfe des LlamaIndex-Frameworks zu verwenden. Die Abfrage nimmt Eingaben in natürlicher Sprache entgegen, konvertiert sie in SQL und zeigt das Ergebnis in natürlicher Sprache an. Es ist ein einfaches und unkompliziertes Projekt für Anfänger, aber bevor Sie mit dem Erstellen der KI-Anwendung beginnen, müssen Sie einige Grundlagen der DuckDB Python API und des LlamaIndex-Frameworks erlernen.
3. Erstellen eines mehrstufigen KI-Agenten mithilfe der LangChain- und Cohere-API
Projektlink: Cohere Command R+: Ein vollständiges Schritt-für-Schritt-Tutorial
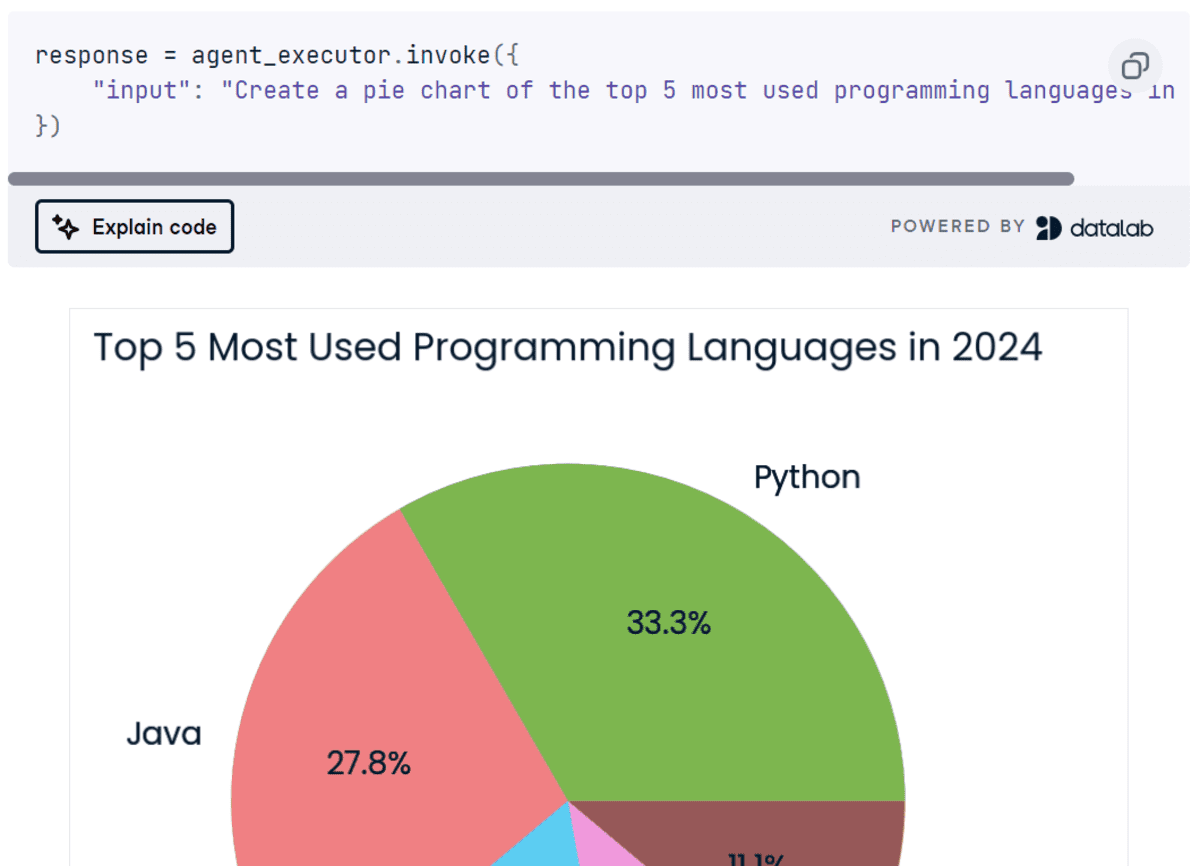
Screenshot aus dem Projekt
Cohere API ist in Bezug auf die Funktionalität für die Entwicklung von KI-Anwendungen besser als OpenAI API. In diesem Projekt werden wir die verschiedenen Funktionen von Cohere API erkunden und lernen, mithilfe des LangChain-Ökosystems und des Command R+-Modells einen mehrstufigen KI-Agenten zu erstellen. Diese KI-Anwendung nimmt die Abfrage des Benutzers entgegen, durchsucht das Web mithilfe der Tavily-API, generiert Python-Code, führt den Code mithilfe von Python REPL aus und gibt dann die vom Benutzer angeforderte Visualisierung zurück. Dies ist ein Projekt auf mittlerem Niveau für Personen mit Grundkenntnissen, die daran interessiert sind, mithilfe des LangChain-Frameworks fortgeschrittene KI-Anwendungen zu erstellen.
