

Bild von Pexels
Beim maschinellen Lernen (ML) geht es nicht nur um Vorhersagen. Es gibt auch andere unbeaufsichtigte Prozesse, unter denen das Clustering hervorsticht. Dieser Artikel stellt Clustering und Clusteranalyse vor und hebt das Potenzial der Clusteranalyse für die Segmentierung, Analyse und Gewinnung von Erkenntnissen aus Gruppen ähnlicher Daten hervor.
Was ist Clustering?
Vereinfacht ausgedrückt ist Clustering ein Synonym für Gruppieren ähnlicher DatenelementeDies könnte beispielsweise mit dem Anordnen und Platzieren ähnlicher Obst- und Gemüsesorten in einem Lebensmittelgeschäft nahe beieinander vergleichbar sein.
Lassen Sie uns dieses Konzept näher ausführen: Clustering ist eine Type von unüberwachtes Lernen Aufgabe: eine breite Familie von maschinellen Lernansätzen, bei denen davon ausgegangen wird, dass Daten a priori nicht gekennzeichnet oder kategorisiert sind, und das Ziel darin besteht, ihnen zugrunde liegende Muster oder Erkenntnisse zu entdecken. Insbesondere besteht der Zweck des Clusterings darin, Gruppen von Datenbeobachtungen zu entdecken mit ähnlich Merkmale oder Eigenschaften.
Hier ist das Clustering im Spektrum der ML-Techniken positioniert:

Um das Konzept des Clusterings besser zu verstehen, denken Sie daran, in einem Supermarkt Kundensegmente mit ähnlichem Einkaufsverhalten zu finden oder eine große Menge an Produkten in einem E-Commerce-Portal in Kategorien oder ähnliche Artikel zu gruppieren. Dies sind gängige Beispiele für reale Szenarien mit Clustering-Prozessen.
Gängige Clustering-Techniken
Es gibt verschiedene Methoden zum Clustering von Daten. Drei der beliebtesten Methodenfamilien sind:
- Iteratives Clustering: Diese Algorithmen ordnen Datenpunkte iterativ ihren jeweiligen Clustern zu (und weisen sie manchmal neu zu), bis sie zu einer „intestine genug“-Lösung konvergieren. Der beliebteste iterative Clusteralgorithmus ist k-Mittel, Dabei werden die Datenpunkte iterativ zu Clustern zugewiesen, die durch repräsentative Punkte (Cluster-Schwerpunkte) definiert sind, und diese Schwerpunkte werden schrittweise aktualisiert, bis Konvergenz erreicht ist.
- Hierarchisches Clustering: Wie der Title schon sagt, erstellen diese Algorithmen eine hierarchische, baumbasierte Struktur. Dabei verwenden sie einen High-down-Ansatz (Aufteilen der Datenpunkte, bis die gewünschte Anzahl an Untergruppen vorliegt) oder einen Backside-up-Ansatz (schrittweises Zusammenführen ähnlicher Datenpunkte wie Blasen zu immer größeren Gruppen). AHC (Agglomeratives hierarchisches Clustering) ist ein gängiges Beispiel für einen hierarchischen Clusteralgorithmus vom Backside-Up-Typ.
- Dichtebasiertes Clustering: Diese Methoden identifizieren Bereiche mit hoher Datenpunktdichte, um Cluster zu bilden. DBSCAN (Dichtebasiertes räumliches Clustering von Anwendungen mit Rauschen) ist ein beliebter Algorithmus in dieser Kategorie.
Sind Clustern Und Clusteranalyse das gleiche?
Die brennende Frage an dieser Stelle könnte sein: Beziehen sich Clustering und Clusteranalyse auf dasselbe Konzept?
Zweifellos sind beide sehr eng verwandt, aber sie sind nicht dasselbe und es gibt subtile Unterschiede zwischen ihnen.
- Beim Clustering werden ähnliche Daten so gruppiert, dass sich zwei Objekte in derselben Gruppe oder demselben Cluster ähnlicher sind als zwei Objekte in unterschiedlichen Gruppen.
- Mittlerweile ist Clusteranalyse ein weiter gefasster Begriff, der nicht nur den Prozess der Gruppierung (Clusterbildung) von Daten umfasst, sondern auch die Analyse, AuswertungUnd Interpretation der erhaltenen Cluster in einem bestimmten Domänenkontext.
