
Einführung
Wir hören immer wieder von „diversen“ Datensätzen in maschinelles Lernen? Nun, es stellt sich heraus, dass es damit ein Drawback gab. Aber keine Sorge – ein brillantes Forscherteam hat gerade ein bahnbrechendes Paper veröffentlicht, das die gesamte ML-Neighborhood in Aufruhr versetzt. In dem Paper, das kürzlich mit dem ICML 2024 Greatest Paper Award ausgezeichnet wurde, befassen sich die Forscher Dora Zhao, Jerone TA Andrews, Orestis Papakyriakopoulos und Alice Xiang mit einem kritischen Drawback des maschinellen Lernens (ML) – den oft vagen und unbegründeten Behauptungen über „Diversität“ in Datensätzen. Ihre Arbeit mit dem Titel „Measure Dataset Range, Do not Simply Declare It“ schlägt einen strukturierten Ansatz zur Konzeptualisierung, Operationalisierung und Bewertung der Diversität in ML-Datensätzen unter Verwendung von Prinzipien der Messtheorie vor.

Ich weiß, was Sie jetzt denken. „Noch ein Artikel über Datensatzvielfalt? Haben wir das nicht schon einmal gehört?“ Aber glauben Sie mir, dieser hier ist anders. Diese Forscher haben sich genau angesehen, wie wir Begriffe wie „Vielfalt“, „Qualität“ und „Voreingenommenheit“ verwenden, ohne sie wirklich zu belegen. Wir gehen mit diesen Konzepten leichtfertig um und sie stellen uns darauf aufmerksam.
Aber das Beste daran ist: Sie weisen nicht nur auf das Drawback hin. Sie haben einen soliden Rahmen entwickelt, der uns dabei hilft, Behauptungen zur Diversität zu messen und zu validieren. Sie geben uns einen Werkzeugkasten in die Hand, um diese chaotische Scenario zu beheben.
Additionally schnallen Sie sich an, denn ich werde Sie gleich auf eine Reise durch diese bahnbrechende Forschung mitnehmen. Wir werden untersuchen, wie wir über die bloße Behauptung von Diversität hinausgehen und sie messen können. Vertrauen Sie mir, am Ende werden Sie einen ML-Datensatz nie wieder mit denselben Augen betrachten!
Das Drawback mit Diversitätsansprüchen
Die Autoren heben ein weitverbreitetes Drawback in der Maschinelles Lernen Neighborhood: Kuratoren von Datensätzen verwenden häufig Begriffe wie „Vielfalt“, „Voreingenommenheit“ und „Qualität“, ohne klare Definitionen oder Validierungsmethoden zu verwenden. Dieser Mangel an Präzision erschwert die Reproduzierbarkeit und verstärkt den Irrglauben, dass Datensätze neutrale Entitäten sind und keine wertbeladenen Artefakte, die von den Perspektiven und gesellschaftlichen Kontexten ihrer Ersteller geprägt sind.
Ein Rahmen zur Messung der Diversität
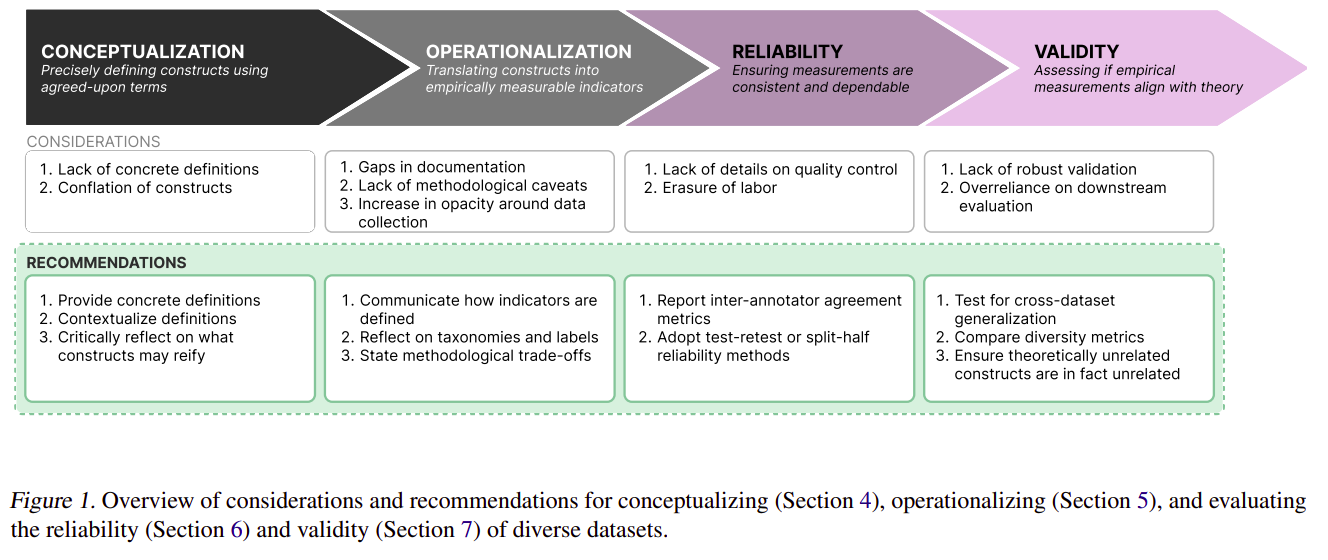
Ausgehend von den Sozialwissenschaften, insbesondere der Messtheorie, präsentieren die Forscher einen Rahmen für die Umwandlung abstrakter Diversitätsbegriffe in messbare Konstrukte. Dieser Ansatz umfasst drei wichtige Schritte:
- Konzeptualisierung: Klare Definition, was „Diversität“ im Kontext eines bestimmten Datensatzes bedeutet.
- Operationalisierung: Entwicklung konkreter Methoden zur Messung der definierten Diversitätsaspekte.
- Auswertung: Beurteilung der Zuverlässigkeit und Gültigkeit der Diversitätsmessungen.
Zusammenfassend plädiert dieses Positionspapier für klarere Definitionen und stärkere Validierungsmethoden bei der Erstellung vielfältiger Datensätze und schlägt die Messtheorie als Gerüst für diesen Prozess vor.
Wichtige Erkenntnisse und Empfehlungen
Durch eine Analyse von 135 Bild- und Textdatensätzen gewannen die Autoren mehrere wichtige Erkenntnisse:
- Fehlen klarer Definitionen: Nur 52,9 % der Datensätze begründeten ausdrücklich die Notwendigkeit vielfältiger Daten. Das Papier betont, wie wichtig es ist, konkrete, kontextualisierte Definitionen von Vielfalt bereitzustellen.
- Dokumentationslücken: Viele Artikel, die Datensätze vorstellen, enthalten keine detaillierten Informationen zu Sammlungsstrategien oder methodischen Entscheidungen. Die Autoren plädieren für mehr Transparenz bei der Datensatzdokumentation.
- Bedenken hinsichtlich der Zuverlässigkeit: Nur 56,3 % der Datensätze deckten Qualitätskontrollprozesse ab. Das Dokument empfiehlt, die Übereinstimmung zwischen Annotatoren und die Check-Retest-Reliabilität zu verwenden, um die Konsistenz der Datensätze zu beurteilen.
- Gültigkeitsprobleme: Behauptungen zur Diversität mangelt es oft an einer soliden Validierung. Die Autoren schlagen vor, Techniken der Konstruktvalidität wie konvergente und diskriminante Validität zu verwenden, um zu bewerten, ob Datensätze die beabsichtigte Diversität der Konstrukte wirklich erfassen.
Praktische Anwendung: Der Section Something-Datensatz
Zur Veranschaulichung ihres Rahmens enthält das Papier eine Fallstudie des Section Something-Datensatzes (SA-1B). Die Autoren loben zwar bestimmte Aspekte des Diversitätsansatzes von SA-1B, identifizieren aber auch Bereiche, in denen Verbesserungen möglich sind, wie etwa die Verbesserung der Transparenz beim Datenerfassungsprozess und die Bereitstellung einer stärkeren Validierung für Behauptungen zur geografischen Diversität.
Weitergehende Auswirkungen
Diese Forschung hat erhebliche Auswirkungen auf die ML-Neighborhood:
- Herausforderung des „Skalendenkens“: Das Papier wendet sich gegen die Vorstellung, dass Diversität automatisch mit größeren Datensätzen einhergeht, und betont die Notwendigkeit einer gezielten Kuratierung.
- Dokumentationsaufwand: Die Autoren plädieren zwar für mehr Transparenz, erkennen jedoch den erforderlichen erheblichen Aufwand an und fordern systematische Änderungen bei der Bewertung der Datenarbeit in der ML-Forschung.