4. Feinabstimmung von Llama 3 und lokale Verwendung
Projektlink: Feinabstimmung von Llama 3 und lokale Verwendung: Eine Schritt-für-Schritt-Anleitung | DataCamp
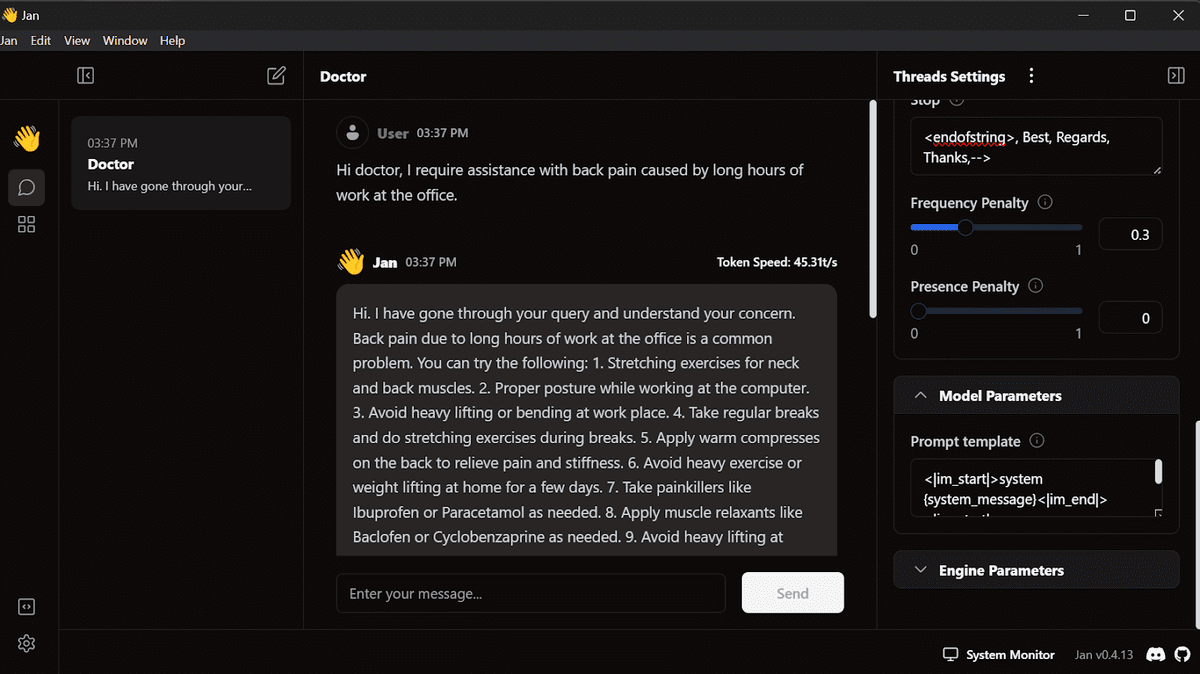
Bild aus dem Projekt
Ein beliebtes Projekt auf DataCamp, das Ihnen hilft, jedes Modell mithilfe kostenloser Ressourcen zu optimieren und das Modell in das Llama.cpp-Format zu konvertieren, sodass es lokal auf Ihrem Laptop computer ohne Internetzugang verwendet werden kann. Sie lernen zunächst, das Llama-3-Modell anhand eines medizinischen Datensatzes zu optimieren, dann den Adapter mit dem Basismodell zusammenzuführen und das vollständige Modell an den Hugging Face Hub zu senden. Anschließend konvertieren Sie die Modelldateien in das Llama.cpp-GGUF-Format, quantisieren das GGUF-Modell und senden die Datei an den Hugging Face Hub. Schließlich verwenden Sie das optimierte Modell lokal mit der Jan-Anwendung.