Das folgende Diagramm veranschaulicht den Unterschied und die Beziehung zwischen diesen beiden häufig verwechselten Begriffen.
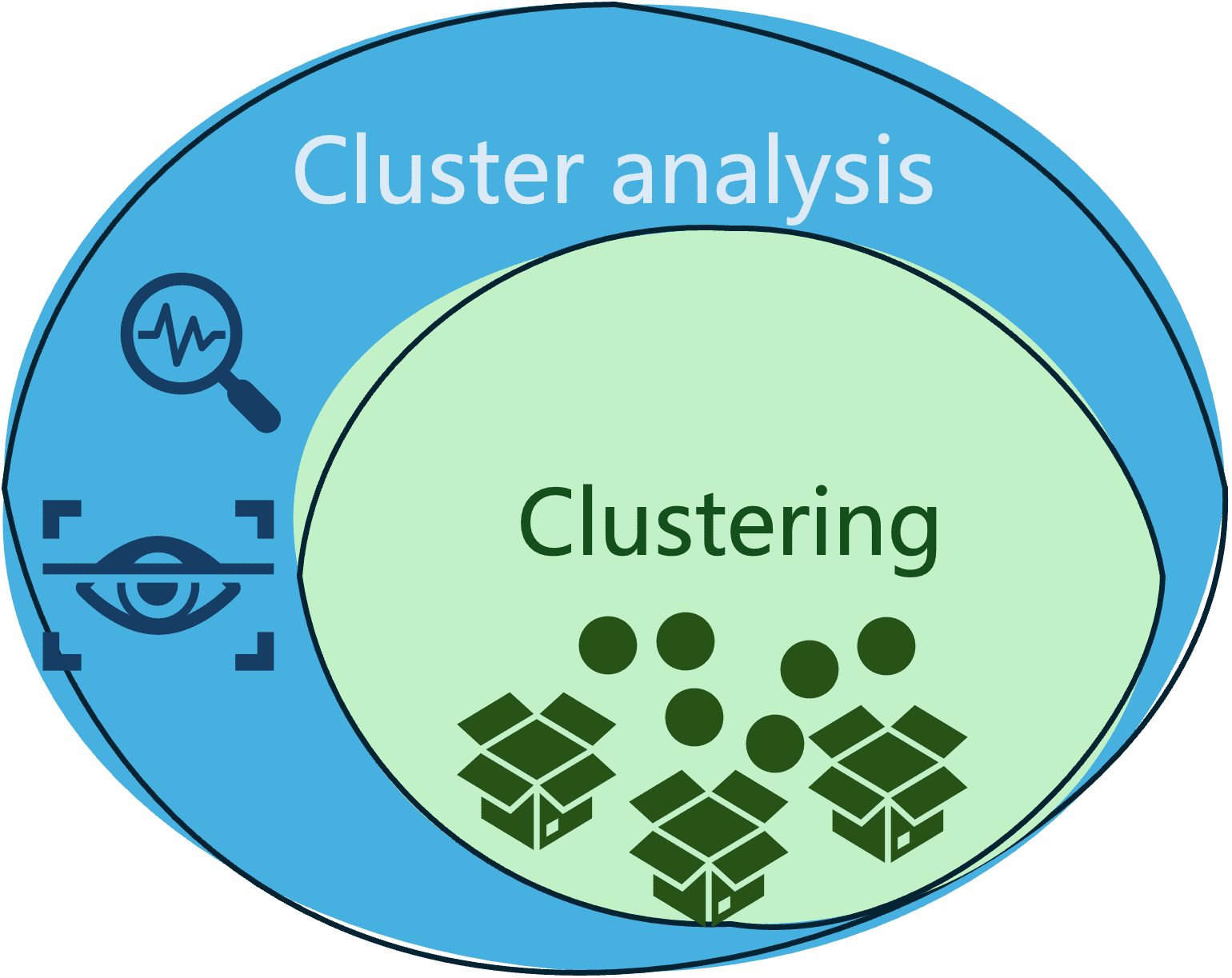
Praktisches Beispiel
Konzentrieren wir uns von nun an auf die Clusteranalyse und veranschaulichen dies anhand eines praktischen Beispiels:
- Segmentiert einen Datensatz.