- Zeitliche Überlegungen: Das Dokument unterstreicht die Notwendigkeit, zu berücksichtigen, wie sich Diversitätskonstrukte im Laufe der Zeit ändern können und dies Auswirkungen auf die Relevanz und Interpretation von Datensätzen hat.
Sie können den Artikel hier lesen: Place: Datensatz messenOkay, Diversität, nicht nur behaupten
Abschluss
Dieses ICML 2024 Greatest Paper bietet einen Weg zu strengerer, transparenterer und reproduzierbarerer Forschung, indem es Messtheorieprinzipien auf die Erstellung von ML-Datensätzen anwendet. Da sich das Feld mit Fragen der Voreingenommenheit und Repräsentation auseinandersetzt, bietet der hier vorgestellte Rahmen wertvolle Instrumente, um sicherzustellen, dass Behauptungen über Vielfalt in ML-Datensätze sind nicht nur Rhetorik, sondern messbare und sinnvolle Beiträge zur Entwicklung fairer und robuster KI-Systeme.
Diese bahnbrechende Arbeit ist ein Aufruf an die ML-Neighborhood, die Requirements der Datensatzkuratierung und -dokumentation zu erhöhen, was letztendlich zu zuverlässigeren und gerechteren Modellen des maschinellen Lernens führt.
Ich muss zugeben, als ich die Empfehlungen der Autoren zum Dokumentieren und Validieren von Datensätzen zum ersten Mal sah, dachte ein Teil von mir: „Ugh, das klingt nach viel Arbeit.“ Und ja, das ist es auch. Aber wissen Sie was? Es ist Arbeit, die getan werden muss. Wir können nicht immer weiter KI-Systeme auf wackeligen Fundamenten aufbauen und einfach auf das Beste hoffen. Aber was mich begeistert hat: In diesem Artikel geht es nicht nur darum, unsere Datensätze zu verbessern. Es geht darum, unser gesamtes Feld strenger, transparenter und vertrauenswürdiger zu machen. In einer Welt, in der KI immer einflussreicher wird, ist das enorm.
Additionally, was denken Sie? Sind Sie bereit, die Ärmel hochzukrempeln und mit der Messung der Datensatzvielfalt zu beginnen? Lassen Sie uns in den Kommentaren chatten – ich würde gerne Ihre Meinung zu dieser bahnbrechenden Forschung hören!
Sie können andere ICML 2024 Greatest Paper lesenist hier: High-Artikel der ICML 2024: Neuigkeiten im maschinellen Lernen.
Häufig gestellte Fragen
Antwort: Die Messung der Datensatzvielfalt ist entscheidend, da sie sicherstellt, dass die zum Trainieren von Modellen für maschinelles Lernen verwendeten Datensätze verschiedene demografische Gruppen und Szenarien repräsentieren. Dies trägt dazu bei, Verzerrungen zu reduzieren, die Generalisierbarkeit von Modellen zu verbessern und Equity und Gerechtigkeit in KI-Systemen zu fördern.
Antwort: Vielfältige Datensätze können die Leistung von ML-Modellen verbessern, indem sie einer breiten Palette von Szenarien ausgesetzt werden und die Überanpassung an eine bestimmte Gruppe oder ein bestimmtes Szenario reduziert wird. Dies führt zu robusteren und genaueren Modellen, die bei unterschiedlichen Populationen und Bedingungen gute Ergebnisse erzielen.
Antworten: Zu den üblichen Herausforderungen gehören die Definition dessen, was Diversität ausmacht, die Operationalisierung dieser Definitionen in messbare Konstrukte und die Validierung der Diversitätsansprüche. Darüber hinaus kann die Gewährleistung von Transparenz und Reproduzierbarkeit bei der Dokumentation der Diversität von Datensätzen arbeitsintensiv und komplex sein.
Antwort: Zu den praktischen Schritten gehören:
a. Klare Definition der projektspezifischen Diversitätsziele und -kriterien.
b. Sammeln von Daten aus verschiedenen Quellen, um unterschiedliche demografische Merkmale und Szenarien abzudecken.
c. Verwenden standardisierter Methoden zur Messung und Dokumentation der Diversität in Datensätzen.
d. Bewerten und aktualisieren Sie Datensätze kontinuierlich, um die Vielfalt im Laufe der Zeit aufrechtzuerhalten.
e. Implementierung robuster Validierungstechniken, um sicherzustellen, dass die Datensätze tatsächlich die beabsichtigte Vielfalt widerspiegeln.