5. Mehrsprachige automatische Spracherkennung
Modell-Repository: kingabzpro/wav2vec2-large-xls-r-300m-Urdu
Code-Repository: kingabzpro/Urdu-ASR-SOTA
Hyperlink zum Tutorial: Optimieren Sie XLSR-Wav2Vec2 für ressourcenarmes ASR mit 🤗 Transformers
Screenshot von kingabzpro/wav2vec2-large-xls-r-300m-Urdu
Mein beliebtestes Projekt aller Zeiten! Es wird jeden Monat quick eine halbe Million Mal heruntergeladen. Ich habe das Wave2Vec2 Massive-Modell mithilfe der Transformer-Bibliothek anhand eines Urdu-Datensatzes optimiert. Anschließend habe ich die Ergebnisse der generierten Ausgabe durch Integration des Sprachmodells verbessert.
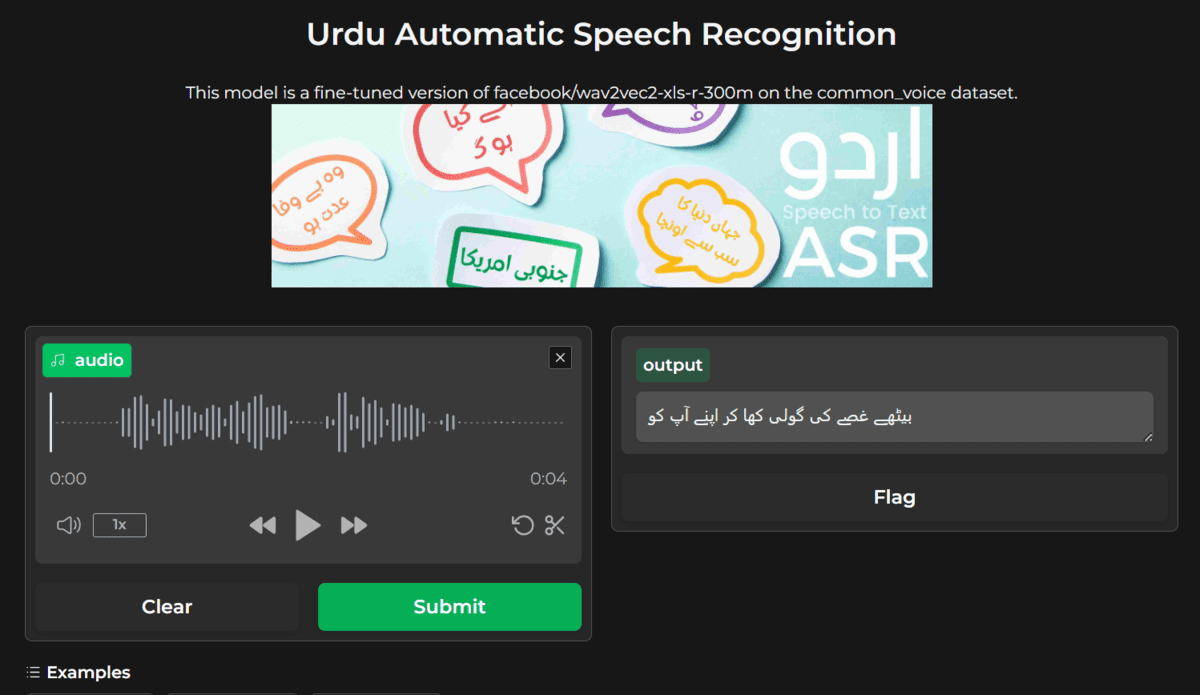
Screenshot von Urdu ASR SOTA – ein umarmender Gesichtsraum von kingabzpro
In diesem Projekt optimieren Sie ein Spracherkennungsmodell in Ihrer bevorzugten Sprache und integrieren es in ein Sprachmodell, um seine Leistung zu verbessern. Danach verwenden Sie Gradio, um eine KI-Anwendung zu erstellen und sie auf dem Hugging Face-Server bereitzustellen. Die Feinabstimmung ist eine anspruchsvolle Aufgabe, die das Erlernen der Grundlagen, das Bereinigen des Audio- und Textdatensatzes und die Optimierung des Modelltrainings erfordert.