- Analysieren Sie die erhaltenen Segmente
HINWEIS: Der zugehörige Code in diesem Beispiel setzt eine gewisse Vertrautheit mit den Grundlagen der Python-Sprache und Bibliotheken wie sklearn (zum Trainieren von Clustermodellen), pandas (für die Datenbereinigung) und matplotlib (für die Datenvisualisierung) voraus.
Wir illustrieren die Clusteranalyse am Pinguine des Palmer-Archipels Datensatz, der Datenbeobachtungen zu Pinguinen enthält, die in drei verschiedene Arten eingeteilt sind: Adelie-, Esels- und Zügelpinguin. Dieser Datensatz ist sehr beliebt zum Trainieren von Klassifizierungsmodellen, hat aber auch viel zu bieten, wenn es darum geht, darin Datencluster zu finden. Alles, was wir nach dem Laden der Datensatzdatei tun müssen, ist anzunehmen, dass das Klassenattribut „Artwork“ unbekannt ist.
import pandas as pd
penguins = pd.read_csv('penguins_size.csv').dropna()
X = penguins.drop('species', axis=1)Wir werden auch zwei kategorische Merkmale aus dem Datensatz entfernen, die das Geschlecht des Pinguins und die Insel beschreiben, auf der dieses Exemplar beobachtet wurde, und den Relaxation der numerischen Merkmale beibehalten. Wir speichern auch die bekannten Bezeichnungen (Arten) in einer separaten Variable j: Sie werden später nützlich sein, um die erhaltenen Cluster mit der tatsächlichen Klassifizierung der Pinguine im Datensatz zu vergleichen.
X = X.drop(('island', 'intercourse'), axis=1)
y = penguins.species.astype("class").cat.codesMit den folgenden wenigen Codezeilen ist es möglich, die Ok-Means-Clustering-Algorithmen anzuwenden, die im Abonnieren Bibliothek, um eine Nummer zu finden ok von Clustern in unseren Daten. Wir müssen lediglich die Anzahl der Cluster angeben, die wir finden möchten. In diesem Fall gruppieren wir die Daten in ok=3 Cluster:
from sklearn.cluster import KMeans
kmeans = KMeans(n_clusters = 3, n_init=100)
X("cluster") = kmeans.fit_predict(X)Die letzte Zeile im obigen Code speichert das Clustering-Ergebnis, nämlich die ID des Clusters, die jeder Dateninstanz zugewiesen wird, in einem neuen Attribut namens „Cluster“.
Es ist Zeit, einige Visualisierungen unserer Cluster zu generieren, um sie zu analysieren und zu interpretieren! Der folgende Codeausschnitt ist etwas lang, läuft aber darauf hinaus, zwei Datenvisualisierungen zu generieren: Die erste zeigt ein Streudiagramm um zwei Datenmerkmale – Länge des Culmen und Länge der Flossen – und den Cluster, zu dem jede Beobachtung gehört, und die zweite Visualisierung zeigt die tatsächliche Pinguinart, zu der jeder Datenpunkt gehört.
plt.determine (figsize=(12, 4.5))
# Visualize the clusters obtained for 2 of the information attributes: culmen size and flipper size
plt.subplot(121)
plt.plot(X(X("cluster")==0)("culmen_length_mm"),
X(X("cluster")==0)("flipper_length_mm"), "mo", label="First cluster")
plt.plot(X(X("cluster")==1)("culmen_length_mm"),
X(X("cluster")==1)("flipper_length_mm"), "ro", label="Second cluster")
plt.plot(X(X("cluster")==2)("culmen_length_mm"),
X(X("cluster")==2)("flipper_length_mm"), "go", label="Third cluster")
plt.plot(kmeans.cluster_centers_(:,0), kmeans.cluster_centers_(:,2), "kD", label="Cluster centroid")
plt.xlabel("Culmen size (mm)", fontsize=14)
plt.ylabel("Flipper size (mm)", fontsize=14)
plt.legend(fontsize=10)
# Evaluate in opposition to the precise ground-truth class labels (actual penguin species)
plt.subplot(122)
plt.plot(X(y==0)("culmen_length_mm"), X(y==0)("flipper_length_mm"), "mo", label="Adelie")
plt.plot(X(y==1)("culmen_length_mm"), X(y==1)("flipper_length_mm"), "ro", label="Chinstrap")
plt.plot(X(y==2)("culmen_length_mm"), X(y==2)("flipper_length_mm"), "go", label="Gentoo")
plt.xlabel("Culmen size (mm)", fontsize=14)
plt.ylabel("Flipper size (mm)", fontsize=14)
plt.legend(fontsize=12)
plt.presentHier sind die Visualisierungen:

Durch die Beobachtung der Cluster können wir eine erste Erkenntnis gewinnen:
- Es gibt eine subtile, aber nicht sehr klare Trennung zwischen den Datenpunkten (Pinguinen), die den verschiedenen Clustern zugeordnet sind, wobei es leichte Überlappungen zwischen den gefundenen Untergruppen gibt. Dies führt uns noch nicht unbedingt zu dem Schluss, dass die Clusterergebnisse intestine oder schlecht sind: Wir haben den Ok-Means-Algorithmus auf mehrere Attribute des Datensatzes angewendet, aber diese Visualisierung zeigt, wie Datenpunkte über Cluster hinweg nur in Bezug auf zwei Attribute positioniert sind: „Culmenlänge“ und „Flossenlänge“. Es könnte andere Attributpaare geben, unter denen Cluster visuell als klarer voneinander getrennt dargestellt werden.
Dies führt zu der Frage: Was wäre, wenn wir versuchen würden, unseren Cluster unter zwei beliebigen anderen Variablen zu visualisieren, die zum Trainieren des Modells verwendet werden?
Versuchen wir, uns die Körpermasse (Gramm) und die Rumpflänge (mm) der Pinguine vorzustellen.
plt.plot(X(X("cluster")==0)("body_mass_g"),
X(X("cluster")==0)("culmen_length_mm"), "mo", label="First cluster")
plt.plot(X(X("cluster")==1)("body_mass_g"),
X(X("cluster")==1)("culmen_length_mm"), "ro", label="Second cluster")
plt.plot(X(X("cluster")==2)("body_mass_g"),
X(X("cluster")==2)("culmen_length_mm"), "go", label="Third cluster")
plt.plot(kmeans.cluster_centers_(:,3), kmeans.cluster_centers_(:,0), "kD", label="Cluster centroid")
plt.xlabel("Physique mass (g)", fontsize=14)
plt.ylabel("Culmen size (mm)", fontsize=14)
plt.legend(fontsize=10)
plt.present
Das scheint glasklar! Jetzt haben wir unsere Daten in drei unterscheidbare Gruppen aufgeteilt. Und wir können zusätzliche Erkenntnisse daraus gewinnen, indem wir unsere Visualisierung weiter analysieren:
- Es besteht eine starke Beziehung zwischen den gefundenen Clustern und den Werten der Attribute „Körpermasse“ und „Schnabellänge“. Von der unteren linken bis zur oberen rechten Ecke des Diagramms zeichnen sich Pinguine der ersten Gruppe dadurch aus, dass sie aufgrund ihrer niedrigen Werte für „Körpermasse“ klein sind, aber sie weisen stark unterschiedliche Schnabellängen auf. Pinguine der zweiten Gruppe sind mittelgroß und haben mittlere bis hohe Werte für „Schnabellänge“. Schließlich zeichnen sich Pinguine der dritten Gruppe dadurch aus, dass sie größer sind und einen längeren Schnabel haben.
- Es ist auch zu beobachten, dass es einige Ausreißer gibt, additionally Datenbeobachtungen mit atypischen Werten, die weit von der Mehrheit entfernt sind. Dies ist besonders beim Punkt ganz oben im Visualisierungsbereich zu erkennen, der auf einige beobachtete Pinguine mit einem überlangen Schnabel in allen drei Gruppen hinweist.
Einpacken
Dieser Beitrag veranschaulicht das Konzept und die praktische Anwendung der Clusteranalyse als Prozess zum Auffinden von Untergruppen von Elementen mit ähnlichen Merkmalen oder Eigenschaften in Ihren Daten und zum Analysieren dieser Untergruppen, um daraus wertvolle oder umsetzbare Erkenntnisse zu gewinnen. Von Advertising and marketing über E-Commerce bis hin zu Ökologieprojekten wird die Clusteranalyse in einer Vielzahl von Bereichen der realen Welt angewendet.
Iván Palomares Carrascosa ist ein führender Experte, Autor, Redner und Berater in den Bereichen KI, maschinelles Lernen, Deep Studying und LLMs. Er schult und leitet andere bei der Nutzung von KI in der realen Welt an.