6. Erstellen von CI/CD-Workflows für Machine-Studying-Operationen
Projektlink: Ein Einsteigerhandbuch zu CI/CD für maschinelles Lernen | DataCamp
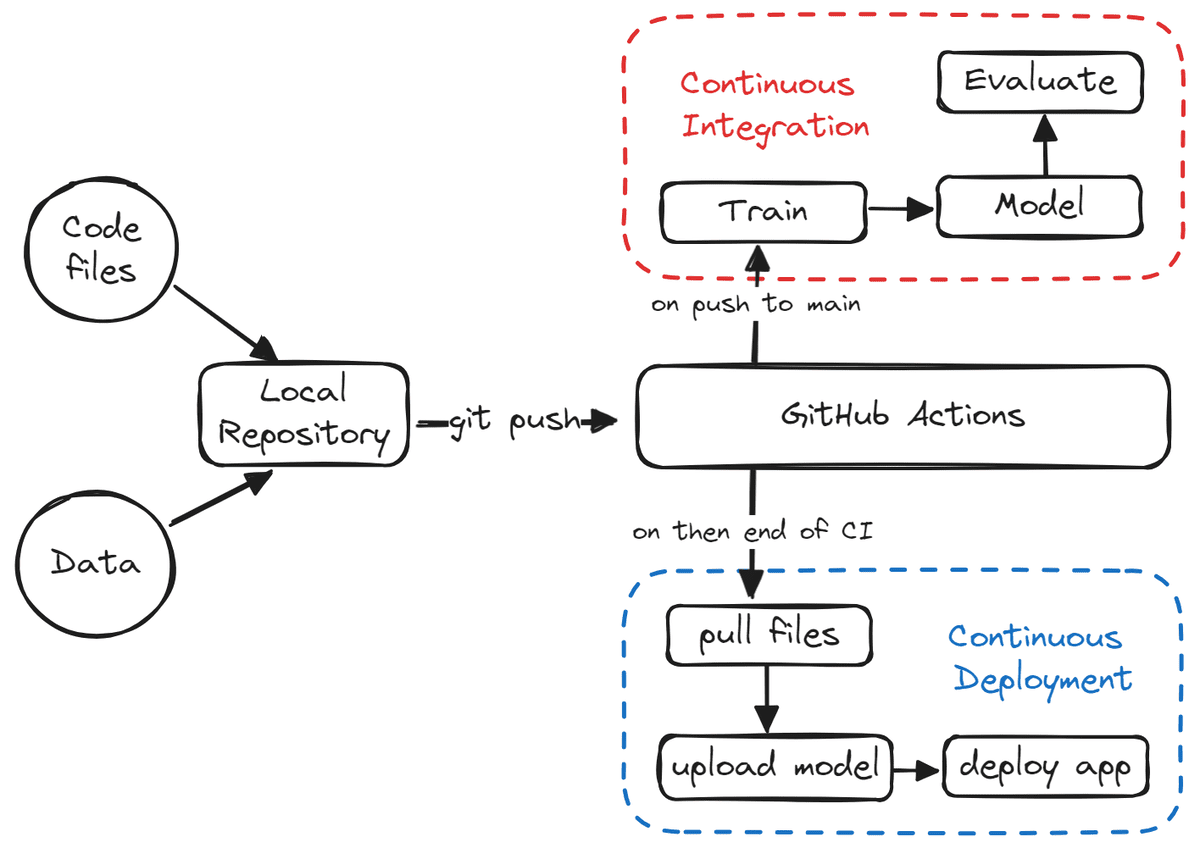
Bild aus dem Projekt
Ein weiteres beliebtes Projekt auf GitHub. Es beinhaltet den Aufbau einer CI/CD-Pipeline oder von maschinellen Lernvorgängen. In diesem Projekt lernen Sie Vorlagen für maschinelle Lernprojekte kennen und erfahren, wie Sie die Prozesse des Modelltrainings, der Modellbewertung und der Modellbereitstellung automatisieren. Sie lernen MakeFile, GitHub Actions, Gradio, Hugging Face, GitHub Secrets and techniques, CML-Aktionen und verschiedene Git-Vorgänge kennen.
Letztendlich werden Sie Finish-to-Finish-Pipelines für maschinelles Lernen erstellen, die ausgeführt werden, wenn neue Daten übertragen oder Code aktualisiert wird. Dabei werden neue Daten verwendet, um das Modell neu zu trainieren, Modellauswertungen zu generieren, das trainierte Modell abzurufen und es auf dem Server bereitzustellen. Es handelt sich um ein vollautomatisches System, das bei jedem Schritt Protokolle generiert.
7. Feinabstimmung von Secure Diffusion XL mit DreamBooth und LoRA
Projektlink: Feinabstimmung von Secure Diffusion XL mit DreamBooth und LoRA | DataCamp

Bild aus dem Projekt
Wir haben gelernt, wie man große Sprachmodelle feinabstimmt, aber jetzt werden wir ein Generative-AI-Modell mithilfe persönlicher Fotos feinabstimmen. Für die Feinabstimmung von Secure Diffusion XL sind nur wenige Bilder erforderlich, und daher können Sie optimale Ergebnisse erzielen, wie oben gezeigt.
In diesem Projekt lernen Sie zunächst Secure Diffusion XL kennen und optimieren es dann anhand eines neuen Datensatzes mithilfe von Hugging Face AutoTrain Advance, DreamBooth und LoRA. Sie können entweder Kaggle für kostenlose GPUs oder Google Colab verwenden. Es wird eine Anleitung mitgeliefert, die Sie bei jedem Schritt unterstützt.
Abschluss
Alle in diesem Weblog erwähnten Projekte wurden von mir erstellt. Ich habe darauf geachtet, eine Anleitung, Quellcode und andere unterstützende Materialien beizufügen.
Durch die Arbeit an diesen Projekten sammeln Sie wertvolle Erfahrungen und können ein überzeugendes Portfolio aufbauen, das Ihre Chancen auf Ihren Traumjob erhöht. Ich empfehle jedem, seine Projekte auf GitHub und Medium zu dokumentieren und sie dann in den sozialen Medien zu teilen, um mehr Aufmerksamkeit zu erregen. Arbeiten Sie weiter und bauen Sie weiter auf; diese Erfahrungen können auch als echte Erfahrung in Ihren Lebenslauf aufgenommen werden.
Abid Ali Awan (@1abidaliawan) ist ein zertifizierter Datenwissenschaftler, der gerne Modelle für maschinelles Lernen erstellt. Derzeit konzentriert er sich auf die Erstellung von Inhalten und das Schreiben technischer Blogs zu Technologien für maschinelles Lernen und Datenwissenschaft. Abid hat einen Grasp-Abschluss in Technologiemanagement und einen Bachelor-Abschluss in Telekommunikationstechnik. Seine Imaginative and prescient ist es, mithilfe eines Graph-Neural-Networks ein KI-Produkt für Studenten zu entwickeln, die mit psychischen Erkrankungen zu kämpfen haben.